

第一章 Numpy基础
Numpy(Numerical Python的简称),其中Numpy提供了两种基本的对象: ndarray(N-dimensional Array Object)和 ufunc(Universal Function Object)。ndarray是存储单一数据类型的多维数 组,而ufunc则是能够对数组进行处理的函数。
Numpy的主要特点:
- ndarray,快速节省空间的多维数组,提供数组化的算术运算和高级的广播功能。
- 使用标准数学函数对整个数组的数据进行快速运算,且不需要编写循环。
- 读取/写入磁盘上的阵列数据和操作存储器映像文件的工具。
- 线性代数、随机数生成和傅里叶变换的能力。
- 集成C、C++、Fortran代码的工具。
1.1 生成Numpy数组
Numpy是Python的外部库,不在标准库中。因此,若要使用它,需要先 导入Numpy。
import numpy as np
Numpy封装了一个新的数据类型ndarray(N-dimensional Array),它是一个多维数组对象。
1.1.1 从已有数据中创建数组
直接对Python的基础数据类型(如列表、元组等)进行转换来生成 ndarray:
(1)将列表转换为ndarray:
import numpy as np
lst1 = [3.14, 2.17, 0, 1, 2] # 列表
nd1 =np.array(lst1) # 转换为ndarray
print(nd1)
print(type(nd1))
[3.14 2.17 0. 1. 2. ]
(2)嵌套列表可以转换为多维ndarray:
import numpy as np
lst2 = [[3.14, 2.17, 0, 1, 2], [1, 2, 3, 4, 5]] # 嵌套列表
nd2 =np.array(lst2) # 转换为ndarray
print(nd2)
print(type(nd2))
print(nd2.shape)
[[3.14 2.17 0. 1. 2. ]
[1. 2. 3. 4. 5. ]]
(2, 5)
1.1.2 利用random模块生成数组
在深度学习中,我们经常需要对一些 参数进行初始化,因此为了更有效地训练模型,提高模型的性能,有些初始化还需要满足一定的条件,如满足正态分布或均匀分布等。


以np.random.random函数为例(生成0到1之间的随机数):
import numpy as np
nd3 =np.random.random([3, 3]) # 生成0到1之间的随机数 3*3矩阵
print(nd3)
print("nd3的形状为:",nd3.shape)
[[0.97151229 0.75627874 0.43857646]
[0.53075204 0.92951764 0.76348507]
[0.95390096 0.49060309 0.33783101]]
nd3的形状为: (3, 3)
为了每次生成同一份数据,可以指定一个随机种子,使用shuffle函数打乱生成的随机数。
import numpy as np
np.random.seed(123) # 随机种子
nd4 = np.random.randn(2,3) # 标准正态随机数
print(nd4)
np.random.shuffle(nd4) # 打乱
print("随机打乱后数据:")
print(nd4)
print(type(nd4))
[[-1.0856306 0.99734545 0.2829785 ]
[-1.50629471 -0.57860025 1.65143654]]
随机打乱后数据:
[[-1.50629471 -0.57860025 1.65143654]
[-1.0856306 0.99734545 0.2829785 ]]
1.1.3 创建特定形状的多维数组
参数初始化时,有时需要生成一些特殊矩阵,如全是0或1的数组或矩 阵,这时我们可以利用 np.zeros、np.ones、np.diag来实现。

import numpy as np
nd5 =np.zeros([3, 3]) # 生成全是 0 的 3x3 矩阵
#np.zeros_like(nd5) # 生成与nd5形状一样的全0矩阵
nd6 = np.ones([3, 3]) # 生成全是 1 的 3x3 矩阵
nd7 = np.eye(3) # 生成 3 阶的单位矩阵
nd8 = np.diag([1, 2, 3]) # 生成 3 阶对角矩阵
print(nd5)
print(nd6)
print(nd7)
print(nd8)
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
[[1 0 0]
[0 2 0]
[0 0 3]]
有时还可能需要把生成的数据暂时保存起来,以备后续使用。
import numpy as np
nd9 =np.random.random([5, 5]) # 5*5在0-1的矩阵
np.savetxt(X=nd9, fname='./test1.txt') # 保存路径和文件名等
print(nd9)
nd10 = np.loadtxt('./test1.txt') # 读取文件
print(nd10)
[[0.02798196 0.17390652 0.15408224 0.07708648 0.8898657 ]
[0.7503787 0.69340324 0.51176338 0.46426806 0.56843069]
[0.30254945 0.49730879 0.68326291 0.91669867 0.10892895]
[0.49549179 0.23283593 0.43686066 0.75154299 0.48089213]
[0.79772841 0.28270293 0.43341824 0.00975735 0.34079598]]
[[0.02798196 0.17390652 0.15408224 0.07708648 0.8898657 ]
[0.7503787 0.69340324 0.51176338 0.46426806 0.56843069]
[0.30254945 0.49730879 0.68326291 0.91669867 0.10892895]
[0.49549179 0.23283593 0.43686066 0.75154299 0.48089213]
[0.79772841 0.28270293 0.43341824 0.00975735 0.34079598]]
1.1.4 利用arange、linspace函数生成数组
arange是numpy模块中的函数,其格式为:
arange([start,] stop[,step,], dtype=None)
其中start与stop用来指定范围,step用来设定步长。在生成一个ndarray 时,start默认为0,步长step可为小数。Python有个内置函数range,其功能与此类似。
import numpy as np
print(np.arange(10)) # [0 1 2 3 4 5 6 7 8 9]
print(np.arange(0, 10)) # [0 1 2 3 4 5 6 7 8 9]
print(np.arange(1, 4, 0.5))# [1. 1.5 2. 2.5 3. 3.5]
print(np.arange(9, -1, -1))# [9 8 7 6 5 4 3 2 1 0]
linspace也是numpy模块中常用的函数,其格式为:
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
linspace可以根据输入的指定数据范围以及等份数量,自动生成一个线性等分向量,其中endpoint(包含终点)默认为True,等分数量num默认为 50。如果将retstep设置为True,则会返回一个带步长的ndarray。
import numpy as np
print(np.linspace(0, 1, 10))
[0. 0.11111111 0.22222222 0.33333333 0.44444444 0.55555556
0.66666667 0.77777778 0.88888889 1. ]
这里并没有像我们预期的那样,生成0.1,0.2,…,1.0这样步长为0.1的ndarray,这是因为linspace必定会包含数据起点和终点,那么其步长则为(1-0)/9=0.11111111。如果需要产生0.1,0.2,…,1.0这样的数据,只需要将数据起点0修改为0.1即可。
除了上面介绍到的arange和linspace,Numpy还提供了 logspace函数,该函数的使用方法与linspace的使用方法一样。
1.2 获取元素
接下来将介绍几种常用获取数据的方法。
import numpy as np
np.random.seed(2019) # 设置随机种子
nd11 = np.random.random([10]) # 生成1*10的处于0-1之间的随机数
print(nd11)
nd11[3] # 获取指定位置的数据,获取第4个元素
nd11[3:6] # 截取一段数据
nd11[1:6:2] # 截取固定间隔数据
nd11[::-2] # 倒序取数
nd12=np.arange(25).reshape([5,5]) # 5*5矩阵
print(nd12)
nd12[1:3,1:3] # 截取一个多维数组的一个区域内数据
nd12[(nd12>3)&(nd12
获取数组中的部分元素除了 通过指定索引标签来实现外,还可以通过使用一些函数来实现,如通过random.choice函数从指定的样本中随机抽取数据。
import numpy as np
from numpy import random as nr
a=np.arange(1,25,dtype=float)
c1=nr.choice(a,size=(3,4)) # size指定输出数组形状
c2=nr.choice(a,size=(3,4),replace=False) # replace缺省为True,即可重复抽取。
#下式中参数p指定每个元素对应的抽取概率,缺省为每个元素被抽取的概率相同。
c3=nr.choice(a,size=(3,4),p=a / np.sum(a))
print("随机可重复抽取")
print(c1)
print("随机但不重复抽取")
print(c2)
print("随机但按制度概率抽取")
print(c3)
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18.
19. 20. 21. 22. 23. 24.]
随机可重复抽取
[[16. 15. 18. 18.]
[14. 18. 18. 14.]
[23. 16. 13. 3.]]
随机但不重复抽取
[[ 6. 14. 7. 4.]
[19. 2. 3. 16.]
[12. 10. 9. 20.]]
随机但按制度概率抽取
[[24. 15. 23. 16.]
[ 9. 9. 17. 19.]
[23. 13. 12. 17.]]
1.3 Numpy的算术运算
一种是对应元素相乘,又称为逐元乘法(ElementWise Product),运算符为np.multiply(),或*。另一种是点积或内积元素,运算符为np.dot()。
1.3.1 对应元素相乘
对应元素相乘(Element-Wise Product)是 两个矩阵中对应元素乘积。 np.multiply函数用于数组或矩阵对应元素相乘,输出与相乘数组或矩阵的大小一致,其格式如下:
numpy.multiply(x1, x2, /, out=None, *, where=True,casting=’same_kind’, order=’K’, dtype=None
A = np.array([[1, 2], [-1, 4]])
B = np.array([[2, 0], [3, 4]])
print(A*B)
print(np.multiply(A,B))
array([[ 2, 0],
[-3, 16]])
array([[ 2, 0],
[-3, 16]])

Numpy数组不仅可以和数组进行对应元素相乘,还可以和单一数值(或 称为标量)进行运算。运算时,Numpy数组中的每个元素都和标量进行运算,其间会用到广播机制。
print(A*2.0)
print(A/2.0)
[[ 2. 4.]
[-2. 8.]]
[[ 0.5 1. ]
[-0.5 2. ]]
由此,推而广之,数组通过一些激活函数后,输出与输入形状一致。
X=np.random.rand(2,3)
def softmoid(x):
return 1/(1+np.exp(-x))
def relu(x):
return np.maximum(0,x)
def softmax(x):
return np.exp(x)/np.sum(np.exp(x))
print("输入参数X的形状:",X.shape)
print("激活函数softmoid输出形状:",softmoid(X).shape)
print("激活函数relu输出形状:",relu(X).shape)
print("激活函数softmax输出形状:",softmax(X).shape)
输入参数X的形状: (2, 3)
激活函数softmoid输出形状: (2, 3)
激活函数relu输出形状: (2, 3)
激活函数softmax输出形状: (2, 3)
1.3.2 点积运算
点积运算(Dot Product)又称为 内积,在Numpy用np.dot表示,其一般格式为:
numpy.dot(a, b, out=None)
X1=np.array([[1,2],[3,4]])
X2=np.array([[5,6,7],[8,9,10]])
X3=np.dot(X1,X2)
print(X3)
[[21 24 27]
[47 54 61]]

其实就是行*列的和=对应位置的值。
1.4 数组变形
由于不同模型所接收的输入格式不一样,往往需要先对其进行 一系列的变形和运算,从而将数据 处理成符合模型要求的格式。在矩阵或者数组的运算中,经常会遇到需要把多个向量或矩阵按某轴方向合并,或展平 (如在卷积或循环神经网络中,在全连接层之前,需要把矩阵展平)的情 况。
1.4.1 更改数组的形状

1、reshape(不修改向量本身)
指定维度时可以只指定行数或列数, 其他用 -1 代替,程序自行运算。(但要整除)
import numpy as np
arr =np.arange(10)
print(arr)
print(arr.reshape(2, 5)) # 将向量 arr 维度变换为2行5列
print(arr.reshape(5, -1)) # 指定维度时可以只指定行数或列数, 其他用 -1 代替
print(arr.reshape(-1, 5))
print(arr)
[0 1 2 3 4 5 6 7 8 9]
[[0 1 2 3 4]
[5 6 7 8 9]]
[[0 1]
[2 3]
[4 5]
[6 7]
[8 9]]
[[0 1 2 3 4]
[5 6 7 8 9]]
[0 1 2 3 4 5 6 7 8 9]
2、resize(修改向量本身)
import numpy as np
arr =np.arange(10)
print(arr)
arr.resize(2, 5) # 将向量 arr 维度变换为2行5列
print(arr)
[0 1 2 3 4 5 6 7 8 9]
[[0 1 2 3 4]
[5 6 7 8 9]]
3、T向量转置
import numpy as np
arr =np.arange(12).reshape(3,4) # 向量 arr 为3行4列
print(arr)
print(arr.T) # 将向量 arr 进行转置为4行3列
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
4、ravel向量展平
import numpy as np
arr =np.arange(6).reshape(2, -1)
print(arr)
print("按照列优先,展平") # 按照列优先,展平
print(arr.ravel('F'))
print("按照行优先,展平") # 按照行优先,展平
print(arr.ravel())
[[0 1 2]
[3 4 5]]
按照列优先,展平
[0 3 1 4 2 5]
按照行优先,展平
[0 1 2 3 4 5]
5、flatten将矩阵转换为向量
经常出现在卷积网络与全连接层之间
import numpy as np
a =np.floor(10*np.random.random((3,4)))
print(a)
print(a.flatten())
[[4. 4. 3. 3.]
[2. 3. 5. 1.]
[7. 5. 1. 9.]]
[4. 4. 3. 3. 2. 3. 5. 1. 7. 5. 1. 9.]
6、squeeze
这是一个主要用来 降维的函数,把矩阵中含1的维度去掉。在PyTorch中 还有一种与之相反的操作——torch.unsqueeze。
import numpy as np
arr =np.arange(3).reshape(3, 1) # 3*1矩阵
print(arr.shape) # (3,1)
print(arr.squeeze().shape) # (3,)
arr1 =np.arange(6).reshape(3,1,2,1) # 3*1*2*1矩阵
print(arr1.shape) #(3, 1, 2, 1)
print(arr1.squeeze().shape) #(3, 2)
(3, 1)
(3,)
(3, 1, 2, 1)
(3, 2)
7、transpose对高维矩阵进行轴变换
对高维矩阵进行轴对换,这个在深度学习中经常使用,比如把图片中表 示颜色顺序的RGB改为GBR。
import numpy as np
arr2 = np.arange(24).reshape(2,3,4) # 2*3*4矩阵
print(arr2.shape) # (2, 3, 4)
print(arr2.transpose(1,2,0).shape) # (0 1 2)->(1,2,0) 得到(3, 4, 2)
1.4.2 合并数组
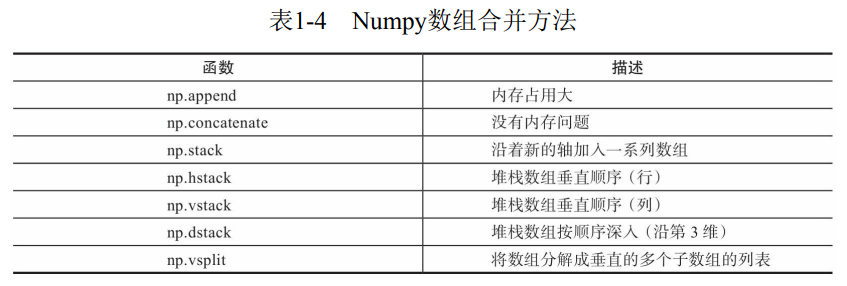
- append、concatenate以及stack都有一个axis参数,用于控制数组的合并方式是按行还是按列。(axis=0按行,axis=1按列)
- 对于append和concatenate,待合并的数组必须有相同的行数或列数 (满足一个即可)。
- stack、hstack、dstack,要求待合并的数组必须具有相同的形状(shape)。
1、append
合并一维数组:
import numpy as np
a =np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = np.append(a, b)
print(c)
[1 2 3 4 5 6]
合并多维数组:
import numpy as np
a =np.arange(4).reshape(2, 2)
b = np.arange(4).reshape(2, 2)
按行合并 axis=0
c = np.append(a, b, axis=0)
print('按行合并后的结果')
print(c)
print('合并后数据维度', c.shape)
按列合并 axis=1
d = np.append(a, b, axis=1)
print('按列合并后的结果')
print(d)
print('合并后数据维度', d.shape)
按行合并后的结果
[[0 1]
[2 3]
[0 1]
[2 3]]
合并后数据维度 (4, 2)
按列合并后的结果
[[0 1 0 1]
[2 3 2 3]]
合并后数据维度 (2, 4)
2、concatenate沿指定轴 连接数组或矩阵
import numpy as np
a =np.array([[1, 2], [3, 4]])
b = np.array([[5, 6]])
c = np.concatenate((a, b), axis=0)
print(c)
d = np.concatenate((a, b.T), axis=1)
print(d)
[[1 2]
[3 4]
[5 6]]
[[1 2 5]
[3 4 6]]
3、stack沿指定轴 堆叠数组或矩阵
import numpy as np
a =np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
print(np.stack((a, b), axis=0))
[[[1 2]
[3 4]]
[[5 6]
[7 8]]]
1.5 批量处理
在实际使用中往往采用批量处理(Mini-Batch)的方法。
如何把大数据拆分成多个批次呢?可采用如下步骤:
- 得到数据集
- 随机打乱数据
- 定义批大小
- 批处理数据集
import numpy as np
data_train = np.random.randn(10000,2,3) # 生成10000个形状为2X3的矩阵
print(data_train.shape) # 这是一个3维矩阵,第一个维度为样本数,后两个是数据形状
# (10000,2,3)
np.random.shuffle(data_train) # 打乱这10000条数据
batch_size=100 # 定义批量大小
for i in range(0,len(data_train),batch_size): # 进行批处理
x_batch_sum=np.sum(data_train[i:i+batch_size])
print("第{}批次,该批次的数据之和:{}".format(i,x_batch_sum))
部分运行结果如下:

1.6 通用函数
ufunc是 universal function的缩写,它是一种能对数组的每个元素进行操作的函数。 许多ufunc函数都是用C语言级别实现的,因此它们的计算速度非常快。此外,它们比math模块中的函数更灵活。math模块的输入一般是标量,但 Numpy中的函数可以是向量或矩阵,而利用向量或矩阵可以避免使用循环语句,这点在机器学习、深度学习中非常重要。

1、math与numpy函数的性能比较
import time
import math
import numpy as np
x = [i * 0.001 for i in np.arange(1000000)]
start = time.perf_counter()
for i, t in enumerate(x):
x[i] = math.sin(t)
print ("math.sin:", time.perf_counter() - start )
x = [i * 0.001 for i in np.arange(1000000)]
x = np.array(x)
start = time.perf_counter()
np.sin(x)
print ("numpy.sin:", time.perf_counter() - start )
python笔记 之 3.8下time.clock()引用出错的问题
math.sin: 0.2921822999996948
numpy.sin: 0.008482100000037462
由此可见,numpy.sin比math.sin快近40倍。
2、循环与向量运算比较
充分使用Python的Numpy库中的内建函数(Built-in Function),来实现计算的 向量化,可大大地提高运行速度。Numpy库中的内建函数使用了 SIMD指令。如下使用的向量化要比使用循环计算速度快得多。如果使用 GPU,其性能将更强大,不过Numpy不支持GPU。PyTorch支持GPU。
import time
import numpy as np
x1 = np.random.rand(1000000)
x2 = np.random.rand(1000000)
##使用循环计算向量点积
tic = time.process_time()
dot = 0
for i in range(len(x1)):
dot+= x1[i]*x2[i]
toc = time.process_time()
print ("dot = " + str(dot) + "\n for loop----- Computation time = " + str(1000*(toc - tic)) + "ms")
##使用numpy函数求点积
tic = time.process_time()
dot = 0
dot = np.dot(x1,x2)
toc = time.process_time()
print ("dot = " + str(dot) + "\n verctor version---- Computation time = " + str(1000*(toc - tic)) + "ms")
dot = 250342.7868182414
for loop----- Computation time = 531.25ms
dot = 250342.78681824336
verctor version---- Computation time = 31.25ms
从运行结果上来看,使用for循环的运行时间大约是向量运算的15倍。 因此,在深度学习算法中,一般都使用向量化矩阵进行运算。
1.7 广播机制
Numpy的Universal functions中要求输入的数组shape是一致的,当数组的shape不相等时,则会使用广播机制。不过,调整数组使得shape一样,需要满足一定的规则,否则将出错。这些规则可归纳为以下4条。
- 让所有输入数组都向其中shape最长的数组看齐,不足的部分则通过在前面加1补齐,如:a:2×3×2 b:3×2 则b向a看齐,在b的前面加1,变为:1×3×2
- 输出数组的shape是输入数组shape的各个轴上的最大值;
- 如果输入数组的某个轴和输出数组的对应轴的长度相同或者某个轴 的长度为1时,这个数组能被用来计算,否则出错;
- 如果输入数组的某个轴和输出数组的对应轴的长度相同或者某个轴 的长度为1时,这个数组能被用来计算,否则出错;
目的:A+B,其中A为4×1矩阵,B为一维向量(3,)。 要相加,需要做如下处理:
- 根据规则1,B需要向看齐,把B变为(1,3)
- 根据规则2,输出的结果为各个轴上的最大值,即输出结果应该为 (4,3)矩阵,那么A如何由(4,1)变为(4,3)矩阵?B又如何由(1,3)变 为(4,3)矩阵?
- 根据规则4,用此轴上的第一组值(要主要区分是哪个轴),进行复制 (但在实际处理中不是真正复制,否则太耗内存,而是采用其他对象如 ogrid对象,进行网格处理)即可,详细处理过程如图1-4所示。

Original: https://blog.csdn.net/weixin_44855366/article/details/120702088
Author: HHzdh
Title: 第一章 Numpy基础
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/761993/
转载文章受原作者版权保护。转载请注明原作者出处!