

本文摘要:


; 分组后使用聚合函数统计
df为
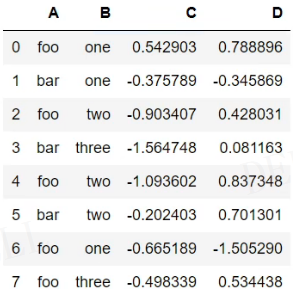
- 单个列groupby,查询所有数据列的统计
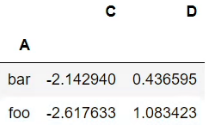
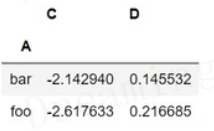
df.groupby('A').sum()
返回结果,可见A变成索引列,里面的值进行了分类有bar、foo。因为调用sum函数,B列不是数字,自动忽略。
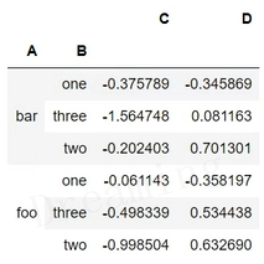
2. 多列groupby,查询所有数据列的平均数
df.groupby(['A', 'B']).mean()
A、B变成了二级索引
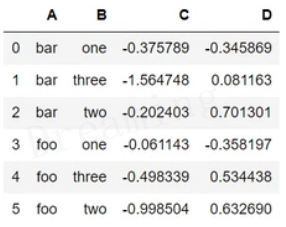
如果不希望A、B变成索引,可以修改as_index参数为False
df.groupby(['A', 'B'], as_index=False).mean()
- 同时查看多种数据统计结果,这里用到了numpy里的函数
df.groupby('A').agg([np.sum, np.mean, np.std])
列变成了多级索引

4. 查看单列的数据统计结果
df.groupby('A')['C'].agg([np.sum, np.mean, np.std])
df.groupby('A')['C'].max()
- 不同列使用不同函数
df.groupby('A').agg({'C': np.sum, 'D': np.mean})
获取某个分组的数据
按某一列分组的情况:
g = df.groupby('A')

for name, group in g:
print(name)
print(group)
print()

通过get_group方法获取某个分组的数据
g.get_group('bar')

按多列分组的情况:
g = df.groupby(['A', 'B'])
这里的返回结果name就是一个包含两个元素的元组
所以可以这么获取分组的数据
g.get_group(('foo', 'one'))
- 此文仅为个人笔记
Original: https://blog.csdn.net/DreamingBetter/article/details/123816046
Author: DreamingBetter
Title: Python – Pandas 数据分组groupby
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/753699/
转载文章受原作者版权保护。转载请注明原作者出处!