

| 1.1 Pandas是什么?
Pandas是Python中最受欢迎的数据科学库之一。它使用起来很容易,它是基于 Numpy之上,并共享了许多功能和属性。
使用 Pandas,您可以从文件,转换和分析中读取和提取数据,计算统计数据和相关性!要开始使用 Pandas,我们需要首先导入:
import pandas as pd
Tips :pd是用于导入 Pandas 的最常用名称。
Pandas 是来自术语”panel data”,数据集的计量术语包括在同一个人的多个时间段内的观察。
| 1.2 Series & DataFrames
Pandas的两个主要组成是 Series和 DataFrame。
一个 Series基本上是一个列,并且 DataFrame是由系列集合组成的多维表。
以下的 DataFrame由两个 Series,年龄和高度组成 。
agesheights14165181802417642184
Tips :事实上你可以将一个 Series 视为一维数组,而 DataFrame 是多维数组。


| 2.1 创建DataFrames
在使用真实数据之前,让我们首先手动创建DataFrame以探索其功能。创建DataFrame的最简单方法是使用字典:
For example:
data = {
'ages': [14, 18, 24, 42],
'heights': [165, 180, 176, 184]
}
Tips :每个键都是一列,而值表示该列的数据的数组。现在,我们可以将此字典传递给DataFrame构造函数:
df = pd.DataFrame(data)
现在你可以运行以下这段代码去看看结果了。

DataFrame自动为每行创建一个数字索引。我们可以在创建DataFrame时指定自定义索引:
df = pd.DataFrame(data, index=['James', 'Bob', 'Amy', 'Dave'])

现在我们可以使用其索引和loc[]函数功能访问一行:
print(df.loc["Bob"])

Tips :注意,loc使用方括号 [ ] 指定索引。


| 3.1 索引(indexing)
我们可以通过在方括号中指定其名称来选择单个列:
print(df["ages"])
结果是一个系列对象。如果我们要选择多个列,我们可以指定列名称列表:
print(df[["ages", "heights"]])
这次,结果是DataFrame,因为它包含多个列。
Tips :当我们需要从数据集中仅选择列的一部分时,这是非常有用的。
| 3.2 切片(slicing)
Pandas使用 iloc函数基于其数字索引选择数据,类似于在python中的切片操作。
For example:
third row
print(df.iloc[2])
first 3 rows
print(df.iloc[:3])
rows 2 to 3
print(df.iloc[1:3])
Tips :iloc按照与Python列表的切片相同的规则。
| 3.3 条件(Conditions)
你可以提供一个条件作为索引来选择满足给定条件的元素。
例如,让我们选择年龄大于18且高度小于180的所有数据行:
print(df[(df['ages'] > 18) & (df['heights'] > 180)])
Tips :可以使用 &(and) 和 |(or)运算符组合条件 。
| 4.1 读数据(reading data)
数据以文件格式进行存储是相当普通的一件事情。最流行的文件格式之一是 CSV(comma-separated values)。 Pandas支持将数据从CSV文件中读取进入DataFrame。为了实现这个功能,我们可以使用 read_csv()函数:
df = pd.read_csv("csv_name")
Tips : Pandas还支持从Json文件以及SQL数据库中读取。
| 4.11 head & tail
一旦我们开始在DataFrame中拥有数据,我们就可以开始探索它。我们可以使用DataFrame的 head()函数来获取第一行数据。
print(df.head())

默认情况下,它返回前5行。您可以指示它返回您想要作为参数的行数。例如,df.head(10)将返回前10行。
Tips :同样,您还可以使用tail()函数返回尾部的行内容 。
| 4.12 info
info()函数用于获取有关数据集的基本信息,如行数、列,数据类型等:
df.info()
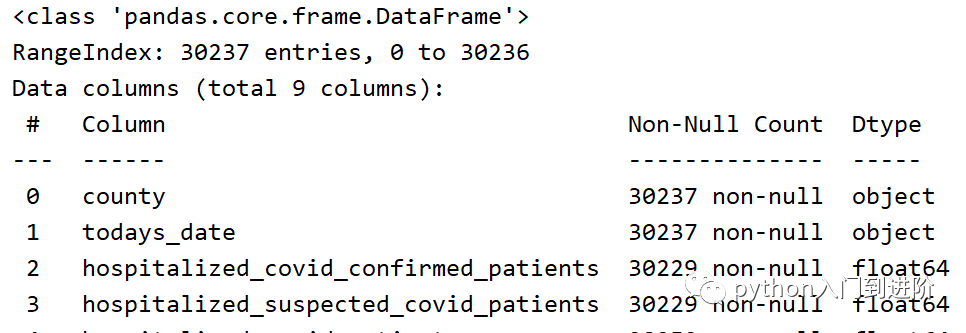
从结果中,我们可以看到我们的数据集包含30327行和9列,我们还可以看到pandas添加了一个自动生成的索引。我们还可以使用set_index()函数设置自己的索引列:
df.set_index("todays_date", inplace=True)
日期列是我们索引的不错选择,因为每个日期都有一行。
Tips :inplace=True参数指定更改将应用于我们的dataframe,而无需将其分配给新的dataframe 。
| 4.13 drop
你可以使用drop()函数来删除你并不需要的数据。
df.drop('county', axis=1, inplace=True)
drop()可以用来删除行和列。
asix=1指定我们要删除列。
asix=0指定我们要删除行。
注意现在我们的数据集是比之前更干净了!!!

| 5.1 创建列(Creating Columns)
Pandas允许我们创建自己的列。例如,我们可以根据日期添加一个月份列:
df['month'] = pd.to_datetime(df['todays_date']).dt.month_name()

我们通过将todays_date列转换为Datetime并从中提取月份的名称来执行此操作,将该值分配给新的month列。
| 5.2 汇总统计(Summary Statistics)
现在我们已经清洗并设置好了我们的数据集,我们已经准备好调查一些统计数据!
describe()函数返回所有数字列的摘要统计信息:
print(df.describe())
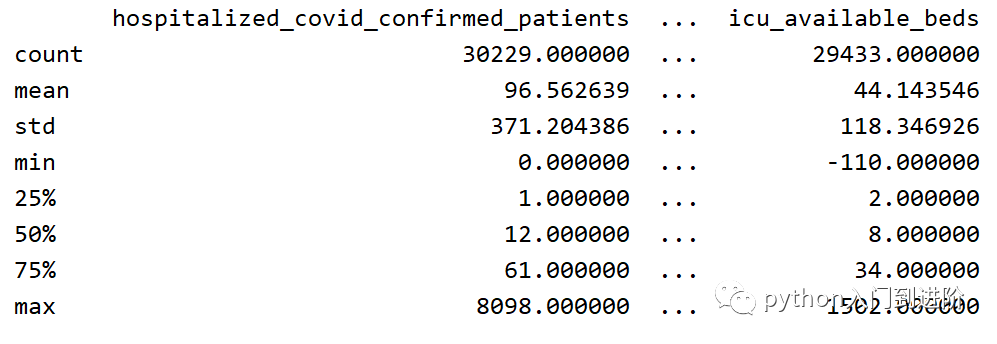
此功能将显示数字列的主要统计信息,例如均值,最大值,最小值等。运行代码看看结果吧。
Tips :我们也可以获得单列的摘要统计数据,例如:
print(df['icu_available_beds'].describe())

| 6.1 频率(Frequency)
由于我们有一个 month列,我们可以通过 value_counts()函数查看每月有多少条数据:
print(df['month'].value_counts())
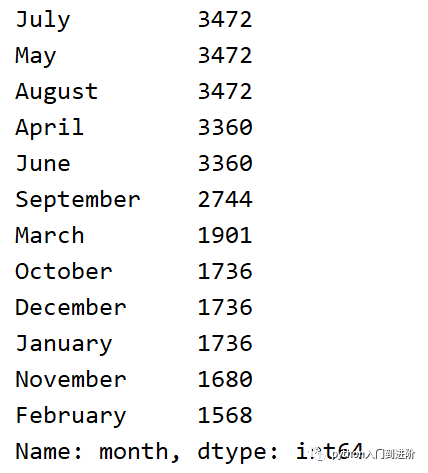
Tips :value_counts()返回的是值在数据集中出现的次数,也称为值的频率。
| 6.2 分组(Grouping)
现在我们可以计算数据洞察率力了!
例如,让我们确定每个月的总感染人数。
为此,我们需要按月份列对数据进行分组,然后计算每个月的案例栏的总和:
print(df.groupby('month')['hospitalized_covid_confirmed_patients'].sum())
group()函数用于按给定列对数据集进行分组,我们也可以计算全年总病例人数:
print(df['hospitalized_covid_confirmed_patients'].sum())

| 7.1 写在最后
本节给大家介绍了数据科学三剑客之一的pandas。涉及到了常见的属性和函数,并且介绍了常见的操作。后续我们会继续介绍matplotlib。希望大家还是动手做一做,有问题可以私信我,欢迎交流和提出您的宝贵意见。
你要偷偷学Python,然后惊艳所有人。


-END-
感谢大家的关注
你关心的,都在这里
Original: https://blog.csdn.net/Zesheng_Wang/article/details/123753250
Author: 此间过客~
Title: 数据科学—使用Pandas进行操作数据
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/751731/
转载文章受原作者版权保护。转载请注明原作者出处!