

文章目录
一、目的与要求
- 熟练运用数据清洗及相关预处理方法;
- 掌握常用可视化技术的适用场合及相关方法;
- 了解
matplotlib库的基本功能; - 掌握
matplotlib库中常用可视化方法调用接口。
二、实验设备与环境、数据
- PC 机、PC 机 + Python3.7 环境(pycharm、anaconda 或其它都可以)
- 可视化库:
Matplotlib库等 - 提供鸢尾花数据集
iris150条记录(150*5)包括一个类标号属性。
三、实验内容
1) 可视化必要性及工具
数据可视化是数据科学工作的一项主要任务,在分析早期阶段,通常会进行探索性数据分析(EDA)以获取对数据的理解和洞察,尤其对于大型高维的数据集,数据可视化有助于使数据分布及关系更清晰易懂;在项目结束时,以清晰、简洁和引人注目的方式展示最终结果使人更容易理解。
本实验采用 Python 的 Matplotlib、Seaborn 等库实现一些快速而简单的可视化功能,Matplotlib 是个比较流行的 Python 库,可以方便实现数据的可视化,它与 Numpy、pandas 及其提供的数据结构紧密集成。Seaborn 是基于
matplotlib 的 Python 可视化库。提供了多种对 matplotlib 绘制的图形的美化
功能。
在可视化过程中,要了解各种可视化技术的特点及接口,根据实际数据集及任务需求来正确选择相应可视化手段,并且正确设置接口数据和参数。
具体要求
(1)数据获取
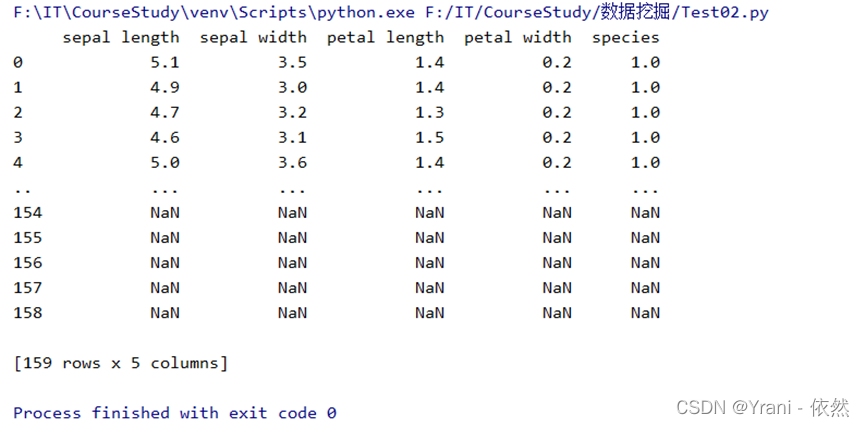
从本地读取 iris 数据集,将列名命名为: 'sepal length', 'sepal width ', 'petal length','petal width', 'species'
import pandas as pd
iris_data = pd.read_csv("iris.csv", header=None, names=['sepal length', 'sepal width',
'petal length', 'petal width', 'species'])
iris = pd.DataFrame(iris_data)
print(iris)

(2)数据的清理
a) 查看数据行列情况,判断是否有空行,如果有则删除;
b) 查看空值情况
import pandas as pd
iris_data=pd.read_csv("iris.csv",header=None,names=['sepal length','sepal width',
'petal length','petal width','species'])
iris=pd.DataFrame(iris_data)
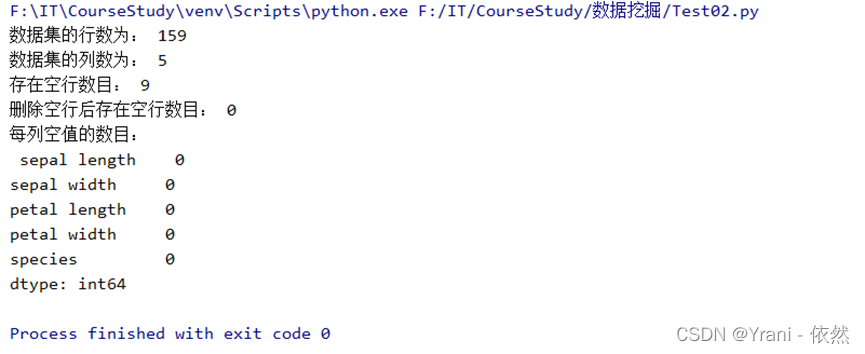
print("数据集的行数为:",iris.shape[0])
print("数据集的列数为:",iris.shape[1])
print("存在空行数目:",iris.isnull().T.any().sum())
iris.dropna(axis=0,how="all",inplace=True)
print("删除空行后存在空行数目:",iris.isnull().T.any().sum ())
print("每列空值的数目:\n",iris.isnull().sum())
(3)可视化技术
(注意:以下图中请标记: title、legend以及各坐标标签。)
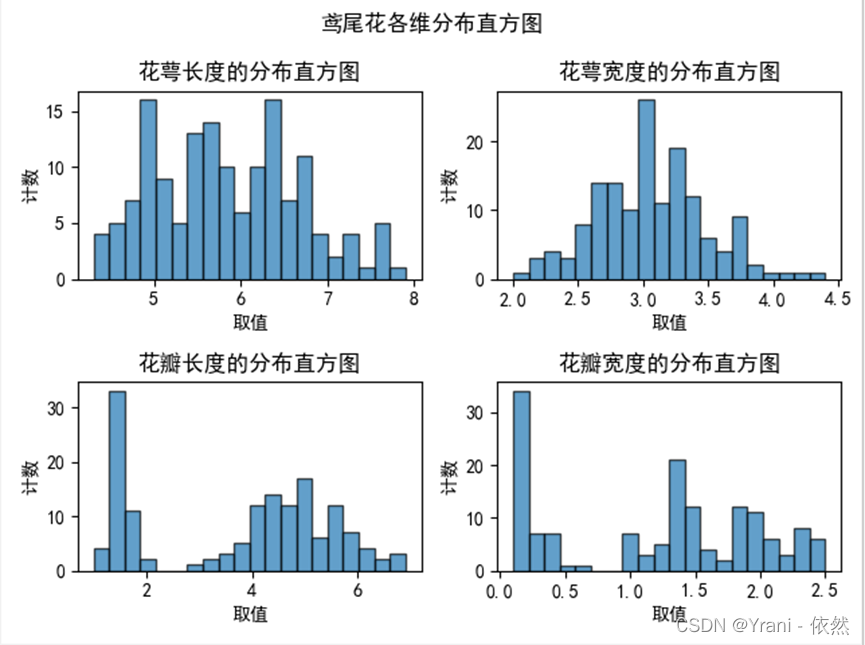
a) 直方图展示各个维度的值分布情况;(20个分箱)
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei']
iris_data = pd.read_csv("iris.csv", header=None, names=['sepal length', 'sepal width',
'petal length', 'petal width', 'species'])
iris = pd.DataFrame(iris_data)
plt.suptitle("鸢尾花各维分布直方图")
plt.subplot(221)
plt.hist(iris_data['sepal length'], bins=20, edgecolor='black', alpha=0.7)
plt.xlabel("取值")
plt.ylabel("计数")
plt.title("花萼长度的分布直方图")
plt.subplot(222)
plt.hist(iris_data['sepal width'], bins=20, edgecolor='black', alpha=0.7)
plt.xlabel("取值")
plt.ylabel("计数")
plt.title("花萼宽度的分布直方图")
plt.subplot(223)
plt.hist(iris_data['petal length'], bins=20, edgecolor='black', alpha=0.7)
plt.xlabel("取值")
plt.ylabel("计数")
plt.title("花瓣长度的分布直方图")
plt.subplot(224)
plt.hist(iris_data['petal width'], bins=20, edgecolor='black', alpha=0.7)
plt.xlabel("取值")
plt.ylabel("计数")
plt.title("花瓣宽度的分布直方图")
plt.subplots_adjust(hspace=0.5)
plt.show()
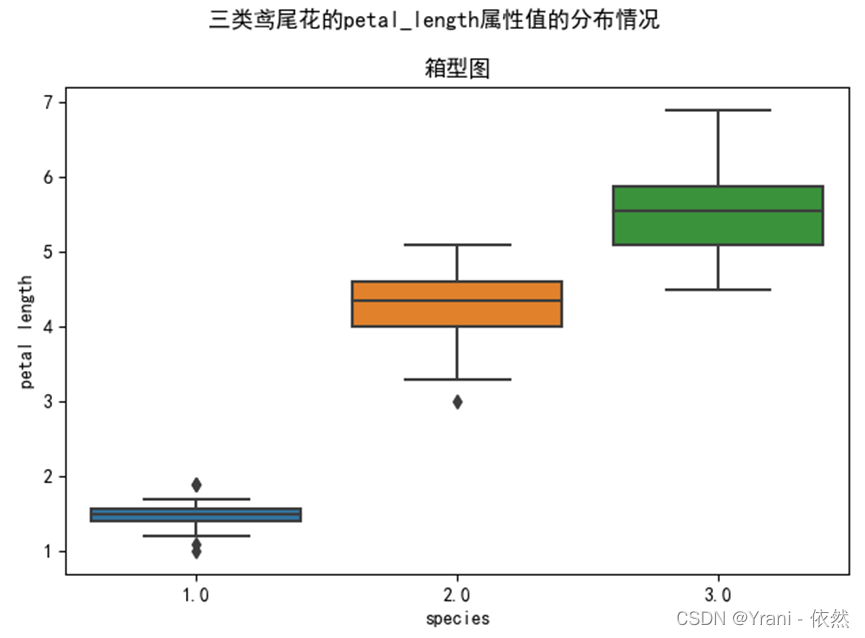
b) 箱式图展示三类鸢尾花的petal_length属性值的分布情况;
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
import seaborn as sns
mpl.rcParams['font.sans-serif']=['SimHei']
iris_data = pd.read_csv("iris.csv", header=None, names=['sepal length', 'sepal width',
'petal length', 'petal width', 'species'])
iris = pd.DataFrame(iris_data)
plt.suptitle("三类鸢尾花的petal_length属性值的分布情况")
sns.boxplot(x="species",y="petal length",data=iris)
plt.title("箱型图")
plt.show()
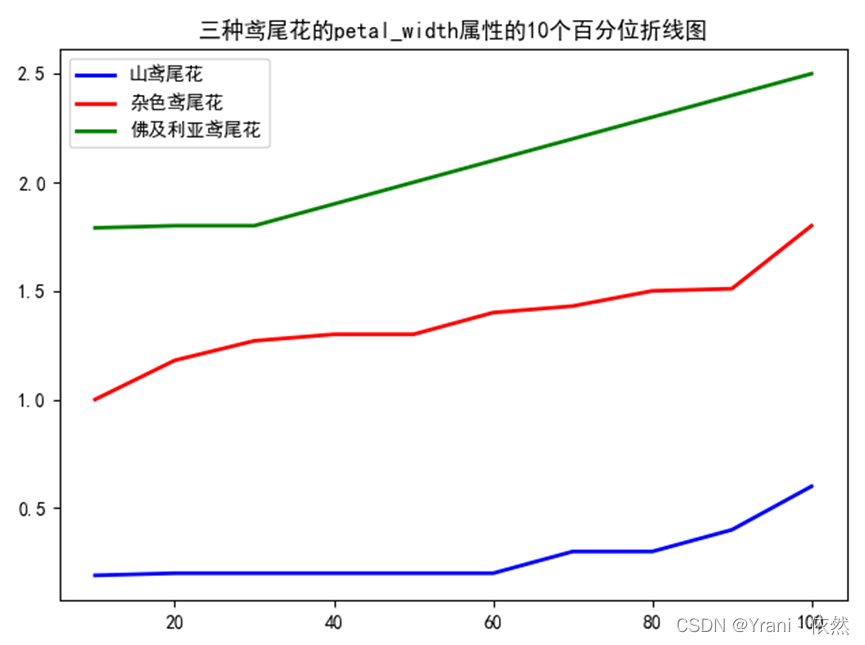
c) 在一个图中展示三种鸢尾花的petal_width属性的10个百分位折线图
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
import numpy as np
mpl.rcParams['font.sans-serif']=['SimHei']
iris_data = pd.read_csv("iris.csv", header=None, names=['sepal length', 'sepal width',
'petal length', 'petal width', 'species'])
iris = pd.DataFrame(iris_data)
q=np.linspace(10,100,num=10)
sepal_length1=np.array(iris[iris['species']==1]['petal width'])
plt.plot(q,np.percentile(sepal_length1,q),color='blue',linewidth=2.0)
sepal_length2=np.array(iris[iris['species']==2]['petal width'])
plt.plot(q,np.percentile(sepal_length2,q),color='red',linewidth=2.0)
sepal_length3=np.array(iris[iris['species']==3]['petal width'])
plt.plot(q,np.percentile(sepal_length3,q),color='green',linewidth=2.0)
plt.title("三种鸢尾花的petal_width属性的10个百分位折线图")
plt.legend([sepal_length1,sepal_length2,sepal_length3],labels=['山鸢尾花','杂色鸢尾花','佛及利亚鸢尾花'])
plt.show()
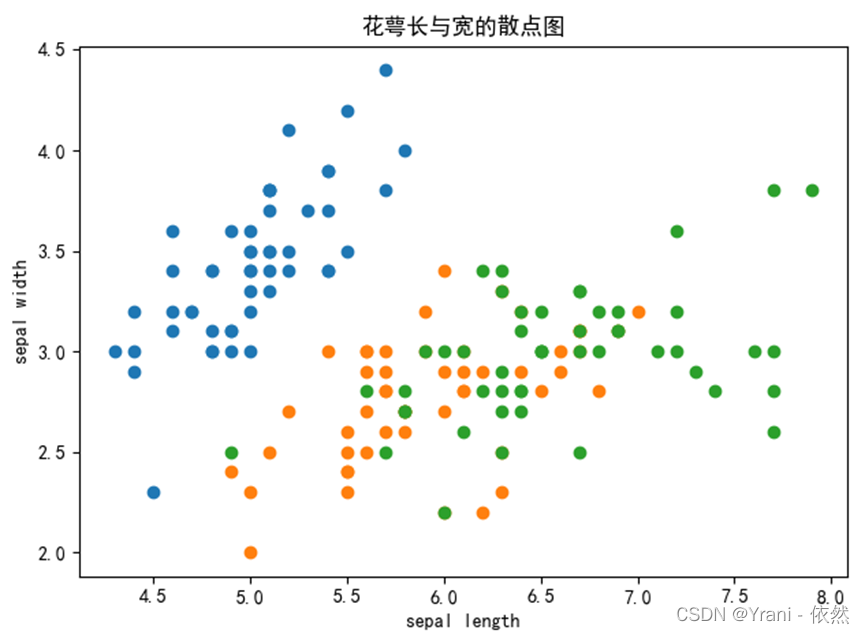
d) 在一个图中展示花萼长与宽的散点图
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei']
iris_data = pd.read_csv("iris.csv", header=None, names=['sepal length', 'sepal width',
'petal length', 'petal width', 'species'])
iris = pd.DataFrame(iris_data)
plt.scatter(iris[iris['species']==1]['sepal length'],iris[iris['species']==1]['sepal width'])
plt.scatter(iris[iris['species']==2]['sepal length'],iris[iris['species']==2]['sepal width'])
plt.scatter(iris[iris['species']==3]['sepal length'],iris[iris['species']==3]['sepal width'])
plt.title('花萼长与宽的散点图', fontsize=24)
plt.xlabel('sepal length', fontsize=14)
plt.ylabel('sepal width', fontsize=14)
plt.show()
e) (选做)将杂色鸢尾花和维吉利亚鸢尾花的花瓣长度分别进行等宽离散化为5个区间,分别统计两种花的花瓣长度的离散值相同的数量在本类花的占比,并分别用饼状图展示离散化的区间占比。
待补充···
四、实验小结
- 通过本次实验我复习了数据集成、数据清洗、及数据变换等数据处理的相关操作,认识到了新的matplotlib函数库并加以使用。
- matplotlib是一个优秀的画图工具库,可以实现很多功能,值得深度研究和探索。
- 学会使用matplotlib库的基本功能,如用matplotlib画折线图、散点图、直方图、箱型图等等。
- matplotlib中的的函数较多,需要多多练习和写代码来实现,才能更好的运用。
- 本次实验中用了经典的iris数据集,同时用数据可视化的方法去展示iris数据集中的内容,数据可视化的作用是可以通过直观的图表来表示三种鸢尾花的各项属性值的变化,更有利于对比。
- 自己的知识还存在很多漏洞和缺口,课下需要多加努力学习。
Original: https://blog.csdn.net/weixin_46264660/article/details/124303833
Author: 寒夜点孤灯
Title: 数据挖掘 | 实验二 数据的可视化
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/764629/
转载文章受原作者版权保护。转载请注明原作者出处!