

对同一流数据进行多种计算
有时我们可能需要针对同一个流的数据源来进行多种计算,比如:使用同一流数据来计算多个指标,并把计算结果保存到不同的地方。此时,就需要对同一个来源的流使用不同的计算逻辑,并把结果写出到不同的存储系统中。
Spark Strucutured Streaming提供了针对同一个数据源流进行不同逻辑计算并对结果进行不同的sink的方式。
这就是在Spark Strucutured Streaming的writestream中提供的foreach和foreachBatch接口。
Foreach和ForeachBatch
- foreach 允许对微批的每一行数据自定义写出逻辑。
- foreachBatch 不仅可以自定义写出逻辑,还可以自定义任意的处理逻辑。
可以看出,这两者有所差别:foreach可以自定义写出的逻辑;而foreachBatch除了具有foreach的特点外,可以自定义处理逻辑,所以相对比较灵活。
ForeachBatch的编程模式
对于foreachBatch的编程模式可以通过通过图1来表示:
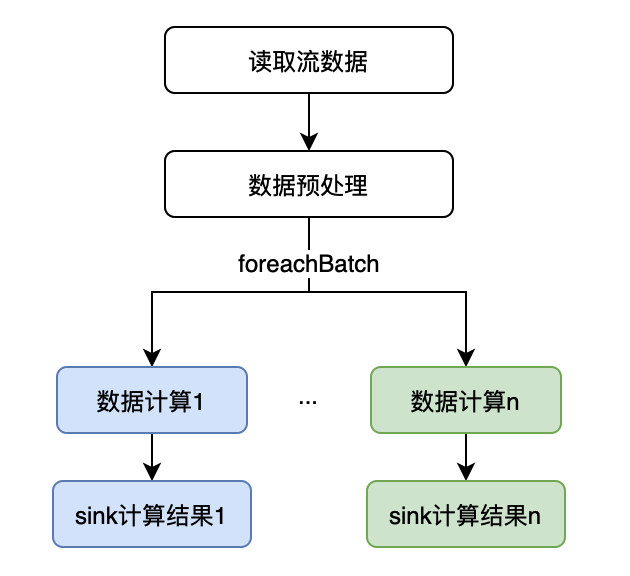

先读取流数据,此时得到的是一个流式的dataframe。它和spark sql的dataframe差不多,但常规dataframe的有些操作它不支持,在源码实现时,只是在常规的dataset结构中添加了一个流式数据集的标识符加以区分。
; foreachBatch的编码模板
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
// Transform and write batchDF
}.start()
例如:
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.persist()
batchDF.xxx1.write.format(...).save(...)
batchDF.xxx2.write.format(...).save(...)
batchDF.unpersist()
}
从以上示例代码可以看出,对来自同一数据源的每个微批的数据,可以进行不同的处理逻辑,并把处理结果保存到不同的存储位置。
foreach的编码模式
def process_row(row):
pass
query = streamingDF.writeStream.foreach(process_row).start()
实战
以下例子是python的代码,针对同一个流数据,分别进行了两种处理逻辑,并得到了两个结果,然后把这两个结果分别写出到了不同的位置。
这里只是计算了两个指标,当然也可以继续添加逻辑计算。
from __future__ import print_function
import sys
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
def func1(df):
wc = df.groupBy('word').count()
wc.write.mode("append").format("json").save("/tmp/sparktest/json/")
def func2(df):
wc2 = df.groupBy('word').count()
wc2.write.mode("append").format("csv").save("/tmp/sparktest/csv/")
func_list = [func1, func2]
def foreach_batch_function(df, epoch_id):
df.persist()
for f in func_list:
f(df)
df.unpersist()
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: structured_network_wordcount.py ",
file=sys.stderr)
sys.exit(-1)
host = sys.argv[1]
port = int(sys.argv[2])
spark = SparkSession\
.builder\
.appName("StructuredNetworkWordCount")\
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
lines = spark\
.readStream\
.format('socket')\
.option('host', host)\
.option('port', port)\
.load()
words = lines.select(
explode(
split(lines.value, ' ')
).alias('word')
)
query = words.writeStream\
.foreachBatch(foreach_batch_function).start()
query.awaitTermination()
提交任务
开启一个终端,并在终端中输入以下命令:
$ nc -lk 10002
hello world
hello world 1
hello world 2
just do it !
这里使用本地模式提交。因为使用了接收socket的流数据,但socket是实验产品,官方不建议在生产环境下使用。
./bin/spark-submit --master local dostream/word_count_v2.py localhost 10002
注意事项
(1)默认情况下,foreachBatch只提供至少一次写(at-least-once write)保证。但是,您可以使用提供给函数的batchId来对输出进行重复数据删除,并获得只执行一次的保证。
(2)foreachBatch不能与连续模式(continuous)一起工作,因为它基本上依赖于流查询的微批处理执行。如果以连续模式写入数据,则使用foreach。
Original: https://blog.csdn.net/zg_hover/article/details/113274986
Author: 一 铭
Title: Spark Structured Streaming实战–对同一流数据进行多种计算
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/754426/
转载文章受原作者版权保护。转载请注明原作者出处!