

处理缺失值流程与方法汇总:
1.读取数据
import numpy as np
data = np.genfromtxt("test.txt",delimiter=',')
print(type(data))
print(data)
<class 'numpy.ndarray'>
[[ 1. 100.]
[ 2. 90.]
[ 3. nan]
[ 4. 70.]
[ 5. nan]
[ 6. 70.]
[ 7. 85.]
[ 8. 75.]
[ 9. nan]]
从上面输出结果可以看出该数据是9行2列,其中第二列存在3个缺失值
说明:
- np.nan不是空对象。
- 对列表中的nan进行操作时不能用”==np.nan”来判断。只能用np.isnan()来操作。
- np.nan的数据类型是float。
2.判断数据中是否有空值
- 利用numpy:np.isnan()函数
np.isnan(data)
array([[False, False],
[False, False],
[False, True],
[False, False],
[False, True],
[False, False],
[False, False],
[False, False],
[False, True]])
从输出结果可以看出,非空值返回False,空值返回True
np.isnan(data[:,1])
np.isnan(data[2,:])
- 利用pandas:isnull()函数
1.首先转换数据类型,因为上面读取数据类型为
import pandas as pd
data_pd = pd.DataFrame(data)
print(type(data_pd))
output
<class 'pandas.core.frame.DataFrame'>
2.进行isnull()操作
data_pd.isnull() #效果等同于np.isnan()函数,同样会返回布尔值
输出


data_pd[0].isnull() #判断第0列是否存在空值(下标从0开始)
data_pd[1].isnull() #判断第1列是否存在空值(下标从0开始)
data_pd[[0,1]].isnull() #判断第0列和第1列是否存在空值(下标从0开始),效果等同于data_pd.isnull()
3.统计空值/非空值数量
1.统计每列的空值数量
data_pd.isnull().sum() # 统计每列的空值数量
#output 第0列0个空值,第1列3个空值
0 0
1 3
dtype: int64
2.统计每列的非空值数量
data_pd.notnull().sum()
#output
0 9
1 6
dtype: int64
3.其他相关操作
data_pd.count() # 统计所有列的非空值数量
data_pd[1].count() # 第1列非空数量(下标从0开始)
data_pd.count(axis=1) # 每行非空值数量,axis=1
4.根据空值筛选数据
1.筛选出data_pd中存在空值的行
data_pd[data_pd.isnull().values==True]
输出
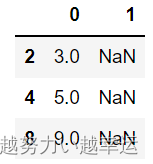
2.筛选出第1列为空的所有行(下标从0开始)
data_pd[data_pd[1].isnull()]
输出
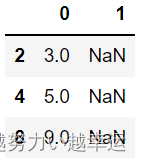
5.查找空值索引
np.where(np.isnan(data_pd)) # data_pd中空值所在的行索引及列索引
np.where(np.isnan(data_pd[1])) # data_pd中第1列空值所在的行索引
6.填充空值fillna()函数、replace()方法(里面填充的是键值对结构)
用指定的数字来填充
data_pd.fillna(0) # 用0来填充data_pd中的空值
用指定的函数统计值来填充
data_pd.fillna(data_pd.mean()) # 用data_pd中数据的平均值来填充空值
data_pd.fillna(data_pd.mean()[1]) #指定用第1列数据均值来填充data_pd中空值
data_pd[1]=data_pd[1].fillna(data_pd[1].mean()) #指定用第1列数据均值来填充第1列数据中空值
data_pd.fillna(data_pd.sum()) # 用data_pd中数据的和来填充空值
使用插值法填充
data=np.genfromtxt('test.txt',delimiter=',')
data=pd.DataFrame(data)
data[1] = data[1].interpolate()
用字典来填充
values = {'0':6, '1': 9} # 0列空值用6填充,1列空值用9填充
data_pd.fillna(value=values)
用指定字符串来填充空值
data_pd.fillna("null")
#上下数据补全
不同的填充方式{'backfill', 'bfill', 'pad', 'ffill', None}
每列的空值,用其列下方非空数值填充
data_pd.fillna(method="backfill")
data_pd.fillna(method="bfill") # 同backfill
每列的空值,用其所在列上方非空数值填充,若上方没有元素,保持空值
data_pd.fillna(method="ffill")
data_pd.fillna(method="pad") # 同 ffill
#limit参数设置填充空值的最大个数
data_pd.fillna(0,limit=1) # 每列最多填充1个空值,超过范围的空值依然为空
#inplace参数空值是否修改原数据data_pd
data_pd.fillna(0,inplace=True) # inplace为true,将修改作用于原数据
参考:如何处理numpy数组中的空值
Pandas+Numpy 数据中空值的处理操作:判断、查找、填充及删除
Original: https://blog.csdn.net/qq_41238751/article/details/126263672
Author: 越努力い越幸运
Title: 缺失值处理的常用方法:判断、查找、填充及删除
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/759976/
转载文章受原作者版权保护。转载请注明原作者出处!