

数据运用
GroupBy机制(分组机制:分隔、应用和组合)
分组之后进行更高一级的运算:最大、小值,求和,均值,中位数,标准差,方差
分组机制拓展:
my_group1=titanic.groupby('pclass')
my_group1.count()
list(my_group1)
my_group2=titanic.groupby('sex')
sex_sur=my_group2['survived'].agg(['mean','count'])
sex_sur
my_group2=titanic.groupby(['pclass','sex'])
my_group2.agg(['mean','count'])
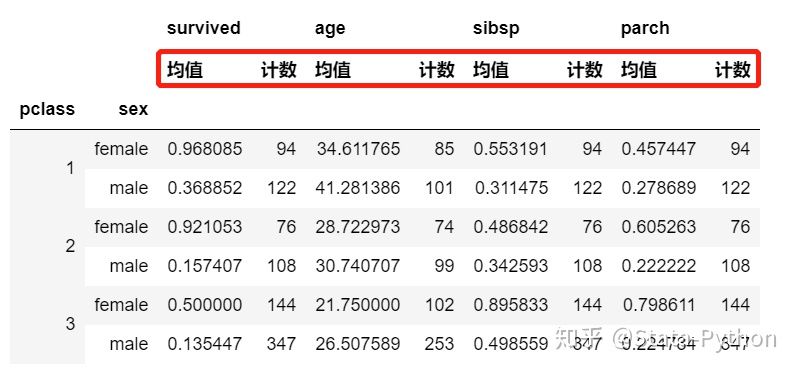
上述代码运行的结果展示:【多层分组】
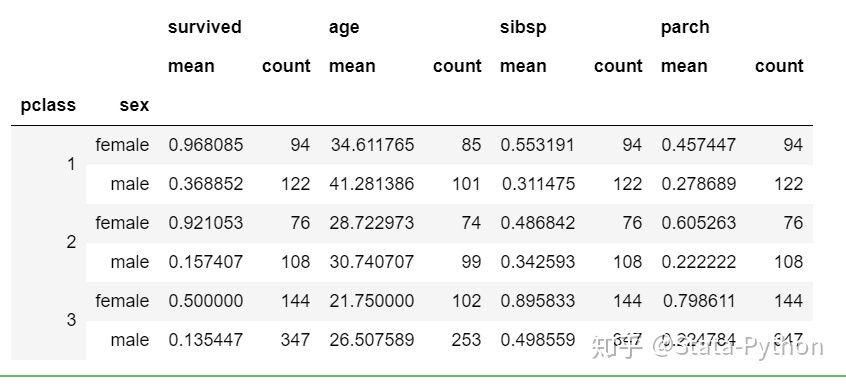

my_group2=titanic.groupby(['pclass','sex'])
my_group2.agg([('均值','mean'),('计数','count')])
① 计算泰坦尼克号男性与女性的平均票价
group = df.groupby('Sex')
group.describe()
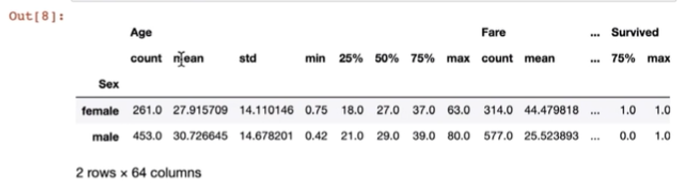
df.groupby('Sex')['Age'].describe()

df.groupby('Sex')['Age'].mean()
df.groupby('Sex')['Fare'].mean()

② 统计泰坦尼克号中男女的存活人数
survived_sex = df.groupby('Sex')['Survived'].sum()
③ 计算客舱不同等级的存活人数
survived_pclass = df.groupby('Pclass')['Survived'].sum()
这些运算可以通过 agg()函数来同时计算。并且可以使用 rename()函数修改列名。
方便同时统计多个维度的数据。否则需要经过多次的数据合并,较复杂。
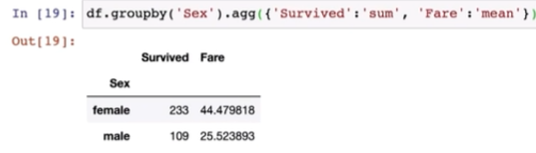
df.groupby('Pclass')['Survived'].agg('sum')
df.df.groupby('Pclass').agg({'Survived':'sum', 'Fare':'mean'})
df.df.groupby('Pclass').agg({'Survived':'sum', 'Fare':'mean'}).rename(columns = {
'Survived':'survived_sum','Fare':'fare_mean'
})
④统计在不同等级的票中的不同年龄的船票花费的平均值
df.groupby(['Pclass','Age'])['Fare'].mean()
⑤ 将①、②数据合并
result = pd.merge(means,survived_sex, on='Sex')

merge()不可以直接对Series格式的数据进行拼接,需要转为DataFrame格式
survived_sex.to_frame()
⑥ 得出不同年龄的总的存活人数,然后找出存活人数最多的年龄段,最后计算存活人数最高的存活率(存活人数/总人数)
survived_age = df.groupby('Age')['Survived'].sum()
survived_age[survived_age.values == survived_age.max()]
_sum = df['Survived'].sum()
percent =survived_age.max()/_su
Original: https://blog.csdn.net/hhhhh601/article/details/121986788
Author: yijia7590jfz
Title: 【TL第二期】动手学数据分析-第二章 数据预处理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/755226/
转载文章受原作者版权保护。转载请注明原作者出处!