

一、什么是DataFrame
DataFrame是一种 表格型的数据结构。它的每一列可以是不同的值类型(例如布尔型、数值型、字符串等),此外它 既有行索引index,又有列索引columns。我们可以将它看成是 由Series组成的字典(将每一列看成是一个Series)。
二、DataFrame的创建
- *Pandas.DataFrame( data, index, columns, dtype, copy )
编号参数描述1data数据可采取各种形式,例如:ndarray、series、map、list、dict、constant、DataFrame。2index行标签。如果没有传递索引值,可选的默认语法是np.arange(n)。3columns列标签。如果没有传递索引值,可选的默认语法为np.arange(n)。4dtype每一列的数据类型。5copy默认值为False,用于复制数据。
1、通过传入列表创建:
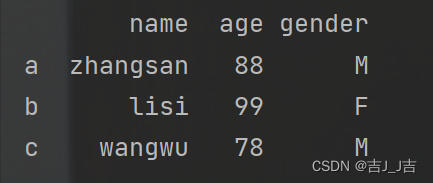
data=[['zhangsan',88,'M'],['lisi',99,'F'],['wangwu',78,'M']]
columns=['name','age','gender']
index=['a','b','c']
df=pd.DataFrame(data=data,index=index,columns=columns)
print(df)
运行结果:

2、通过传入dict创建:
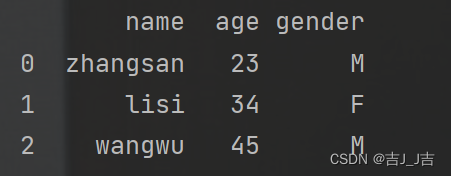
data={'name':['zhangsan','lisi','wangwu'],'age':[23,34,45],'gender':['M','F','M']}
df=pd.DataFrame(data=data)
print(df)
运行结果:
3、通过传入dataframe创建:
通过观察结果可以发现,相当于是通过index和columns的值对原dataframe进行了索引得到的一个新的dataframe。如果在原表中没有找到相应的行或列,会自动补充NaN。
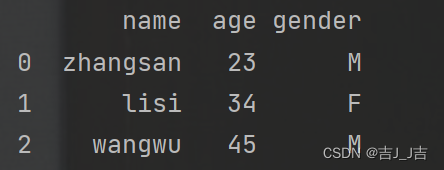
data={'name':['zhangsan','lisi','wangwu'],'age':[23,34,45],'gender':['M','F','M']}
df=pd.DataFrame(data=data)
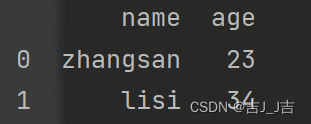
tmp1=pd.DataFrame(data=df,index=[0,1],columns=['name','age'])
tmp2=pd.DataFrame(data=df,index=['a','b','c'])
print(df)
print(tmp1)
print(tmp2)
运行结果:
df表:
tmp1:
tmp2:

三、读写文件
1、读文件:
- pd.read_csv(文件路径) #读csv文件,返回DataFrame对象
- *pd.read_excel(文件路径) #读excel文件,返回DataFrame对象
2、写文件:
- df.to_csv(文件路径)
- *df.to_excel(文件路径)
四、DataFrame的索引:
1、df [列名] :返回series
2、df [ [列名1,列名2] ]:返回DataFrame
3、df [ 起始行(include):结束行(exclude) ]:返回索引值所对应的行组成的DataFrame。
4、df [布尔列表]:返回列表中为True的行组成的DataFrame (布尔列表的长度必须与df的行数相同,且返回的DataFrame的索引是原表中的对应的索引)
5、df [多条件布尔查询]:使用’&’和’|’连接查询条件。
注意:多条件布尔查询时,不能用and或or代替’&’和’|’。因为and和or它要求所连接的是真实的True或False,而例如df_baby_name[‘Count’]>85000这样的条件语句返回的是一个series,而不是True或False,因此要用&代替and,用|代替or。
6、loc索引:
df.loc[行维度,列维度]——标签选择
行维度:标签索引、标签切片(include:include) 、标签列表、
列维度:标签索引、标签切片(include:include) 、标签列表、
举例:
data=pd.read_csv('elections.csv') #数据
print(data.head()) #展示前几行
数据示例:

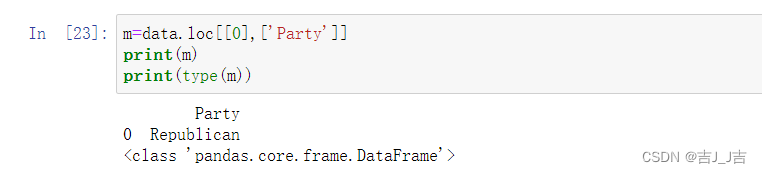
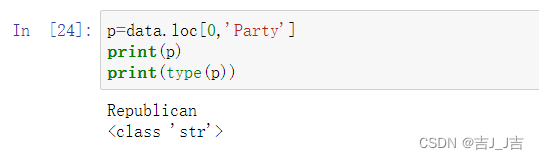
标签索引:
data.loc[0,'Party'] #标签索引
结果:
'Republican' #类型为str
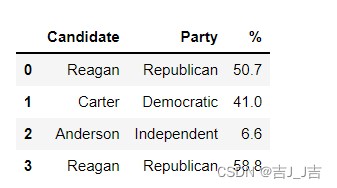
标签切片:
data.loc[0:3,'Candidate':'%'] #标签切片,因为是标签构成的切片,
#因此(include:include),这里比较特殊!
结果:
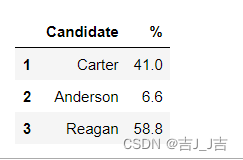
标签列表:
data.loc[[1,2,3],['Candidate','%']] #标签列表
结果:
布尔数组:
data.loc[(data['%']
结果:

注意:易混淆的返回结果类型。


7、iloc索引:
df.iloc[行索引,列索引]——索引选择
行索引:整数索引、整数切片(include:exclude)、整数列表、
列索引:整数索引、整数切片(include:exclude)、整数列表、
举例:
data.iloc[0,0]
结果:

整数切片:
data.iloc[0:2,0:2]
结果:
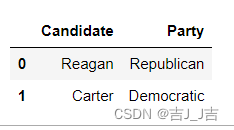
整数列表:
data.loc[[1,2,3],['Candidate','%']]
结果:
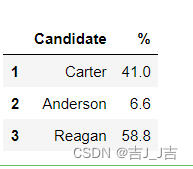
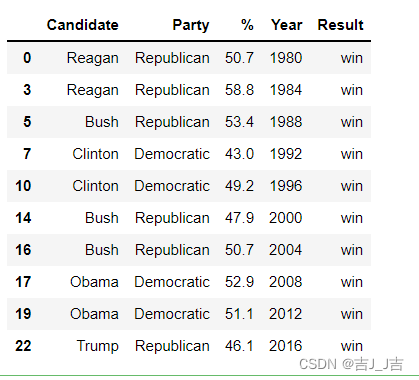
布尔数组:iloc里的布尔表达式最后必须加.values,否则会报错哦!
data.iloc[(data['Result']=='win').values,:]
结果:
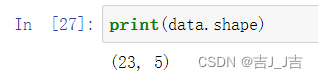
五、DataFrame的常用属性:
- shape:返回行数和列数。
- size:DataFrame的行数*列数,即元素的总个数
- index:返回行索引或行标签列表

- columns:返回列标签列表

六、DataFrame的常用方法:
- head(n) / tail(n):返回dataframe的前/后n行,默认参数为5行
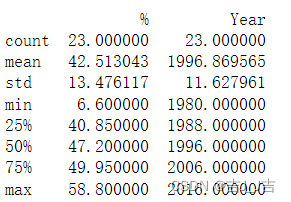
- describe():显示每一列的描述性统计分析
print(data.describe())
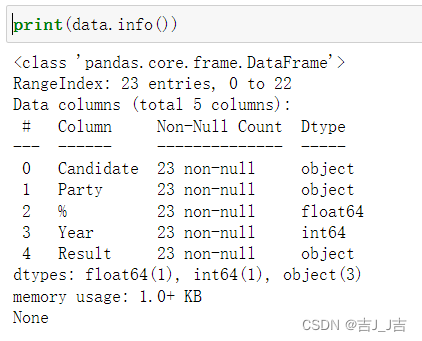
- info():显示dataframe相关信息,包括每一列的非空值数量和数据类型
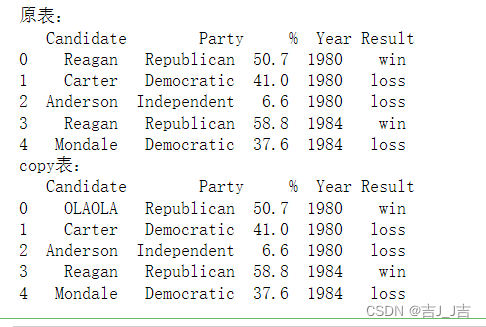
- copy():复制DataFrame的值和指针。
与 = 赋值运算不同的是,copy后得到的是一个新的一模一样的DataFrame,修改copy后的表的值并不改变原来的DataFrame,但是修改=复制后的表的值会改变原来的DataFrame。
举例:
data_copy=data.copy()
data_copy.iloc[0,0]='OLAOLA'
print('原表:\n',data.head())
print('copy表:\n',data_copy.head())
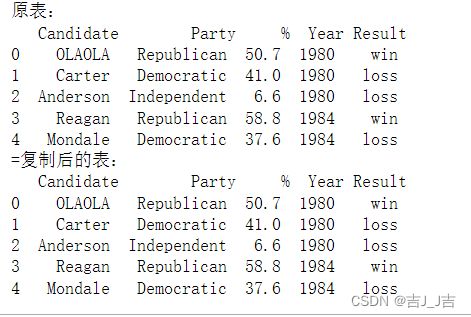
举例:
data_equal=data
data_equal.iloc[0,0]='OLAOLA'
print('原表:\n',data.head())
print('=复制后的表:\n',data_equal.head())
- sort_values():DataFrame调用该方法将返回按照指定列排序后的dataFrame对象。
df.sort_values(‘指定列’,ascending=True):按指定列升序排列(默认)
df.sort_values(‘指定列’,ascending=False):按指定列降序排列
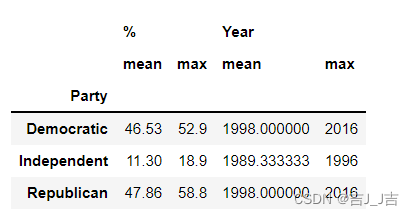
- groupby(列名):返回按照指定列名进行分组的DataFrameGroupBy对象,其实就是一个字典,key由指定列名的值组成,values即key对应的DataFrame。
- df.groupby(列名).agg([聚合函数]): 分组后再聚合,常用聚合函数有’min’,’mean’,’max’,’count’,’sum’等。
举例:
data.groupby('Party').agg(['mean','max'])
- concat():拼接,将两个DataFrame拼接成为一个DataFrame。
concat(
objs, #需要拼接对象,一般为列表或字典
axis=0 #axis=0为行拼接,axis=1为列拼接
join='outer', #out时外连接
join_axea=None,
ignore_index=False,
keys=None,
levels=None,
names=None,
verigy_integrity=False)
下期见!
Original: https://blog.csdn.net/m0_55807855/article/details/126896741
Author: 吉J_J吉
Title: Pandas基础学习笔记(二)——DataFrame用法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/750919/
转载文章受原作者版权保护。转载请注明原作者出处!