

目录
1.示例使得数据格式为包含图片的文件夹、包含路径和标签的TXT文件\mmclassification\mmcls\data\mnist\filelist.py
2.修改数据加载方式,以加载自己格式的数据\mmclassification\mmcls\datasets\my_filelist.py
3.添加自己的类名\mmclassification\mmcls\datasets__init__.py
4.在训练配置文件中改为自己的类名,和数据D:\Code\mmclassification\configs\resnet\GWF_resnet18_8xb32_in1k.py
0.常用的两种数据格式,详见 官网
The CustomDataset supports two kinds of format:
- An annotation file is provided, and each line indicates a sample image. The sample images can be organized in any structure, like:
train/
├── folder_1
│ ├── xxx.png
│ ├── xxy.png
│ └── ...
├── 123.png
├── nsdf3.png
└── ...
And an annotation file records all paths of samples and corresponding category index. The first column is the image path relative to the folder (in this example, train) and the second column is the index of category:
folder_1/xxx.png 0
folder_1/xxy.png 1
123.png 1
nsdf3.png 2
...
NOTE The value of the category indices should fall in range [0, num_classes - 1].
- The sample images are arranged in the special structure:
train/
├── cat
│ ├── xxx.png
│ ├── xxy.png
│ └── ...
│ └── xxz.png
├── bird
│ ├── bird1.png
│ ├── bird2.png
│ └── ...
└── dog
├── 123.png
├── nsdf3.png
├── ...
└── asd932_.png
In this case, you don’t need provide annotation file, and all images in the directory cat will be recognized as samples of cat.
Usually, we will split the whole dataset to three sub datasets: train, val and test for training, validation and test. And every sub dataset should be organized as one of the above structures.
And in your config file, you can modify the data field as below:
...
dataset_type = 'CustomDataset'
classes = ['cat', 'bird', 'dog'] # The category names of your dataset
data = dict(
train=dict(
type=dataset_type,
data_prefix='data/my_dataset/train',
ann_file='data/my_dataset/meta/train.txt',
classes=classes,
pipeline=train_pipeline
),
val=dict(
type=dataset_type,
data_prefix='data/my_dataset/val',
ann_file='data/my_dataset/meta/val.txt',
classes=classes,
pipeline=test_pipeline
),
test=dict(
type=dataset_type,
data_prefix='data/my_dataset/test',
ann_file='data/my_dataset/meta/test.txt',
classes=classes,
pipeline=test_pipeline
)
)
...
1.示例使得数据格式为包含图片的文件夹、包含路径和标签的TXT文件\mmclassification\mmcls\data\mnist\filelist.py
实例:将数据格式从以下格式:
--\mmclassification\mmcls\data\mnist\train
        --0 
          --00001.png
           --00021.png
           --。。。
        --1
        --。。。
修改为:
--\mmclassification\mmcls\data\mnist\train
        --00001.png
        --00021.png
        --。。。
并且生成文件\mmclassification\mmcls\data\mnist\train.txt,形如 :
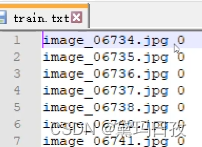

And an annotation file records all paths of samples and corresponding category index. The first column is the image path relative to the folder (in this example, train) and the second column is the index of category:
The value of the category indices should fall in range [0, num_classes - 1].
#\mmclassification\mmcls\data\filelist.py
import numpy as np
import os
import shutil
path = r'D:\Code\mmclassification\mmcls\data\1'
train_path = os.path.join(path, 'train')
train_out = os.path.join(path, 'train.txt')
val_path = os.path.join(path, 'test')
val_out = os.path.join(path, 'test.txt')
data_train_out = os.path.join(path, 'train_filelist')
data_val_out = os.path.join(path, 'test_filelist')
if not os.path.exists(data_train_out):
os.mkdir(data_train_out)
if not os.path.exists(data_val_out):
os.mkdir(data_val_out)
labelISfilename = False #True: when label is filename
def get_filelist(input_path,output_path):
print('get_filelist input_path,output_path:', input_path, output_path)
with open(output_path, 'w') as f:
i = 0
index__label_name = {}
for dir_path, dir_names, file_names in os.walk(input_path): #os.walk返回的是一个三元组(root,dirs,files)。root 所指的是当前正在遍历的这个文件夹的本身的地址;dirs 是一个 list ,内容是该文件夹中所有的目录(文件夹)的名字(不包括子目录);files 同样是 list , 内容是该文件夹中所有的文件的名字(不包括子目录)
print('-dir_path, dir_names, file_names-', dir_path, dir_names, file_names)
if dir_path == input_path:
label_name = dir_names
if dir_path != input_path:
if labelISfilename:
label = int(dir_path.split('\\')[-1])
else:
label = i
#print('label:', label)
for filename in file_names:
f.write(filename +' '+str(label)+"\n")
index__label_name[str(i)] = label_name[i]
i+=1
print('index__label_name:', index__label_name)
return index__label_name
def move_imgs(input_path,output_path):
for dir_path, dir_names, file_names in os.walk(input_path):
print('-dir_path, dir_names, file_names-', dir_path, dir_names, file_names)
for filename in file_names:
if dir_path != input_path:
source_path = os.path.join(dir_path, filename)
print('source_path:', source_path)
print('out_path:', os.path.join(output_path, filename))
shutil.copyfile(source_path, os.path.join(output_path, filename))
print('strat get_filelist:')
get_filelist(train_path, train_out)
get_filelist(val_path, val_out)
print('strat move_imgs:')
move_imgs(train_path, data_train_out)
move_imgs(val_path, data_val_out)
2.修改数据加载方式,以加载自己格式的数据\mmclassification\mmcls\datasets\my_filelist.py
#\mmclassification\mmcls\datasets\my_filelist.py
import numpy as np
from .builder import DATASETS
from .base_dataset import BaseDataset
@DATASETS.register_module()
class MyFilelist(BaseDataset):
CLASSES = ['0','1','2','3','4','5','6','7','8','9']
def load_annotations(self):
assert isinstance(self.ann_file, str) #对应配置文件GWF_resnet18_8xb32_in1k.py中ann_file表示包括文件名和标签的txt文件
data_infos = []
with open(self.ann_file) as f:
samples = [x.strip().split(' ') for x in f.readlines()]
for filename, gt_label in samples:
info = {'img_prefix': self.data_prefix} #对应配置文件GWF_resnet18_8xb32_in1k.py中data_prefix表示文件路径前缀
info['img_info'] = {'filename': filename}
info['gt_label'] = np.array(gt_label, dtype=np.int64)
data_infos.append(info)
return data_infos
3.添加自己的类名\mmclassification\mmcls\datasets__init__.py
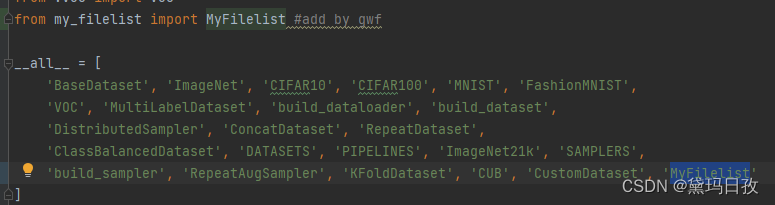
#\mmclassification\mmcls\datasets\__init__.py
Copyright (c) OpenMMLab. All rights reserved.
from .base_dataset import BaseDataset
from .builder import (DATASETS, PIPELINES, SAMPLERS, build_dataloader,
build_dataset, build_sampler)
from .cifar import CIFAR10, CIFAR100
from .cub import CUB
from .custom import CustomDataset
from .dataset_wrappers import (ClassBalancedDataset, ConcatDataset,
KFoldDataset, RepeatDataset)
from .imagenet import ImageNet
from .imagenet21k import ImageNet21k
from .mnist import MNIST, FashionMNIST
from .multi_label import MultiLabelDataset
from .samplers import DistributedSampler, RepeatAugSampler
from .voc import VOC
from .my_filelist import MyFilelist #add by gwf
__all__ = [
'BaseDataset', 'ImageNet', 'CIFAR10', 'CIFAR100', 'MNIST', 'FashionMNIST',
'VOC', 'MultiLabelDataset', 'build_dataloader', 'build_dataset',
'DistributedSampler', 'ConcatDataset', 'RepeatDataset',
'ClassBalancedDataset', 'DATASETS', 'PIPELINES', 'ImageNet21k', 'SAMPLERS',
'build_sampler', 'RepeatAugSampler', 'KFoldDataset', 'CUB', 'CustomDataset', 'MyFilelist'
]
4.在训练配置文件中改为自己的类名,和数据D:\Code\mmclassification\configs\resnet\GWF_resnet18_8xb32_in1k.py
type='MyFilelist', #新写的类
data_prefix='../mmcls/data/mnist/train',#里面直接保存所有的图片
ann_file='../mmcls/data/mnist/train.txt',#格式为图片名 标签(为一行)
5.相关文档推荐
记录一次 mmclassification 自定义数据训练和推理
Original: https://blog.csdn.net/weixin_40712293/article/details/126197608
Author: 黛玛日孜
Title: open-mmlab. mmclassification构建自己的数据集格式并训练
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/761387/
转载文章受原作者版权保护。转载请注明原作者出处!