

目录
1.911数据分析实战
如果遇到文件的数据量比较大,默认打印无法全部显示。
可以尝试输入以下代码:
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',100)
以911数据为例,title下存放各种紧急情况的类型。


将title下数据取出,发现只需要最前面的元素


先遍历再逐个取第一个元素,再转变为集合去重,发现一共就3个分类。

构造全为0的数组来统计3个类别的数目。
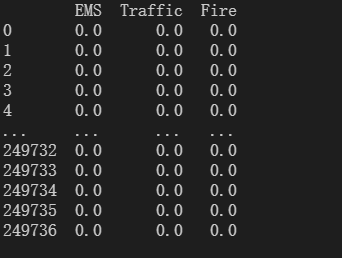
遍历数据,就所属的类别赋值为1。
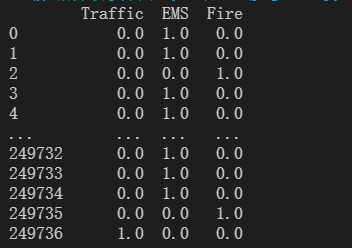
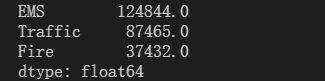
将统计好的结果进行求和
完整代码如下:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.read_csv("./911.csv")
pd.set_option('display.max_columns', None)
print(df.head(5))
print(df.info())
#获取分类
print()df["title"].str.split(": ")
temp_list = df["title"].str.split(": ").tolist()
#print(temp_list)
cate_list = list(set([i[0] for i in temp_list]))
#print(cate_list)
#构造全为0的数组 并修改列索引
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(cate_list))),columns=cate_list)
#print(zeros_df)
#赋值 遍历将对应位置赋值为1
for cate in cate_list:
zeros_df[cate][df["title"].str.contains(cate)] = 1
# break
print(zeros_df)
sum_ret = zeros_df.sum(axis=0)
print(sum_ret)
也可以新增一列cate用来存放类别,再进行求和统计。
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.read_csv("./911.csv")
#print(df.head(5))
#获取分类
print()df["title"].str.split(": ")
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
print(df["cate"].head(5))
print(df.groupby(by="cate").count()["title"])
2.pandas时间序列

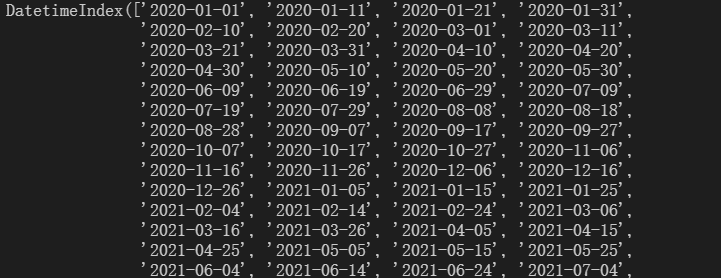
t1=pd.date_range(start='20200101',end='20220203',freq='10d')
print(t1)
pandas重采样:
重采样:指的是将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据为降采样,低频率转化为高频率为升采样。
针对911数据中,统计不同月份电话次数。
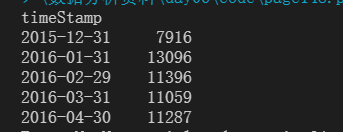
以折线图形式表示。

ps:第一个月和最后一个月次数较少是由于数据的不完整导致的。
完整代码如下:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.read_csv("./911.csv")
#将时间改为pandas中时间格式
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
#修改索引
df.set_index("timeStamp",inplace=True)
#print(df.head(5))
#统计出911数据中不同月份电话次数的
count_by_month = df.resample("M").count()["title"]
#print(count_by_month.head(5))
#画图
_x = count_by_month.index
_y = count_by_month.values
#时间只保留年月日,去掉时分秒
_x = [i.strftime("%Y%m%d") for i in _x]
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y)
#旋转避免重叠
plt.xticks(range(len(_x)),_x,rotation=45)
plt.show()
接下来针对每一个类别的数目进行统计并绘制折线图。
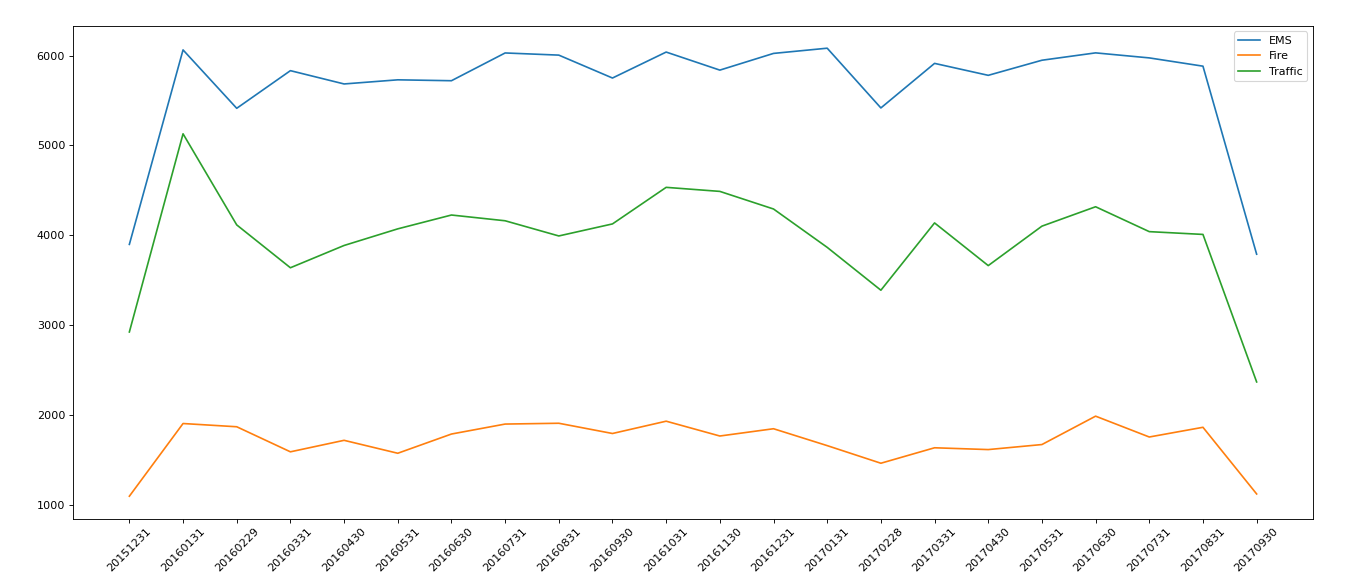
完整代码如下:
#911数据中不同月份不同类型的电话的次数的变化情况
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
#把时间字符串转为时间类型设置为索引
df = pd.read_csv("./911.csv")
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
#添加列,表示分类
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
print(np.array(cate_list).reshape((df.shape[0],1)))
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
#保证索引的一致性
df.set_index("timeStamp",inplace=True)
#print(df.head(1))
plt.figure(figsize=(20, 8), dpi=80)
#对按类别分组后的数据进行遍历
for group_name,group_data in df.groupby(by="cate"):
#对不同的分类都进行绘图 按照月份进行分组
count_by_month = group_data.resample("M").count()["title"]
# 画图
_x = count_by_month.index
print(_x)
_y = count_by_month.values
_x = [i.strftime("%Y%m%d") for i in _x]
plt.plot(range(len(_x)), _y, label=group_name)
#在完成三个类别的绘画以后再进行调整 最后再进行show
plt.xticks(range(len(_x)), _x, rotation=45)
plt.legend(loc="best")
plt.show()
3.pm2.5项目实战
查看文件内容和相关信息
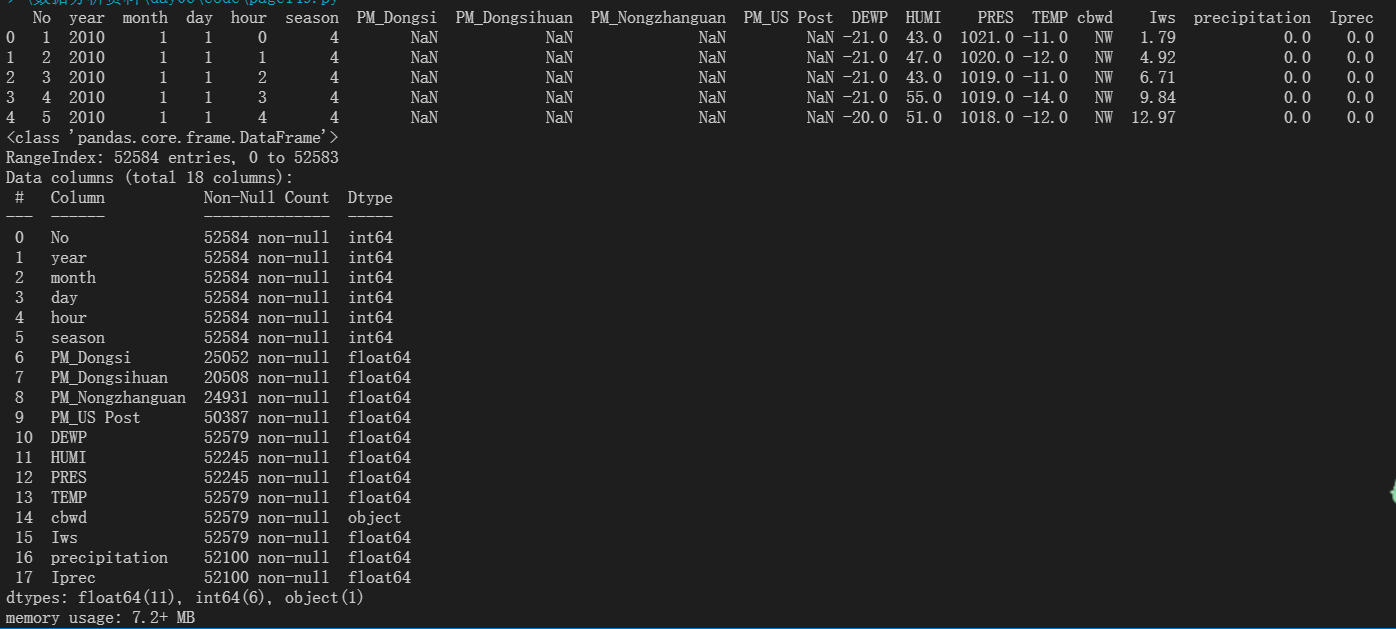
上图中时间:年月日分开对应不同的列,通过PeriodIndex()可以将数据中的分离的时间字段,重组为时间序列,并指定为index。
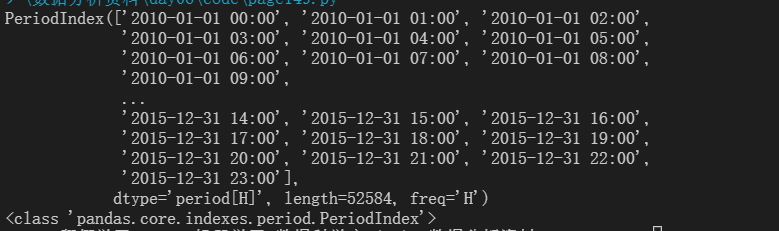
向读取的文件中新增datatime列

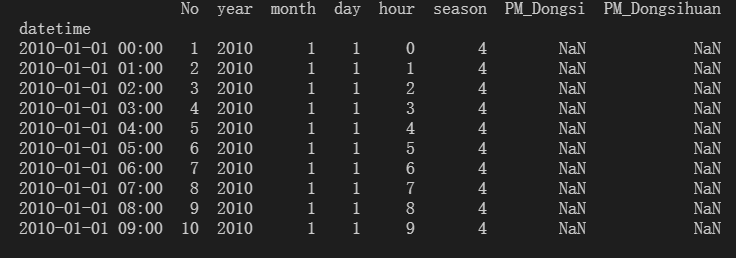
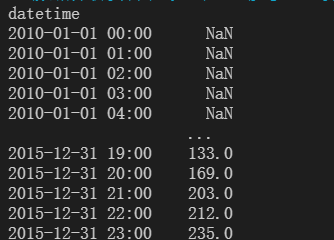
原数据按照小时进行记录,数据过于密集,重新修改采样区间为7天。

进行dropna操作时,结果如下
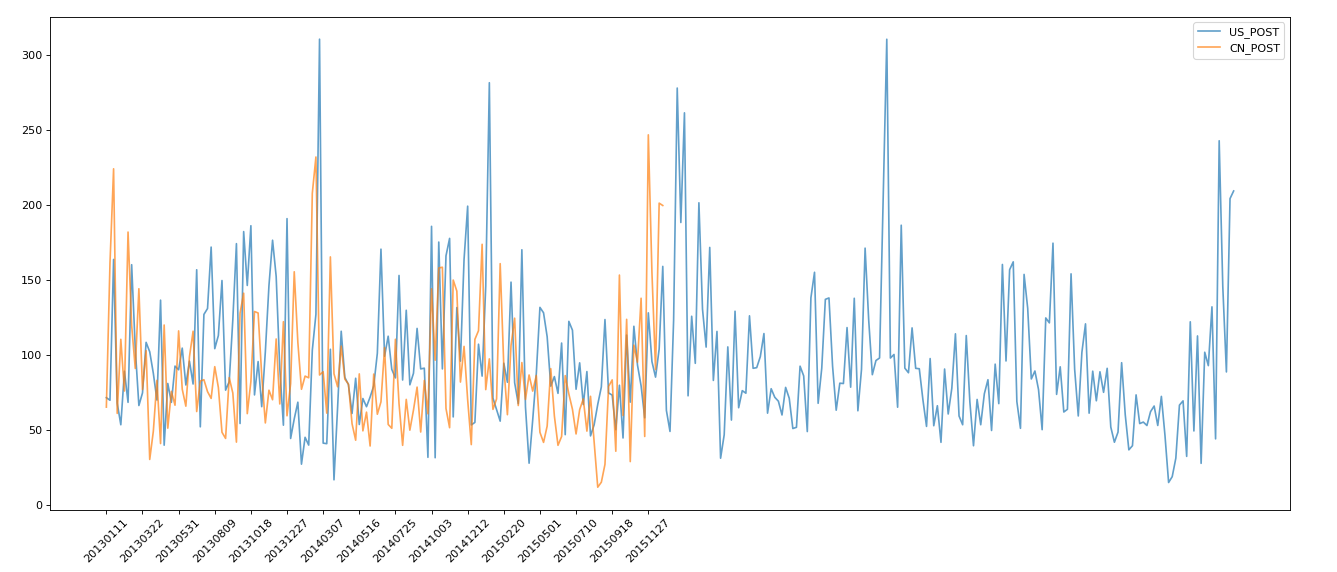
不进行dropna操作时,结果如下
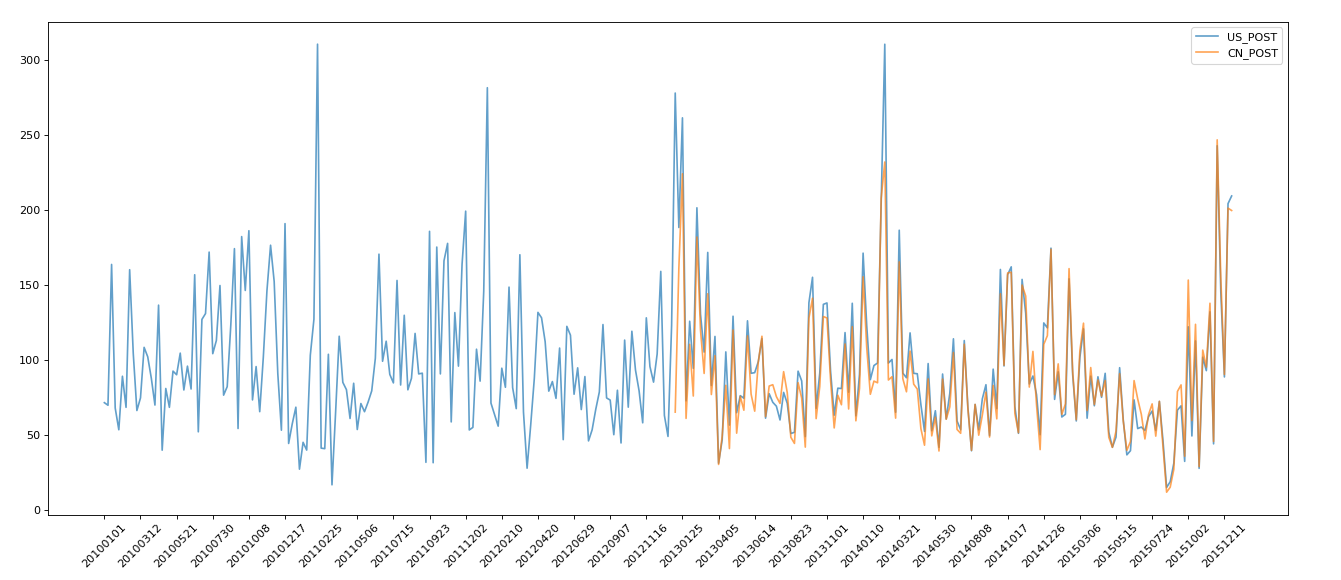
观察发现黄色的图像在两个操作后是一样的,说明数据存在缺失。
Original: https://blog.csdn.net/kongqing23/article/details/122299245
Author: kongqing23
Title: python数据分析day6
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/751491/
转载文章受原作者版权保护。转载请注明原作者出处!