

文章目录
- 前言
- 一、DataFrame创建
* - 1.基于列表(或numpy.ndarray)创建
- 2.基于字典创建
- 3.读取csv文件的方式
- 二、查询
* - 1.df直接查询
– - 2.query()方法
– - 3.查询行索引值
- 4.模糊查询 (必须是字符串类型)
- 三、增加
* - 1.增加列
– - 2.增加行
– - 四、更新(改)
* - 1. 更新整行值
- 2.更新整列值
- 3. 更新某个值
- 4.更新某一整列的数值类型
- 5.将某一列日期(字符串/object类型)格式进行调整
- 6.更改某一列的列名,以及设置index名称,并将index设置为一列
- 五、删除
* - 1. 删除行
- 2. 删除列
- 六、聚合(合并)
* - 1、group by操作
- 2、join操作
- 七、遍历
- 八、转换
* - 1、字典和dataFrame的相互转换
- 2、数据类型转换
- 3、把Nan值转换成None值
- 九、其他
* - 1、去除有Nan值的行
- 2、pandas生成时间列表
前言
本篇文章将会持续更新,记录在日常工作中,容易遇到的pandas库DataFrame中的常用操作。
一、DataFrame创建
1.基于列表(或numpy.ndarray)创建
方式一:
data = [['Jack', 10], ['Tom', 12], ['Lucy', 13]]
columns = ['Name', 'Age']
df_by_list = pd.DataFrame(data, columns=columns)
print(df_by_list)
方式二:
data = [
{'name': 'Jack', 'Age': 10},
{'name': 'Tom', 'Age': 12},
{'name': 'Lucy', 'Age': 13}
]
df = pd.DataFrame(data)
print(df)
输出:
Name Age
0 Jack 10
1 Tom 12
2 Lucy 13
2.基于字典创建
row = {
'Name': ['Jack', 'Tom', 'Lucy'],
'Age': [10, 12, 13]
}
df_by_dict = pd.DataFrame(row)
print(df_by_dict)
输出:
Name Age
0 Jack 10
1 Tome 12
2 Lucy 13
3.读取csv文件的方式
csv文件样式:
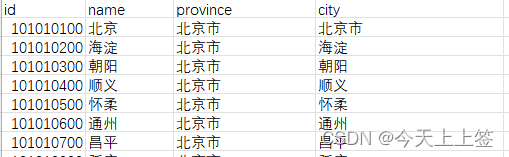

df = pd.read_csv('city.csv')
print(df.head(5))
输出:
id name province city
0 101010100 北京 北京市 北京市
1 101010200 海淀 北京市 海淀
2 101010300 朝阳 北京市 朝阳
3 101010400 顺义 北京市 顺义
4 101010500 怀柔 北京市 怀柔
二、查询
1.df直接查询
① 查询一列
names = df['Name'].tolist()
print(names)
输出:
['Jack', 'Tom', 'Lucy']
② 查询多列
names = df[['Name','Age']]
print(names)
输出:
Name Age
0 Jack 10
1 Tom 12
2 Lucy 13
③ 条件查询
ages = df[(df['Age'] > 10) & (df['Age'] < 13)]
print(ages)
输出:
Name Age
1 Tom 12
2.query()方法
① 条件查询
result = df.query('Age > 10 & Age < 13')
print(result)
输出:
Name Age
1 Tom 12
② 带有变量的查询(用@变量)
names = ['Tom', 'Lily', 'Sam']
result = df.query('Name not in @names')
print(result)
输出:
Name Age
0 Jack 10
2 Lucy 13
3.查询行索引值
例如我现在想查Name字段为Tom的行索引:
print(df)
index = df[df['Name'] == "Tom"].index.tolist()[0]
print("Tom所在行的索引:", index)
输出:
Name Age
0 Jack 10
1 Tom 12
2 Lucy 13
Tom所在行的索引: 1
4.模糊查询 (必须是字符串类型)
例如我想对Sdate字段进行模糊查询,查询2023年的数据:
data = [['20201001', 10], ['20201002', 12], ['20201003', 13],['20231003', 13]]
columns = ['Sdate', 'type']
df = pd.DataFrame(data, columns=columns)
df = df[df['Sdate'].str.contains('2023')]
print(df)
输出:
Sdate type
3 20231003 13
此种模糊查询方法也支持正则表达式:例如我要查询开头是2023的数据:
data = [['20201001', 10], ['20201002', 12], ['20202303', 13],['20231003', 13]]
columns = ['Sdate', 'type']
df = pd.DataFrame(data, columns=columns)
df = df[df['Sdate'].str.contains('^2023')]
print(df)
输出:
Sdate type
3 20231003 13
三、增加
1.增加列
① 直接加:在最后一列加新的列
df['Gender'] = ['M', 'M', 'F']
print(df)
输出:
Name Age Gender
0 Jack 10 M
1 Tom 12 M
2 Lucy 13 F
② insert方法:可以指定位置加
df.insert(0, 'Gender', ['M', 'M', 'F'])
print(df)
输出:
Gender Name Age
0 M Jack 10
1 M Tom 12
2 F Lucy 13
2.增加行
① loc函数:增加一行
df.loc[len(df.index)] = ('Lily', 20)
print(df)
输出:
Name Age
0 Jack 10
1 Tom 12
2 Lucy 13
3 Lily 20
注意: 如果不加在最后一行,数据将会被替换,例:
df.loc[1] = ('Lily', 20)
print(df)
输出:
Name Age
0 Jack 10
1 Lily 20
2 Lucy 13
② 增加多行
data1 = [['Lily', 23], ['Sam', 35]]
columns1 = ['Name', 'Age']
df1 = pd.DataFrame(data1, columns=columns1)
df2 = pd.concat([df, df1], ignore_index=True)
print(df2)
输出:
Name Age
0 Jack 10
1 Tom 12
2 Lucy 13
3 Lily 23
4 Sam 35
注意:
1.ignore_index=True 参数表示重新设置索引
2.append方法即将过时,建议用concat方法
3.concat方法要求两个df需要有相同的列名
四、更新(改)
1. 更新整行值
data1 = [['Lily', 23], ['Sam', 35]]
columns1 = ['Name', 'Age']
new_df = pd.DataFrame(data1, columns=columns1)
df.update(new_df)
print(df)
输出:
Name Age
0 Lily 23.0
1 Sam 35.0
2 Lucy 13.0
2.更新整列值
import pandas as pd
t1 = pd.DataFrame({'A': [1, 2, 3, 4],
'B': [5, 6, 7, 8]})
t2 = pd.DataFrame({'B': [10, 11, 12, 13]})
t1.update(t2)
print(t1)
输出:
A B
0 1 10
1 2 11
2 3 12
3 4 13
3. 更新某个值
① 通过顺序数字索引修改:
df.iloc[0, 1] = 25
print(df)
输出:
Name Age
0 Jack 25
1 Tom 12
2 Lucy 13
② 通过实际设置的索引来修改:
df.loc[0, 'Age'] = 25
print(df)
输出:
Name Age
0 Jack 25
1 Tom 12
2 Lucy 13
4.更新某一整列的数值类型
例如将 Sdate列由数值型更改为字符串类型:
data = [[20201001, 10], [20201002, 12], [20201003, 13]]
columns = ['Sdate', 'type']
df = pd.DataFrame(data, columns=columns)
print(df)
print("Sdate开始类型:",df['Sdate'].dtypes)
df['Sdate'] = pd.Series(df['Sdate'], dtype="string")
print("Sdate改变后类型:",df['Sdate'].dtypes)
输出:
Sdate type
0 20201001 10
1 20201002 12
2 20201003 13
Sdate开始类型: int64
Sdate改变后类型: string
将将 Sdate列由字符串(object)型更改为日期类型(两种方法):
data = [['20201001', 10], ['20201002', 12], ['20201003', 13]]
columns = ['Sdate', 'type']
df = pd.DataFrame(data, columns=columns)
df['Sdate'] = pd.Series(df['Sdate'], dtype="datetime64[ns]")
df['Sdate'] = pd.to_datetime(df['Sdate'], format="%Y-%m-%d")
5.将某一列日期(字符串/object类型)格式进行调整
例如将 Sdate列的’20201001’格式转换成’2020-10-01’格式:
data = [['20201001', 10], ['20201002', 12], ['20201003', 13]]
columns = ['Sdate', 'type']
df = pd.DataFrame(data, columns=columns)
print(df)
df['Sdate'] = pd.to_datetime(df['Sdate']).dt.strftime('%Y-%m-%d')
print(df)
输出:
Sdate type
0 20201001 10
1 20201002 12
2 20201003 13
Sdate type
0 2020-10-01 10
1 2020-10-02 12
2 2020-10-03 13
6.更改某一列的列名,以及设置index名称,并将index设置为一列
df = pd.DataFrame({"numlegs": [4, 4, 2],
"numarms": [0, 0, 2]},
["dog", "cat", "monkey"])
print("原始df:\n", df)
df = df.rename(columns={'numlegs': 'num_legs', 'numarms': 'num_arms'})
print("修改完列名的df:\n", df)
df = df.rename_axis('animal').reset_index()
print("将索引变成一列的df:\n", df)
输出:
原始df:
numlegs numarms
dog 4 0
cat 4 0
monkey 2 2
修改完列名的df:
num_legs num_arms
dog 4 0
cat 4 0
monkey 2 2
将索引变成一列的df:
animal num_legs num_arms
0 dog 4 0
1 cat 4 0
2 monkey 2 2
五、删除
1. 删除行
df = df.drop(df[(df['Age'] > 10) & (df['Age'] < 13)].index)
print(df)
输出:
Name Age
0 Jack 10
2 Lucy 13
2. 删除列
df = df.drop('Age', axis=1)
print(df)
输出:
Name
0 Jack
1 Tom
2 Lucy
注意:
DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False)
- labels:要删除的行或列,用列表给出
- axis:默认为0,指要删除的是行,删除列时需指定axis为1
- index :直接指定要删除的行,删除多行可以使用列表作为参数
- columns:直接指定要删除的列,删除多列可以使用列表作为参数
- inplace: 默认为False,该删除操作不改变原数据;inplace = True时,改变原数据
六、聚合(合并)
1、group by操作
df = pd.DataFrame({'key1': list('ababa'),
'key2': ['one', 'two', 'one', 'two', 'one'],
'data1': np.random.randn(5),
'data2': np.random.randn(5)})
print(df)
group = df.groupby('key1')[['data1', 'data2']].min()
print(group)
输出:
key1 key2 data1 data2
0 a one -3.393454 1.847552
1 b two -1.647726 0.220853
2 a one 1.181992 0.642054
3 b two 1.678282 0.166917
4 a one 0.232609 0.562615
data1 data2
key1
a -3.393454 0.562615
b -1.647726 0.166917
2、join操作
df1 = pd.read_csv('energy.csv', encoding='gb2312')
df2 = pd.read_csv('energy.csv', encoding='gb2312')
result = pd.merge(df1, df2, how='left', on=['日期'])
print(result)
输出:
日期 能量值_x 电量值_x 能量值_y 电量值_y
0 2020-06-06 2900 NaN 2900 NaN
1 2020-06-07 3300 0.0 3300 0.0
2 2020-06-08 666 666.0 666 666.0
七、遍历
for index, row in df.iterrows():
print(index)
print(row['Name'])
print(row['Age'])
输出:
0 Jack 10
1 Tom 12
2 Lucy 13
注意: 这里的iterrows()返回值为元组,(index,row),index即为行索引,row就是一行的所有数据,可通过字段名获取到
八、转换
1、字典和dataFrame的相互转换
参考文章:https://blog.csdn.net/m0_43609475/article/details/125328938
2、数据类型转换
df = pd.read_csv('energy.csv', encoding='gb2312')
print(df.dtypes)
df['能量值'] = df['能量值'].astype(object)
print("=====================================")
print(df.dtypes)
输出:
日期 object
能量值 int64
电量值 float64
dtype: object
=====================================
日期 object
能量值 object
电量值 float64
dtype: object
3、把Nan值转换成None值
原因:pandas中的空值是NaN表示的,如果插入数据库中,必须将NaN转换成None值,否则会报错
df = pd.read_csv('energy.csv', encoding='gb2312')
print(df)
print("=====================================")
df = df.astype(object).where(pd.notnull(df), None)
print(df)
输出:
日期 能量值 电量值
0 2020-06-06 2900 NaN
1 2020-06-07 3300 0.0
2 2020-06-08 666 666.0
=====================================
日期 能量值 电量值
0 2020-06-06 2900 None
1 2020-06-07 3300 0.0
2 2020-06-08 666 666.0
九、其他
1、去除有Nan值的行
df = pd.read_csv('energy.csv', encoding='gb2312')
print(df)
print("==========================================")
result = df.drop(df[df.isnull().T.any()].index)
print(result)
输出:
日期 能量值 电量值
0 2020-06-06 2900 NaN
1 2020-06-07 3300 0.0
2 2020-06-08 666 666.0
==========================================
日期 能量值 电量值
1 2020-06-07 3300 0.0
2 2020-06-08 666 666.0
解释:
df = pd.read_csv('energy.csv', encoding='gb2312')
print(df)
print("==========================================")
print("df.isnull():")
print(df.isnull())
print("==========================================")
print("df.isnull().T:")
print(df.isnull().T)
print("==========================================")
print("df.isnull().T.any():")
print(df.isnull().T.any())
print("==========================================")
print("df[df.isnull().T.any()]:")
print(df[df.isnull().T.any()])
print("==========================================")
print("df[df.isnull().T.any()].index:")
print(df[df.isnull().T.any()].index)
输出:
日期 能量值 电量值
0 2020-06-06 2900 NaN
1 2020-06-07 3300 0.0
2 2020-06-08 666 666.0
==========================================
df.isnull():
日期 能量值 电量值
0 False False True
1 False False False
2 False False False
==========================================
df.isnull().T:
0 1 2
日期 False False False
能量值 False False False
电量值 True False False
==========================================
df.isnull().T.any():
0 True
1 False
2 False
dtype: bool
==========================================
df[df.isnull().T.any()]:
日期 能量值 电量值
0 2020-06-06 2900 NaN
==========================================
df[df.isnull().T.any()].index:
Int64Index([0], dtype='int64')
2、pandas生成时间列表
from_date = '20230513'
to_date = '20230515'
date_list = pd.date_range(from_date, to_date).strftime("%Y-%m-%d").tolist()
print(date_list)
上述时间也可以是datetime类格式:
from_date = datetime.strptime('20230513', "%Y%m%d")
to_date = datetime.strptime('20230515', "%Y%m%d")
date_list = pd.date_range(from_date, to_date).strftime("%Y-%m-%d").tolist()
print(date_list)
输出:
['2023-05-13', '2023-05-14', '2023-05-15']
Original: https://blog.csdn.net/bradyM/article/details/125485280
Author: 今天上上签
Title: pandas库–DataFrame常用操作
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/750877/
转载文章受原作者版权保护。转载请注明原作者出处!