

kaggle创始人为Anthony毕业于墨尔本大学,于2010年在创立kaggle, 现在被google收购, 现在有100多万活跃用户。
- 学习kaggle平台如何参加比赛, 如何提交项目
- 练习Titanic – Machine Learning from Disaster
泰坦尼克号项目主要是通过一个train.csv文件提供的基础数据,预测test.csv文件中测试数据集的准确性, 然后把预测结果保存到gender_submission.csv提交。
import pandas as pd
train_data = pd.read_csv('titanic/train.csv')
pandas是数据科学库, 和numpy处理矩阵类似, 主要用于处理表格, 相当于一个可编程的excel, 方便处理数据.
按照惯例缩写为pd
所以一般语法:
import pandas as pd
读取文件:一般pandas读取的文件为csv, 也有excel和text文件, 语法一样。
train_data = pd.read_csv('titanic/train.csv')
train_data变量名用于保存读取的文件内存
type(train_data)
pandas.core.frame.DataFrame
DataFrame是pandas的数据保存方式, 就是一个数据表格
一下语法可以制作表格:
pd.DataFrame({'Yes': [1, 2], 'No': [3, 4]})
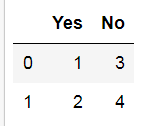

可见, pandas可以制作漂亮的表格, DataFrame为制表方法, 字典中的key为column, 代表列的项目名, value用list表示, 代表每一列的具体内容, DataFrame自动加索引。
train_data.head()

1 解题的第一步是读懂表格:
第一列为索引号, 第二列为乘客ID,然后是否生还,根据表格1 代表活着, 0代表死亡, 应为一等舱的旅客大部分生还,另外kaggle文件有说明, 可见Pclass是一个影响很大的feature, 姓名应该影响不大, 但根据我们对泰坦尼克号的了解, 性别和年龄应该影响很大,应该是妇女和儿童优先登上救生艇,下一列是有没有兄弟姐妹或配偶也在船上,另一列是有没有父母小孩, 这些项目也是其中的影响因素。然后再看船票和票价, 可见头等舱几乎是三等的10倍, 应该影响很大。然后舱位和上船地点, 舱位也影响很大, 因为三等的没有, 应该在船的底层, 从电影中我们可以看到, 至于上船地点, 应该影响不大, 那个地方都有穷人和富人。
2 test.csv
import pandas as pd
test_data = pd.read_csv('titanic/test.csv')
test_data.head()

可见test.csv几乎和train.csv一样, 但少了一项survived, 这项需要我们预测。
3 gender_submission.csv
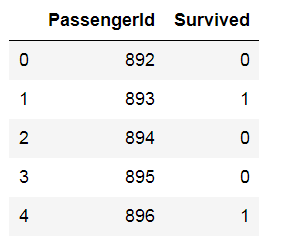
可见, 从892号开始测试, 通过的前面891个数据的feature, 预测后面的数据, 通过提交的submission检验模型的准确性。
; 4 模型的选择
通过对kaggle的基础内容学习, 可以选择决策树模型, 但Random Forest 应该准确性更高, 至于features的选择, 可以先全部选择, 然后尝试是否有必要删除一些featueres来提高精确性。
5 数据清洗
由于表格中的性别影响很大, 应该需要用到, 需要做数据处理。
6 题目要求
The competition is simple: we want you to use the Titanic passenger data (name, age, price of ticket, etc) to try to predict who will survive and who will die.
7 代码IDE
由于本题要求数据量不大, 运算时间不长, 可以用kaggle提供的notebook或者自己的Jupyter notebook, 如果处理计算机视觉和深度学习的一些问题建议使用GPU, 如果没有, 可以用Kaggle免费提供的加快计算时间。
8 关于submission file 原始数据:
原始数据假设所有male挂了, 所有的female活着, 我们需要检验是否正确。
9 计算男女的存活率:
需要学习过pandas或SQL, 这样更容易理解下面的语法:
women = train_data.loc[train_data.Sex == 'female']["Survived"]
rate_women = sum(women)/len(women)
print("% of women who survived:", rate_women)
% of women who survived: 0.7420382165605095
men = train_data.loc[train_data.Sex == 'male']["Survived"]
rate_men = sum(men) / len(men)
print("% of men who survived:", rate_men)
% of men who survived: 0.18890814558058924
语法: women = train_data.loc[train_data.Sex == ‘female’]代表
locate 表中Sex == ‘female’ 的所有项目, 然后再单独取[“Survived”]这一列。
sum()和len()是pandas的方法。
可见男女的存活比例差距很大, 但男人还是有一定的存活比例, 不然都挂了, 人类就该灭绝了。
但是这一数据是相当重要的, 即使我们什么都不做,直接预测所有女人存活, 我们就有了75%的正确率了。
如果我们还用用到其他参数, 比如船票, 舱位,是有有子女父母等,那就需要很大的运算量。
但是是否还有更好的模型可以利用。
10 ML 模型
在机器学习中sklearn, sci-kit-learn中有很多可以直接运用的模型, 这样大量减少了我们的编码与运算时间。
对于同一问题,多种模型都可解决, 不同的模型对于运算结果有很大的影响, 模型中参数的选择对于预测结果也有很大的影响, 而且每个人都有不同的偏好。通过对模型的不断理解可以针对不同问题, 选择合适的模型。
该问题, 我们用到random forest model。
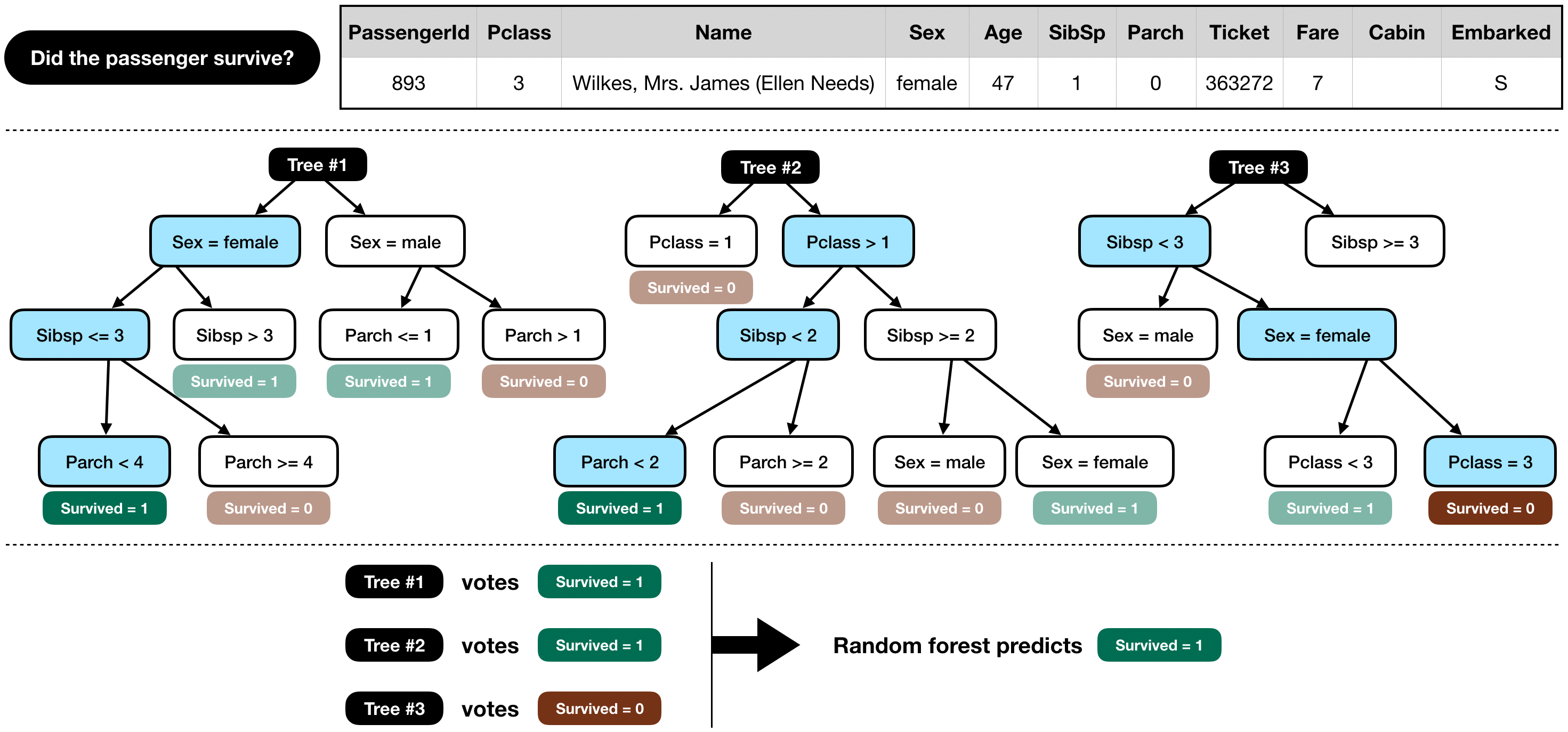
如果只用一颗树, 也就是决策树做模型, 可能会遇到很多问题, 如果树太深, 会造成overfitting, 如果叶子节点太少, 则会underfitting, 为了避免这样的问题, 我们可以用多颗决策树, 也就是random forest model, 通过多棵树(例如100), 然后取平均值, 一般会得到很好的结果。好比参加知识竞赛, 自己不会时, 求助现场观众, 如果多数选A, 那么就选A, 一般会得到正确的答案。至于数学证明, 暂时不会, 应该就是这样理解。
; 11 使用pandas注意事项
和使用SQL一样, 使用前需要保存原始数据, 不然数据经过修改, 无法恢复。
12 sklearn模型学习方法
建议边学machine learning, 边学sklearn, 如果不理解机器学习, 很难理解sklearn.
13 本题模型
import numpy as np
import pandas as pd
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
from sklearn.ensemble import RandomForestClassifier
y = train_data["Survived"]
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
predictions = model.predict(X_test)
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('my_submission.csv', index=False)
print("Your submission was successfully saved!")
Your submission was successfully saved!
our First Entry
Welcome to the leaderboard!
Your score represents your submission’s accuracy. For example, a score of 0.7 in this competition indicates you predicted Titanic survival correctly for 70% of people.
What next? You’ve got a few options:
💪Learn skills that can improve your score in our Intro to Machine Learning course by Dan Becker.
🔍Check out the discussion forum to find lots of tutorials and insights from other competitors.
🏆Find a new challenge by entering one of our open, active competitions or searching our public datasets.
14 模型优化
需要对年龄, 票价等处理, 明天完成。
Original: https://blog.csdn.net/weixin_43012796/article/details/112891688
Author: JasonDecode
Title: 入坑kaggle第二天- 详细分析Titanic – Machine Learning from Disaster
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/756605/
转载文章受原作者版权保护。转载请注明原作者出处!