

文章目录
*
– 数据合并之merge
– 数据合并之join
– 示例
– 分组
– 索引和复合索引
–
+ 简单的索引操作
+ Series复合索引
+ DataFrame复合索引
– 生成一段时间范围
– pandas重采样
示例
问题
:统计电影分类genre的情况,应该如何处理数据
思路: 重新构造一个全为0的数组,列名为分类,如果某一条数据中分类出现过,就让0变为1
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
file_path = './dataCSV/data.csv'
df = pd.read_csv(file_path)
print(df["Genre"].head(3))
temp_list = df["Genre"].str.split(",").tolist()
genre_list = list(set([i for j in temp_list for i in j]))
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns=genre_list)
for i in range(df.shape[0]):
zeros_df.loc[i,temp_list[i]] = 1
gener_count= zeros_df.sum(axis=0)
print(gener_count)
gener_count = gener_count.sort_values()
_x = gener_count.index
_y = gener_count.values
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(_x)),_y,width=0.4)
plt.xticks(range(len(_x)),_x)
plt.show()
数据合并之merge


; 数据合并之join

示例
import numpy as np
import pandas as pd
df1= pd.DataFrame(np.ones((2,4)),index=["A","B"],columns=list("abcd"))
print(df1)
print("*"*100)
df2 = pd.DataFrame(np.zeros((3,3)),index=["A","B","C"],columns=list("xyz"))
print(df2)
print("*"*100)
print(df1.join(df2))
print("*"*100)
print(df2.join(df1))
print("*"*100)
df3 = pd.DataFrame(np.arange(9).reshape((3,3)),columns=list("fax"))
print(df3)
print("*"*100)
print(df1.merge(df3,on="a"))
print("*"*100)
df1.loc["A","a"] = 100
print(df1)
print("*"*100)
print(df1.merge(df3,on="a"))
print("*"*100)
print(df1.merge(df3,on='a',how="inner"))
print("*"*100)
print(df1.merge(df3,on='a',how="outer"))
print("*"*100)
print(df1.merge(df3,on='a',how="left"))
print("*"*100)
print(df1.merge(df3,on='a',how="right"))
print("*"*100)
运行结果:

分组
grouped = df.groupby(by="columns_name")
grouped是一个 DataFrameGroupBy对象,是 可迭代的,grouped中的每一个元素是 一个元组,元组里面是 (索引(分组的值), 分组之后的DataFrame)

import pandas as pd
file_path = './dataCSV/data.csv'
df = pd.read_csv(file_path)
grouped = df.groupby(by="Country")
print(grouped)
df[df["Country"]=="US"]
country_count = grouped["Brand"].count()
print(country_count["US"])
china_data = df[df["Country"] == "CN"]
grouped = china_data.groupby(by="State/Province").count()["Brand"]
print(grouped)
grouped = df["Brand"].groupby(by=[df["Country"],df["State/Province"]]).count()
print(grouped)
print(type(grouped))
grouped1 = df[["Brand"]].groupby(by=[df["Country"],df["State/Province"]]).count()
grouped2 = df.groupby(by=[df["Country"],df["State/Province"]])[["Brand"]].count()
grouped3 = df.groupby(by=[df["Country"],df["State/Province"]]).count()[["Brand"]]
① 返回Series类型:

② 返回DataFrame类型:

索引和复合索引
简单的索引操作
- 获取index:
df.index - 指定index:
df.index = ['x','y'] - 重新设置index:
df.reindex(list("abcdef")) - 指定某一列作为index:
df.set_index("Country",drop=False) - 返回index的唯一值:
df.set_index("Country").index_unique()
Series复合索引

此外:
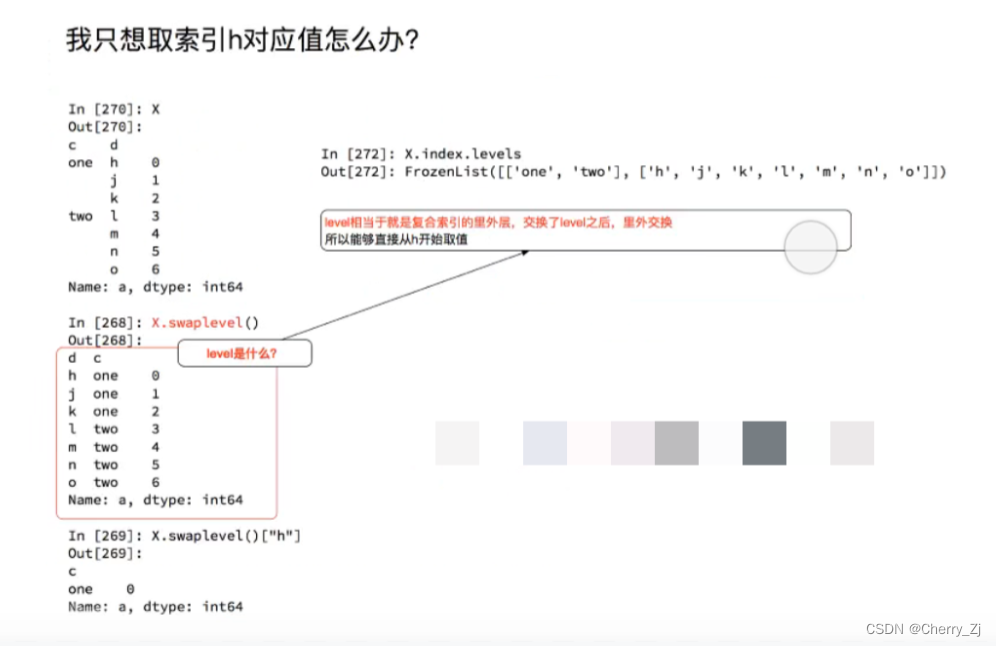
; DataFrame复合索引

生成一段时间范围
pd.date_range(start=None,end=None,periods=None,freq='D')
①start和end以及freq配合能够 生成start和end范围内以 频率freg的一组时间索引
②start和periods以及freq配合能够生成从start开始的频率为freq的 periods个时间索引

关于频率的缩写:

示例:在DataFrame中使用时间序列
index=pd.date_range(" 20170101" ,periods=10)
df = pd.DataFrame(np.random.rand(10),index=index)
format参数大部分情况下可以不用写,但是对于pandas无法格式化的时间字符串,我们可以使用该参数,比如包含中文
df["timeStamp"] = pd.to_datetime(df"timeStamp" ],format=")
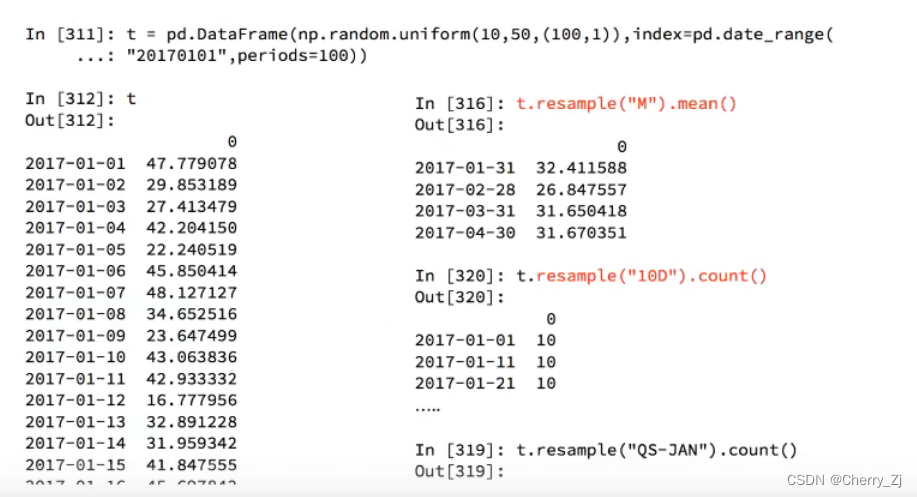
pandas重采样
重采样:指的是将时间序列从 一个频率转化为另一个频率进行处理的过程,将 高频率数据转化为低频率数据为 降采样, 低频率转化为高频率为 升采样
pandas提供了一个 resample的方法来帮助我们 实现频率转化
Original: https://blog.csdn.net/Cherry_Zj/article/details/126215703
Author: Cherry_Zj
Title: pandas之数据的合并与分组
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/751083/
转载文章受原作者版权保护。转载请注明原作者出处!