

目录
大体上的更新就这样子啦,还有一些函数没有补充上去,等哪天用到了 想起来了我又回来补嘿嘿。
前言
博主是第一次写文章,也是非计算机的小白一枚,刚刚开始接触科研,希望以此记录一下学习过程。
如果有哪里不完全或者是不对的地方,希望各位能多多指正啦!
一、pandas是什么?
对于博主来说,pandas就像是一个工具,处理数据以及分析数据。
那如何学习pandas呢?
学好pandas首先你得对numpy有一定的了解。
基本数据类型Series一维结构,可以理解为竖起来的listDateframe二维结构,可以理解为excel表格
二、开始正式学习啦!!
1.基本数据类型
1.1认识Series(系列)
先上段简单的代码!
import pandas as pd
s_1 = pd.Series([1,2,3,4,5,6,7]) #注意S必须要大写!!!
好了,这样我们就创建了一个简单的 Series了,我们来看看它里面的内容
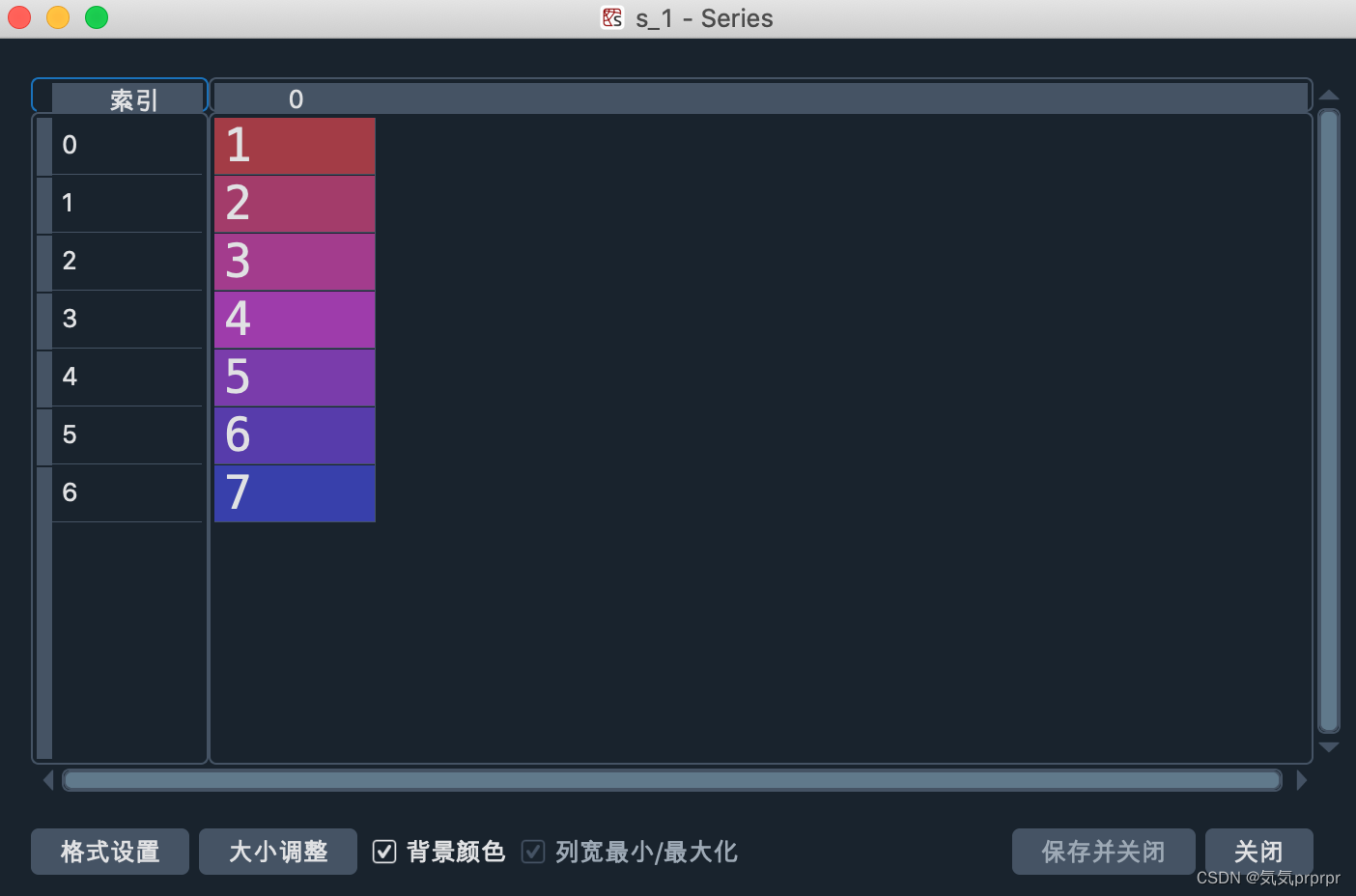

我们可以发现他的索引也就是index和他的值也就是value是一一对应的关系
那么可能有些人觉得这个索引不顺眼,那可不可以换呢?答案是当然可以了!
import pandas as pd
s_1 = pd.Series([1,2,3,4,5,6,7],index=['a','b','c','d','e','f','g'])
让我们看看效果!
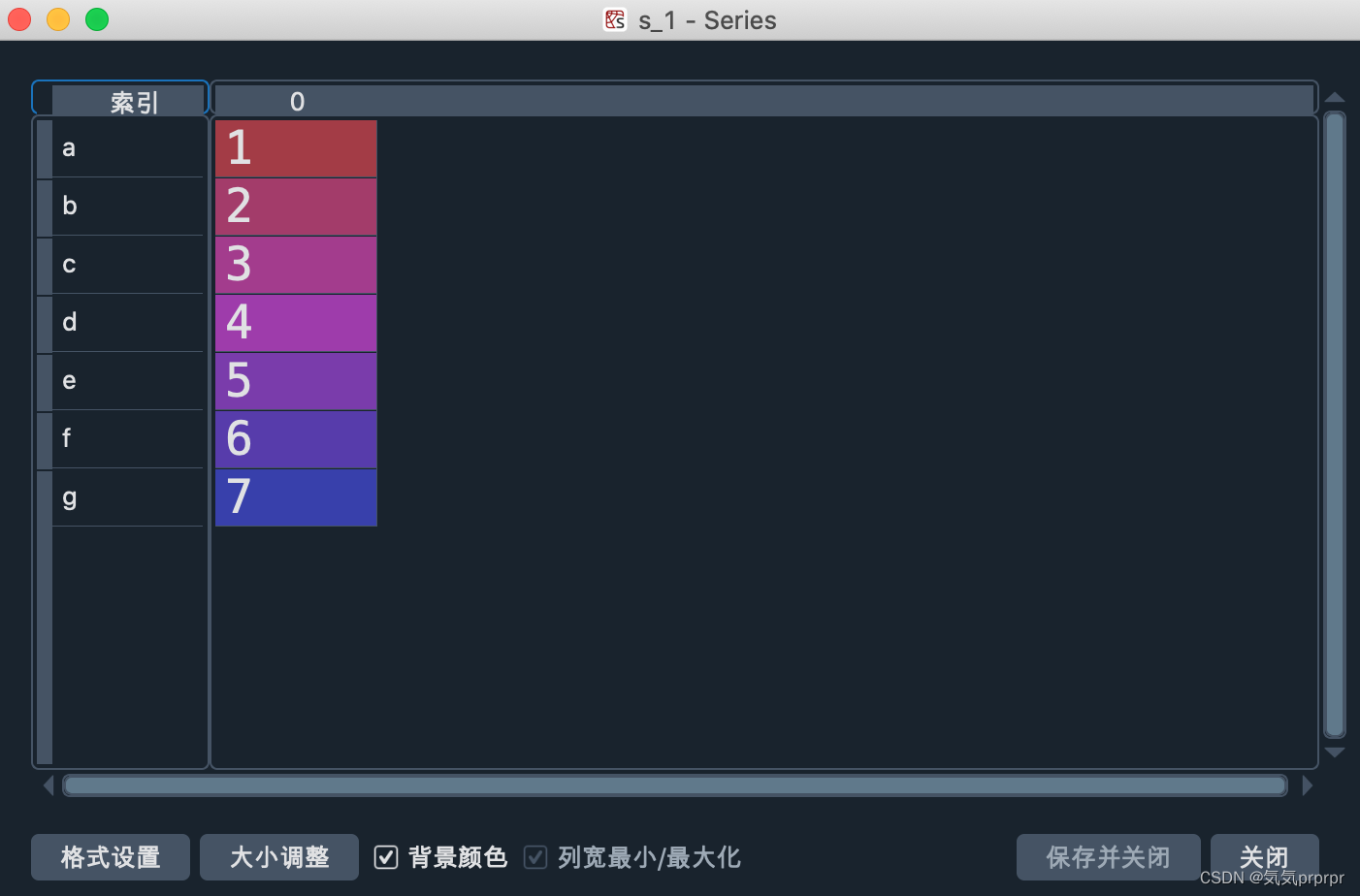
Series的属性
s_1.index
>>Index(['a', 'b', 'c', 'd', 'e', 'f', 'g'], dtype='object')
s_1.values
>>array([1, 2, 3, 4, 5, 6, 7])
”’查”’
(1)通过标签
s_1['d']#访问的index为d
s_1[['a','d']]#访问的index为a和d
s_1[['a':'d']]#访问的index为a到d
(1)通过列表
s_1[0]
s_1[[0,4]]
s_1[[0:4]]
”’增删改”’
s_2 = pd.Series(['rose','lily'])
s_3 = pd.Series(['2'],index = ['d'])
s_3 = s_2.append(s_3)#s_2 s_3的数据类型得相同!!
s_1.drop('a')
s_2[0] = 'petter'
1.2认识Dataframe(数据框)
可以简单理解为一个Excel表格,废话不多说!先上代码
import pandas as pd
df_1 = pd.DataFrame({'age':[10,11,12],
'name':['Tim','jack','rose'],
'income':[100,200,300]},
index=['person1','person2','person3'])
让我们再来看看效果,是不是对理解有了更进一步的认识呢!
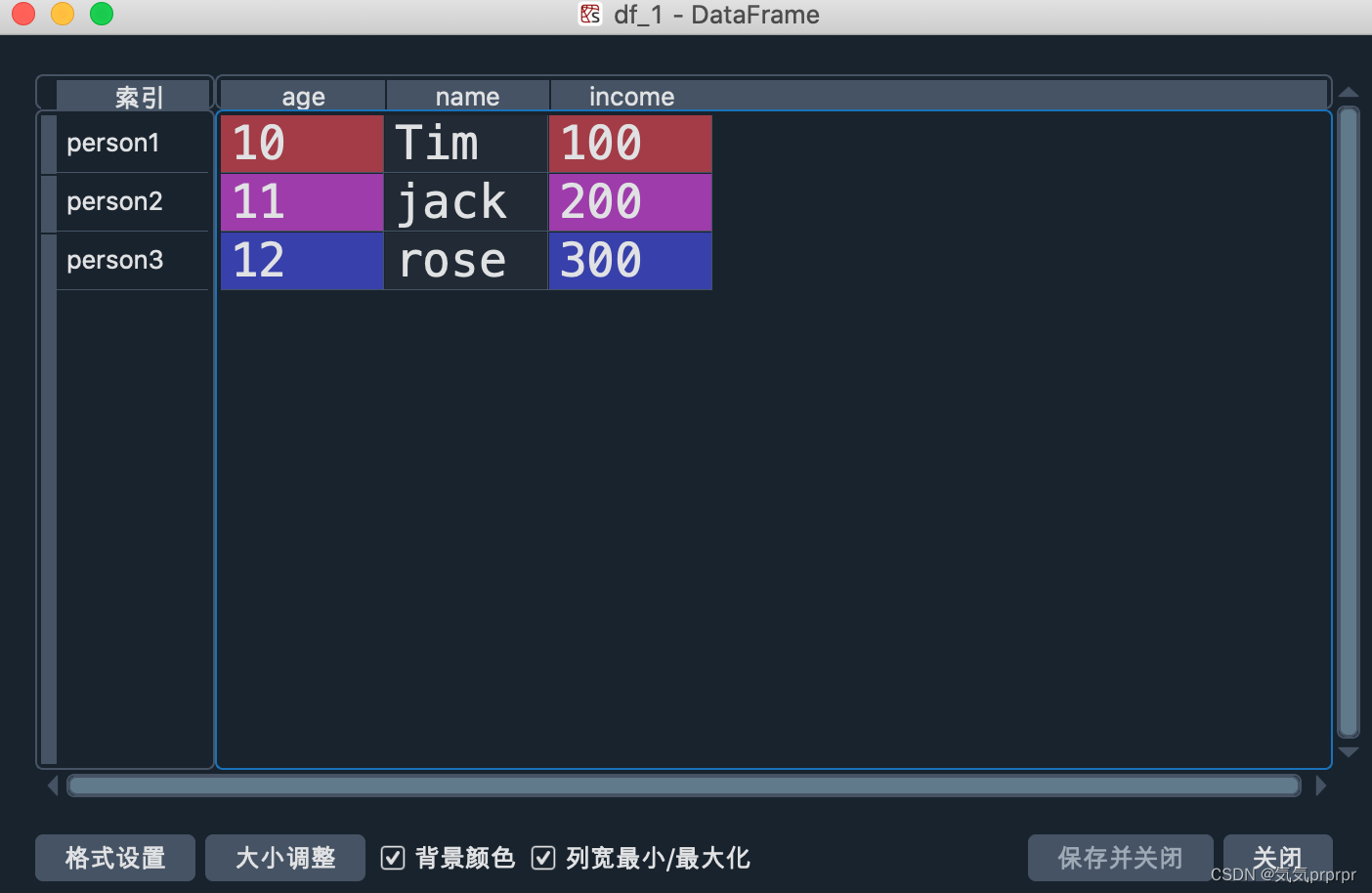
我们接下来看看它的 属性吧!!
df_1.index
>>Index(['person1', 'person2', 'person3'], dtype='object')
df_1.columns
>>Index(['age', 'name', 'income'], dtype='object')
df_1.values
>>array([[10, 'Tim', 100],
[11, 'jack', 200],
[12, 'rose', 300]], dtype=object)
改名字
#修改列名
df_1.columns = ['a','c','f']#字符型
df_1.columns = range(0,len(df_1.columns))#数字型
#精确修改
df_1.rename(columns={1:'hh'},inplace = True)
如果想改行名的话直接在把columns换成index就可以了!
来看看df_1变成什么样子了
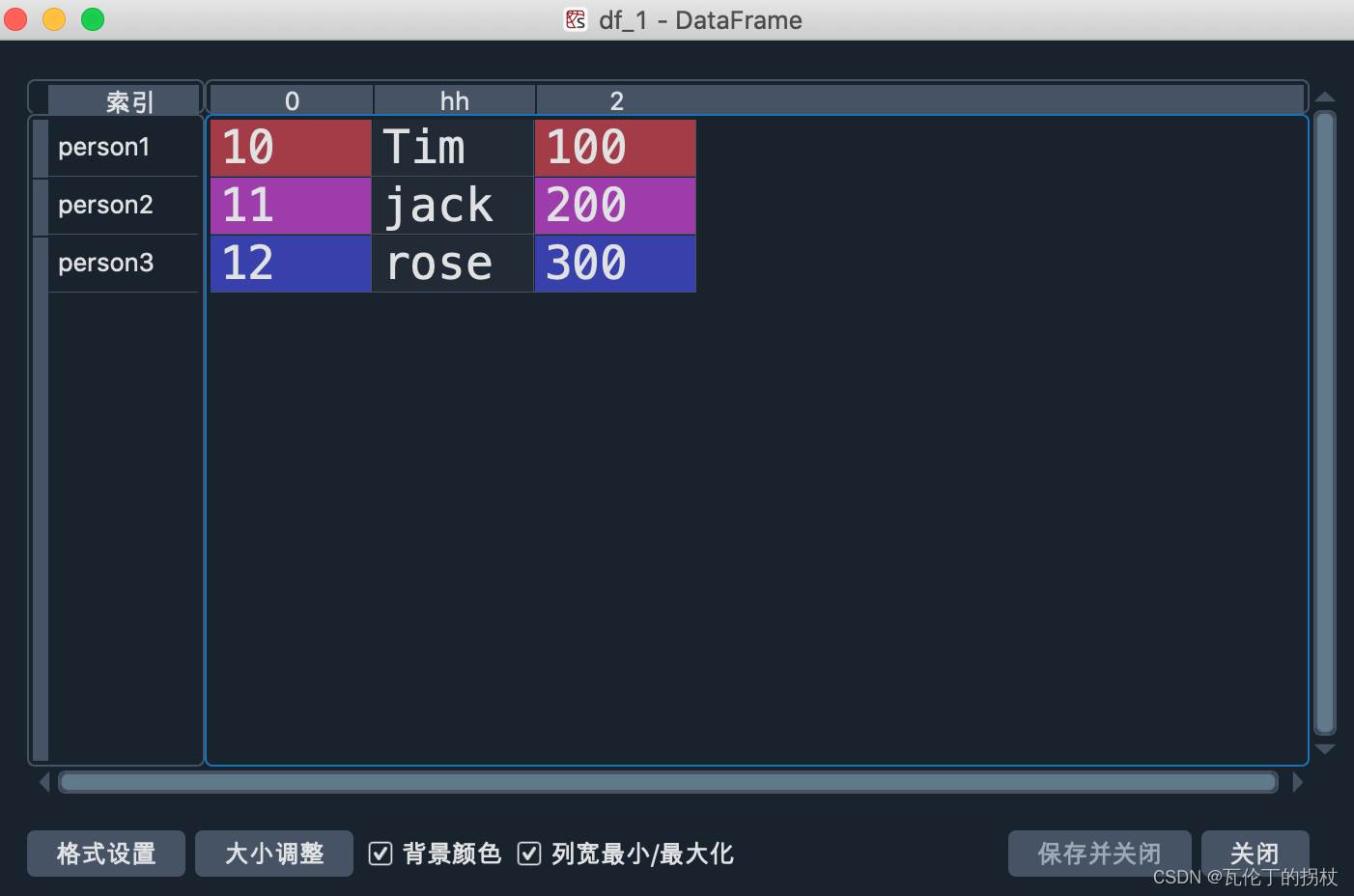
”’增加行or列” ‘
df_1['pay'] = [1,2,3]
df_1.loc['person4',[0,'hh',2,'pay']] = [13,'jimi',400,90]
效果
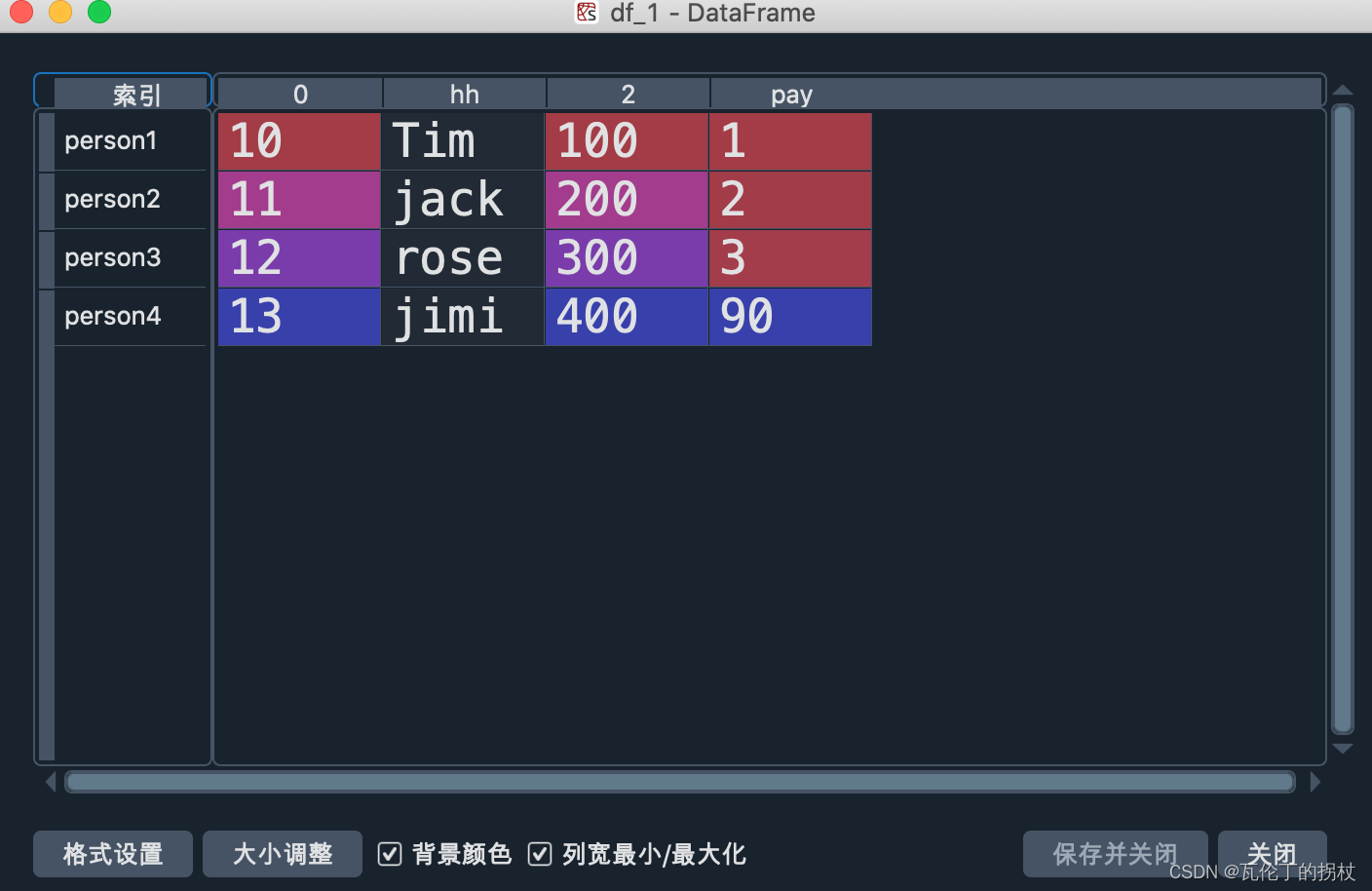
可以看出,以上都是在最后一行或者最后一列增加,那接下来我们来看指定位置增加
指定位置
DataFrameName.insert(loc,colums,value)
- loc:是一个 整数,我们要插入列的位置
- column:是一个 字符串,列名
2.访问DataFrame
df_1.hh#访问列名为hh的
df_1[[0,2]]#访问第一列和第三列
df_1[0:2]#访问前三行
df_1.loc[['person1','person4']]#访问名字
df_1.loc['person1','hh']#访问特定的值
2.1删除操作
data = df_1.drop('hh',axis=1,inplace = False)
#删除名字为hh的这一列,不会在原处修改
del df_1['hh']#删除名字为hh的这一列,直接在原数据修改
df_1.drop('person2',axis=0,inplace = True)
#删除名字为hh的这一行,会在原处修改
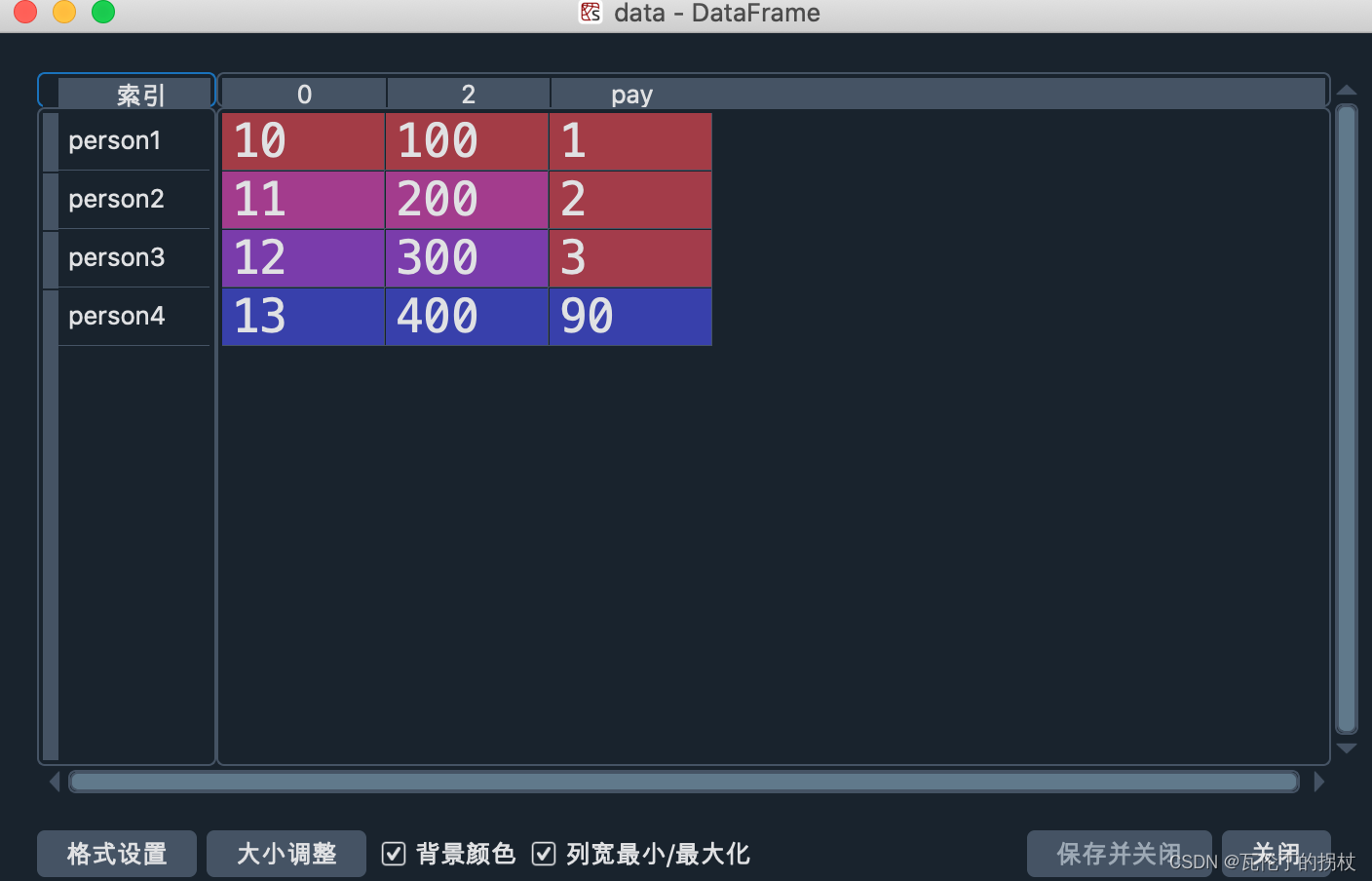
2.2 查询数据的方法
先创建一个数据框
import pandas as pd
import numpy as np
datas = pd.date_range('20221001',periods = 5)
df = pd.DataFrame(np.arange(30).reshape(5,6),index = datas,
columns = ['a','b','c','d','e','f'])
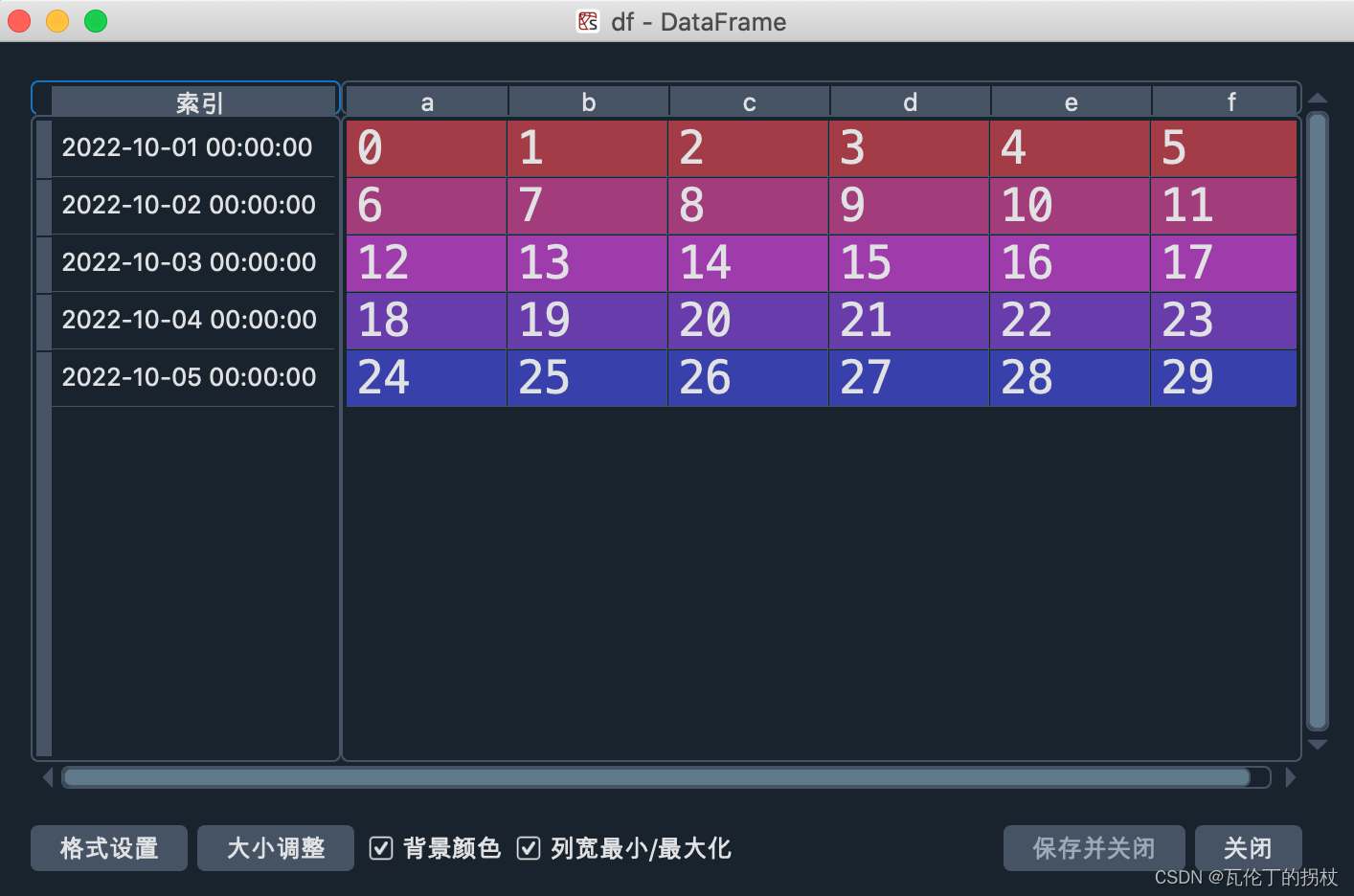
loc方法#标签索引
df.loc[index.columns]
df.loc['20221003','b']#某个值
>>13
df.loc['20221004',['b','d']]#2个值
>>b 19
d 21
Name: 2022-10-04 00:00:00, dtype: int64
df.loc[:,['b','d']]#所有行的b d列
>> b d
2022-10-01 1 3
2022-10-02 7 9
2022-10-03 13 15
2022-10-04 19 21
2022-10-05 25 27
iloc方法(位置索引)
df.iloc[2,1]
df.iloc[3,[1,3]]
df.iloc[:,[1,3]]
ix方法(混合索引)
在pandas版本0.20.0及其以后版本中,ix已经不被推荐使用,。这是为什么呢?这是由于ix的复杂特点可能使ix使用起来有些棘手:
3. DataFrame常见操作
3.1排序
import pandas as pd
dic = {'name':['kiti','beta','peter','tom'],
'age':[20,18,35,21],
'gender':["f","f",'m','m']}
df = pd.DataFrame(dic)
#根据年龄排序
df = df.sort_values(by = ['age']) #升序
df = df.sort_values(by = ['age'],ascending = False)#降序
#值替换
df['gender'] = df['gender'].replace(['m','f'],['male','fmale'])
#重新排列数据中的列
colos = ['name','gender','age']
df = df.loc[:,colos]
3.2数据文件的导入与导出
import pandas as pd
#读文件
df1 = pd.read_csv("file.csv",header = None)
df2 = pd.read_csv("file.xlxs",header = None)
#导出文件
df1.to_csv("file.csv",index = False,header = True)
高能预警
4.处理数据常见操作
4.1缺失值处理
- 进行逻辑判断并判断空值所在位置
na = df.isnull()
- 找出空值所在行数据
df[na.any(axis = 1)]
- 找出空值所在列数据
df[na[["列名"]].any(axis = 1)]
- 填充缺失值
df = df.fillna('1')
4.2重复值的处理
- 找
result1 = df.duplicated()
#结果只有True和False,完全相同才是True
- 找某列或者多列
result2 = df.duplicated(['列名'])
result3 = df.duplicated(['列名1','列名2'])
- 删
new_df1 = df.drop_duplicates #完全重复
new_df2 = df.drop_duplicates(['列1','列2'])#部分重复
4.3抽取数据
- 比较
df[df['列1']>17000]
df[df['列1'].between(1500,19000)]
- 字样匹配
df['name'].str.contains['apple',na=False]
4.4数据合并
- “concat函数”
concat[df1,df2,……]
import pandas as pd
import numpy as np
df_1 = pd.DataFrame(np.arange(12).reshape(3,4))
df2 = df1*2#df2的数据的值是1的2倍
横向
new_df1 = pd.concat([df_2,df_1])
竖向
new_df2 = pd.concat([df_2,df_1],axis = 1)
”’join”’ inner:交集 outer:并集
df3 =pd.DataFrame(np.arange(12).reshape(3,4),index = ['a','s','d'])
new_df3 = pd.concat([df_1,df_3],axis = 1,join = 'inner')
new_df3 = pd.concat([df_1,df_3],axis = 1,join = 'outer')
大体上的更新就这样子啦,还有一些函数没有补充上去,等哪天用到了 想起来了我又回来补嘿嘿。
Original: https://blog.csdn.net/qq_62969774/article/details/126970591
Author: 瓦伦丁的拐杖
Title: Python之pandas库(万年一更版)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/754354/
转载文章受原作者版权保护。转载请注明原作者出处!