

Pandas
- 1.Pandas 数据结构
*
–
–
–
–
–
–
介绍:记录一下笔记,方便以后迅速回忆使用。
1.Pandas 数据结构
- 导入所需的库
import numpy as np
import pandas as pd
- series有点像python的字典
[1].创建Series
- 1.普通创建
def CreatSeries():
"""普通创建"""
mylist = list('abc')
ser1 = pd.Series(mylist)
myarr = np.arange(3)
ser2 = pd.Series(myarr)
mydict = dict(zip(mylist, myarr))
ser3 = pd.Series(mydict)
print("{}\n{}\n{}\n".format(ser1, ser2, ser3))
ser4 = pd.Series([1, 2, 5], index=['apple', 'banana', 'peach'])
print(ser4[2])
- 2.从Python字典对象创建Series
def CreatSeries():
my_dict = {'a': 29, 'b': 994, '5': 94}
ser1 = pd.Series(my_dict)
print(ser1)
""" 访问 Series 里的数据的方式,和 Python 字典基本一样:"""
[2].对 Series 进行算术运算操作
myarr1 = np.arange(2, 7)
myarr2 = np.arange(1, 4)
ser2 = pd.Series(myarr1)
ser3 = pd.Series(myarr2)
print("加:\n{}\n减:\n{}\n乘:\n{}\n除:\n{}\n".format(ser2 + ser3, ser2 - ser3, ser2 * ser3, ser2 / ser3))
[1].创建DataFrame数据
- 形式1
dict_data = {
'id': ["0", "1", "2"],
'student': ["Li Lei", "Han Meimei", "Tom"],
'score': [95, 98, 92],
'gender': ['M', 'F', 'M']
}
DF_data = pd.DataFrame(dict_data, columns=['id', 'gender', 'student', 'score'])
print(DF_data)
- 输出结果:
id gender student score
0 0 M Li Lei 95
1 1 F Han Meimei 98
2 2 M Tom 92
- 形式2
df = {'Name': pd.Series(['Jon', 'Aaron', 'Todd'], index=['a', 'b', 'c']),
'Age': pd.Series(['18', '19', '20', '21'], index=['a', 'b', 'c', 'd']),
'Nationality': pd.Series(['Us', 'China', 'China'], index=['a', 'b', 'c'])}
ser1 = pd.DataFrame(df)
print(ser1)
- 输出结果:
Name Age Nationality
a Jon 18 Us
b Aaron 19 China
c Todd 20 China
d NaN 21 NaN
[2].向 DataFrame 里增加数据列
ser2['Time'] = [2001, 2002, 1999, 1998]
ser2['Nowtime'] = ser2['Time'] + ser2['Age']
[3].向 DataFrame 里删除数据列
"""从 DataFrame 里删除行/列,xis=0 对应的是行 row,而 axis=1 对应的是列 column 。"""
print(ser2.drop('Nowtime',axis=1))
print(ser2.drop('d',axis=0))
"""请务必记住,除非用户明确指定,否则在调用 .drop() 的时候,Pandas 并不会真的永久性地删除这行/列。这主要是为了防止用户误操作丢失数据。"""
ser2.drop('d', axis=0, inplace=True)
[4].获取 DataFrame 中的一行或多行数据
print(ser2.loc['a'])
print(ser2.iloc[0])
print(ser2.iloc[[0,1,2]])
[1].生成一个子数据表
ser3 = ser2.iloc[[0,1,2]]
ser3 = ser2.loc[['a', 'b'], ['Name', 'Age']]
[2].条件筛选
ser4 = pd.DataFrame(np.random.randn(5, 4), ['A', 'B', 'C', 'D', 'E'], ['W', 'X', 'Y', 'Z'])
print(ser4[ser4['W']>0])
print(ser4[ser4['W'] > 0][['X','Y']])
print( ser4[(ser4['W'] > 0)&(ser4['X']>0)] )
[3].重置 DataFrame 的索引
print(ser4.reset_index())
"""和删除操作差不多,.reset_index() 并不会永久改变你表格的索引,除非你调用的时候明确传入了 inplace 参数,比如:.reset_index(inplace=True)"""
[4].设置 DataFrame 的索引值
ser4['ID'] = ['1', '2', '3', '4', '5']
print(ser4.set_index('ID'))
[1].多级索引(MultiIndex)以及命名索引的不同等级
outside = ['0 Level', '0 Level', '0 Level', 'A Level', 'A Level', 'A Level']
inside = [21, 22, 23, 22, 25, 22]
my_index = list(zip(outside, inside))
sre1 = pd.MultiIndex.from_tuples(my_index)
sre2 = pd.DataFrame(np.random.randn(6, 2), index=sre1, columns=['A', 'B'])
print("sre2:\n", sre2, "\n")
print("sre2.loc['0 Level'].loc[21]:\n", sre2.loc['0 Level'].loc[21], "\n")
sre2.index.names = ['Lecels', 'Num']
print("为索引命名:\n", sre2, "\n")
print("找到所有 Levels 中,Num = 22 的行:\n", sre2.xs(22, level='Num'))
- 输出结果:
sre2:
A B
0 Level 21 0.608813 -0.371427
22 -0.774077 0.487629
23 0.946066 -0.195156
A Level 22 -1.613374 -0.245341
25 -0.976701 -0.076784
22 0.333692 0.438889
sre2.loc['0 Level'].loc[21]:
A 0.608813
B -0.371427
Name: 21, dtype: float64
为索引命名:
A B
Lecels Num
0 Level 21 0.608813 -0.371427
22 -0.774077 0.487629
23 0.946066 -0.195156
A Level 22 -1.613374 -0.245341
25 -0.976701 -0.076784
22 0.333692 0.438889
找到所有 Levels 中,Num = 22 的行:
A B
Lecels
0 Level -0.774077 0.487629
A Level -1.613374 -0.245341
A Level 0.333692 0.438889
Process finished with exit code 0
[2].数据清洗
- 删除或填充空值
"""dropna() 来丢弃这些自动填充的值"""
sre3 = {'A': [1, np.nan, 3], 'B': [2, np.nan, np.nan], 'C': [4, 5, 6]}
sre3 = pd.DataFrame(sre3)
print("操作前", sre3)
print("删除列后:\n", sre3.dropna())
print("删除行后:\n", sre3.dropna(axis=1))
"""填充空值,用fillna() 来自动给这些空值填充数据。"""
print("将表中所有 NaN 替换成 20:\n", sre3.fillna('20'))
- 输出结果:
操作前 A B C
0 1.0 2.0 4
1 NaN NaN 5
2 3.0 NaN 6
删除列后:
A B C
0 1.0 2.0 4
删除行后:
C
0 4
1 5
2 6
将表中所有 NaN 替换成 20:
A B C
0 1 2 4
1 20 20 5
2 3 20 6
[1].分组统计
ser1 = {'Company': ['Google', 'Google', 'Google', 'ORACLE', 'TWITER', 'TWITER'],
'Person': ['Sam', 'Charline', 'Amy', 'Vanessa', 'Garl', 'Sarah'],
'Sales': [200, 120, 340, 124, 243, 350]}
ser1 = pd.DataFrame(ser1)
print(ser1)
print('\n')
print(ser1.groupby('Company').mean())
print(ser1.groupby('Company').count())
print(ser1.groupby('Company').describe())
print(ser1.groupby('Company').describe().transpose())
print(ser1.groupby('Company').describe().transpose()['Google'])
[2].堆叠(Concat)
pd.concat([ser1,ser2])
pd.concat([ser1, ser2],axis=1)
df = {'Name': pd.Series(['Jon', 'Aaron', 'Todd', 'ko'], index=['a', 'b', 'c', 'd']),
'Age': pd.Series(['18', '19', '20', '21'], index=['a', 'b', 'c', 'd']),
'Nationality': pd.Series(['Us', 'China', 'China', 'Us'], index=['a', 'b', 'c', 'd']),
'ID': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
ser1 = pd.DataFrame(df)
df = {'Bookname': pd.Series(['Jonk', 'Aaronk', 'Toddk', 'kok'], index=['a', 'b', 'c', 'd']),
'Time': pd.Series(['1920', '1928', '2021', '2120'], index=['a', 'b', 'c', 'd']),
'Nationality': pd.Series(['Us', 'China', 'China', 'Us'], index=['a', 'b', 'c', 'd']),
'ID': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
ser2 = pd.DataFrame(df)
print(pd.concat([ser1,ser2]))
print(pd.concat([ser1, ser2],axis=1))
[3].归并(Merge)
print(pd.merge(ser1, ser2, how='inner', on='ID'))
print(pd.merge(ser1, ser2, how='inner', on=['ID','Nationality']))
[4].连接(Join)
print(ser1.join(ser2,how='outer'))
[5].数值处理
ser3 = pd.DataFrame({'col1': [1, 2, 3, 4], 'col2': [444, 555, 444, 666], 'col3': ['a', 'b', 'a', 'c']},
index=[0, 1, 2, 3])
print(ser3.head())
print(ser3['col2'].unique())
print(ser3['col2'].nunique())
print(ser3['col2'].value_counts())
[6].apply()方法
def square(x):
return x * x
print(ser3['col1'])
print(ser3['col1'].apply(square))
print(ser3['col3'].apply(len))
print(ser3['col1'].apply(lambda x:x*x))
[7].其他操作
print(ser1.columns)
print(ser3.sort_values('col2'))
print(ser3.isnull())
[8].数据透视表
data = {
'A': ['dog', 'dog', 'dog', 'goat', 'goat', 'goat'],
'B': ['brown', 'brown', 'black', 'black', 'brown', 'brown'],
'C': ['x', 'y', 'x', 'y', 'x', 'y'],
'D': [1, 3, 2, 5, 4, 1]
}
ser1 = pd.DataFrame(data)
print(ser1)
print(pd.pivot_table(ser1,values='D',index=['A','B'],columns=['C']))
print(ser1.pivot_table(values='D', index=['A', 'B'], columns=['C']))
- 数据准备
data = {
'A': ['dog', 'dog', 'dog', 'goat', 'goat', 'goat'],
'B': ['brown', 'brown', 'black', 'black', 'brown', 'brown'],
'C': ['x', 'y', 'x', 'y', 'x', 'y'],
'D': [1, 3, 2, 5, 4, 1]
}
ser1 = pd.DataFrame(data)
[1].文本文件、csv文件
- 使用read_table来读取文本文件。
pandas.read_table(filepath_or_buffer, sep='\t', header='infer', names=None, index_col=None, dtype=None, engine=None, nrows=None)
- 使用read_csv函数来读取csv文件。
pandas.read_csv(filepath_or_buffer, sep=',', header='infer', names=None, index_col=None, dtype=None, engine=None, nrows=None)
- read_table和read_csv常用参数及其说明。


- 其他事项
read_table和read_csv函数中的sep参数是指定文本的分隔符的,如果分隔符指定错误,在读取数据的时候,每一行数据将连成一片。
header参数是用来指定列名的,如果是None则会添加一个默认的列名。
encoding代表文件的编码格式,常用的编码有utf-8、utf-16、gbk、gb2312、gb18030等。如果编码指定错误数据将无法读取,IPython解释器会报解析错误
- 文本文件的存储
- 文本文件的存储和读取类似,结构化数据可以通过pandas中的to_csv函数实现以csv文件格式存储文件。
DataFrame.to_csv(path_or_buf=None, sep=',', na_rep=", columns=None, header=True, index=True,index_label=None,mode='w',encoding=None)
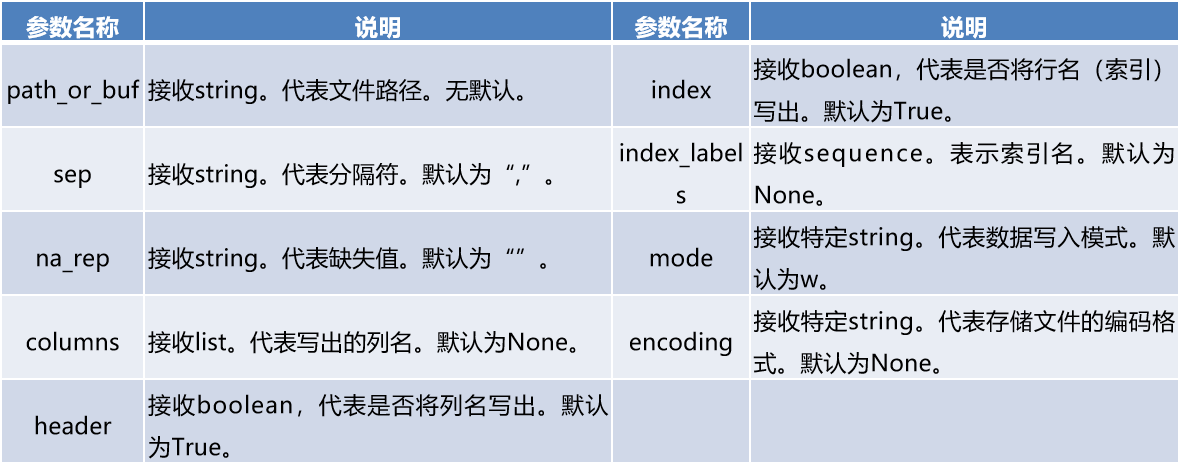
演示:
- 写入 CSV 文件
ser1.to_csv('example.csv', index=False)
- 读取 CSV 文件
ser2 = pd.read_csv('example.csv')
print(ser2)
[2].Excel 表格文件
- to_csv方法的常用参数基本一致,区别之处在于指定存储文件的文件路径参数名称为excel_writer,并且没有sep参数,增加了一个sheetnames参数用来指定存储的Excel sheet的名称,默认为sheet1。
DataFrame.to_excel(excel_writer=None, sheetname=None', na_rep=", header=True, index=True, index_label=None, mode='w', encoding=None)
ser1.to_excel('excel.xlsx', sheet_name='Sheet1')
ser2 = pd.read_excel('excel.xlsx', sheet_name='Sheetl')
[3].HTML 文件
ser3 = pd.read_html('file:///D:/phpstudy_pro/WWW/www.test.com/index.php')
print(ser3[0])
Original: https://blog.csdn.net/weixin_46703850/article/details/113872544
Author: 一个平凡de人
Title: 程序开发笔记-python数据分析处理工具-Pandas(一)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/755903/
转载文章受原作者版权保护。转载请注明原作者出处!