

💥 项目专栏:【Python实现经典机器学习算法】附代码+原理介绍
文章目录
前言
- 👑 最近粉丝群中很多朋友私信咨询一些决策树、逻辑回归等机器学习相关的编程问题,为了能更清晰的说明,所以建立了本专栏
专门记录基于原生Python实现一些入门必学的机器学习算法,帮助广大零基础用户达到轻松入门,为了更深刻算法的基本原理,本专栏没有采用第三方库来实现(sklearn),而是采用原生Python自己复现相关算法,从而帮助新手理解算法的内部细节。 - 👑 本专栏适用人群:🚨🚨🚨
机器学习初学者,刚刚接触sklearn的用户群体,专栏将具体讲解如何基于原生Python来实现一些经典机器学习算法,快速让新手小白能够对机器学习算法有更深刻的理解。 - 👑 本专栏内包含基于原生Python从零实现经典机器学习算法,通过自复现帮助新手小白对算法有更深刻的认识,理论与实践相结合,每一篇文章都附带有
完整的代码+原理讲解。
🚨 我的项目环境:
- 平台:Windows11
- 语言环境:Python 3.7
- 编译器:Jupyter Lab
- Pandas:1.3.5
- Numpy:1.19.3
- Scipy:1.7.3
- Matplotlib:3.1.3
💥 项目专栏:【Python实现经典机器学习算法】附代码+原理介绍
一、NAG(Nesterov accelerated gradient)优化原理
Momentum是基于动量原理的,就是每次更新参数时,梯度的方向都会和上一次迭代的方向有关,当一个球向山下滚的时候,它会越滚越快,能够加快收敛,但是这样也会存在一个问题,每次梯度都是本次和上次之和,如果是同向,那么将导致梯度很大,当到达谷底的时候很容易动量过大导致小球冲过谷底,跳过当前局部最优位置。
我们希望有一个更智能的球,一个知道它要去哪里的球,这样它知道在山坡再次向上倾斜之前减速。
Nesterov accelerated gradient是一种使动量项具有这种预见性的方法。我们知道我们将使用动量项来移动参数。因此,为我们提供了参数下一个位置的近似值(完全更新时缺少梯度),大致了解了参数的位置。我们现在可以通过计算梯度(不是我们当前参数的,而是我们参数的近似未来位置的)有效地向前看。
v t = γ v t − 1 + η ∇ θ J ( θ − γ v t − 1 ) θ = θ − v t v_t=\gamma v_{t-1}+\eta\nabla_{\theta}J(\theta-\gamma v_{t-1})\ \theta=\theta-v_t v t =γv t −1 +η∇θJ (θ−γv t −1 )θ=θ−v t
第一个公式分为两个部分看,第一项是动量部分,保持上次的梯度方向,第二项就是当前梯度,但是这个不太一样,梯度参数里面是 θ − γ ∗ v t − 1 \theta-\gamma * v_{t-1}θ−γ∗v t −1 ,由于我们希望小球可以知道自己何时停下,所以希望小球可以预测未来梯度的趋势,一旦发现前方的坡度上升,那么就应该减小步伐,以免冲出最低点,从公式角度理解,更新当前梯度时,我先按照上次梯度方向更新,计算一个大概未来的一个梯度,如果为正,那么说明本次更新后仍和我之前更行的方向一致,说明本次不会冲出去,保持更新即可,但是如果为负,说明本次更新后梯度方向变化了,即冲过了最优点,那么正好和上次的动量方向抵消一部分,因为两者异号,这样小球就知道自己此次更新会冲过去,所以两者抵消一部分导致本次更新步伐没有那么大。
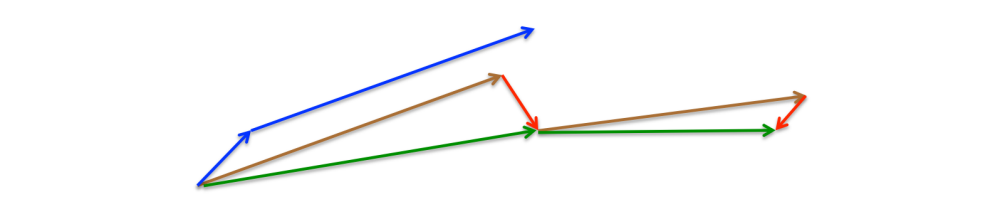

我们再次将动量项的值设置为0.9左右。动量首先计算当前梯度(图3中的蓝色小矢量),然后在更新的累积梯度(蓝色大矢量)的方向上进行大跳跃,而NAG首先在先前累积梯度(棕色矢量)的方向上进行大跳跃,测量梯度,然后进行校正(绿色矢量)。此预期更新可防止我们进行得太快,从而提高响应能力,从而显著提高RNN在许多任务上的性能。
现在我们能够根据误差函数的斜率调整更新,并反过来加快SGD,我们还希望根据每个参数的重要性调整更新,以执行更大或更小的更新。
; 二、更新规则
NAG(Nesterov accelerated gradient)是一种基于动量的优化算法,它在 Momentum 的基础上提出了 Nesterov 加速梯度(Nesterov accelerated gradient)的概念,以进一步提高训练效率。
Nesterov 加速梯度的核心思想是,在计算梯度之前,先对参数进行一次预测,然后基于这个预测值来计算梯度。这样,可以更加准确地计算出梯度,并在更新参数时得到更好的结果。
具体地,NAG 的更新规则如下:
v t = γ v t − 1 + η ∇ θ J ( θ − γ v t − 1 ) v_t = \gamma v_{t-1} + \eta \nabla_{\theta} J(\theta – \gamma v_{t-1})v t =γv t −1 +η∇θJ (θ−γv t −1 )
θ t = θ t − 1 − v t \theta_t = \theta_{t-1} – v_t θt =θt −1 −v t
其中,v t v_t v t 表示在 t 时刻的动量,γ \gamma γ 是动量系数,η \eta η 是学习率,∇ θ J ( θ − γ v t − 1 ) \nabla_{\theta} J(\theta – \gamma v_{t-1})∇θJ (θ−γv t −1 ) 是关于参数 θ \theta θ 的损失函数 J 的梯度。需要注意的是,在计算梯度时,预测值 θ − γ v t − 1 \theta – \gamma v_{t-1}θ−γv t −1 用于计算损失函数的梯度。
在更新参数时,首先根据当前的梯度和上一次的动量计算出当前时刻的动量 v t v_t v t 。然后,根据学习率和动量来更新参数 θ t \theta_t θt 。这里需要注意的是,NAG 中使用的动量是基于预测值的动量,而不是基于当前梯度的动量。
NAG 的优点是可以加速训练过程,提高参数更新的准确性,并减小震荡。此外,NAG 也易于与其他算法进行结合,如 AdaGrad、RMSprop 和 Adam 等。
三、迭代过程

; 四、代码实践
import numpy as np
import matplotlib.pyplot as plt
class Optimizer:
def __init__(self,
epsilon = 1e-10,
iters = 100000,
lamb = 0.01,
gamma = 0.0,
):
self.epsilon = epsilon
self.iters = iters
self.lamb = lamb
self.gamma = gamma
def nag(self, x_0 = 0.5, y_0 = 0.5):
f1, f2 = self.fn(x_0, y_0), 0
w = np.array([x_0, y_0])
k = 0
v_t = 0.0
while True:
if abs(f1 - f2) self.epsilon or k > self.iters:
break
f1 = self.fn(x_0, y_0)
if k == 0:
g = np.array([self.dx(x_0, y_0), self.dy(x_0, y_0)])
else:
g = np.array([self.dx(x_0 - v_t[0], y_0 - v_t[1]), self.dy(x_0 - v_t[0], y_0 - v_t[1])])
v_t = self.gamma * v_t + self.lamb * g
x_0, y_0 = np.array([x_0, y_0]) - v_t
f2 = self.fn(x_0, y_0)
w = np.vstack((w, (x_0, y_0)))
k += 1
self.print_info(k, x_0, y_0, f2)
self.draw_process(w)
def print_info(self, k, x_0, y_0, f2):
print('迭代次数:{}'.format(k))
print('极值点:【x_0】:{} 【y_0】:{}'.format(x_0, y_0))
print('函数的极值:{}'.format(f2))
def draw_process(self, w):
X = np.arange(0, 1.5, 0.01)
Y = np.arange(-1, 1, 0.01)
[x, y] = np.meshgrid(X, Y)
f = x**3 - y**3 + 3 * x**2 + 3 * y**2 - 9 * x
plt.contour(x, y, f, 20)
plt.plot(w[:, 0],w[:, 1], 'g*', w[:, 0], w[:, 1])
plt.show()
def fn(self, x, y):
return x**3 - y**3 + 3 * x**2 + 3 * y**2 - 9 * x
def dx(self, x, y):
return 3 * x**2 + 6 * x - 9
def dy(self, x, y):
return - 3 * y**2 + 6 * y
"""
函数: f(x) = x**3 - y**3 + 3 * x**2 + 3 * y**2 - 9 * x
最优解: x = 1, y = 0
极小值: f(x,y) = -5
"""
optimizer = Optimizer()
optimizer.nag()
Original: https://blog.csdn.net/m0_47256162/article/details/121576888
Author: Bi 8 Bo
Title: 【机器学习】numpy实现NAG(Nesterov accelerated gradient)优化器
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/763523/
转载文章受原作者版权保护。转载请注明原作者出处!