

日常用 Python做数据分析最常用到的就是查询筛选了,按各种条件、各种维度以及组合挑出我们想要的数据,以方便我们分析挖掘。
今天我给大家总结了日常查询和筛选常用的种骚操作,供各位学习参考。本文采用 sklearn的 boston数据举例介绍。 喜欢本文记得收藏、关注、点赞。
【注】完整代码、数据资料、文末提供技术交流群
from sklearn import datasets
import pandas as pd
boston = datasets.load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)

1. []
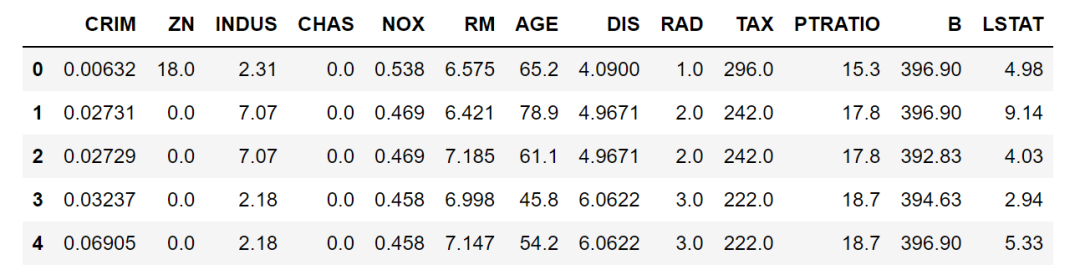
第一种是最快捷方便的,直接在dataframe的 []中写筛选的条件或者组合条件。比如下面,想要筛选出大于 NOX这变量平均值的所有数据,然后按 NOX降序排序。
df[df['NOX']>df['NOX'].mean()].sort_values(by='NOX',ascending=False).head()
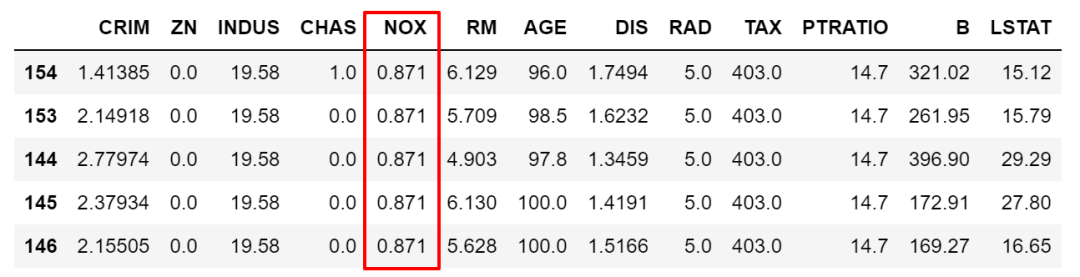
当然,也可以使用组合条件,条件之间使用逻辑符号 & |等。比如下面这个例子除了上面条件外再加上且条件 CHAS为1,注意逻辑符号分开的条件要用 ()隔开。
df[(df['NOX']>df['NOX'].mean())& (df['CHAS'] ==1)].sort_values(by='NOX',ascending=False).head()
2. loc/iloc
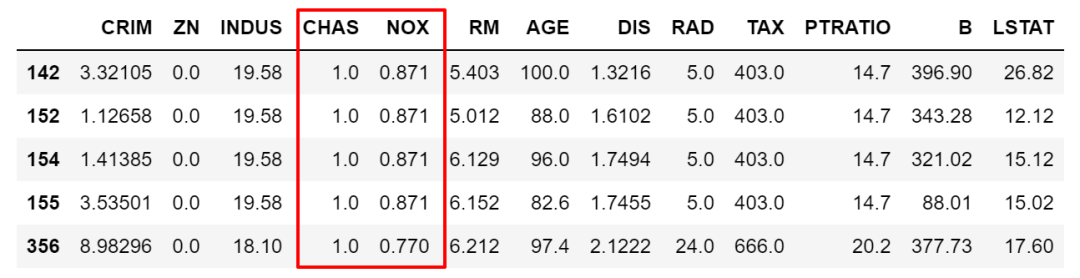
除 []之外, loc/iloc应该是最常用的两种查询方法了。 loc按标签值(列名和行索引取值)访问, iloc按数字索引访问,均支持单值访问或切片查询。除了可以像 []按条件筛选数据以外, loc还可以指定返回的列变量, 从行和列两个维度筛选。
比如下面这个例子,按条件筛选出数据,并筛选出指定变量,然后赋值。
df.loc[(df['NOX']>df['NOX'].mean()),['CHAS']] = 2
3. isin
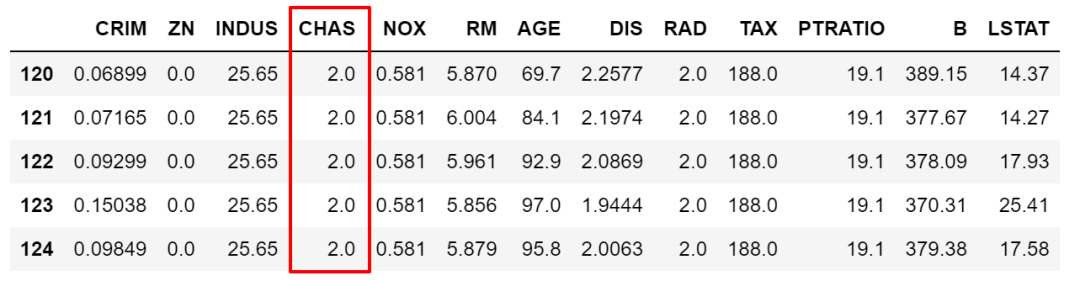
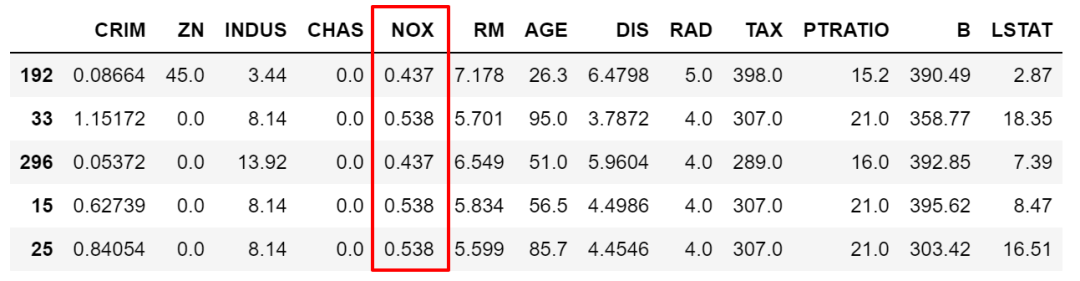
上面我们筛选条件 < > == !=都是个范围,但很多时候是需要锁定某些具体的值的,这时候就需要 isin了。比如我们要限定 NOX取值只能为 0.538,0.713,0.437中时。
df.loc[df['NOX'].isin([0.538,0.713,0.437]),:].sample(5)
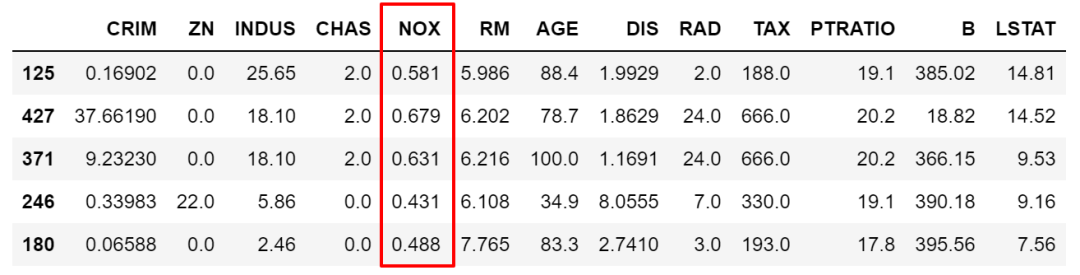
当然,也可以做取反操作,在筛选条件前加 ~符号即可。
df.loc[~df['NOX'].isin([0.538,0.713,0.437]),:].sample(5)
4. str.contains
上面的举例都是 数值大小比较的筛选条件,除数值以外当然也有 字符串的查询需求。 pandas里实现字符串的模糊筛选,可以用 .str.contains()来实现,有点像在SQL语句里用的是 like。
下面利用titanic的数据举例,筛选出人名中包含 Mrs或者 Lily的数据, |或逻辑符号在引号内。
train.loc[train['Name'].str.contains('Mrs|Lily'),:].head()

.str.contains()中还可以设置正则化筛选逻辑。
- case=True:使用case指定区分大小写
- na=True:就表示把有NAN的转换为布尔值True
- flags=re.IGNORECASE:标志传递到re模块,例如re.IGNORECASE
- regex=True:regex :如果为True,则假定第一个字符串是正则表达式,否则还是字符串
5. where/mask
在SQL里,我们知道 where的功能是要把满足条件的筛选出来。pandas中 where也是筛选,但用法稍有不同。
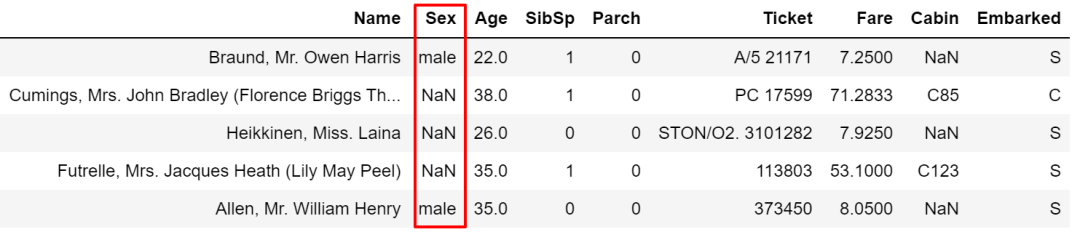
where接受的条件需要是 布尔类型的,如果不满足匹配条件,就被赋值为默认的 NaN或其他指定值。举例如下,将 Sex为 male当作筛选条件, cond就是一列布尔型的Series,非male的值就都被赋值为默认的 NaN空值了。
cond = train['Sex'] == 'male'
train['Sex'].where(cond, inplace=True)
train.head()
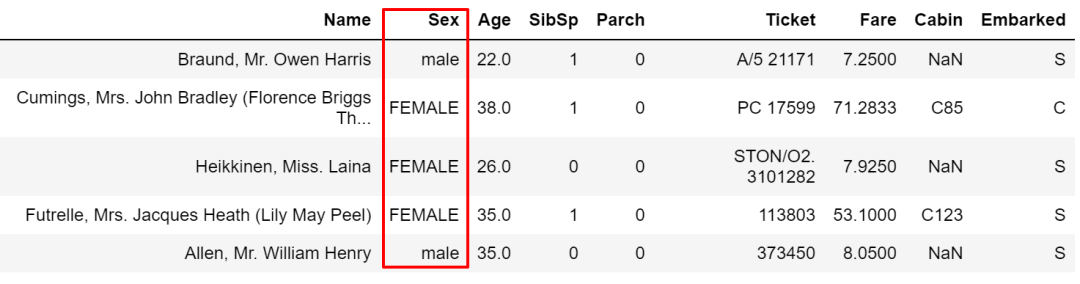
也可以用 other赋给指定值。
cond = train['Sex'] == 'male'
train['Sex'].where(cond, other='FEMALE', inplace=True)
甚至还可以写组合条件。
train['quality'] = ''
traincond1 = train['Sex'] == 'male'
cond2 = train['Age'] > 25
train['quality'].where(cond1 & cond2, other='低质量男性', inplace=True)
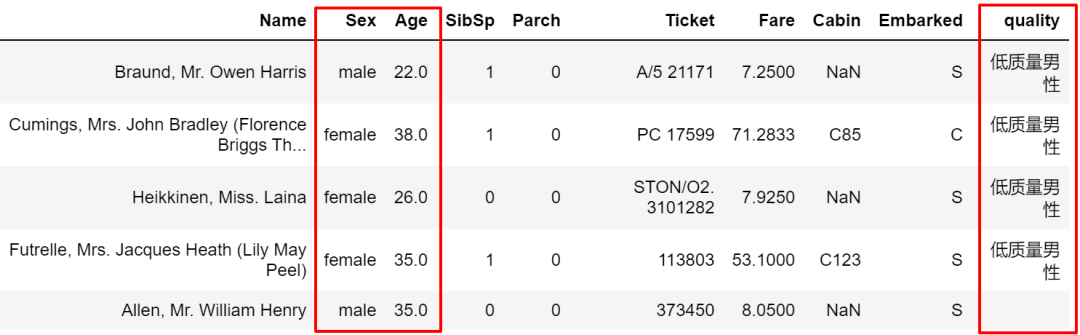
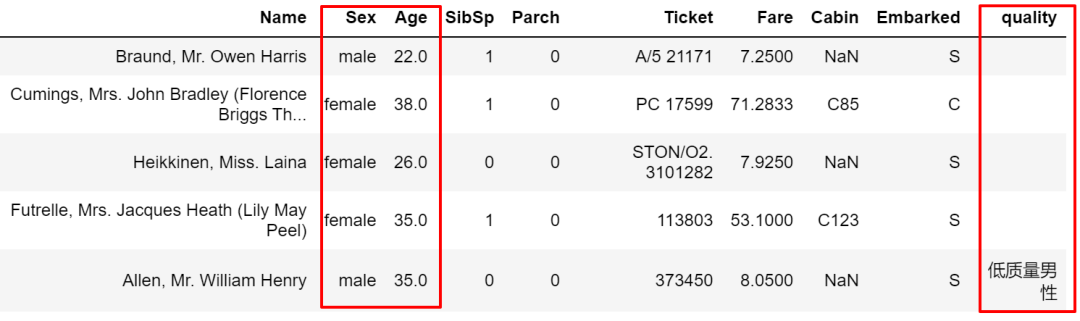
mask和 where是一对操作,与 where正好反过来。
train['quality'].mask(cond1 & cond2, other='低质量男性', inplace=True)
6. query
这是一种非常优雅的筛选数据方式。所有的筛选操作都在 ''之内完成。
train[train.Age > 25]
train.query('Age > 25')
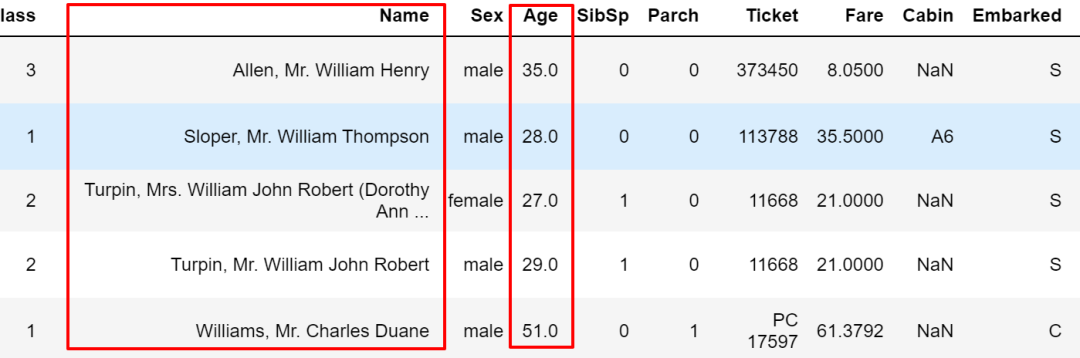
上面的两种方式效果上是一样的。再比如复杂点的,加入上面的 str.contains用法的组合条件,注意条件里有 ''时,两边要用 ""包住。
train.query("Name.str.contains('William') & Age > 25")
在 query里还可以通过 @来设定变量。
name = 'William'
train.query("Name.str.contains(@name)")
7. filter
filter是另外一个独特的筛选功能。 filter不筛选具体数据,而是筛选特定的行或列。它支持三种筛选方式:
- items:固定列名
- regex:正则表达式
- like:以及模糊查询
- axis:控制是行index或列columns的查询
下面举例介绍下。
train.filter(items=['Age', 'Sex'])

train.filter(regex='S', axis=1)
train.filter(like='2', axis=0)

train.filter(regex='^2', axis=0).filter(like='S', axis=1)
8. any/all
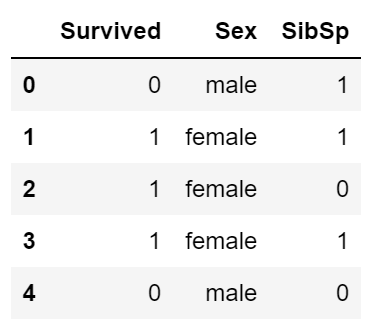
any方法意思是,如果至少有一个值为 True结果便为 True, all需要所有值为 True结果才为 True,比如下面这样。
>> train['Cabin'].all()
>> False
>> train['Cabin'].any()
>> True
any和 all一般是需要和其它操作配合使用的,比如查看每列的空值情况。
train.isnull().any(axis=0)

再比如查看含有空值的行数。
>>> train.isnull().any(axis=1).sum()
>>> 708
原创不易,欢迎点赞、留言、分享,支持我继续写下去。
推荐文章
- 李宏毅《机器学习》国语课程(2022)来了
- 有人把吴恩达老师的机器学习和深度学习做成了中文版
- 上瘾了,最近又给公司撸了一个可视化大屏(附源码)
- 如此优雅,4款 Python 自动数据分析神器真香啊
- 梳理半月有余,精心准备了17张知识思维导图,这次要讲清统计学
- 香的很,整理了20份可视化大屏模板
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过 2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号: dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号: Python学习与数据挖掘,后台回复:加群

Original: https://blog.csdn.net/qq_34160248/article/details/124390932
Author: Python数据挖掘
Title: Pandas 筛选数据的 8 个神操作
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/752645/
转载文章受原作者版权保护。转载请注明原作者出处!