

一、前言
一般情况下,numpy总是和pandas一起出现。如果numpy处理的数据类似于list类型的话,那么pandas处理的数据就类似于dictionary类型。
二、前提准备
使用pandas的话,需要将pandas这个第三方包,提前下载到你的python解释器中。
(1)Win + R,输入cmd,然后点击确定
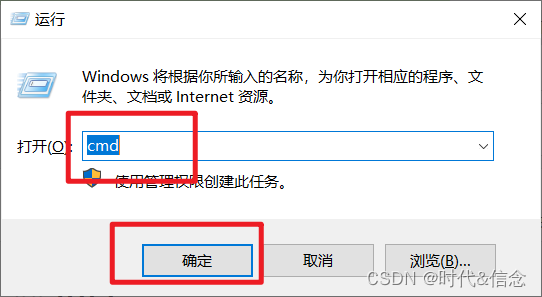

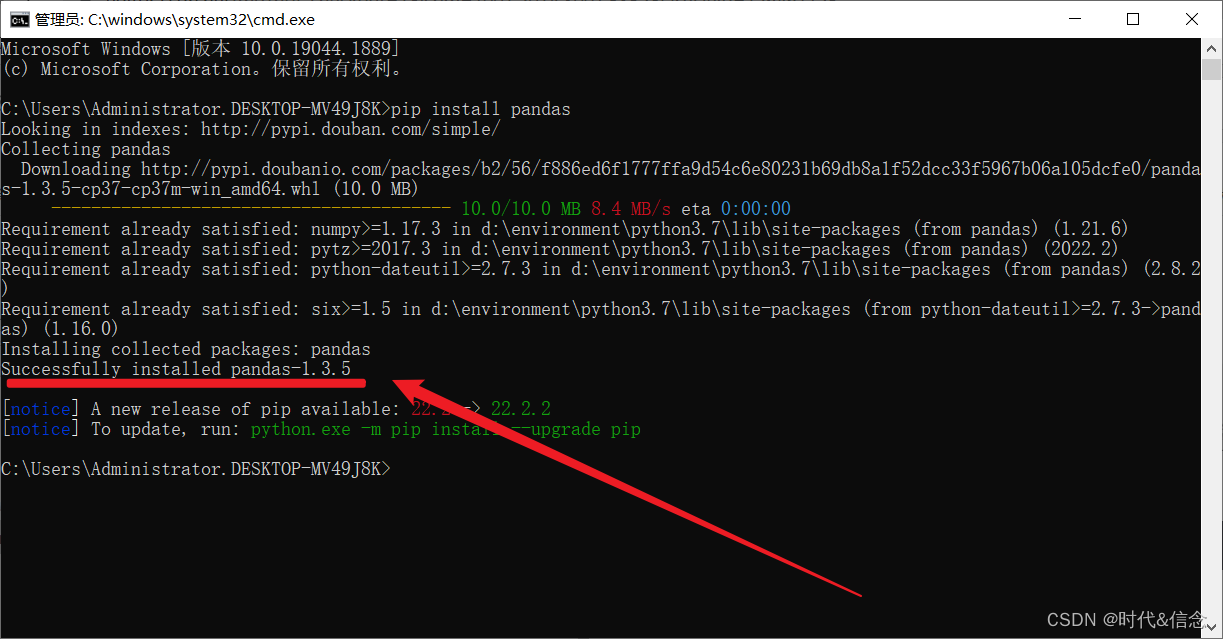
(2)在Windows的终端中输入如下命令,然后回车
pip install pandas
三、具体使用
1.基本使用
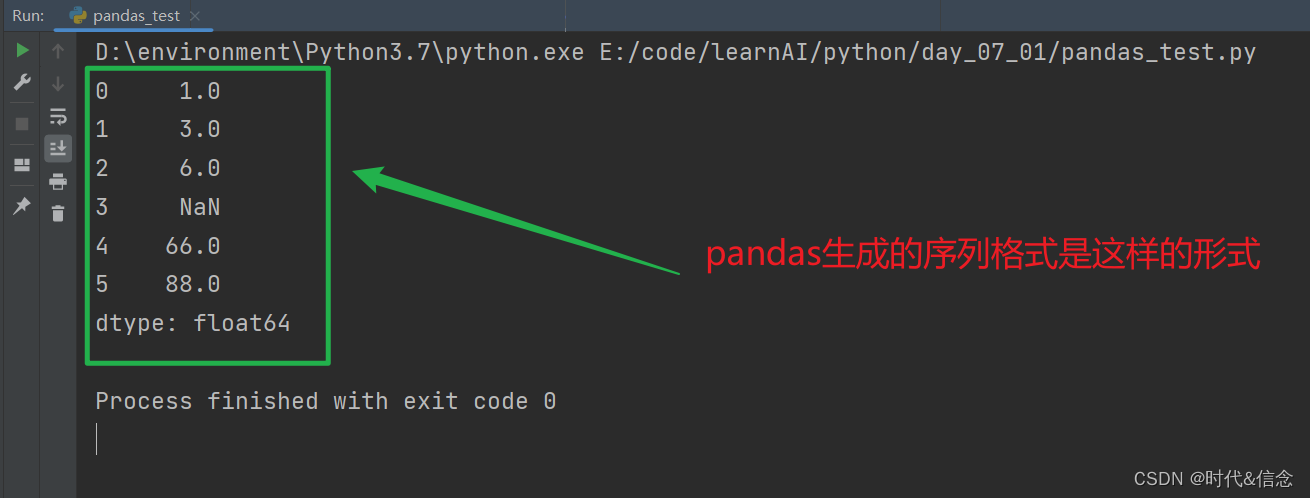
(1)使用pandas生成序列
import pandas as pd
import numpy as np
s = pd.Series([1, 3, 6, np.NAN, 66, 88])
print(s)
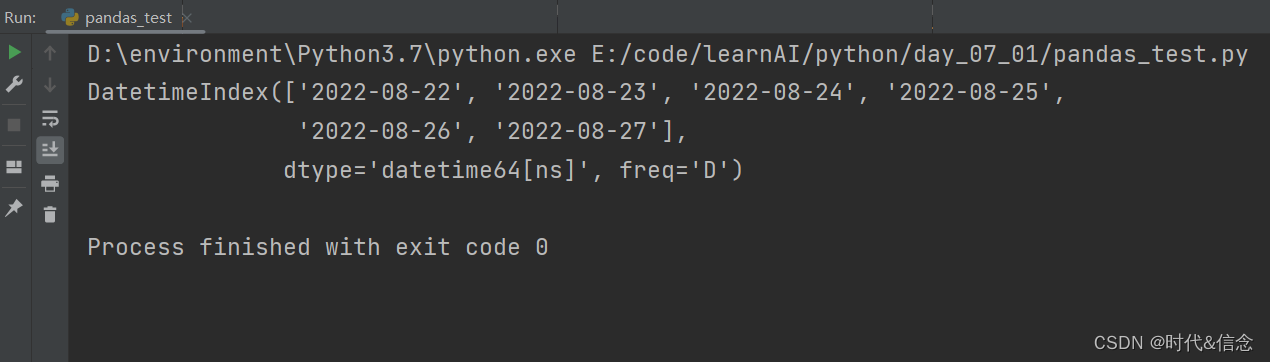
(2)生成日期序列
dates = pd.date_range('20220822', periods=6)
print(dates)
(3)生成DataFrame
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=['a', 'b', 'c', 'd'])
print(df)
print("-" * 50)
df1 = pd.DataFrame(np.arange(12).reshape((3, 4)))
print(df1)
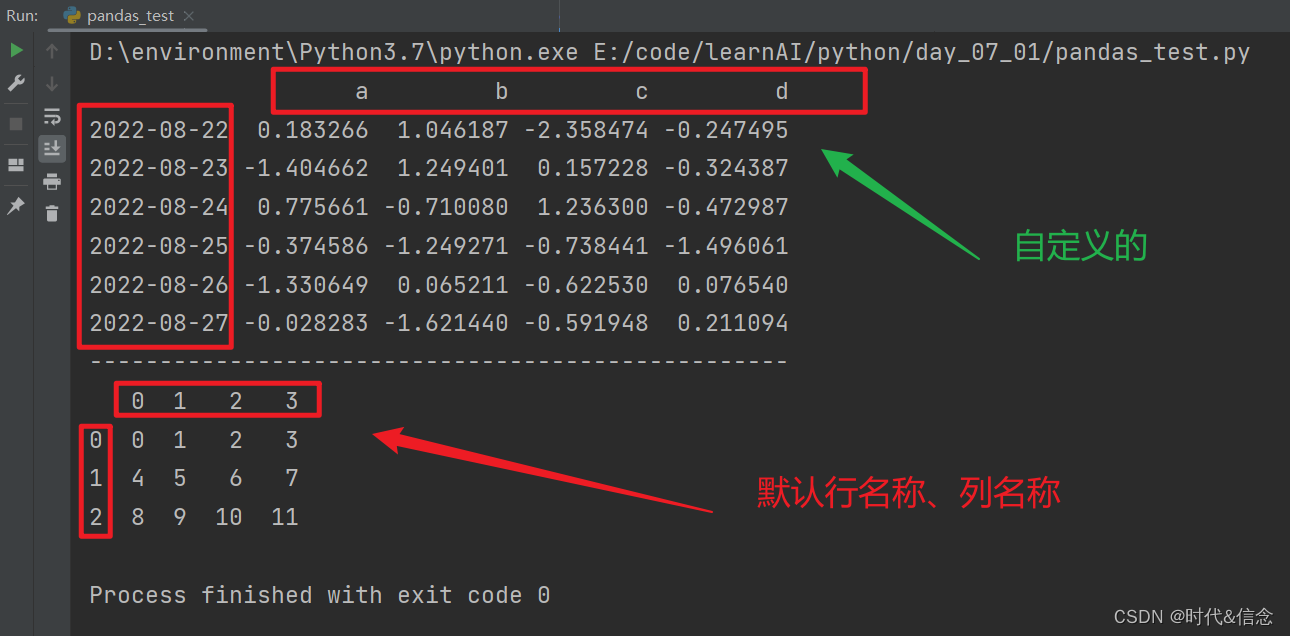
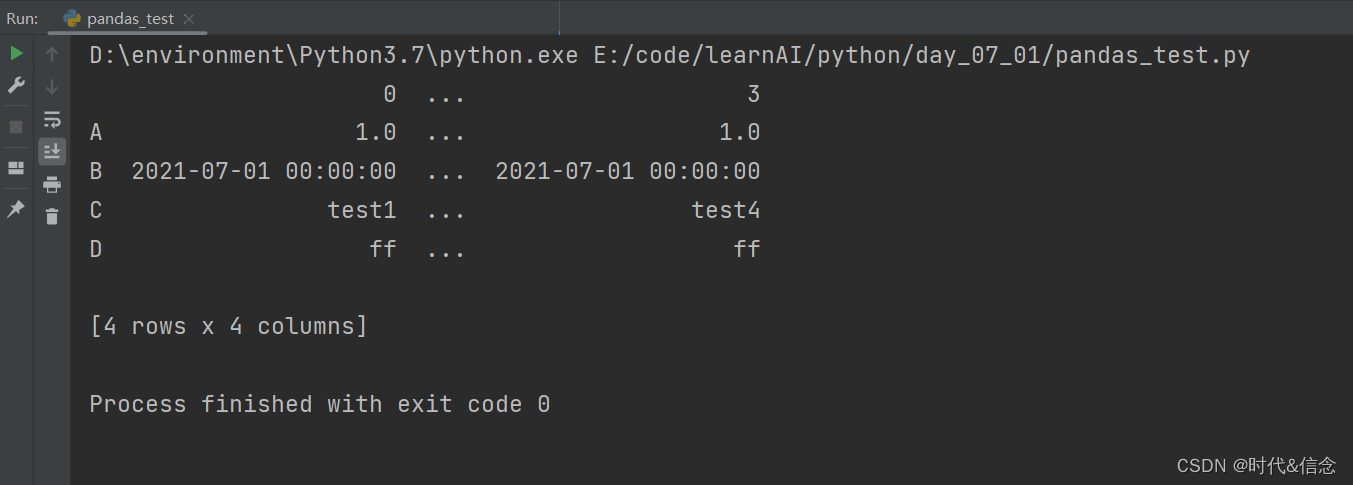
(4)使用字典参数生成DataFrame
df2 = pd.DataFrame({'A': 1.0, 'B': pd.Timestamp('20210701'),
'C': pd.Categorical(['test1', 'test2', 'test3', 'test4']), 'D': 'ff'})
print(df2)
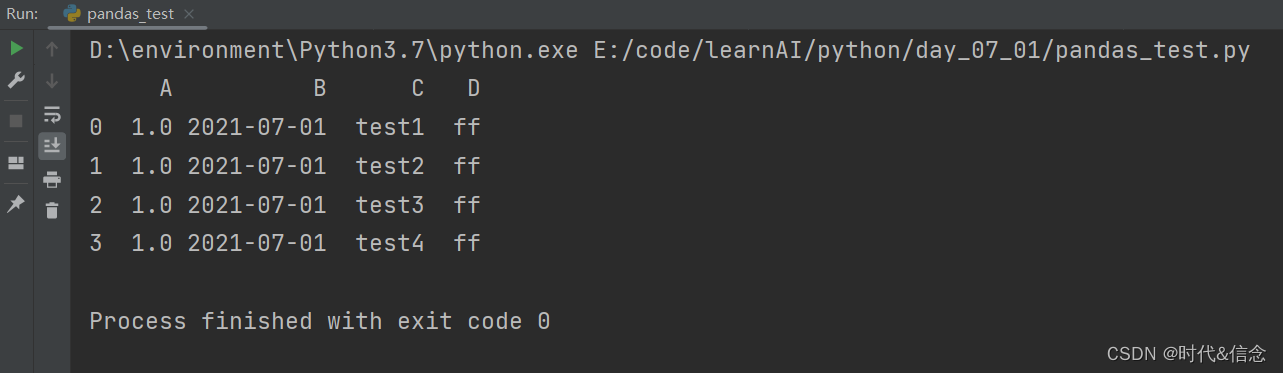
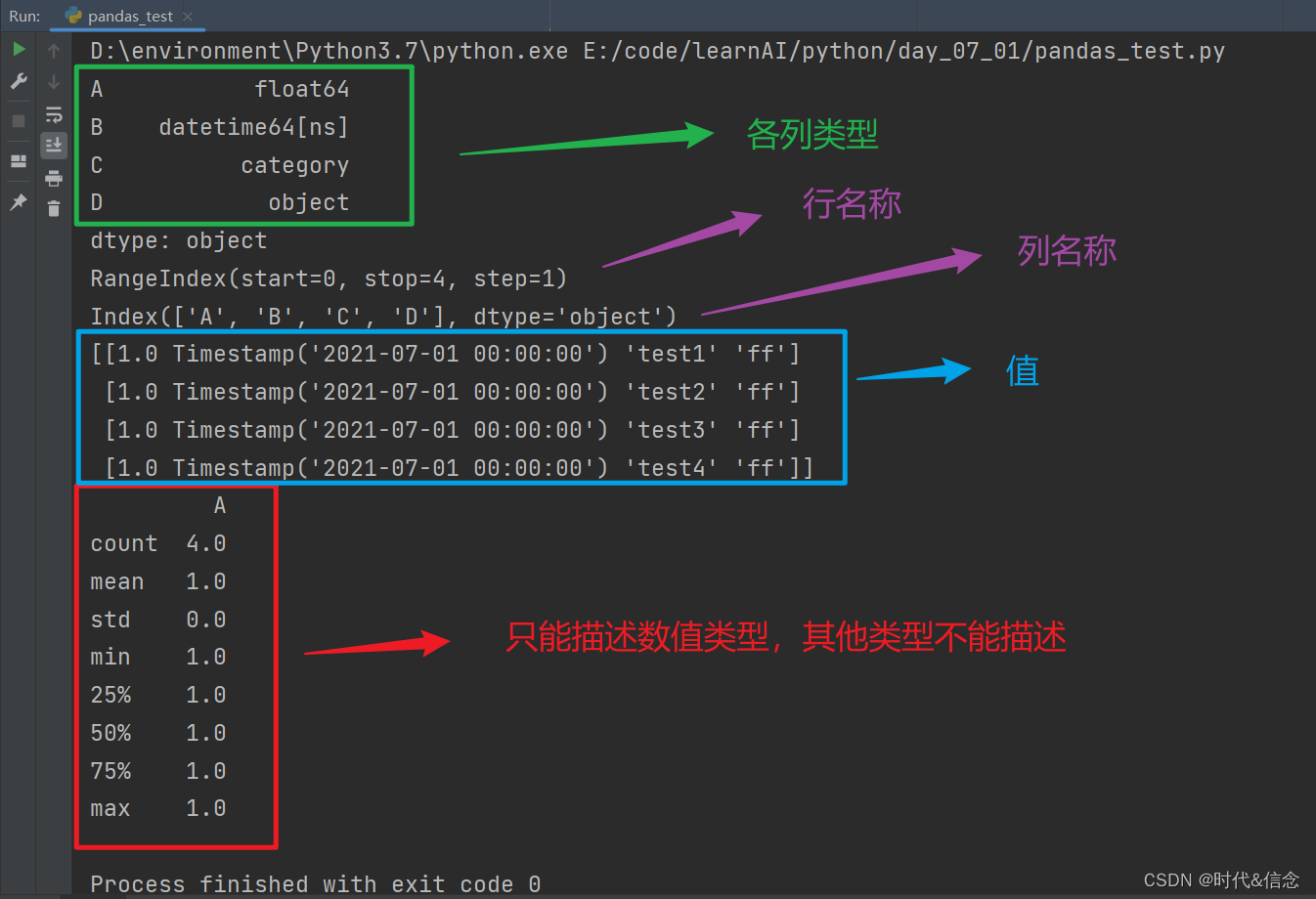
(5)Dataframe的属性
print(df2.dtypes)
print(df2.index)
print(df2.columns)
print(df2.values)
print(df2.describe())
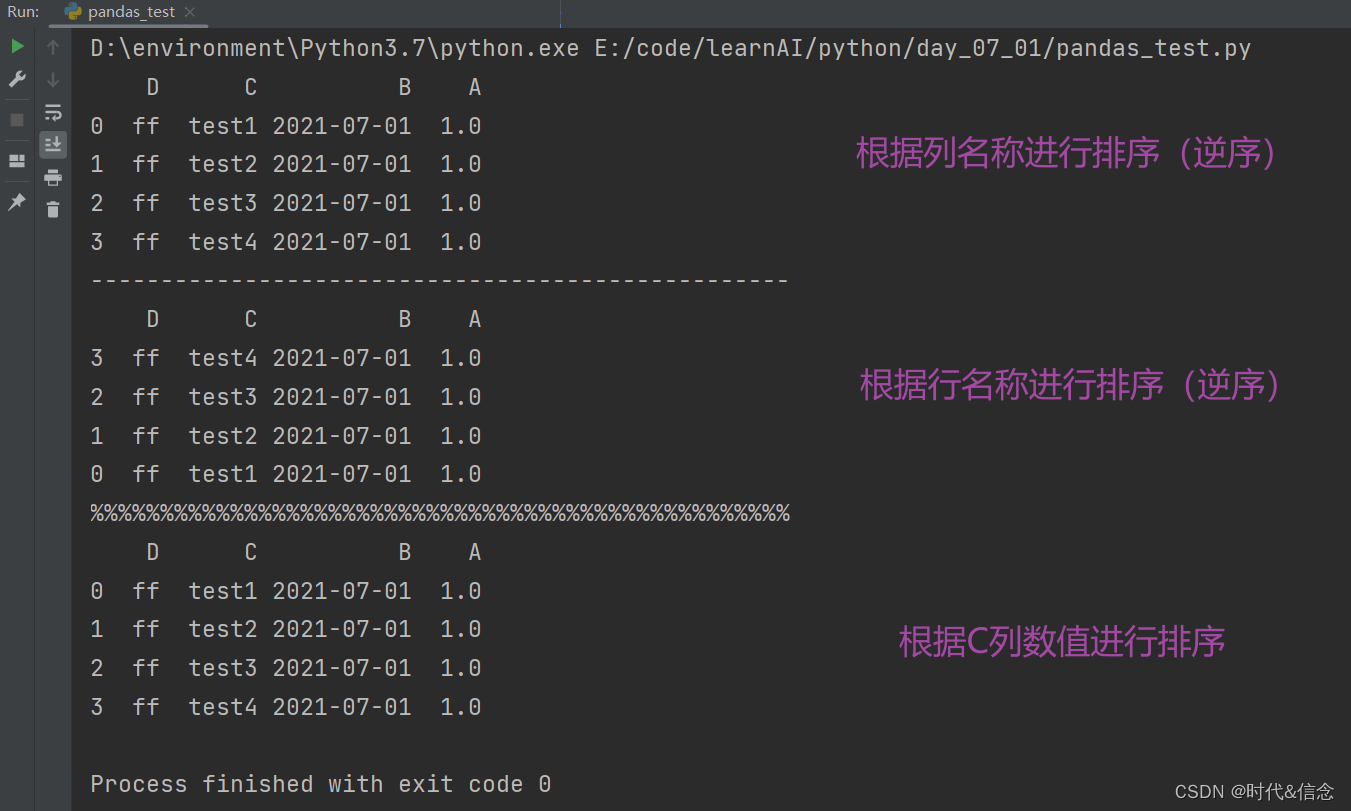
(6)在Dataframe中进行排序
df2 = df2.sort_index(axis=1, ascending=False)
print(df2)
print("-" * 50)
df2 = df2.sort_index(axis=0, ascending=False)
print(df2)
print("%" * 50)
df2 = df2.sort_values(by='C')
print(df2)
(7)对Dataframe进行转置
print(df2.T)
2.选择数据
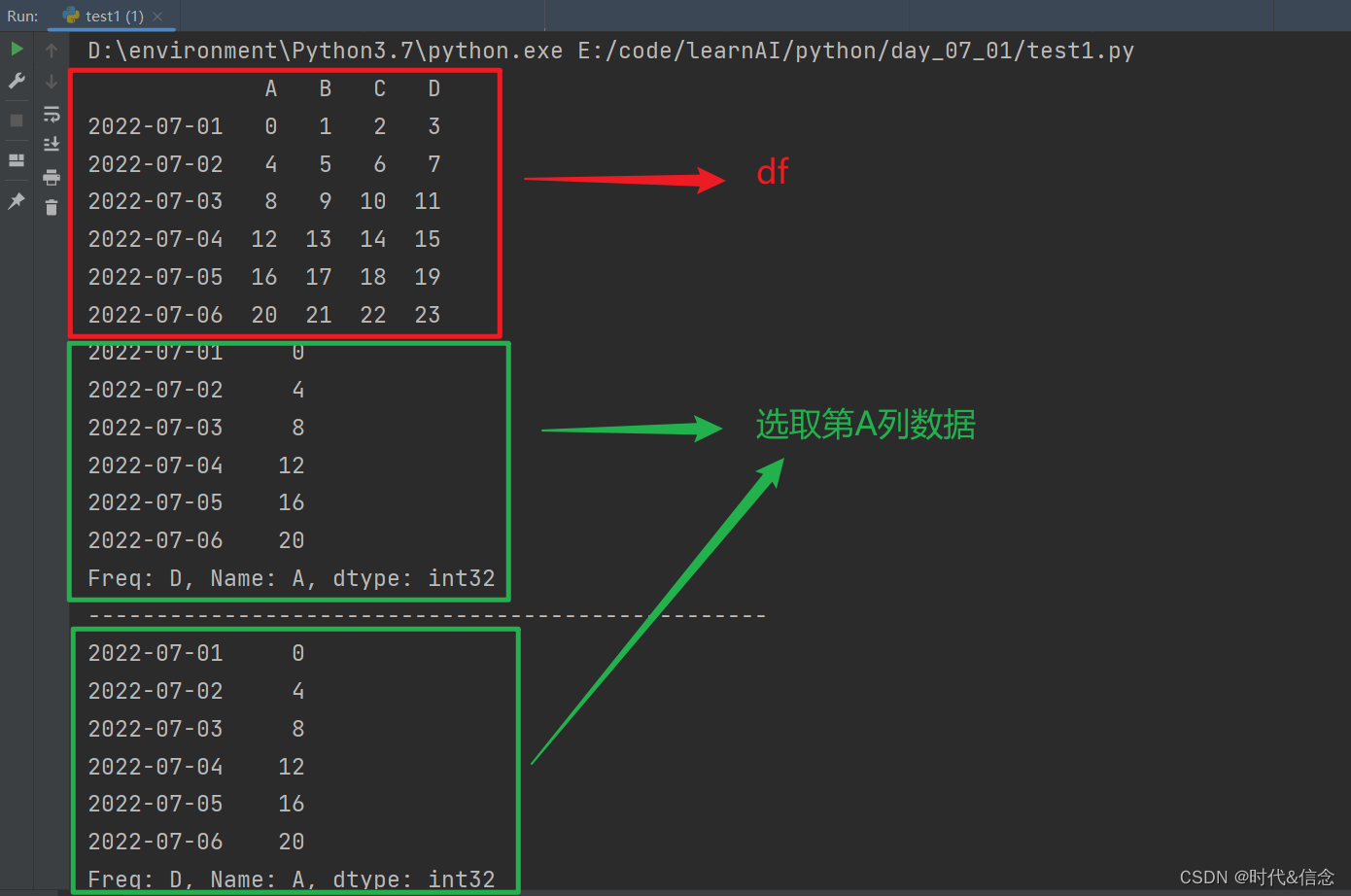
(1)选择列
import numpy as np
import pandas as pd
"""
pandas从DateFrame中选取一行
"""
dates = pd.date_range('2022.07.01', periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)), index=dates, columns=['A', 'B', 'C', 'D'])
print(df)
print(df.A)
print("-" * 50)
print(df['A'])
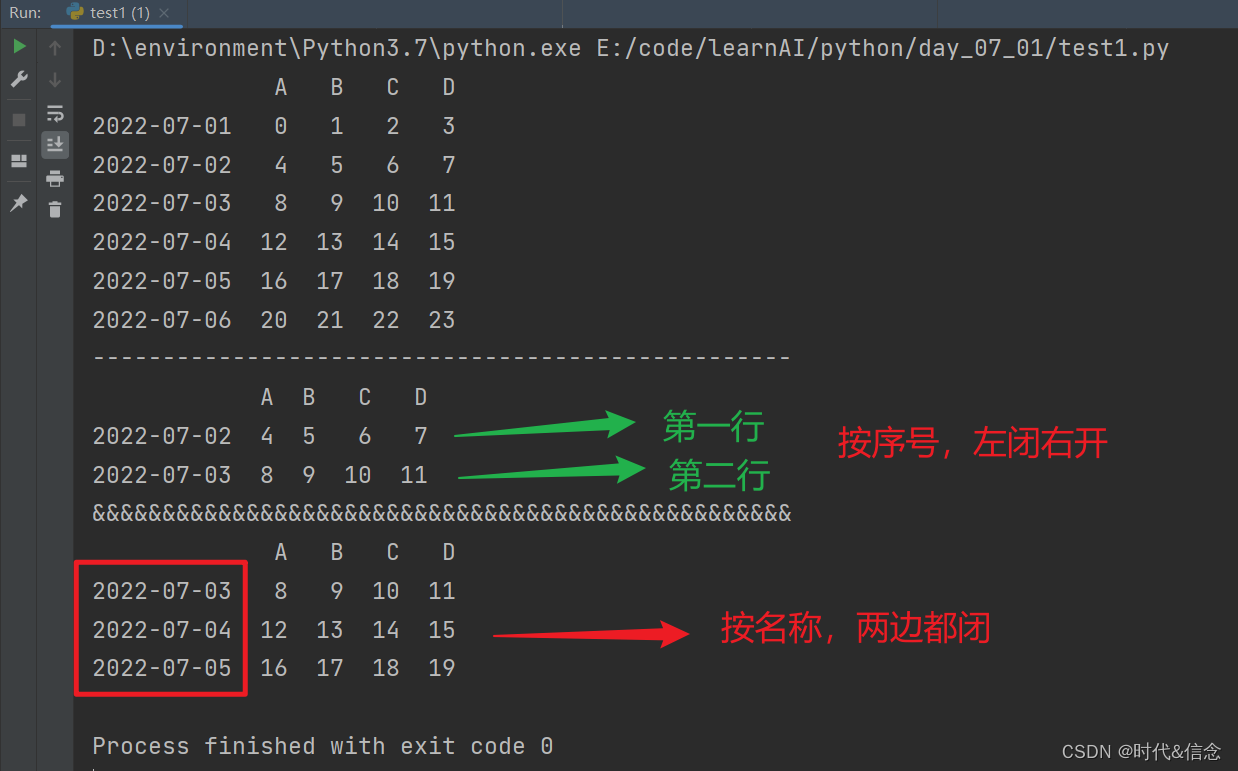
(2)通过”切片”选择数据
print("-" * 50)
print(df[1:3])
print("&" * 50)
print(df['20220703':'20220705'])
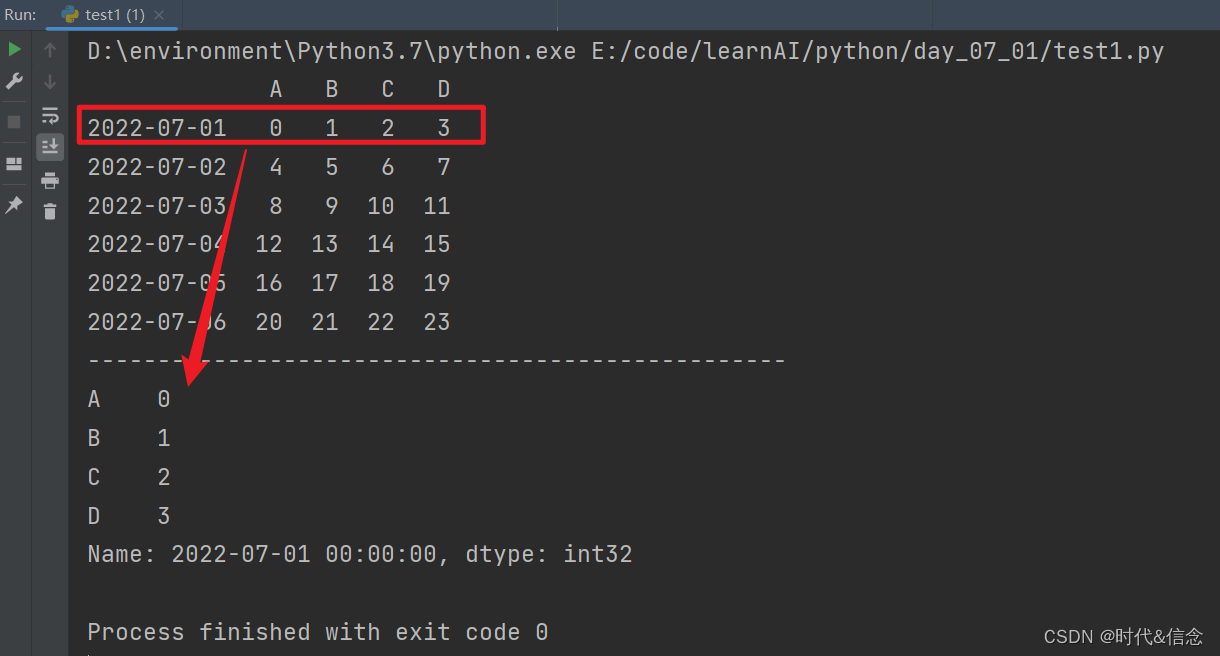
(3)根据标签进行选择数据
print("-" * 50)
print(df.loc['20220701'])
print("-" * 50)
print(df.loc[:, ['B', 'C']])
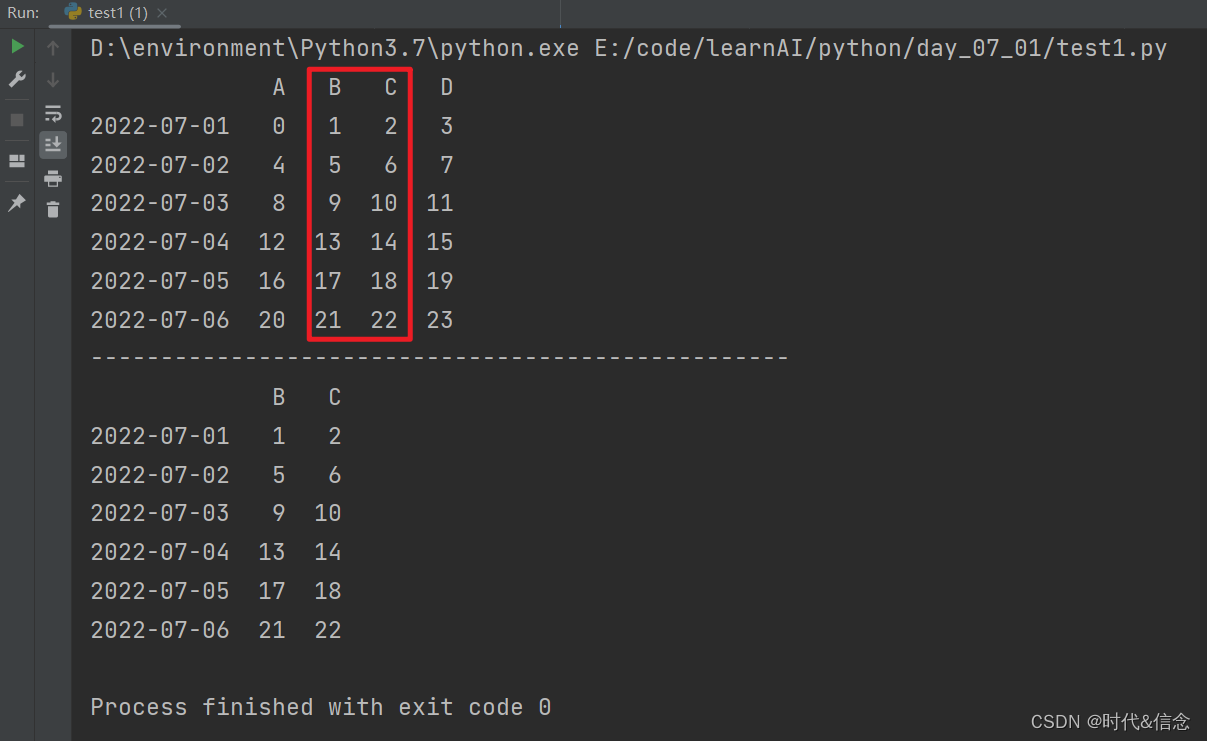
print("-" * 50)
print(df.loc["20220702", ['C', 'D']])
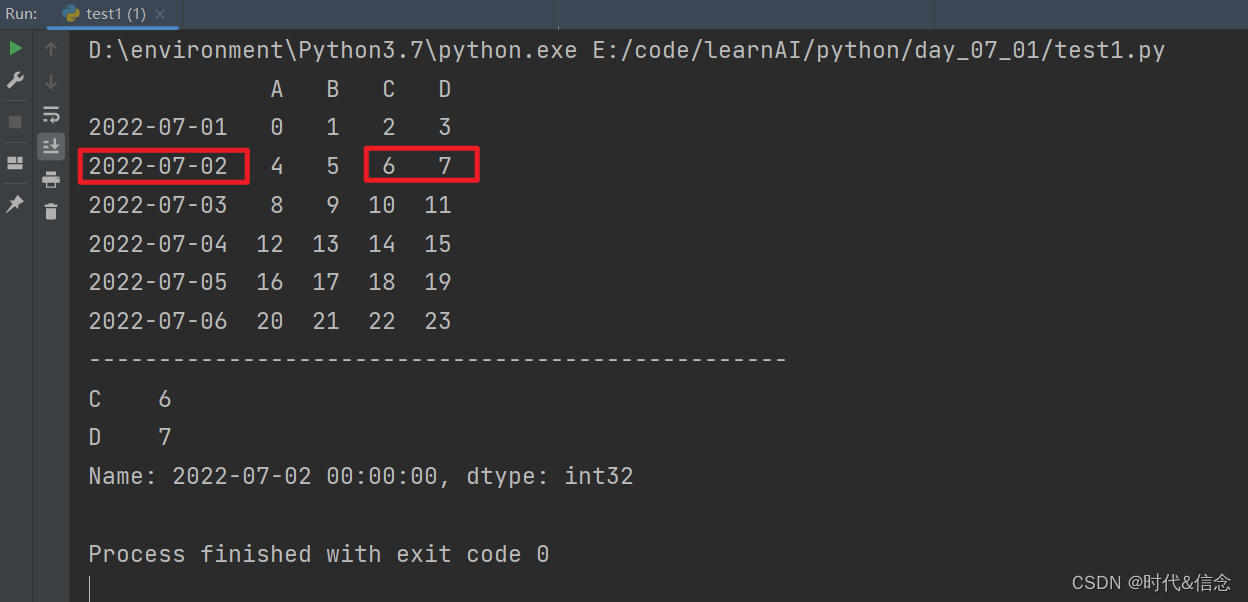
(4)根据位置选择数据
print("-" * 50)
print(df.iloc[3])
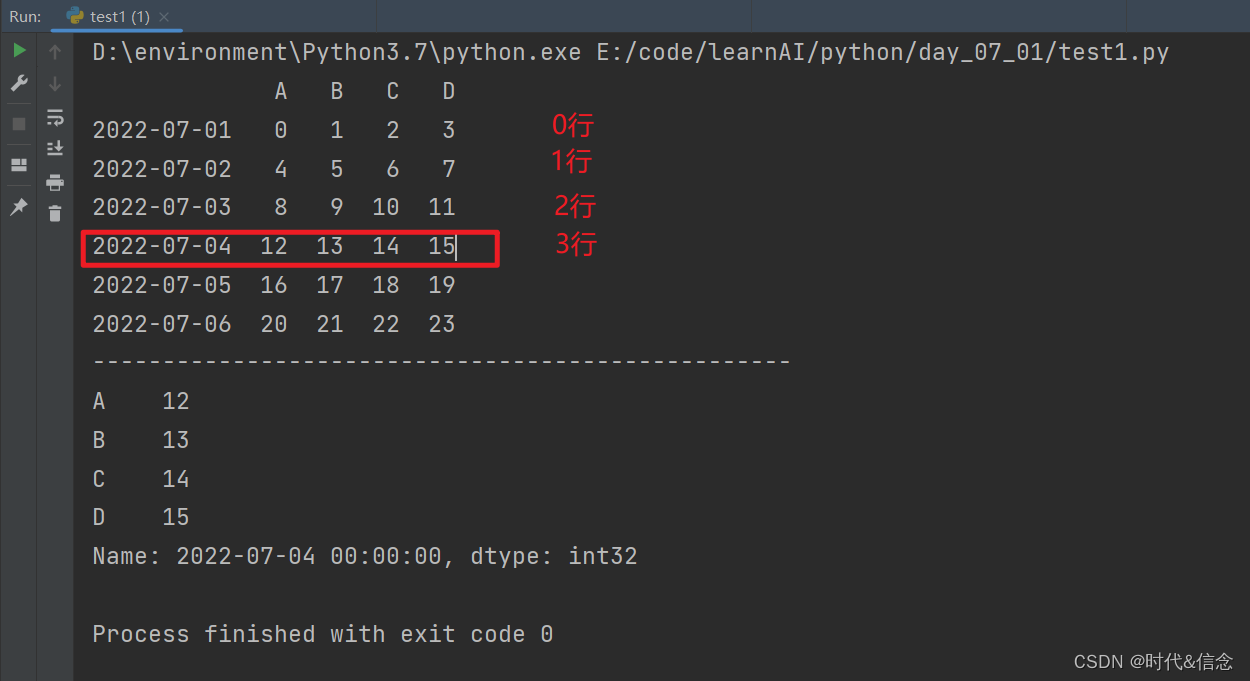
print("-" * 50)
print(df.iloc[[1,3,5], 1:3])
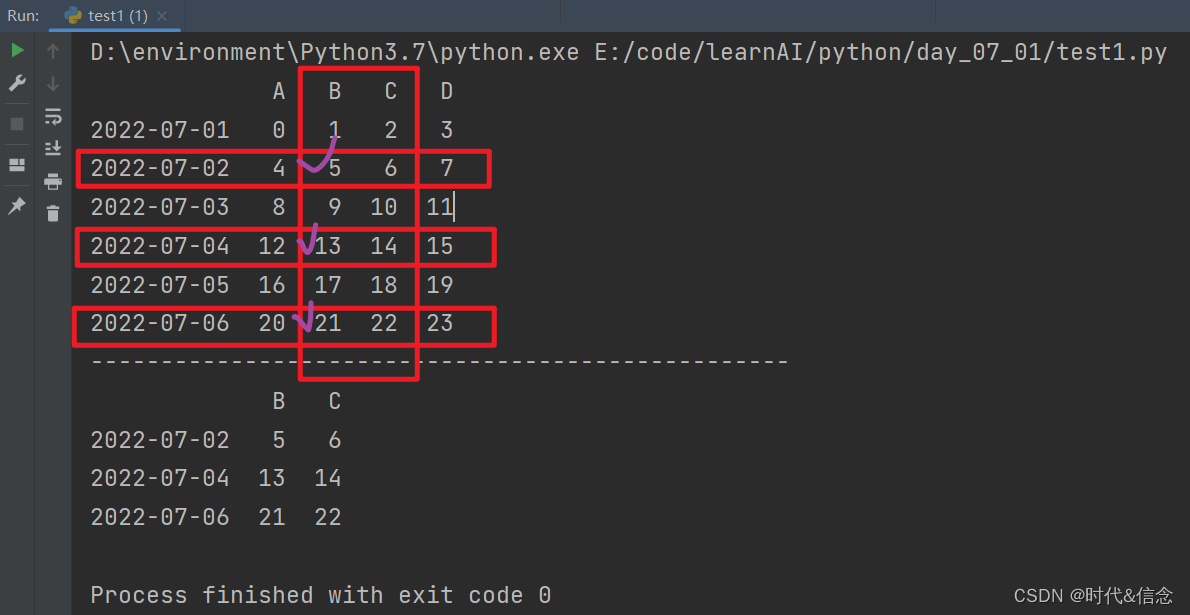
(5)根据条件进行选择数据
print("-" * 50)
print(df[df.A > 8])
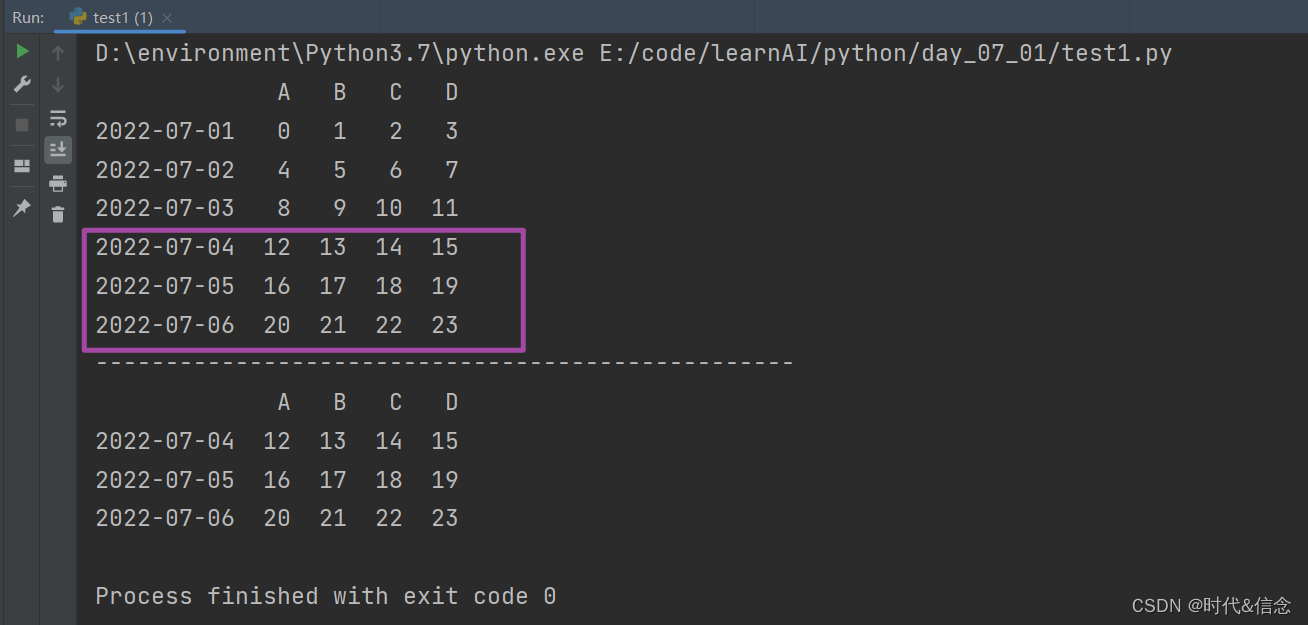
3. 设置值
设置值的本质就是:先选择数据,然后再赋值
(1)通过位置选择数据,然后改变数据
import numpy as np
import pandas as pd
"""
在指定位置进行替换值
"""
dates = pd.date_range('20220701', periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)), index=dates, columns=['A', 'B', 'C', 'D'])
print(df)
df.iloc[2, 2] = 666
print("-" * 50)
print(df)
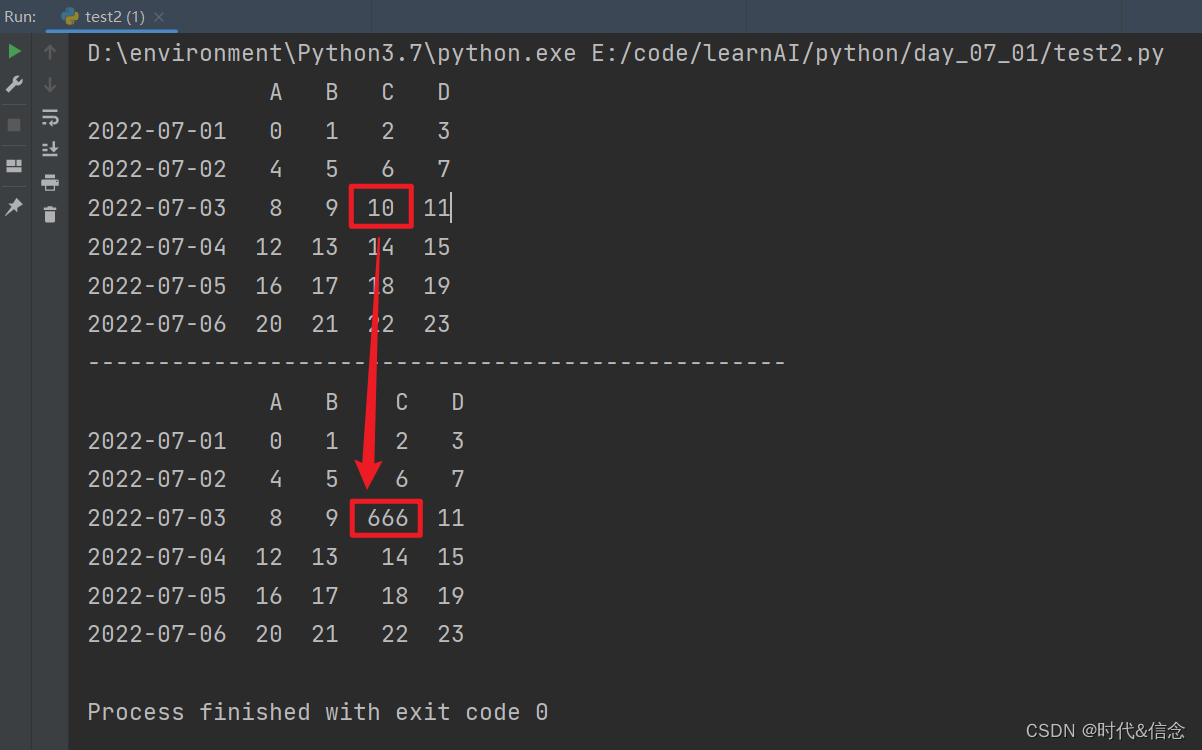
(2)通过标签选择数据,然后改变数据
df.loc['20220701', 'B'] = 999
print("-" * 50)
print(df)
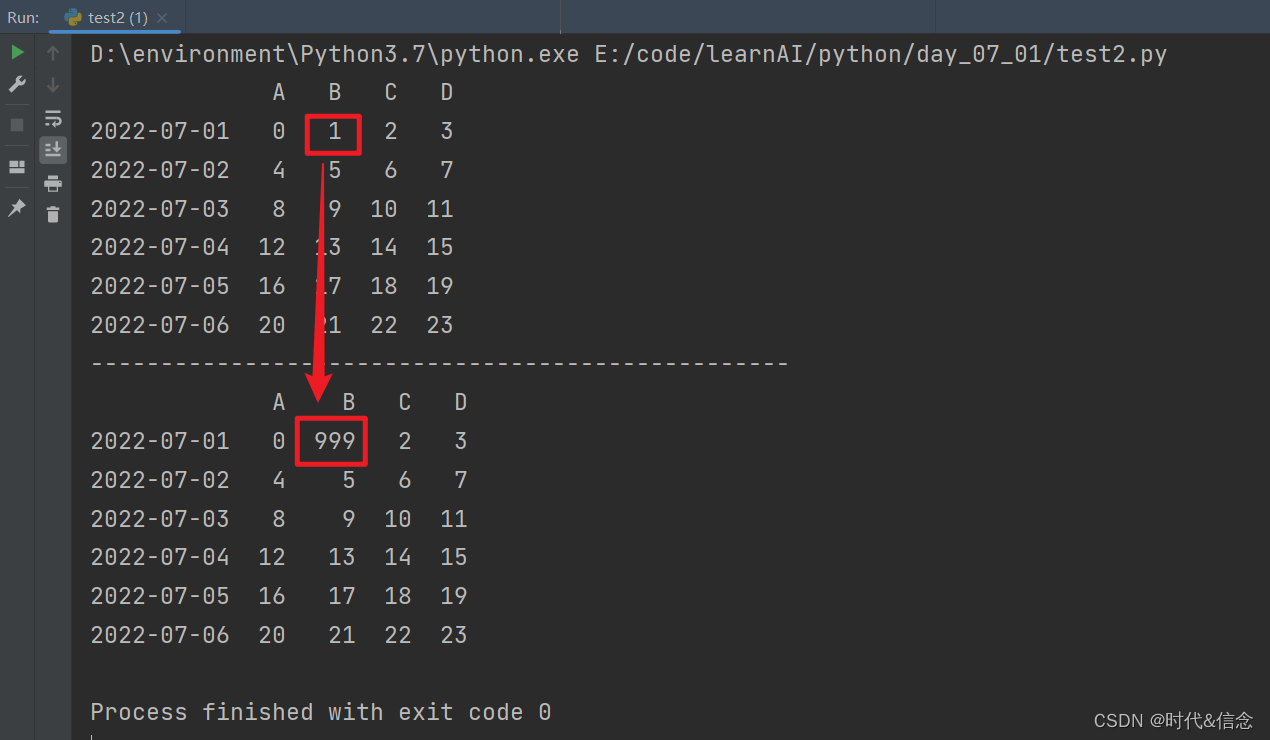
(3)通过选择列选择数据,然后改变数据
df['D'] = np.NAN
print(df)
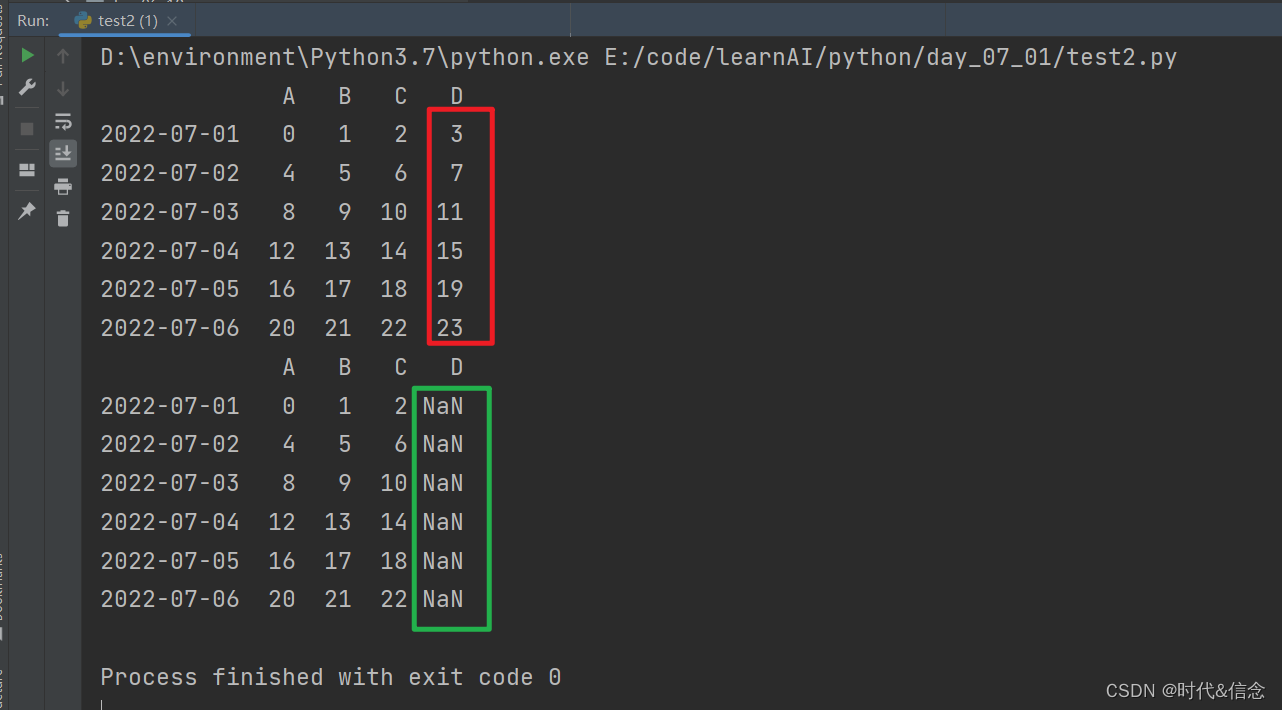
(4)给Dataframe新加一列
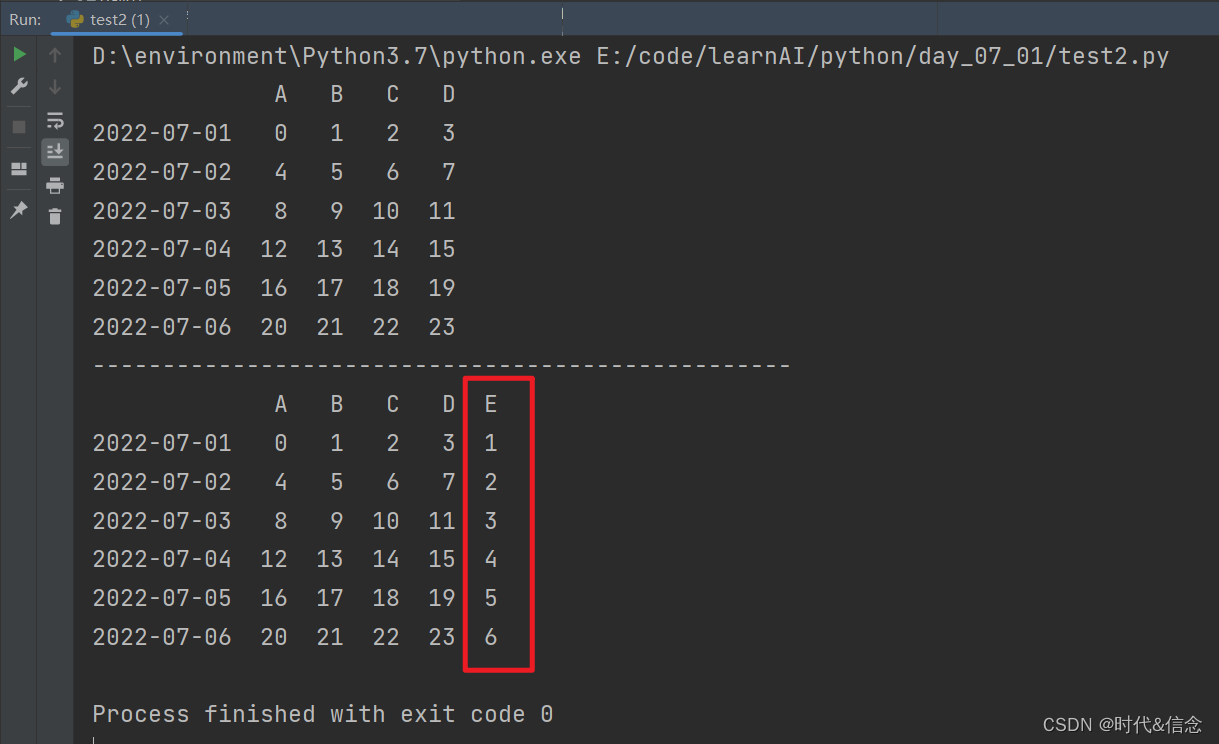
df['E'] = pd.Series([1, 2, 3, 4, 5, 6], index=pd.date_range('20220701', periods=6))
print("-" * 50)
print(df)
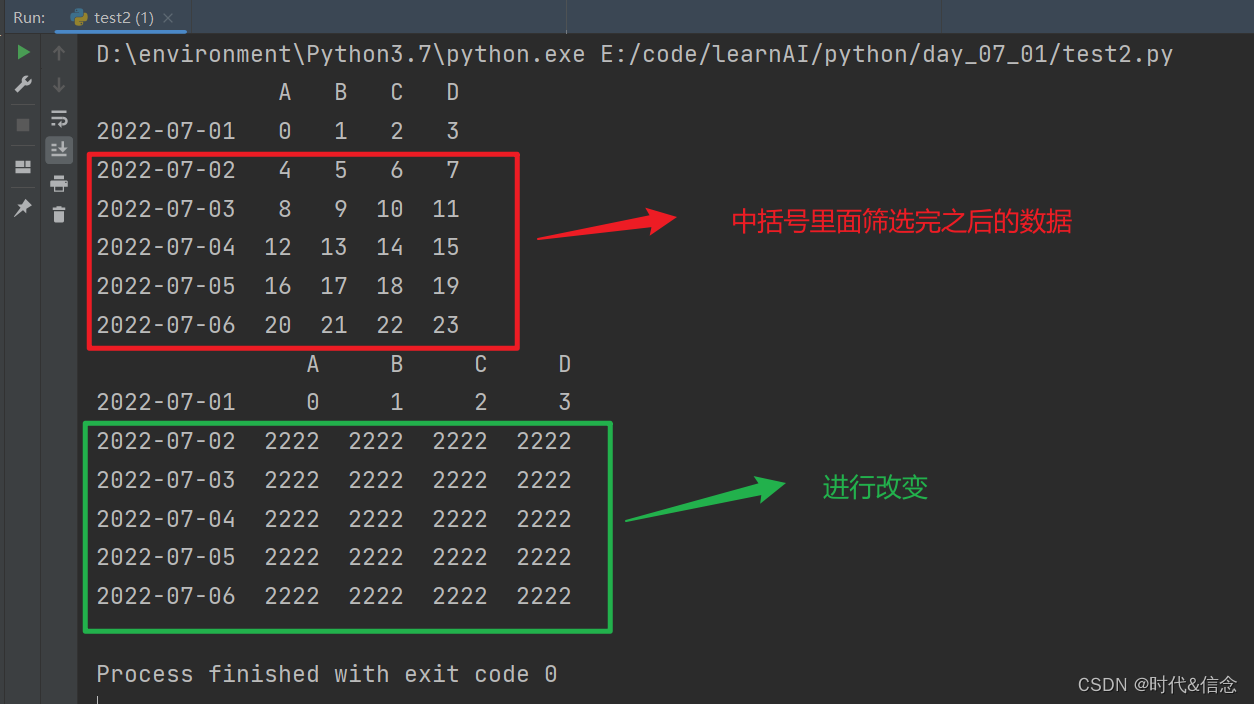
(5)通过条件选择数据,然后改变数据
df[df.A > 0] = 2222
print(df)
4.处理丢失数据
(1)丢弃NaN值
import numpy as np
import pandas as pd
dates = pd.date_range('20220701', periods=6)
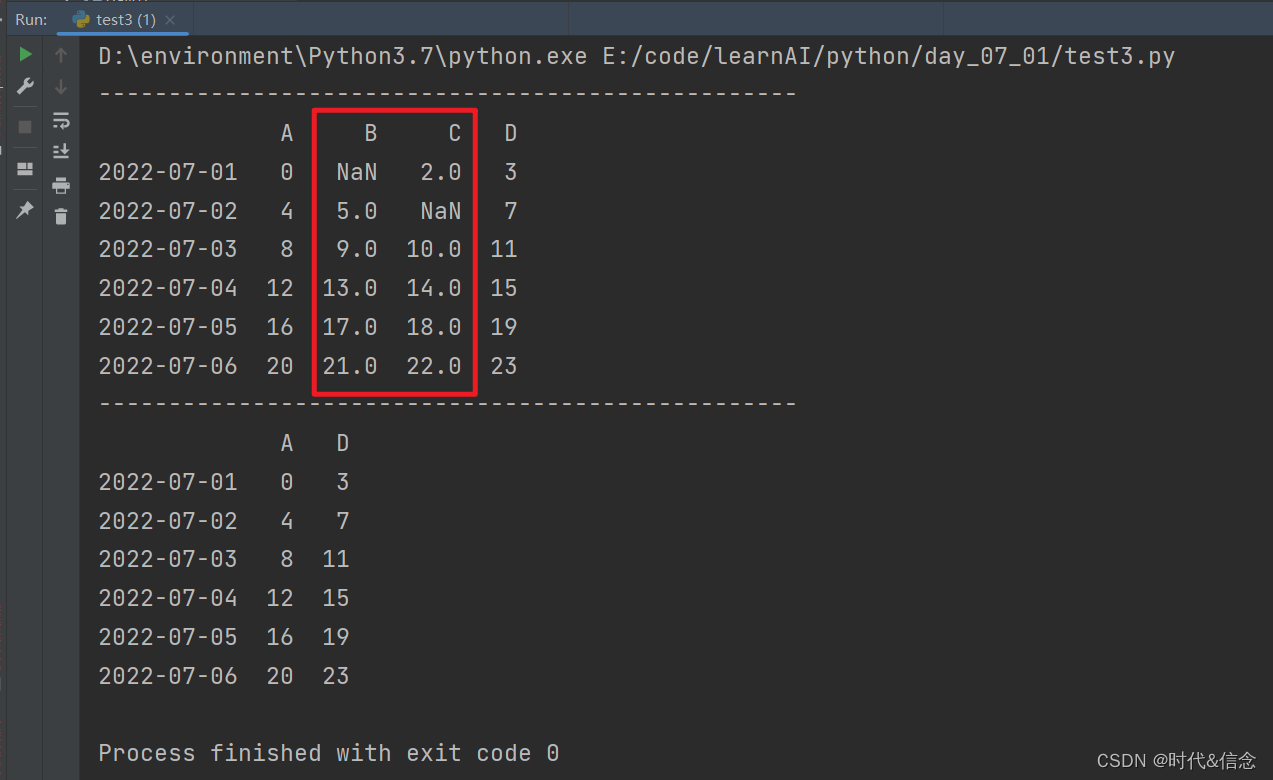
df = pd.DataFrame(np.arange(24).reshape(6, 4), index=dates, columns=['A', 'B', 'C', 'D'])
df.iloc[0, 1] = np.NAN
df.iloc[1, 2] = np.NAN
print("-" * 50)
print(df)
"""
丢弃nan
"""
df = df.dropna(axis=1, how='any')
print("-" * 50)
print(df)
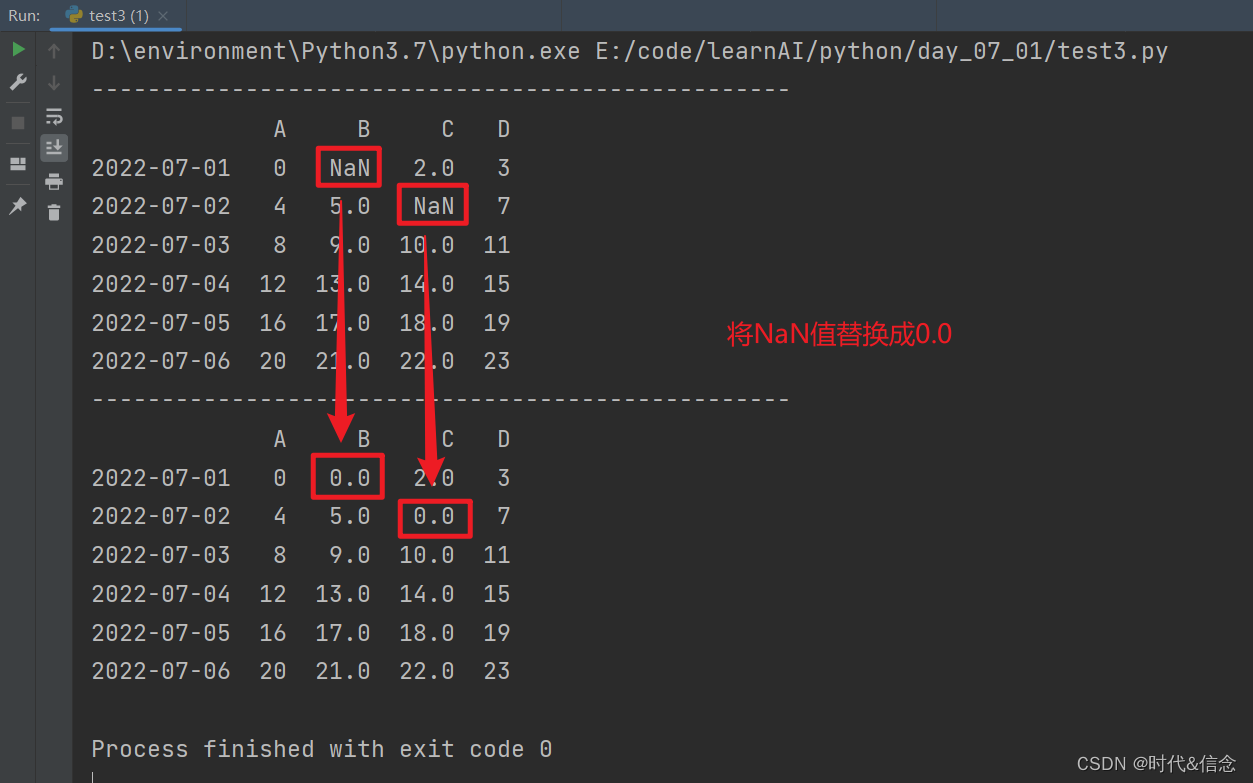
(2)替换NaN值
"""
替换nan
"""
print(df.fillna(value=0))
(3)判断df的各个位置上是否缺失数据
print(df.isnull())
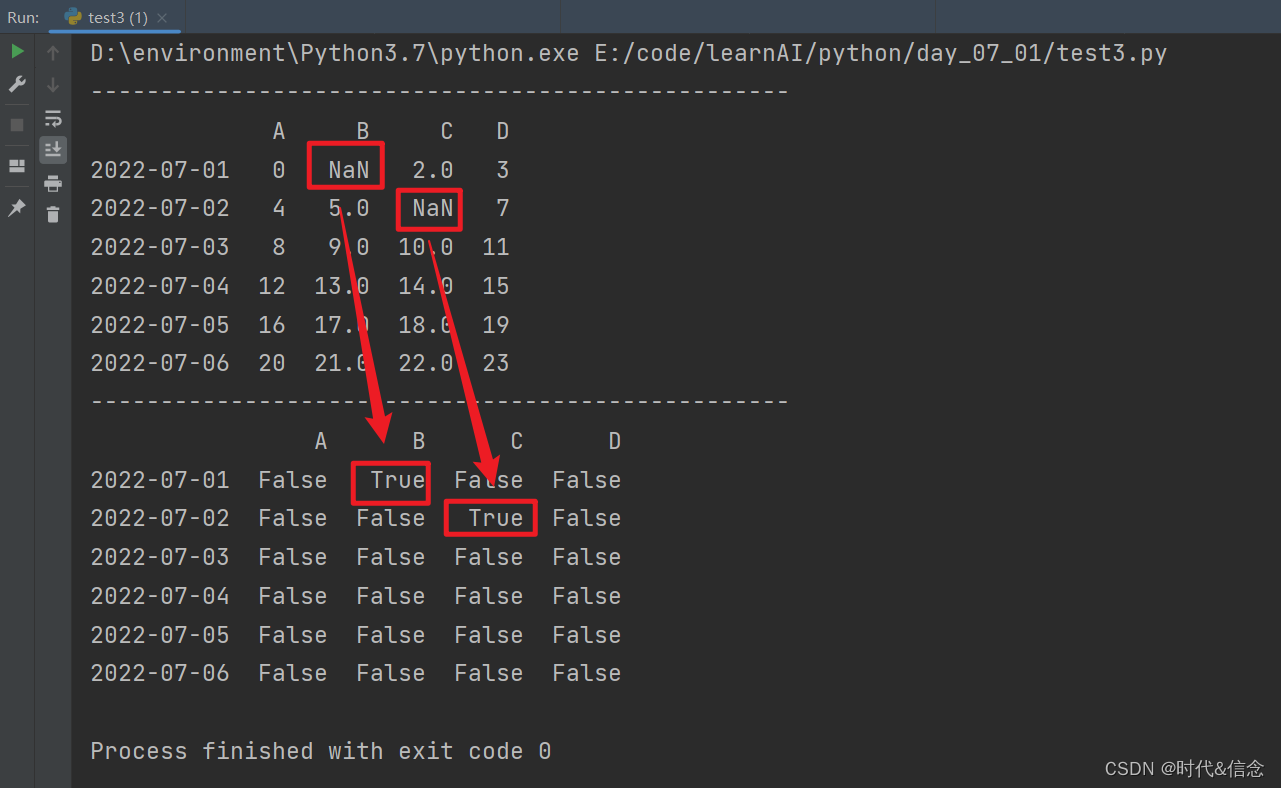
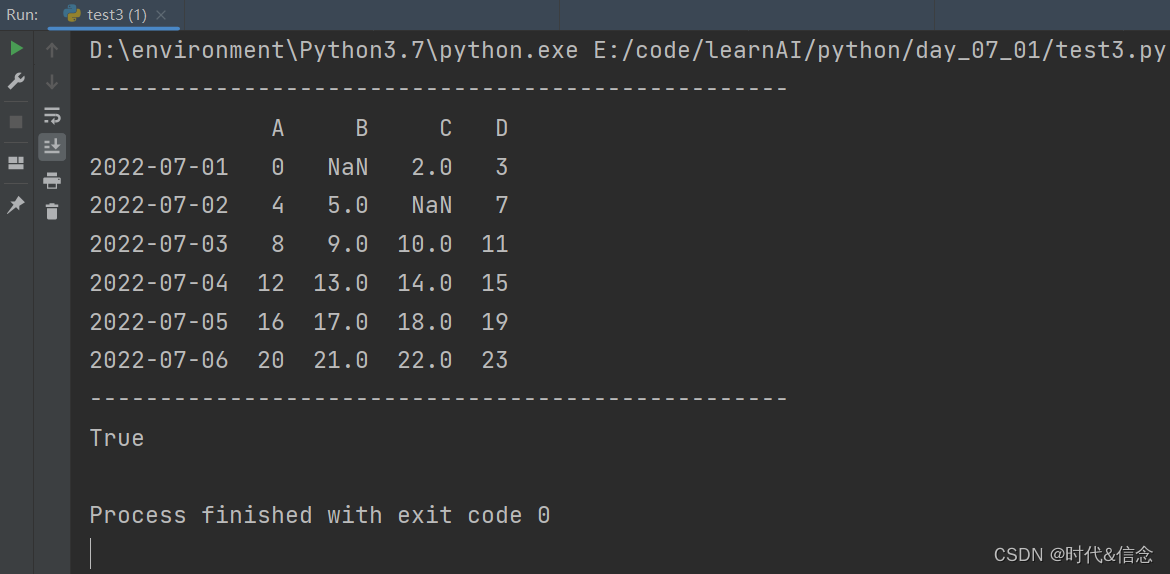
(4)判断df中是否存在NaN值
print("-" * 50)
print(np.any(df.isnull()) == True)
5.导入导出数据
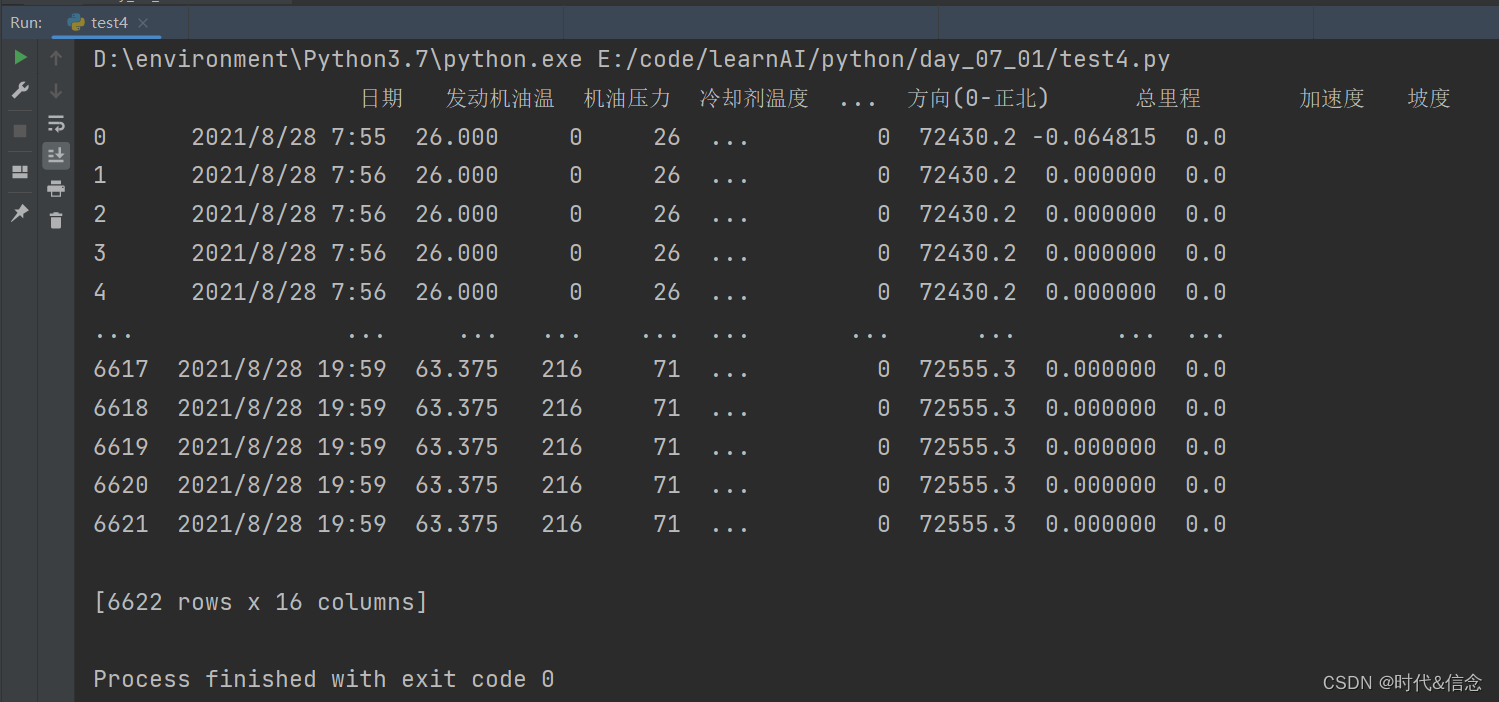
(1)读取数据
import numpy as np
import pandas as pd
"""
用pandas导入导出数据
"""
data = pd.read_csv("AAH691(2).csv", encoding='gb18030')
print(data)
(2)存储数据
data.to_pickle('test.pickle')
6.使用contact合并Dataframe
(1)contact竖直方向合并
import numpy as np
import pandas as pd
"""
pandas中的合并
"""
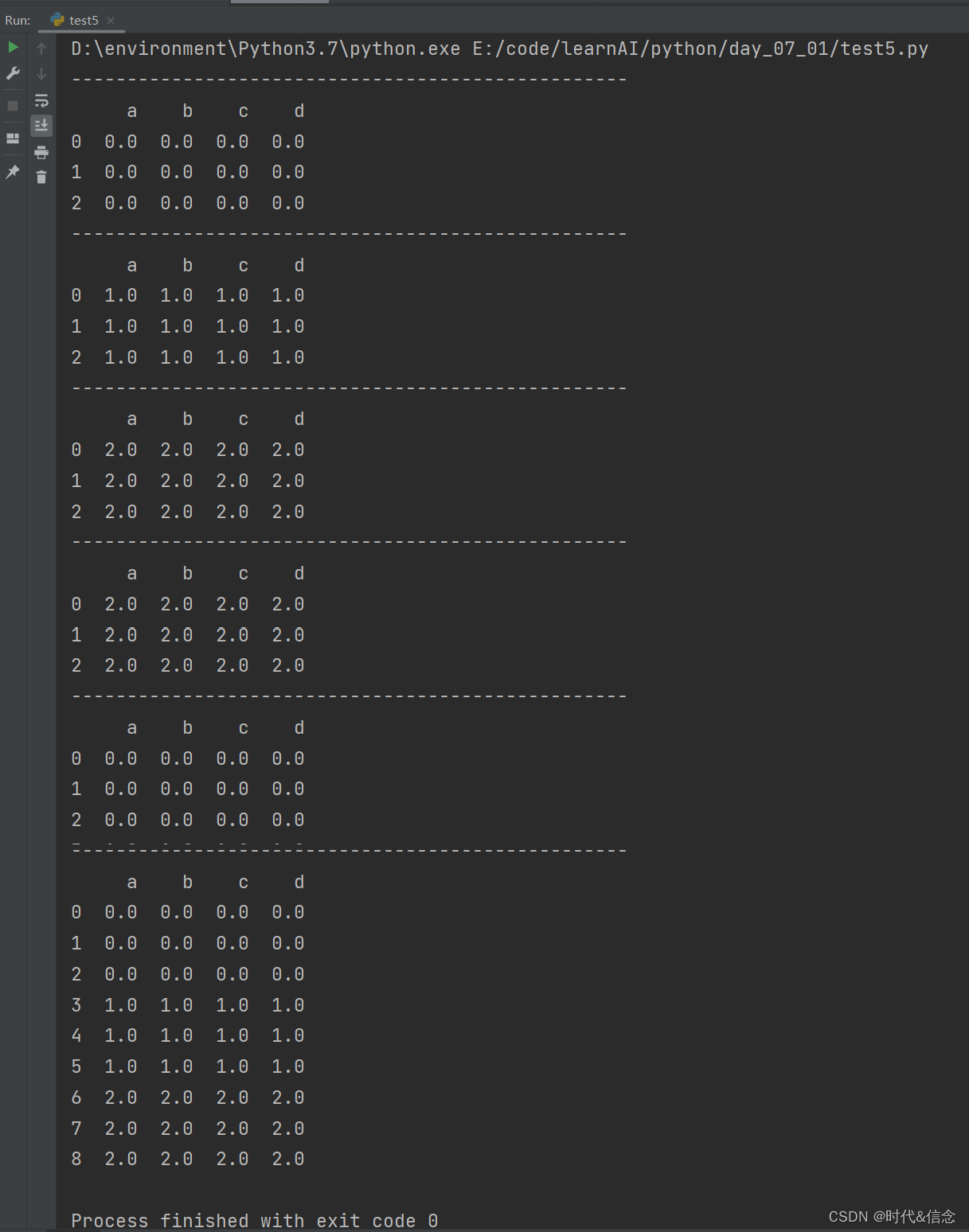
df1 = pd.DataFrame(np.ones((3, 4))*0, columns=['a', 'b', 'c', 'd'])
df2 = pd.DataFrame(np.ones((3, 4))*1, columns=['a', 'b', 'c', 'd'])
df3 = pd.DataFrame(np.ones((3, 4))*2, columns=['a', 'b', 'c', 'd'])
print("-" * 50)
print(df1)
print("-" * 50)
print(df2)
print("-" * 50)
print(df3)
print("-" * 50)
res = pd.concat([df1, df2, df3], axis=0, ignore_index=True)
print(res)
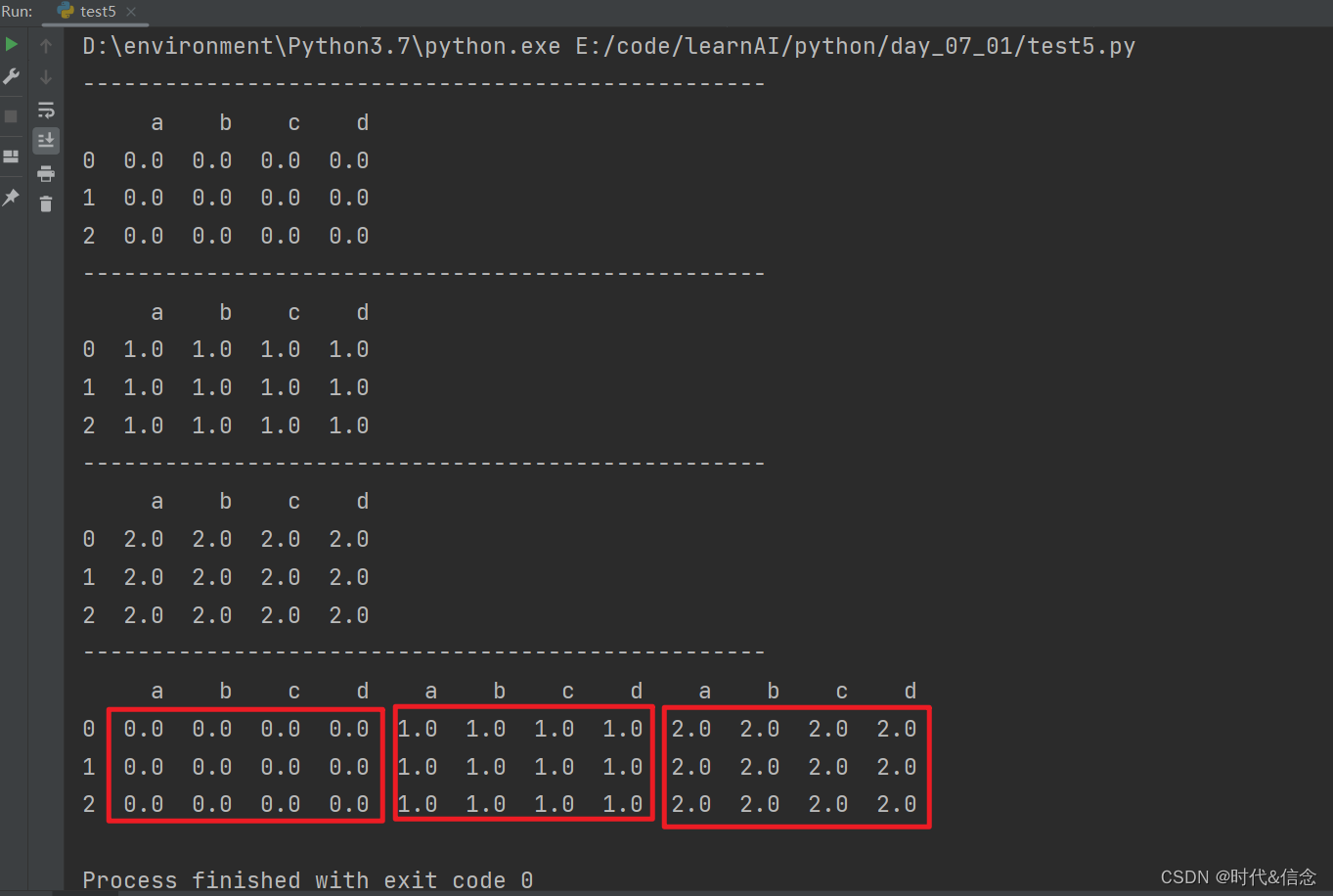
(2)contact水平方向合并
print("-" * 50)
res = pd.concat([df1, df2, df3], axis=1)
print(res)
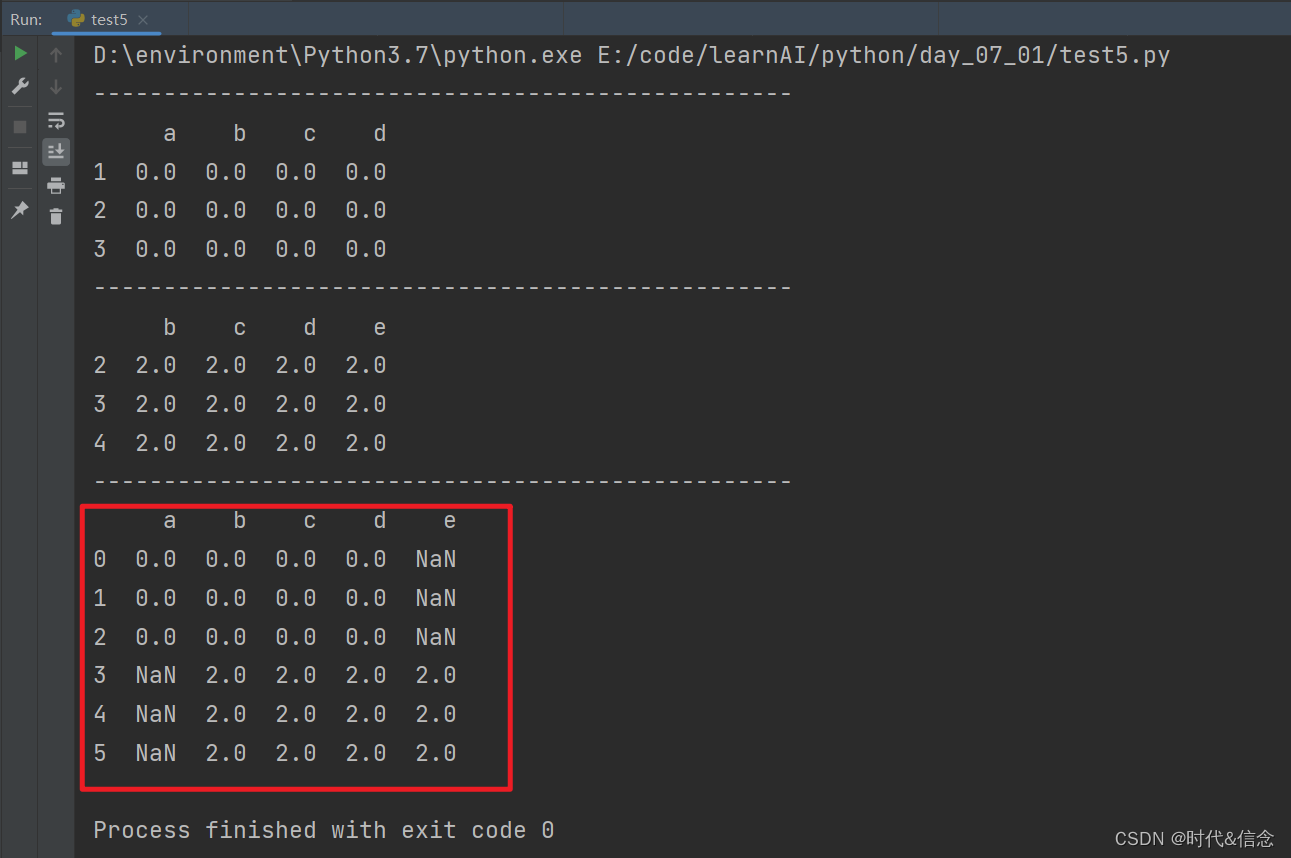
(3)outer方式合并
print("-" * 50)
df1 = pd.DataFrame(np.ones((3, 4))*0, columns=['a', 'b', 'c', 'd'], index=[1, 2, 3])
df2 = pd.DataFrame(np.ones((3, 4))*2, columns=['b', 'c', 'd', 'e'], index=[2, 3, 4])
print(df1)
print("-" * 50)
print(df2)
res = pd.concat([df1, df2], join="outer", ignore_index=True)
print("-" * 50)
print(res)
(4)inner方式合并
res = pd.concat([df1, df2], join="inner", ignore_index=True)
print("-" * 50)
print(res)
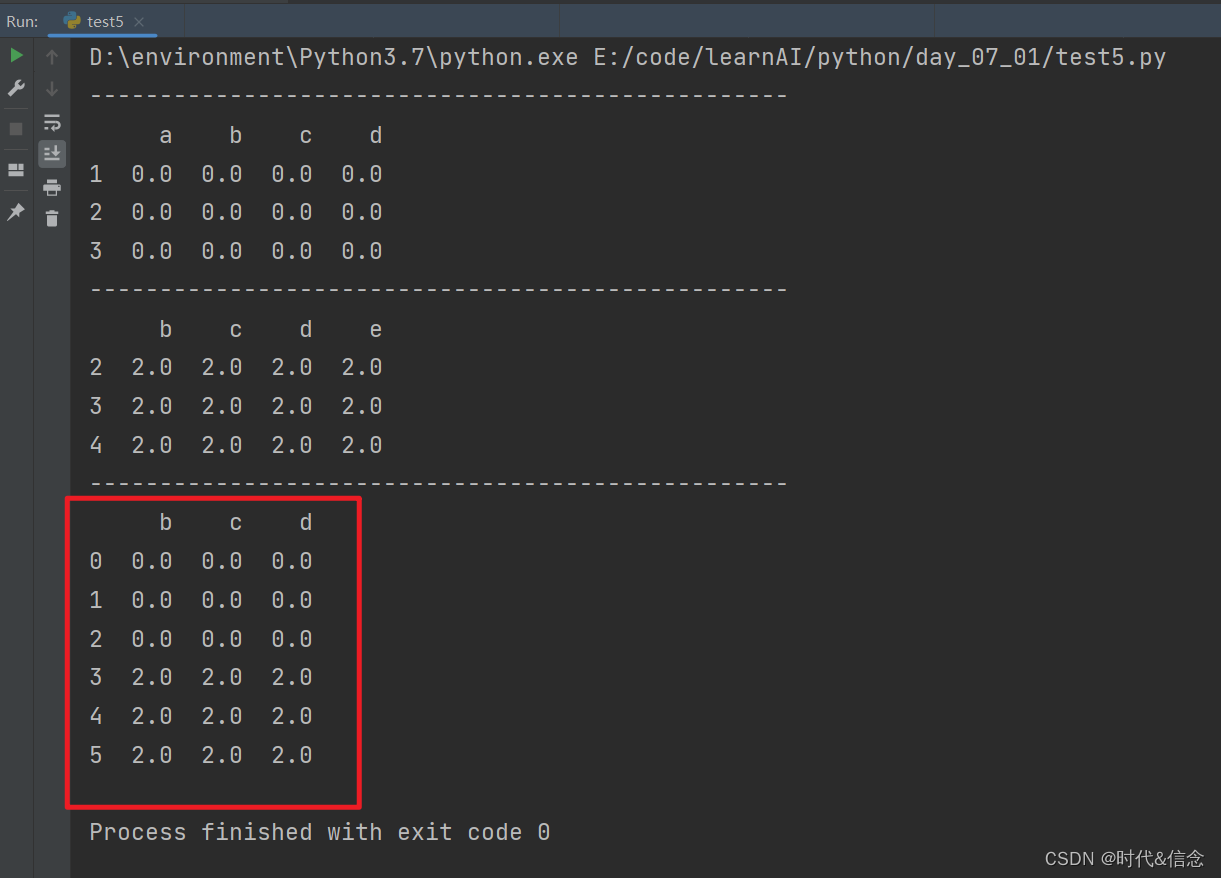
(5)使用append进行添加df
"""
append的使用,默认数据框架df进行纵向合并,添加到最下面
"""
df1 = pd.DataFrame(np.ones((3, 4))*0, columns=['a', 'b', 'c', 'd'], index=[1, 2, 3])
df2 = pd.DataFrame(np.ones((3, 4))*2, columns=['a', 'b', 'c', 'd'], index=[2, 3, 4])
df3 = pd.DataFrame(np.ones((3, 4))*3, columns=['a', 'b', 'c', 'd'], index=[2, 3, 4])
print("-" * 50)
print(df1)
print("-" * 50)
print(df2)
print("-" * 50)
print(df3)
print("-" * 50)
res = df1.append([df2, df3], ignore_index=True)
print(res)
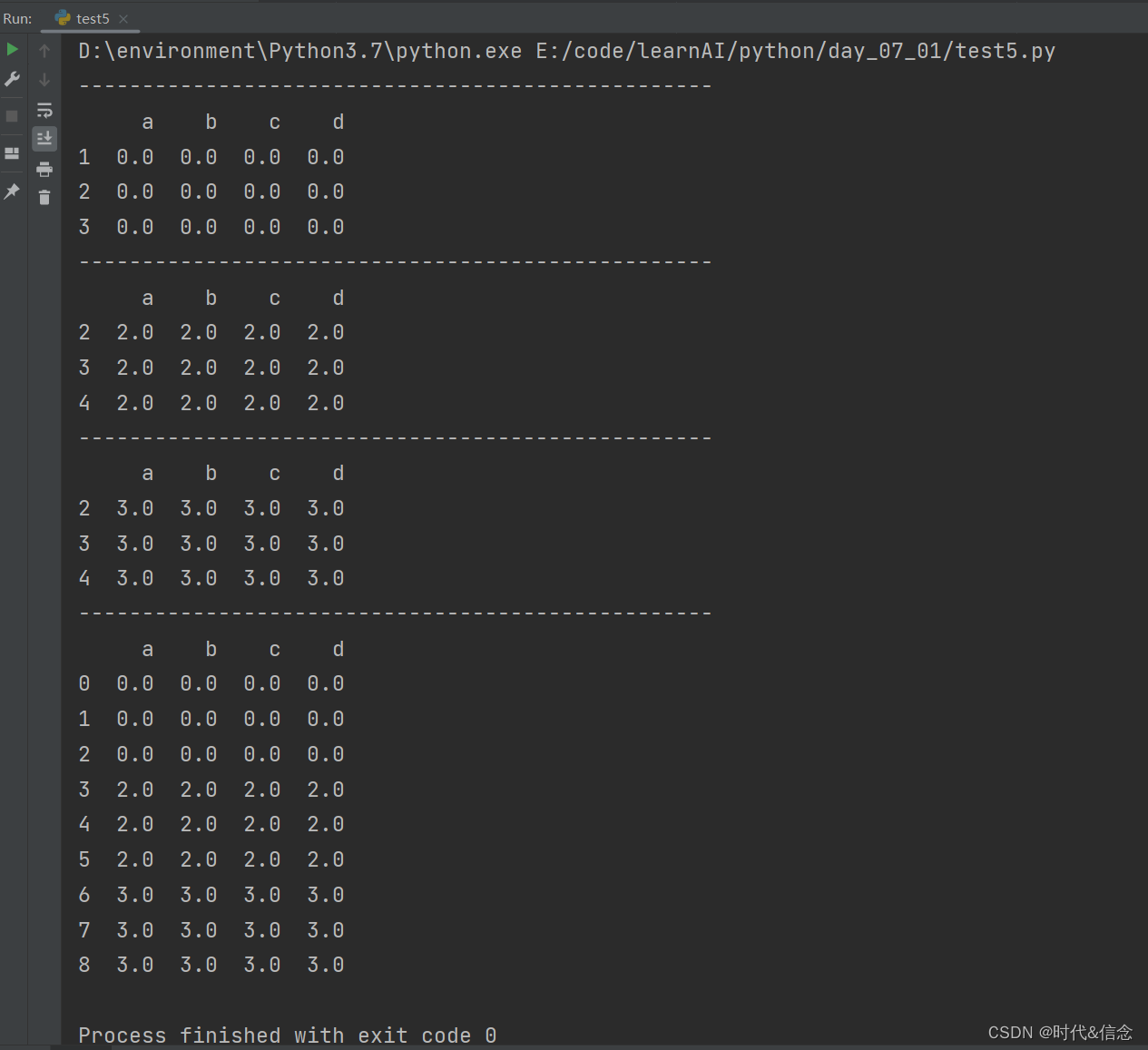
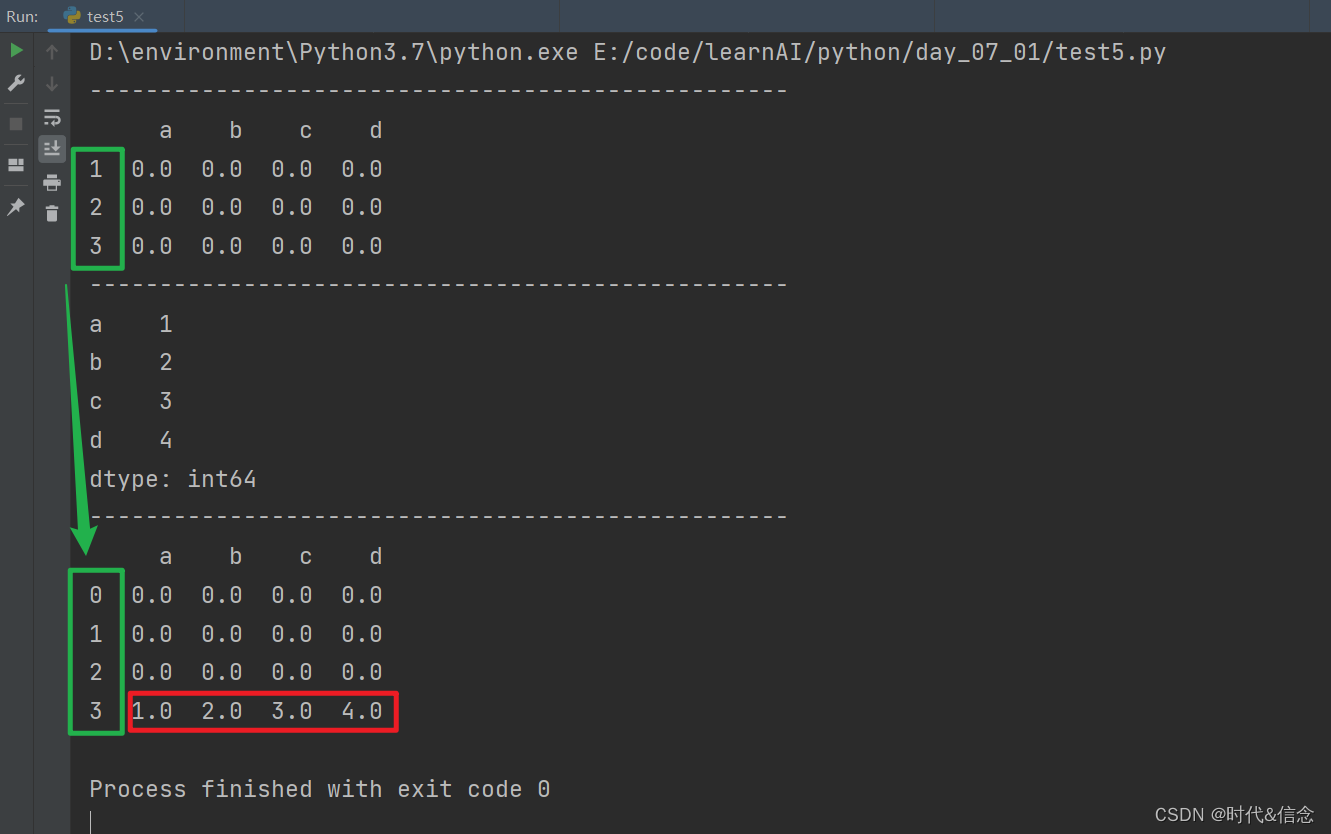
(6)使用append添加Series
s1 = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
print(s1)
print("-" * 50)
res = df1.append(s1, ignore_index=True)
print(res)
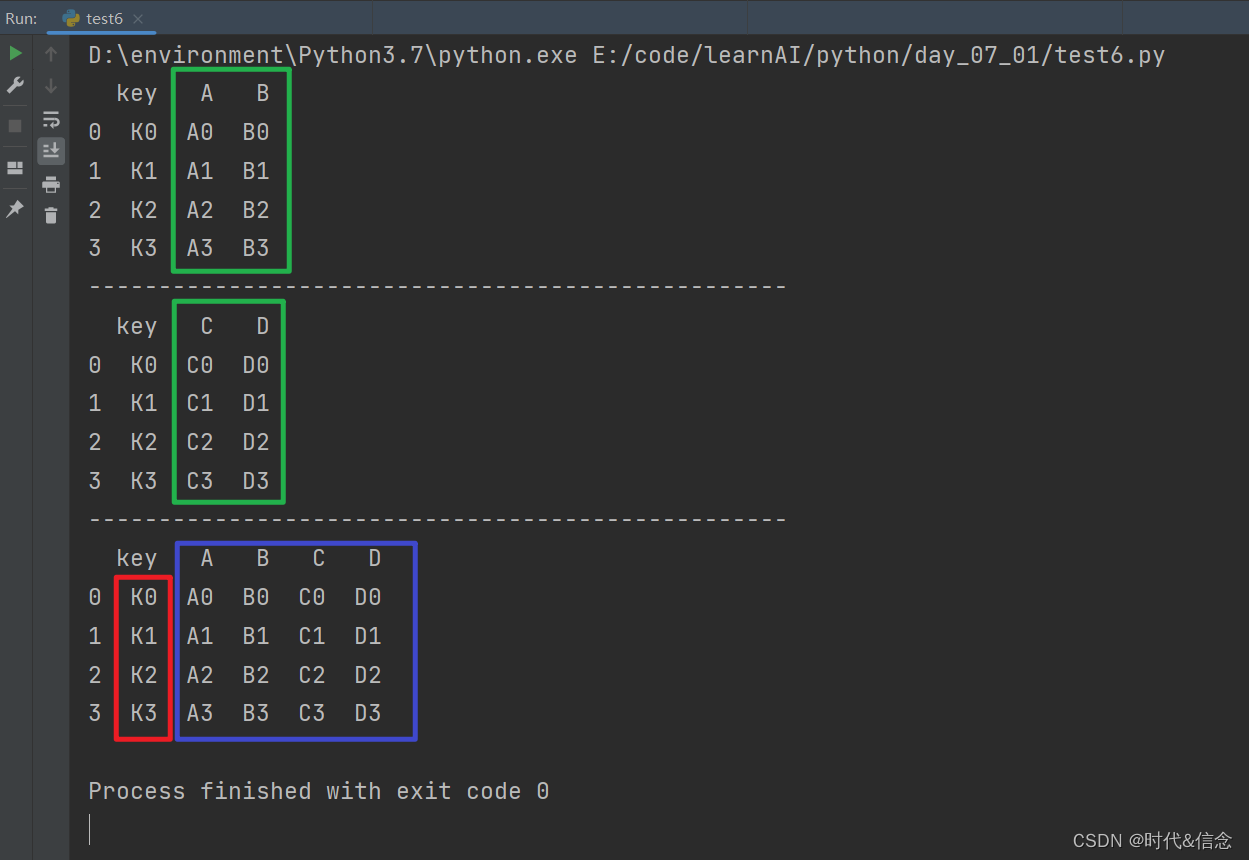
7.使用merge合并Dataframe
(1)基于公共列进行合并
import numpy as np
import pandas as pd
"""
merge的使用
"""
left = pd.DataFrame({'key':['K0', 'K1', 'K2', 'K3'],
'A':['A0', 'A1', 'A2', 'A3'],
'B':['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key':['K0', 'K1', 'K2', 'K3'],
'C':['C0', 'C1', 'C2', 'C3'],
'D':['D0', 'D1', 'D2', 'D3']})
print(left)
print("-" * 50)
print(right)
print("-" * 50)
res = pd.merge(left, right, on='key')
print(res)
(2)inner形式的merge合并
print("-" * 50)
left = pd.DataFrame({'key1':['K0', 'K0', 'K1', 'K2'],
'key2':['K0', 'K1', 'K0', 'K1'],
'A':['A0', 'A1', 'A2', 'A3'],
'B':['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1':['K0', 'K1', 'K1', 'K2'],
'key2':['K0', 'K0', 'K0', 'K0'],
'C':['C0', 'C1', 'C2', 'C3'],
'D':['D0', 'D1', 'D2', 'D3']})
print(left)
print("-" * 50)
print(right)
print("-" * 50)
res = pd.merge(left, right, on=['key1', 'key2'], how="inner")
print(res)
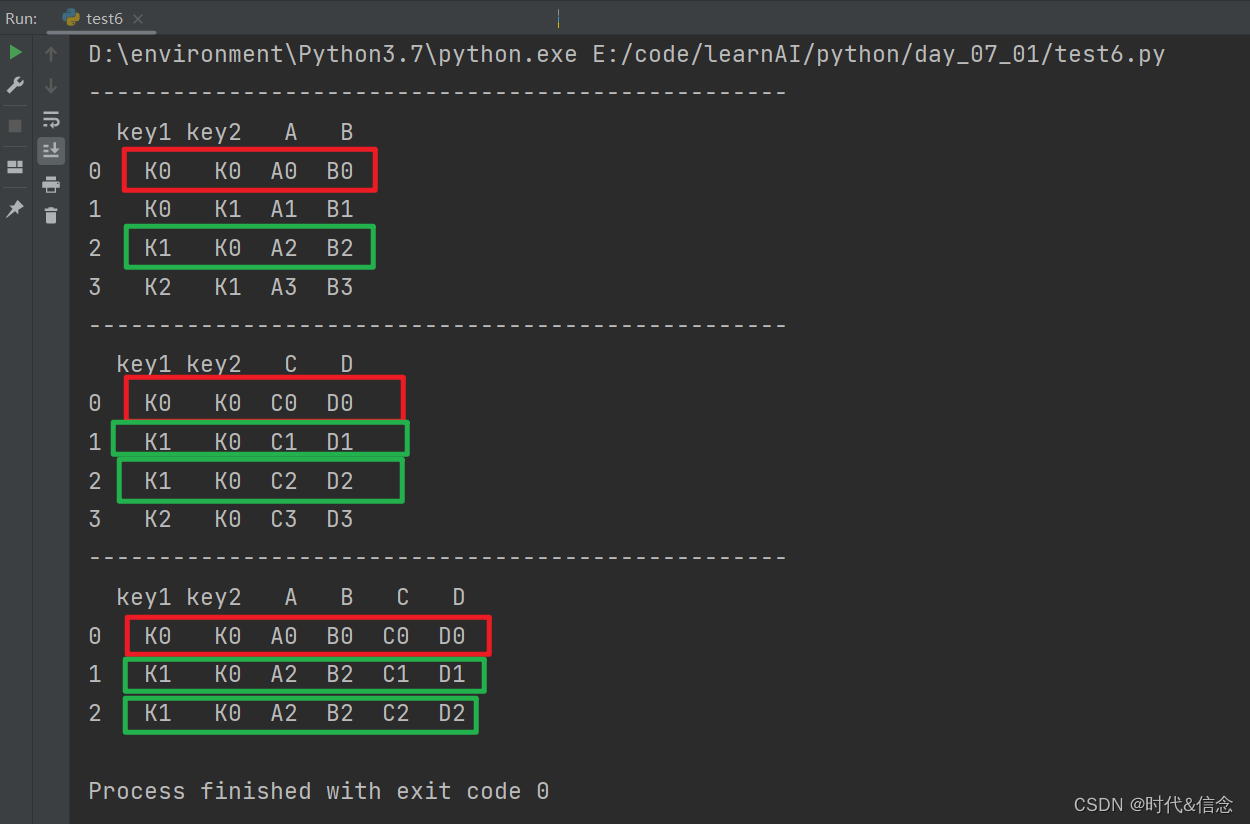
(3)outer形式的merge合并
print("-" * 50)
res = pd.merge(left, right, on=['key1', 'key2'], how="outer")
print(res)
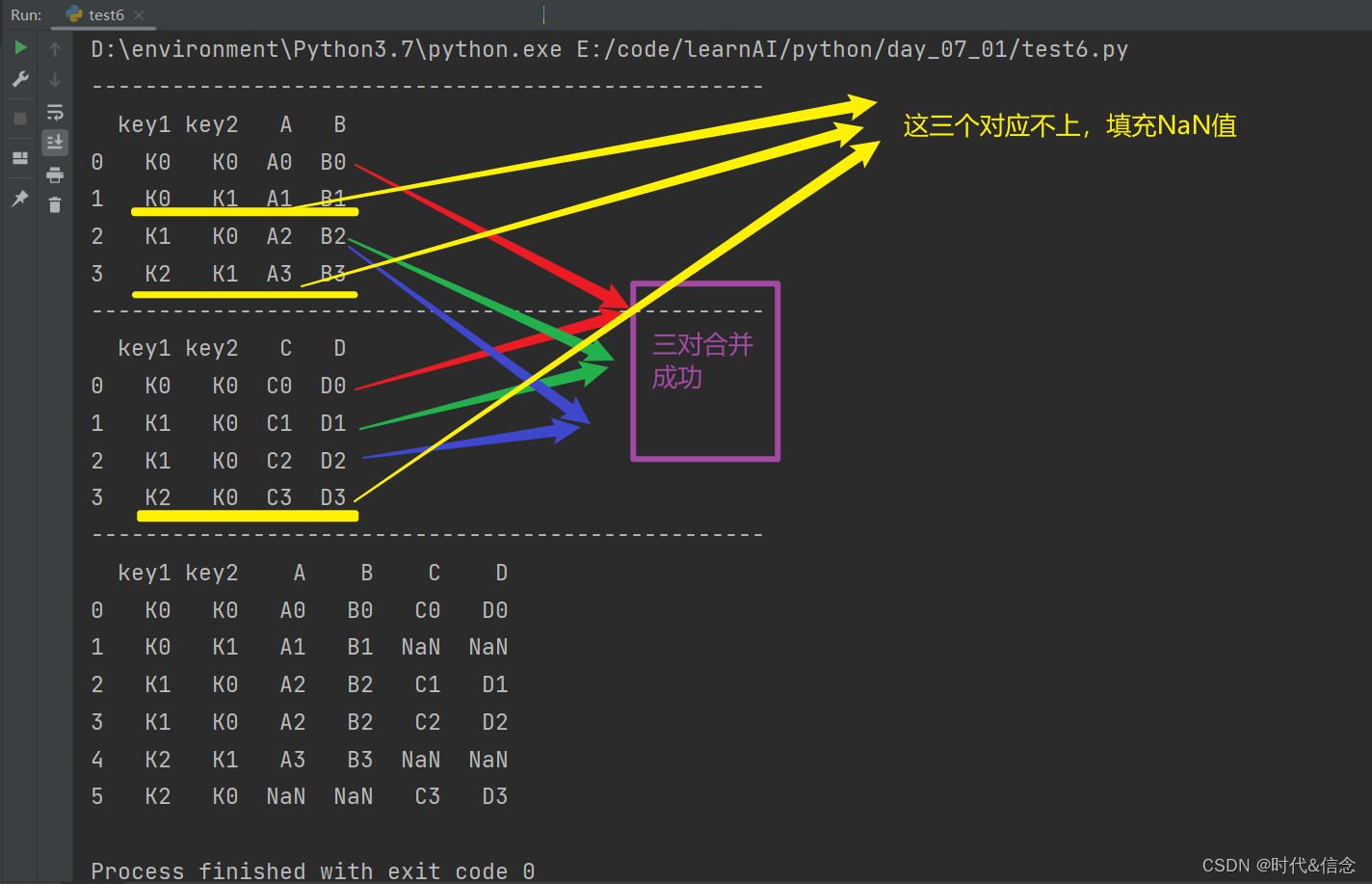
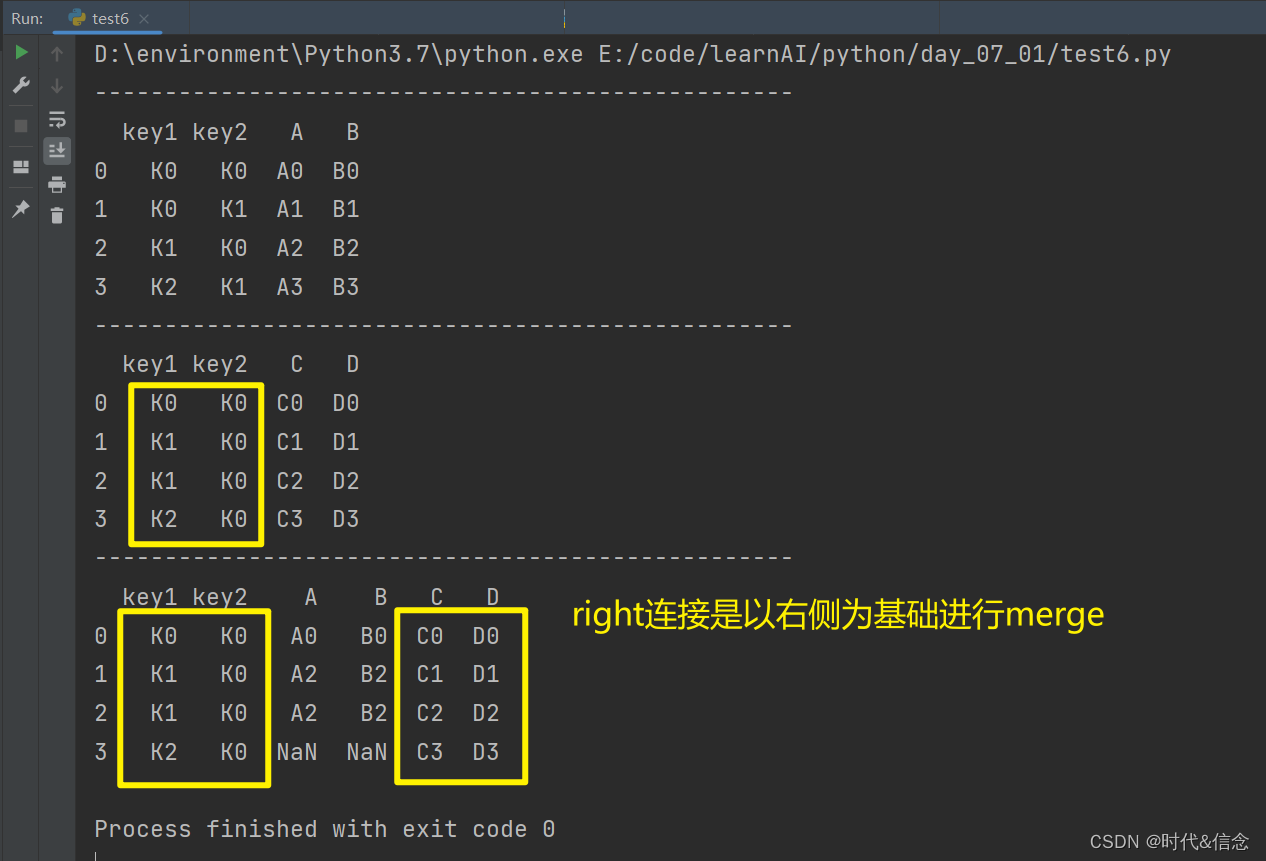
(4)right形式的merge合并
print("-" * 50)
res = pd.merge(left, right, on=['key1', 'key2'], how="right")
print(res)
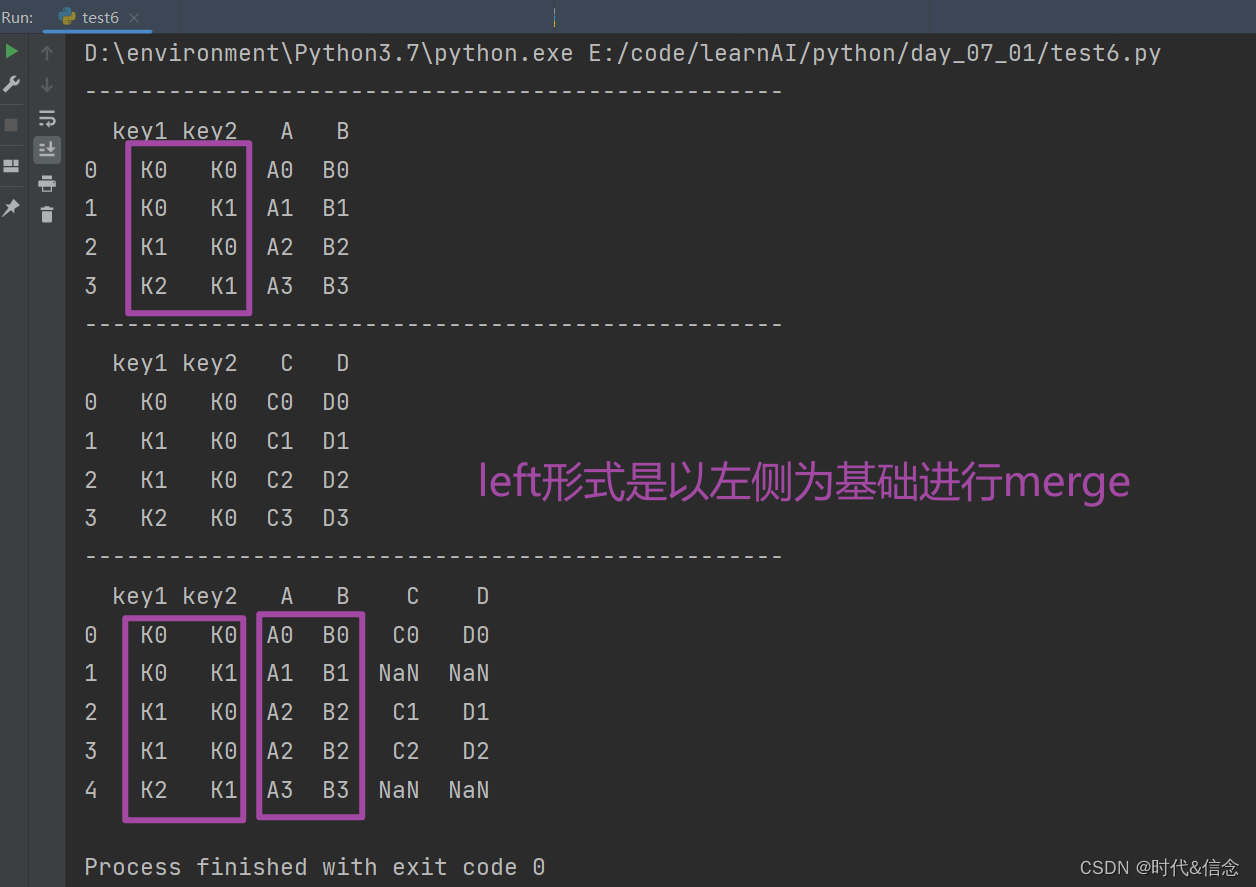
(5)left形式的merge合并
print("-" * 50)
res = pd.merge(left, right, on=['key1', 'key2'], how="left")
print(res)
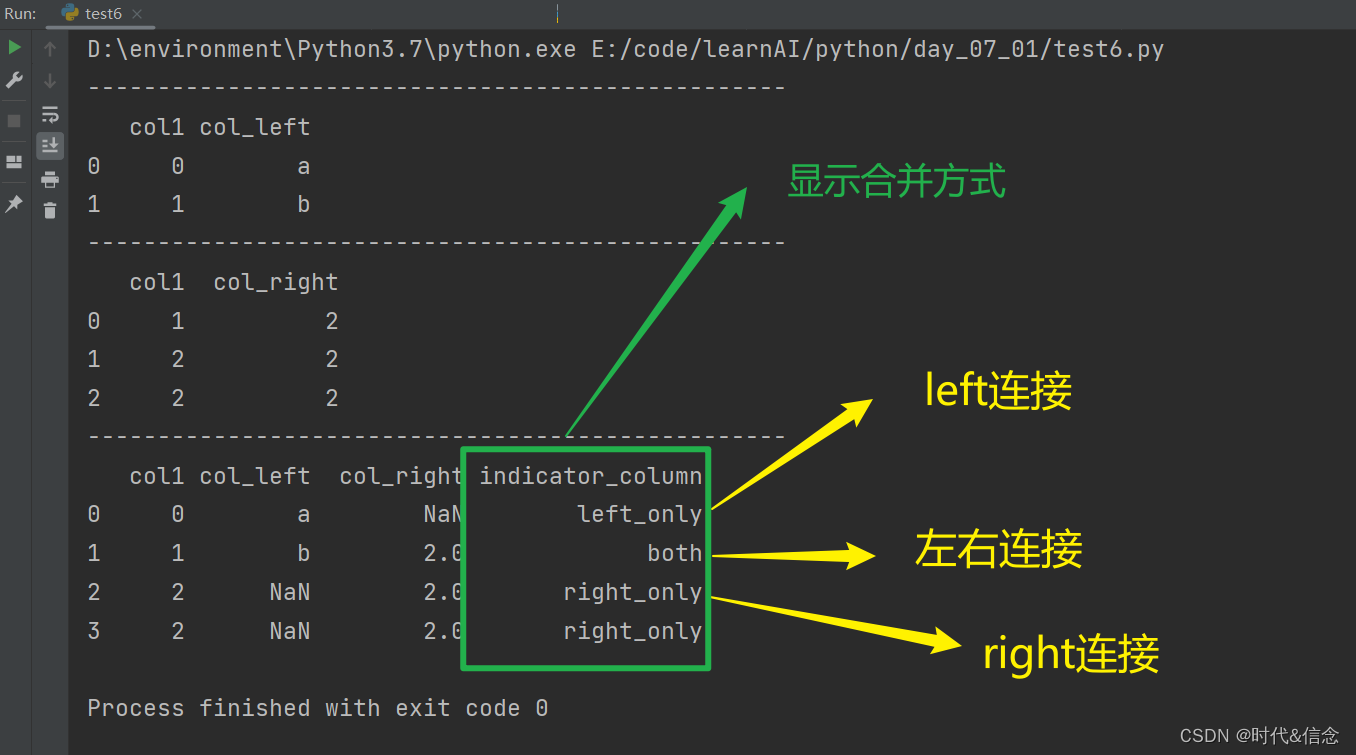
(6)merge参数之indicator
df1 = pd.DataFrame({'col1':[0, 1], 'col_left':['a', 'b']})
df2 = pd.DataFrame({'col1':[1, 2, 2], 'col_right':[2, 2, 2]})
print("-" * 50)
print(df1)
print("-" * 50)
print(df2)
res = pd.merge(df1, df2, on='col1', how='outer', indicator="indicator_column")
print("-" * 50)
print(res)
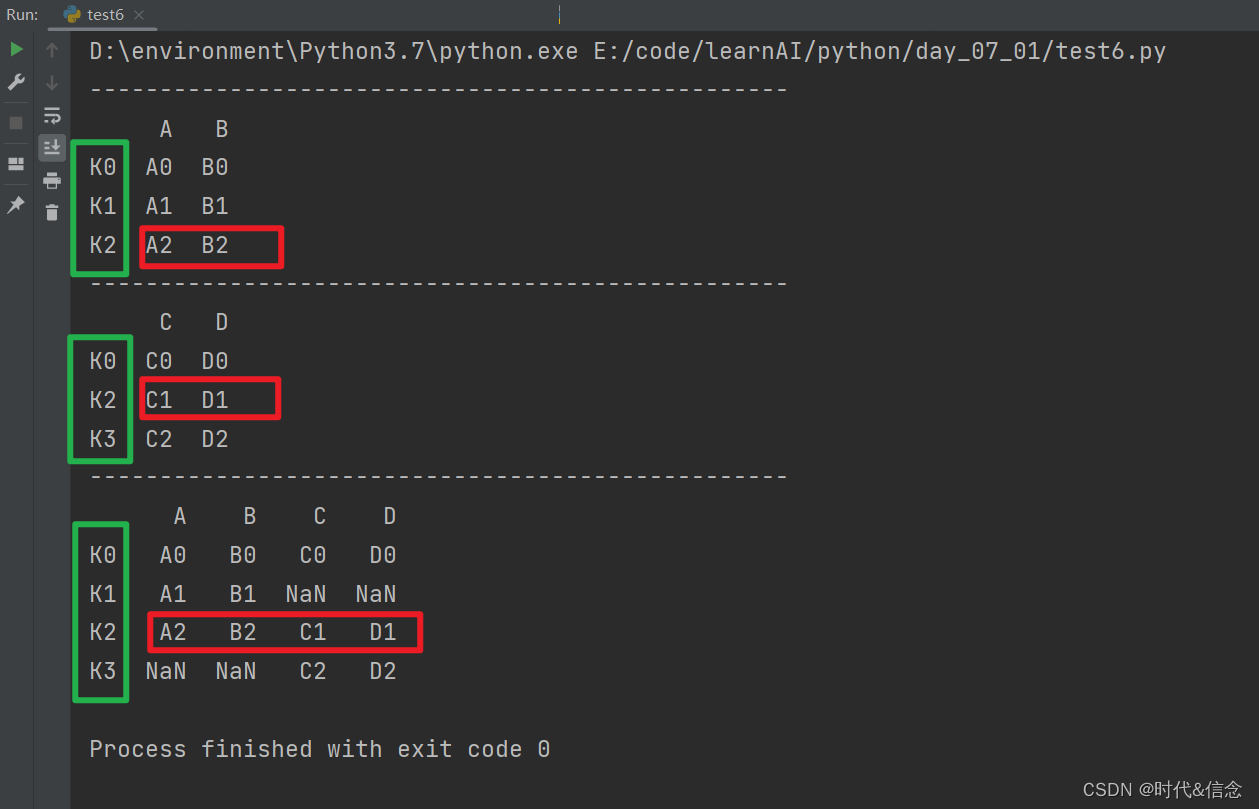
(7)merge参数之index
left = pd.DataFrame({'A':['A0', 'A1', 'A2'],
'B':['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'C':['C0', 'C1', 'C2'],
'D':['D0', 'D1', 'D2']},
index=['K0', 'K2', 'K3'])
print("-" * 50)
print(left)
print("-" * 50)
print(right)
print("-" * 50)
res = pd.merge(left, right, left_index=True, right_index=True, how='outer')
print(res)
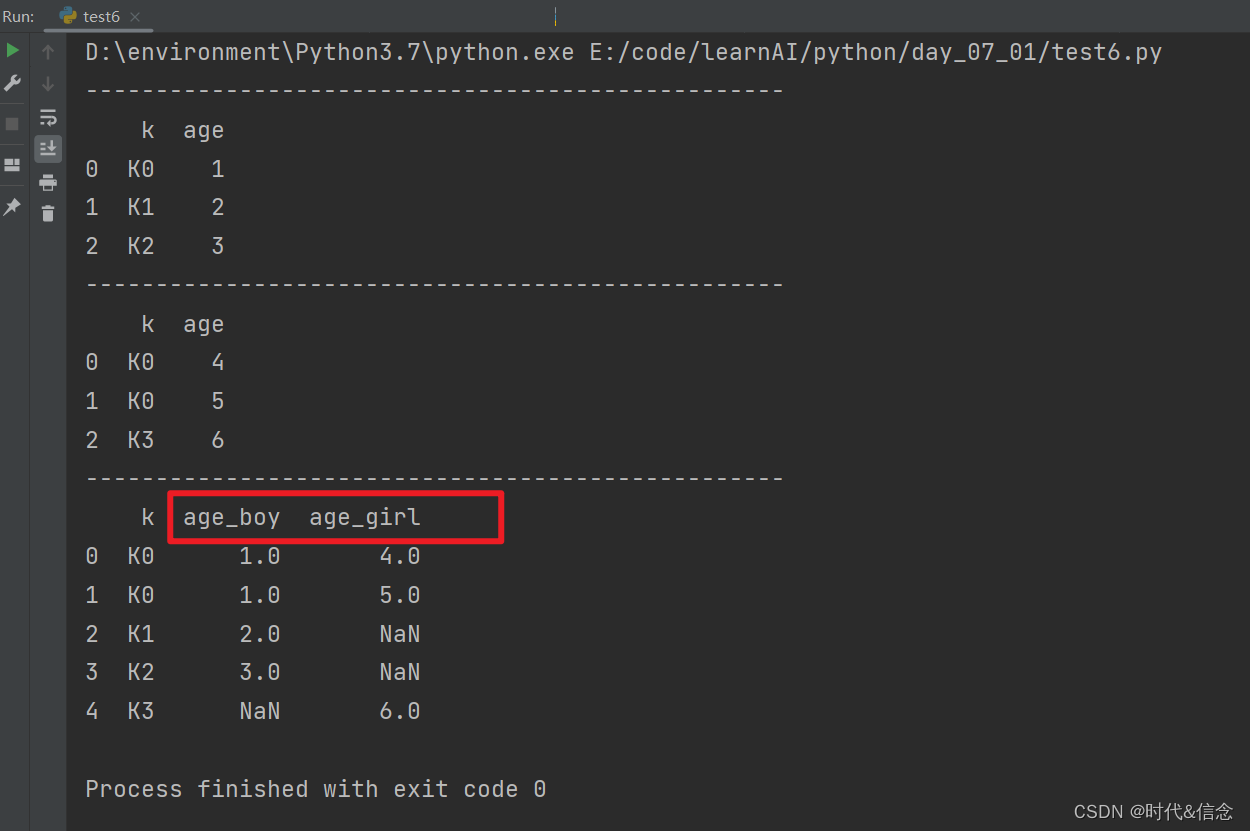
(8)merge参数之suffixes
boys = pd.DataFrame({'k':['K0', 'K1', 'K2'], 'age':[1, 2, 3]})
girls = pd.DataFrame({'k':['K0', 'K0', 'K3'], 'age':[4, 5, 6]})
print("-" * 50)
print(boys)
print("-" * 50)
print(girls)
res = pd.merge(boys, girls, on='k', suffixes=['_boy', '_girl'], how='outer')
print("-" * 50)
print(res)
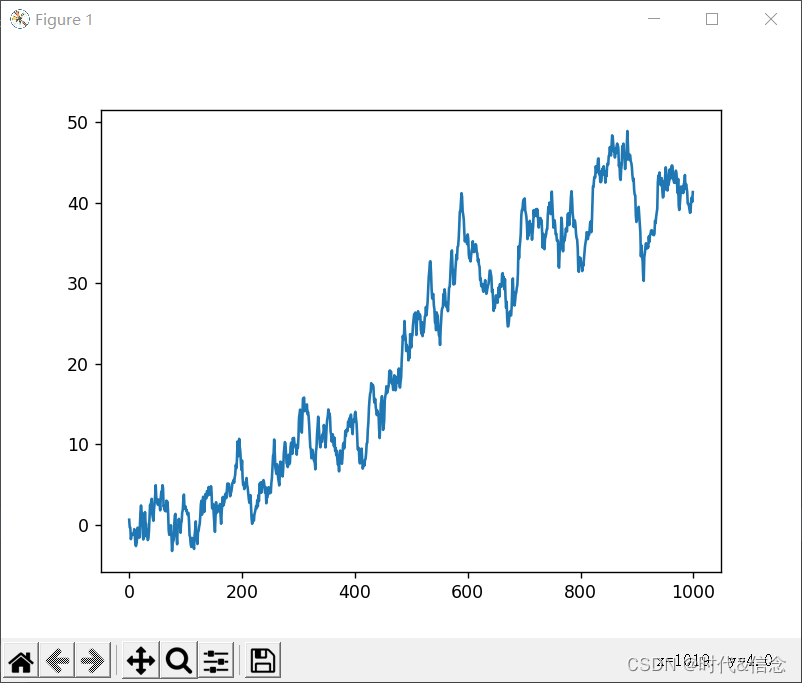
8. numpy和pandas处理数据之后,用matplotlib进行绘制图像
(1)对Series数据进行绘制线性图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.Series(np.random.randn(1000), index=np.arange(1000))
data = data.cumsum()
data.plot()
plt.show()
(2)对Dataframe数据进行绘制线性图
data = pd.DataFrame(np.random.randn(1000, 4),
index=np.arange(1000),
columns=["A", "B", "C", "D"])
data = data.cumsum()
data.plot()
plt.show()
(3)对Dataframe数据进行绘制散点图
ax = data.plot.scatter(x='A', y='B', color='DarkBlue', label='Class 1')
data.plot.scatter(x='A', y='C', color='DarkGreen', label='Class 2', ax=ax)
plt.show()
pandas总结完毕,撒花撒花…
Original: https://blog.csdn.net/Elon15/article/details/126467725
Author: 时代&信念
Title: Python数据分析之pandas(保姆级教程)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/754989/
转载文章受原作者版权保护。转载请注明原作者出处!