

目录
3.2 按行遍历 DataFrame.itertuples()
3.2.1 DataFrame.itertuples() 语法
3.2.2 DataFrame.itertuples() 范例
3.3 按列遍历 DataFrame.iteritems()
3.3.1 DataFrame.iteritems() 语法
3.3.2 DataFrame.iteritems() 范例
对于 pandas.DataFrame 有以下三种遍历方法
- iterrows(): 按行遍历,将 DataFrame 的每一行迭代为 (index, data) 对,可以通过data[column_name] 和 data.column_name 对元素进行访问。
- itertuples(): 按行遍历,将 DataFrame 的每一行迭代为元祖,可以通过data[ 列号数值 ] 和 data.column_name 对元素进行访问,不能使用 row[ column_name ]对元素进行访问,比 iterrows() 效率高。
-
iteritems():按列遍历,将 DataFrame 的每一列迭代为(label, content)对,可以通过content[ index ] 对元素进行访问。
-
DataFrame 类型的遍历过程
先准备数据
import pandas as pd
import numpy as np
import pymysql
conn=pymysql.connect(host="127.0.0.1",user="root",password="wxf123",database="ivydb")
data=pd.read_sql('''SELECT * FROM human;''', con = conn)
data
生成数据如下


3.1 按行遍历 DataFrame.iterrows()
3.1.1 DataFrame.iterrows() 语法
首先,DataFrame.iterrows() 函数没有参数
其次,DataFrame.iterrows() 返回 Iterable 的 [index,data] 对,可以理解 index 即行名,data 即此行的数据,为 Series 类型。既然是 Iterable 类型的,意味着可以用 next 来逐步读取。
再次,对于读出来的 data,可以通过 data[column_name] 读取具体的某个元素
最后,请注意 应该永远不要修改您正在迭代的内容。这并不能保证在所有情况下都有效。取决于数据类型,迭代器返回的是一个副本而不是一个视图,如果你视图写入,这样做是没有效果的。
简单说,我建议在所有迭代过程中,都不要有写入过程。
Help on method iterrows in module pandas.core.frame:
iterrows() -> 'Iterable[Tuple[Label, Series]]' method of pandas.core.frame.DataFrame instance
Iterate over DataFrame rows as (index, Series) pairs.
Yields
------
index : label or tuple of label
The index of the row. A tuple for a MultiIndex.
data : Series
The data of the row as a Series.
See Also
--------
DataFrame.itertuples : Iterate over DataFrame rows as namedtuples of the values.
DataFrame.items : Iterate over (column name, Series) pairs.
Notes
-----
1. Because itertuples which returns namedtuples of the values
and which is generally faster than 3.1.2 DataFrame.iterrows() 范例
代码范例,此处使用大家最熟悉的 for 循环
for rowname,row in data.iterrows():
print("*"*50)
print(rowname)
print(type(row))
print(row)
结果如下,可以看到不同的行名和行数据,
**************************************************
0
id 1
title Teacher
age 36
location Beijing
comment 1982-01-01
Name: 0, dtype: object
**************************************************
1
id 2
title NewMan
age 3
location Shanghai
comment 1983-02-01
Name: 1, dtype: object
**************************************************
2
id 3
title Policeman
age 33
location Beijing
comment 1984-05-09
Name: 2, dtype: object
......................................................
9
id 10
title Singer
age 22
location Nanjing
comment 1982-01-01
Name: 9, dtype: object
如果想对某个元素来进行读取,有两种方式,第一种是 row.column_name
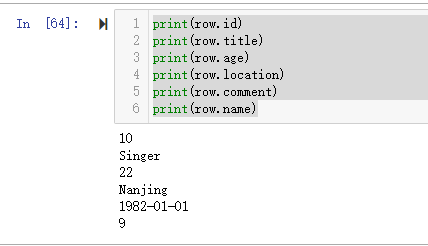
print(row.id)
print(row.title)
print(row.age)
print(row.location)
print(row.comment)
print(row.name)
运行结果如下
第二种方式是 row[column_name] 方式
print(row["id"])
print(row["title"])
print(row["age"])
print(row["location"])
print(row["comment"])
print(row["name"]) 不能用这个方式读 row 的名字,只能用 row. name 方式
运行结果如下

3.2 按行遍历 DataFrame.itertuples()
itertuples() 也是按照行来进行迭代,和 iterrows() 一样将返回一个迭代器,该方法会把 DataFrame 的每一行生成一个 元组,最关键的是比 iterrows() 效率高。 。
3.2.1 DataFrame.itertuples() 语法
itertuples(index: ‘bool’ = True, name: ‘Optional[str]’ = ‘Pandas’)
首先,和 iterrows() 不一样,itertuples() 有两个参数。
index: 布尔值,默认为 True,即返回的每行数据里面是否包含 index,如果为 False,则不包含
name:字符串或者为 None,默认为 “Pandas”,是返回的namedtuples的名字,如果为None,则名字也为空。
其次,.itertuples() 返回的是 默认是’pandas.core.frame. Pandas‘,是元组类型
Help on method itertuples in module pandas.core.frame:
itertuples(index: 'bool' = True, name: 'Optional[str]' = 'Pandas') method of pandas.core.frame.DataFrame instance Iterate over DataFrame rows as namedtuples.
Parameters
----------
index : bool, default True
If True, return the index as the first element of the tuple.
name : str or None, default "Pandas"
The name of the returned namedtuples or None to return regular
tuples.
Returns
-------
iterator
An object to iterate over namedtuples for each row in the
DataFrame with the first field possibly being the index and
following fields being the column values.
See Also
--------
DataFrame.iterrows : Iterate over DataFrame rows as (index, Series)
pairs.
DataFrame.items : Iterate over (column name, Series) pairs.
Notes
-----
The column names will be renamed to positional names if they are
invalid Python identifiers, repeated, or start with an underscore.
On python versions < 3.7 regular tuples are returned for DataFrames
with a large number of columns (>254).
Examples
--------
>>> df = pd.DataFrame({'num_legs': [4, 2], 'num_wings': [0, 2]},
... index=['dog', 'hawk'])
>>> df
num_legs num_wings
dog 4 0
hawk 2 2
>>> for row in df.itertuples():
... print(row)
...
Pandas(Index='dog', num_legs=4, num_wings=0)
Pandas(Index='hawk', num_legs=2, num_wings=2)
By setting the index parameter to False we can remove the index
as the first element of the tuple:
>>> for row in df.itertuples(index=False):
... print(row)
...
Pandas(num_legs=4, num_wings=0)
Pandas(num_legs=2, num_wings=2)
With the name parameter set we set a custom name for the yielded
namedtuples:
>>> for row in df.itertuples(name='Animal'):
... print(row)
...
Animal(Index='dog', num_legs=4, num_wings=0)
Animal(Index='hawk', num_legs=2, num_wings=2)
3.2.2 DataFrame.itertuples() 范例
现在我简化一下数据,这样可以看得更加清楚点

1) index 和 name 都为 默认的情况
for row in data.itertuples():
print("*"*50)
print(row)
print(type(row))
运行结果如下,可以看得结果中包含了 index,type 出来的类型名为 ‘pandas.core.frame. Pandas‘

如果想读取具体的元素,如下
print(row.id)
print(row.title)
print(row.age)
print(row.location)
#print(row.name) 此时不可读 row 的名字
print(row.index)
print(row.Index)
运行结果

此外,因为.itertuples() 返回的是 tuple 类型,所以不能使用 row[column_name]的方式读取

可以使用使用 row[column_no]的方式读取
print(row[0:3])
运行结果

2) 如果 index= False,name=”NewPandas”
for row in data.itertuples(index=False,name="NewPandas"):
print("*"*50)
print(row)
print(type(row))
运行结果如下:
可以看得结果中 不再包含了 index,type 出来的类型名为 ‘pandas.core.frame. NewPandas‘

3.3 按列遍历 DataFrame.iteritems()
DataFrame.iteritems()
3.3.1 DataFrame.iteritems() 语法
首先,.iteritems() 没有参数
其次,.iteritems() 生成[label,content] 数据对,对于具体的元素,可以通过 content[index] 和content.index 来读取
最后,
Help on method iteritems in module pandas.core.frame:
iteritems() -> 'Iterable[Tuple[Label, Series]]' method of pandas.core.frame.DataFrame instance
Iterate over (column name, Series) pairs.
Iterates over the DataFrame columns, returning a tuple with
the column name and the content as a Series.
Yields
------
label : object
The column names for the DataFrame being iterated over.
content : Series
The column entries belonging to each label, as a Series.
See Also
--------
DataFrame.iterrows : Iterate over DataFrame rows as
(index, Series) pairs.
DataFrame.itertuples : Iterate over DataFrame rows as namedtuples
of the values.
Examples
--------
>>> df = pd.DataFrame({'species': ['bear', 'bear', 'marsupial'],
... 'population': [1864, 22000, 80000]},
... index=['panda', 'polar', 'koala'])
>>> df
species population
panda bear 1864
polar bear 22000
koala marsupial 80000
>>> for label, content in df.items():
... print(f'label: {label}')
... print(f'content: {content}', sep='\n')
...
label: species
content:
panda bear
polar bear
koala marsupial
Name: species, dtype: object
label: population
content:
panda 1864
polar 22000
koala 80000
Name: population, dtype: int64
3.3.2 DataFrame.iteritems() 范例
代码范例,此处使用大家最熟悉的 for 循环
for columnname,column in data.iteritems():
print("*"*50)
print(columnname)
print(type(columnname))
print(column)
print(type(column))
结果如下,可以看到不同的列名和列数据,
**************************************************
id
1 2
2 3
3 4
Name: id, dtype: int64
**************************************************
title
1 NewMan
2 Policeman
3 CodingMan
Name: title, dtype: object
**************************************************
age
1 3
2 33
3 32
Name: age, dtype: int64
**************************************************
location
1 Shanghai
2 Beijing
3 Nanjing
Name: location, dtype: object
因为返回的 content (即代码中的 column) 是 series 类型,所以相关的读取可以参看 Series。
Original: https://blog.csdn.net/u010701274/article/details/121768096
Author: 江南野栀子
Title: Pandas 模块-操纵数据(3)-iteration 遍历
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/751950/
转载文章受原作者版权保护。转载请注明原作者出处!