

Python
文章目录
- Python
* - init、new__和__call
- 型態
– - input
- 集合Set 基本語法
– - 字典Dictionary 基本語法
- 判斷式
– - 流程控制:迴圈基礎
– - 函式
– - Data Structure – 資料結構
- 安裝第三方套件
– - Module 模組
– - 封包的設計與使用
– - 讀取、儲存文字檔案
– - Class的定義與使用
– - 實體物件的建立與使用
– - 網路連線程式、公開資料串接
– - 網路爬蟲 Web Crawler
–- 抓取的網頁,取得網址
- 安裝BeautifulSoup
- 實務操作:抓取 [PTT 電影版](https://www.ptt.cc/bbs/movie/index.html)的文章標題
+ - 看起來像人類
- 解析原始碼
- Cookie 操作實務
+ - 追蹤網頁連結
- 連續抓取頁面實務
+ - ptt八卦板
- 觀察網路連線
- 不斷抓別的頁面
- PTT 八卦板 連續抓3頁標題
- AJAX / XHR 網站技術分析實務
+ - Medium 文章列表 (舊版)
- 抓取知名網站medium.com的首頁文章列表
- Request Data 操作實務
+ - 抓取 Medium.COM 網站的文章列表資料 2021 版
- 抓取 Medium.COM 網站實務操作
- Flask 網站架設
–
:::info PPT
:::warning
VScode python
Shift + Alt + F自動排版
ctrl+C強制結束
ctrl+/全部註解
:::
init 、 new__和__call
https://codertw.com/%E7%A8%8B%E5%BC%8F%E8%AA%9E%E8%A8%80/364923/
https://ithelp.ithome.com.tw/m/articles/10231756
型態
- int (整數)
- float (浮點數)
- bool (布林值)
- str (字串)
- List(列表) : [ ]
- Tuple(元组) : ( ) 不能更動裡面的內容
- Dictionary(字典) : { }
- None(空)
len(資料)
回傳(字數、list等)長度或項目個數。
Tuple
元組基本語法
變數 = (東西1, 東西2, ...)
元組中只包含 一個元素時
需要在元素後面加逗號(,)
tup = (50,)
特殊字串
如果字串裡面有包含特殊字元
要使用脫逸字元 反斜線
\
成員運算子
運算子意義 in
在指定的序列中找到值返回 True
,否則返回 False not in
指定的序列中沒有找到值返回 True
,否則返回 False
s=[1,2,3]
print(3 in s)
input
取得字串形式的使用者輸入
x=input("請輸入數字:")
x=int(x)
集合Set 基本語法
自動把字串拆解成集合
set("字串")
s=set("Hello")
print(s)
print("H" in s)
Set 運算子
運算子意義 &
交集: 取兩個集合中,相同的資料 |
聯集: 取兩個集合中的所有資料,但不重複取 -
差集: 從S1中,減去和S2重疊的部分 ^
反交集: 取兩個集合中,不重疊的部分
字典Dictionary 基本語法
key-value 配對
變數 = {key1:value1, key2:value2, ...}
key是唯一的,如果重複,最後一個key的value會代替前面的
value可以重複沒關係
只能用key去拿value
所以要修改value時,只能用key去找也可以用
in去搜尋key值
刪除字典中的key-value pair
del dic["key"]
從列表的資料產生字典
dic={x:x*2 for x in 列表}
範例
dic={"apple":"蘋果","bug":"蟲蟲"}
print(dic["apple"])
del dic["apple"]
dic={x:x*2 for x in [3,4,5]}
print(dic)
判斷式
if (條件式一):
條件式一成立,要做的事
elif (條件式二):
條件式二成立,要做的事
else:
上述條件式都不成立,要做的事
要記得加
:
四則運算
n1=int(input("請樹入數字1:"))
n2=int(input("請樹入數字2:"))
op=input("請樹入運算: +, -, *, /")
if op=="+":
print(n1+n2)
elif op=="-":
print(n1-n2)
elif op=="*":
print(n1*n2)
elif op=="/":
print(n1/n2)
else:
print("不支援")
流程控制:迴圈基礎
range()
for 變數名稱 in range(3):
||
for 變數名稱 in [0,1,2]:
for 變數名稱 in range(3, 6):
||
for 變數名稱 in [3,4,5]:
while 迴圈
while迴圈基本語法
while (條件):
條件成立要做的事
for 迴圈
for迴圈基本語法
for 變數 in 列表或字串:
要做的事
for c in "Hello":
print("逐一取得字串中的字元",c)
"""
H
e
l
l
o
"""
要記得加
:
break
強制結束迴圈
n=1
while n<5:
if n==3:
break
n+=1
print(n)
continue
強制執行下一圈
忽略接下來的程式,跳進下一圈迴圈
範例
n=0
for x in range(4):
if x%2==0:
continue
print(x)
n+=1
print("最後的 n:",n)
else
迴圈結束前執行此區塊的命令
while 布林值:
...
else:
迴圈結束前執行此區塊的命令
for 變數 in 列表或字串:
要做的事
else:
迴圈結束前執行此區塊的命令
要記得加
:
:::info
用break強制結束迴圈時,不會執行else區塊
:::
綜合範例
找出整數平方根
輸入9. 得到 3.
輸入11 得到”沒有”整數平方根
n=int(input("請輸入數字"))
for i in range(n):
if i*i == n:
print("找到整數平方根",i)
break
else:
print("沒有 整數平方根")
函式
1. 定義函式
def 函式名稱(參數名稱):
內部程式碼
return 資料
要記得加
:
2. 定義參數的預設值
def 函式名稱(參數名稱=預設資料):
內部程式碼
return 資料
:::info
example
def power(base ,exp=0):
print(base**exp)
power(3,2)
power(4)
:::
- 回傳與回傳值
2.1 使用 return 結束函式
2.2 使用 return 定義回傳值
2.3 呼叫函式後,如何串接回傳值
def add(n1, n2):
result = n1+n2
return result
value=add(3,4)
print(value)
使用參數名稱對應
呼叫函式,以參數名稱對應資料
python=
def 函式名稱(名稱1,名稱2):
內部程式</p>
<p>呼叫函式,以參數名稱對應資料
函式名稱(名稱2=3,名稱1=5)</p>
<pre><code>
def divide(n1,n2):
result=n1/n2
print(result)
divide(2,4)
divide(n2=2,n1=4)
無限/不定 參數資料
在參數名稱前面加*
def 函式名稱(*無限參數):
無限參數以Tuple資料形態處理
函式內部的程式碼
函式名稱(資料1,資料2,資料3)
def say(*msgs):
for msg in msgs:
print(msg)
say("Hello","Arbitrary","Arguments")
def avg(*nums):
sum=0
for n in nums:
sum=sum+n
return sum/len(nums)
:::info
更多
- 函式的目的:包裝需要重複利用的程式碼。
- 參數的目的:替函式加入更多彈性。
- 回傳值的目的:將函式內部的資料傳遞出來。
:::
範例 SUM
def calculate(n):
sum=0
for i in range(1,n+1):
sum=sum+i
return sum
print(calculate(10))
要記得加
:
torch.nn.funtional.softmax()
torch.nn.functional.Softmax(input,dim=1)
要注意的是当dim=0时, 是对每一维度相同位置的数值进行softmax运算,举个栗子:
每一个维度(2,3)对应的数值相加为1,例如:
在第0维度中:
- [0][0][0]+[1][0][0]=0.0159+0.9841=1
- [0][0][1]+[1][0][1]=0.6464+0.3536=1
在第1维度中:
- [0][0][0]+[0][1][0]=0.1058+0.8942=1
在第2维度中:
- [1][0][0]+[1][1][0]=0.3189+0.6811=1
map(function, iterable, …)
https://www.runoob.com/python/python-func-map.html
input = [1, 2, 3, 4, 5]
output = list(map(lambda x: x+1, input))
print(output)
>>> [2, 3, 4, 5, 6]
参数
- function – 函数
- iterable – 一个或多个序列
返回值
- Python 2.x 返回列表。
- Python 3.x 返回迭代器(iterator)。
Data Structure – 資料結構
https://algorithm.yuanbin.me/zh-tw/basics_data_structure/linked_list.html#python
安裝第三方套件
PIP 套件管理工具
安裝python時,就一起安裝在你的電腦裡了
python 加入環境變數path中 才能使用pip指令 > https://hackmd.io/@yizhewang/B1zdXG4br
安裝BeautifulSoup
pip install beautifulsoup4
解讀 HTML 格式 > 使用第三方套件 BeautifulSoup 來做解析
Module 模組
載入
import 模組名稱
import 模組名稱 as 模組別名
使用
模組名稱/別名.函式名稱(參數資料)
模組名稱/別名.變數名稱
內建模組 – sys 模組
取得系統相關資訊
import sys
sys.platform
sys.maxsize
sys.path
||
import s
s.platform
s.maxsize
s.path
自訂模組的設計
建立幾何運算模組
- 建立新的geo.py檔案
def distance(x1,y1,x2,y2):
return ((x2-x1)**2+(y2-y1)**2)**0.5
def slope(x1,y1,x2,y2):
return (y2-y1)/(x2-x1)
載入
- 在主程式.py中,輸入import (同個路徑)
import geo
result=geo.distance(1,1,5,5)
print(result)
調整搜尋模組的路徑
在模組的搜尋路徑列表中【新增路徑】
sys.path.append("名稱")
在專案資料夾中建立一個module資料夾,專門放模組用,但是路徑會跑掉
import sys
print(sys.path)
sys.path.append("modules")
import geo
封包的設計與使用
包含模組的資料夾
用來整理分類模組程式
檔案系統中的檔案對應到模組
檔案系統中的資料夾對應到python的封包
建立封包
專案檔案配置
- 專案資料夾
- 主程式.py
- 封包資料夾
- init .py (有這個才會被當作封包)
- 模組一.py
- 模組二.py
如果沒有__init __.py,該資料夾會被視為普通的資料夾
專案檔案配置範例
- 專案資料夾
- main.py
- geometry
- init .py
- point.py
- line.py
使用封包
import某個封包中的模組
import 封包名稱.模組名稱
import 封包名稱.模組名稱 as 模組別名
封包名稱.模組名稱.函式
範例
- 先建立一個新的資料夾 geometry
- 在資料夾中建立一個檔案__init__.py (geometry變成”封包”了)
- 在封包中建立新的模組 line.py , point.py
def distance(x,y):
return (x**2+y**2)**0.5
def len(x1,y1,x2,y2):
return (((x2-x1)**2)+((y2-y1)**2))**0.5
def slope(x1,y1,x2,y2):
return (y2-y1)/(x2-x1)
import geometry.point
import geometry.line
result=geometry.point.distance(3,4)
print(result)
result=geometry.line.slope(1,1,3,3)
print("slope:",result)
import geometry.point as point
result=point.distance(3,4)
print(result)
讀取、儲存文字檔案
開啟檔案 > 讀取或寫入 > 關閉檔案
開啟檔案
檔案物件=open(檔案路徑,mode=開啟模式,encoding=文字編碼)
開啟模式意思 r
讀取模式 w
寫入模式 r+
讀寫模式 utf-8
中文/日文編碼
最佳實務:使用 with … as … 語法
:::info
最佳實務
用檔案物件去操作檔案,會自動關閉檔案且安全
with open(檔案路徑, mode=開啟模式) as 檔案物件:
讀取或寫入檔案的程式
:::
要記得加
:
讀取檔案
- 讀取全部文字
檔案物件.read()
- 一次讀取一行
for 變數 in 檔案物件:
從檔案依序讀取每行文字到變數中
- 讀取 JSON 格式
import json
讀取到的資料=json.load(檔案物件)
寫入檔案
- 寫入文字
檔案物件.write(字串)
- 寫入換行符號
檔案物件.write("這是範例文字\n")
- 寫入 JSON 格式
import json
json.dump(要寫入的資料, 檔案物件)
關閉檔案
檔案物件.close()
範例
file=open("data.txt" , mode="w",encoding="utf-8")
file.write("Hello file\nSecond 好棒棒")
file.close()
with open("data.txt", mode="w",encoding="utf-8") as file:
file.write("5\n3")
with open("data.txt", mode="r",encoding="utf-8") as file:
data=file.read()
print(data)
sum=0
with open("data.txt", mode="r",encoding="utf-8") as file:
for line in file:
sum+=int(line)
print(sum)
使用JSON格式讀取,複寫檔案
先建立一個檔案 config.json在路徑中
先建立一個檔案 config.json在路徑中
{
"name":"My Name",
"version":"1.2.5"
}
import json
with open("config.json",mode="r") as file:
data=json.load(file)
print(data)
print("name: " , data["name"])
print("version: " , data["version"])
data["name"]="New Name"
with open("config.json",mode="w") as file:
json.dump(data, file)
:::info
json讀取資料會是一個字典
讀取dict 要使用 [ ]
:::
Class的定義與使用
封裝變數或函式: 封裝的變數或函式,統稱 類別的屬性
class定義
class 類別名稱:
定義封裝的變數
定義封裝的函式
要記得加
:
class Test:
x=3
def say():
print("Hello")
class使用
python=
類別名稱.屬性名稱</p>
<pre><code>
class Test:
x=3
def say():
print("Hello")
Test.x+3
Test.say()
範例
- 定義類別 與 類別屬性 (封裝在類別中的變數和函式)
- 定義一個類別 IO,有兩個屬性 supportedSrcs 和 read
class IO:
supportedSrcs=["console","file"]
def read(src):
if src not in IO.supportedSrcs:
print("Not Supported")
else:
print("Read from", src)
print(IO.supportedSrcs)
IO.read("file")
IO.read("internet")
實體物件的建立與使用
類別的兩種用法
- 類別與類別屬性
- 類別與 實體物件、實體屬性、實體方法
本篇教學為2.部分
建立實體物件
建立 > 使用
要先建立實體物件,然後才能使用實體屬性
class 類別名稱:
def __init__(self,其他變數):
透過操作 self 來定義實體屬性
self.變數=其他變數
obj=類別名稱()
class Point:
def __init__(self):
self.x=3
self.y=4
p=Point()
class Point:
def __init__(self, x, y):
self.x=x
self.y=y
p=Point(1, 5)
使用實體
python=
實體物件.實體屬性名稱</p>
<pre><code>
class Point:
def __init__(self, x, y):
self.x=x
self.y=y
p=Point(1, 5)
print(p.x+p.y)
範例
class Point:
def __init__(self,x=0,y=0):
self.x=x
self.y=y
p1=Point(3,4)
print(p1.x, p1.y)
p2=Point(5,6)
print(p2.x, p2.y)
p3=Point()
print(p3.x, p3.y)
class FullName:
def __init__(self,first,last):
self.first=first
self.last=last
name1=FullName("C.W.","Peng")
print(name1.first, name1.last)
name2=FullName("S.W.","Seng")
print(name2.first, name2.last)
實體方法
封裝在實體物件中的函式
class 類別名稱:
def __init__(self):
定義實體屬性
定義實體方法 / 函式
obj=類別名稱()
class 類別名稱:
def __init__(self):
封裝在實體物件中的變數
def 方法名稱(self, 更多自訂參數):
方法主體,透過 self 操作實體物件
obj=類別名稱()
使用實體方法
實體物件.實體方法名稱(參數資料)
class Point:
def __init__(self, x, y):
self.x=x
self.y=y
def show(self):
print(self.x, self.y)
p=Point(1, 5)
p.show()
範例
class Point:
def __init__(self,x=0,y=0):
self.x=x
self.y=y
def show(self):
print(self.x, self.y)
def distance(self,targetX,targetY):
return ((self.x-targetX)**2+(self.y-targetY)**2)**0.5
p=Point(3,4)
p.show()
result=p.distance(0,0)
print(result)
先準備2個檔案:
data1.txt: 哈哈哈哈哈哈
data2.txt: FUXK YOU
class File:
def __init__(self, name):
self.name=name
self.file=None
def open(self):
self.file=open(self.name, mode="r",encoding="utf-8")
def read(self):
return self.file.read()
f1=File("data1.txt")
f1.open()
data=f1.read()
print(data)
f2=File("data2.txt")
f2.open()
data=f2.read()
print(data)
:::info
尚未開啟檔案: 初期是 None
要記得寫 self
:::
網路連線程式、公開資料串接
抓取台北市政府的資料
確認公開資料格式
JSON、CSV、或其他格式
解讀 JSON 格式 > 使用內建的 json 模組
解讀 HTML 格式 > 使用第三方套件 BeautifulSoup 來做解析
適合的資料來源: 台北市政府公開資料
載入urllib模組、下載特定網址資料
import urllib.request
檔案名稱請不要取得跟模組一樣
系统搜索模块的优先顺序是:程序主目录,然后是系统环境变量定义的路径,然后才是标准库目录。 如果按这个顺序找到了,当然就不再向下找了。因为文件名正好是urllib,本意想导入标准库目录下的urllib,结果把自己的当前文件导入了
import urllib.request as request
with request.urlopen(網址) as response:
data=response.read()
print(data)
網路連線
import urllib.request as request
src="https://www.ntu.edu.tw/"
with request.urlopen(src) as response:
data=response.read().decode("utf-8")
print(data)
:::info
網站有中文要用.decode(“utf-8”)解讀
:::
串接,擷取公開資料
用API去連線
臺北市內湖科技園區廠商名錄
會提供連線API網址範例
https://data.taipei/api/v1/dataset/296acfa2-5d93-4706-ad58-e83cc951863c?scope=resourceAquire
用網頁打開API網址會看到一堆資料
仔細看資料是一個JSON格式
results是用陣列去存 in JSON
python中是list裡面 dict.字典方式去存資料
import urllib.request as request
import json
src="https://data.taipei/api/v1/dataset/296acfa2-5d93-4706-ad58-e83cc951863c?scope=resourceAquire"
with request.urlopen(src) as response:
data=json.load(response)
clist=data["result"]["results"]
print(clist)
with open("data.txt","w",encoding="utf-8") as file
for company in clist:
print(company["公司名稱"])
:::info
json.load(response)
用 json模組處理 json資料格式,會自己處理json格式資料細節,不用自己處理資料
:::
網路爬蟲 Web Crawler
- 抓取特定網址的資料
- 解析 HTML 格式資料
盡可能讓程式模仿使用者樣子
抓取的網頁,取得網址
解讀 HTML 格式 > 使用第三方套件 BeautifulSoup 來做解析
HTML格式資料
<html> // 用小括號框起來的叫【標籤】
<head>
title>HTML格式title> //有title代表【網頁的標題】
head>
//head 和 body是相鄰的標籤
<body>
<div class="list"> //div標籤 有個屬性叫做class
<span>階層結構span>
<span>樹狀結構span>
div>
body>
html> // 有斜線代表【結束】
安裝BeautifulSoup
在terminal中
pip install beautifulsoup4
python 加入path> https://hackmd.io/@yizhewang/B1zdXG4br
:::info
CMD
去CMD 移動到python磁碟機
C:\Users\Tracy HO>F:
//確認Python是否有讀取到
F:>python –version
Python 3.8.9
//安裝pip版本最新
F:>py -m pip install -U pip
Requirement already satisfied: pip in f:\python_3.8.9\lib\site-packages (21.0.1)
//確認pip版本
F:>py -m pip –version
pip 21.0.1 from F:\Python_3.8.9\lib\site-packages\pip (python 3.8)
//安裝第三方套件
F:>pip install beautifulsoup4
Collecting beautifulsoup4
Downloading beautifulsoup4-4.9.3-py3-none-any.whl (115 kB)
|██████████████ | 51 kB 544 kB/s eta 0:00:01
|█████████████████ | 61 kB 653 kB/s eta 0:00
|████████████████████ | 71 kB 657 kB/s eta 0
|██████████████████████▌ | 81 kB 655 kB/s et
|█████████████████████████▌ | 92 kB 737 kB/s
|████████████████████████████ | 102 kB 819 k
|███████████████████████████████ | 112 kB 81
|████████████████████████████████| 115 kB 8
19 kB/s
Collecting soupsieve>1.2
Downloading soupsieve-2.2.1-py3-none-any.whl (33 kB)
Installing collected packages: soupsieve, beautifulsoup4
Successfully installed beautifulsoup4-4.9.3 soupsieve-2.2.1
完成
:::
看起來像人類
- 觀察網址
- 右鍵 【檢視網頁原始碼】 會抓到這些原始碼
- chrome中 【選單】>【更多工具】>【開發人員工具】 或 直接按【F12】
- 上方有個標籤選單【Network】>【All】> 再按【F5】
為了要把網頁顯示出來 會做了非常多的網路連線
- 看到最上面有個【index.html】>右邊視窗的左邊【Headers】>【Request Headers】> 最重要的是【user-agent】
用瀏覽器發送網路連線到PTT的伺服器會附加很多資訊,附加【Request Headers】資訊會代表我們是正常的使用者
【user-agent】代表我們是使用怎樣的OS/瀏覽器
必須讓我們的程式也發送這些訊息,PTT就會認為我們是正常人
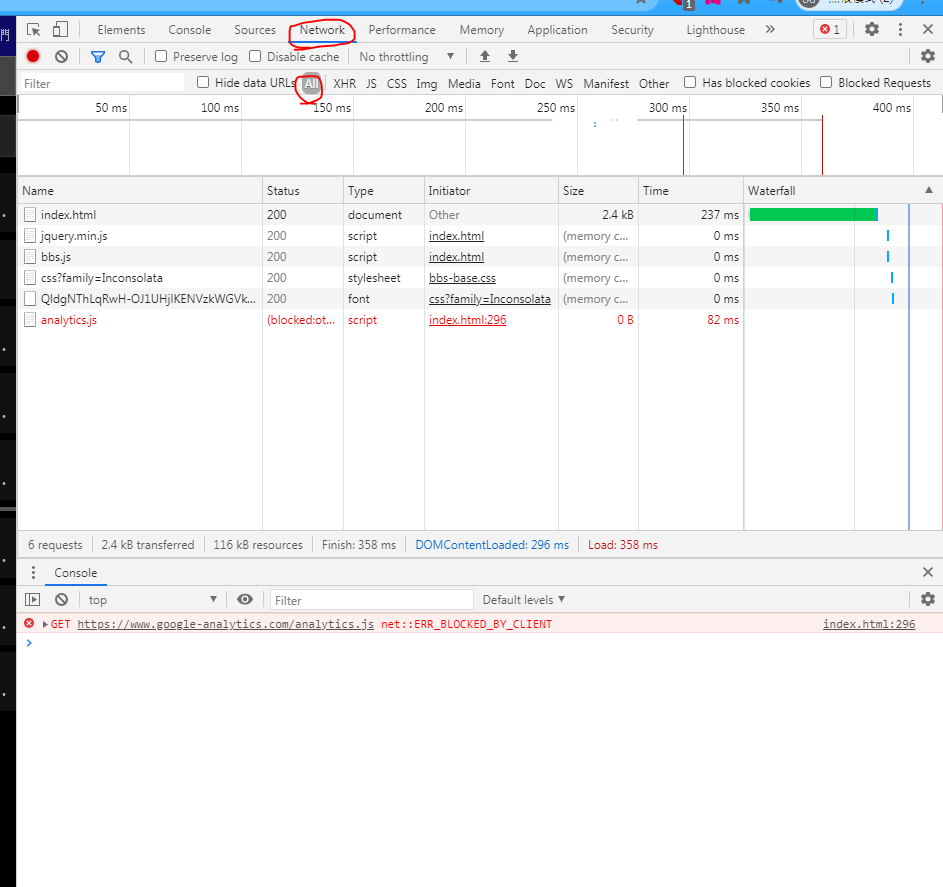

; 解析原始碼
使用BeautifulSoup
隨便複製一個標題,ctrl+f 搜尋原始碼中標題的位子在哪一層結構
:::info
發現每個文章標題都會被 <div class="title">包住</div>
:::
import urllib.request as req
url="https://www.ptt.cc/bbs/movie/index.html"
request=req.Request(url, headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36"
})
with req.urlopen(request) as response:
data=response.read().decode("utf-8")
print(data)
import bs4
root=bs4.BeautifulSoup(data, "html.parser")
print(root.title)
print(root.title.string)
titles=root.find("div",class_="title")
print(titles)
print(titles.a.string)
titles=root.find_all("div",class_="title")
print(titles)
for title in titles:
if title.a != None:
print(title.a.string)
Cookie 操作實務
網站存放在瀏覽器的一小段內容
與伺服器的互動
如果使用者的瀏覽器中有放cookies,在連線的時候cookies會放在request headers中被帶出去
追蹤網頁連結
HTML格式資料
<html> // 用小括號框起來的叫【標籤】
<head>
title>HTML格式title> //有title代表【網頁的標題】
head>
//head 和 body是相鄰的標籤
<body>
<a href="https://www.google.com/">Googlea> //html原始碼中經常會包含<a>超連結
// 追蹤網頁的連結href的屬性去抓下一個網頁
body>
html> // 有斜線代表【結束】
連續抓取頁面實務
解析頁面的超連結並結合程式完成
抓ptt第二頁並追蹤他的上一頁連結
ptt八卦板
因為ptt 八卦版多了一個畫面 年齡限制
:::info
複製上面的程式
import urllib.request as req
url="https://www.ptt.cc/bbs/movie/index.html"
request=req.Request(url, headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36"
})
with req.urlopen(request) as response:
data=response.read().decode("utf-8")
print(data)
import bs4
root=bs4.BeautifulSoup(data, "html.parser")
print(root.title)
print(root.title.string)
titles=root.find("div",class_="title")
print(titles)
print(titles.a.string)
titles=root.find_all("div",class_="title")
print(titles)
for title in titles:
if title.a != None:
print(title.a.string)
:::
:::info
如果純粹改網址就跑上面的code會無法抓到東西
這件事情跟cookie有關
因為八卦板有18歲的警告畫面
我們沒有給他over18的訊息 所以沒有給我們回應
:::
【F12 or 開發人員工具】 > 【Application】 > 【Cookies】 > https://www.ptt.cc
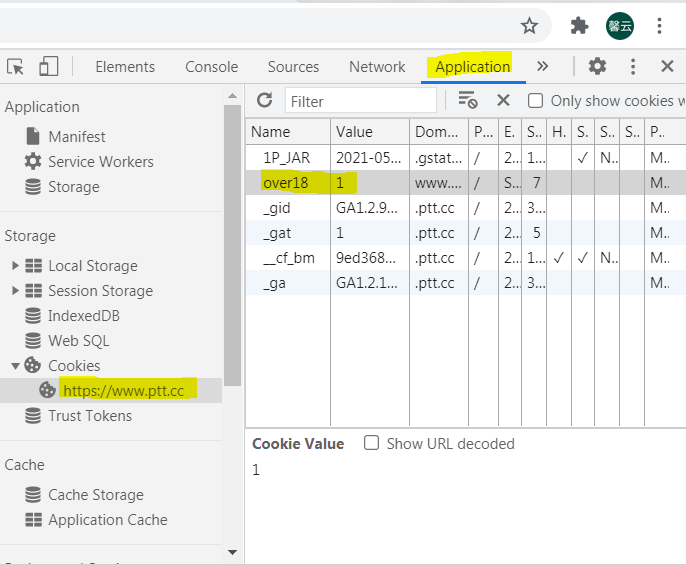
列表中 就是ptt放在我的瀏覽器的cookies (放了5個小資料)
over18 的餅乾就是紀錄有沒有超過18歲 就不會跳出那個確認畫面
NameValueDomain名字資料誰放的over181www.ptt.cc
:::info
可以手動把cookie清掉
:::
觀察網路連線
模仿他 帶上over18的cookie
【F12 開發者工具】 > 【Network】 > 【index.html】 > 【Headers】 > 【cookie】 > 【 over18=1】
over18用分號隔開了
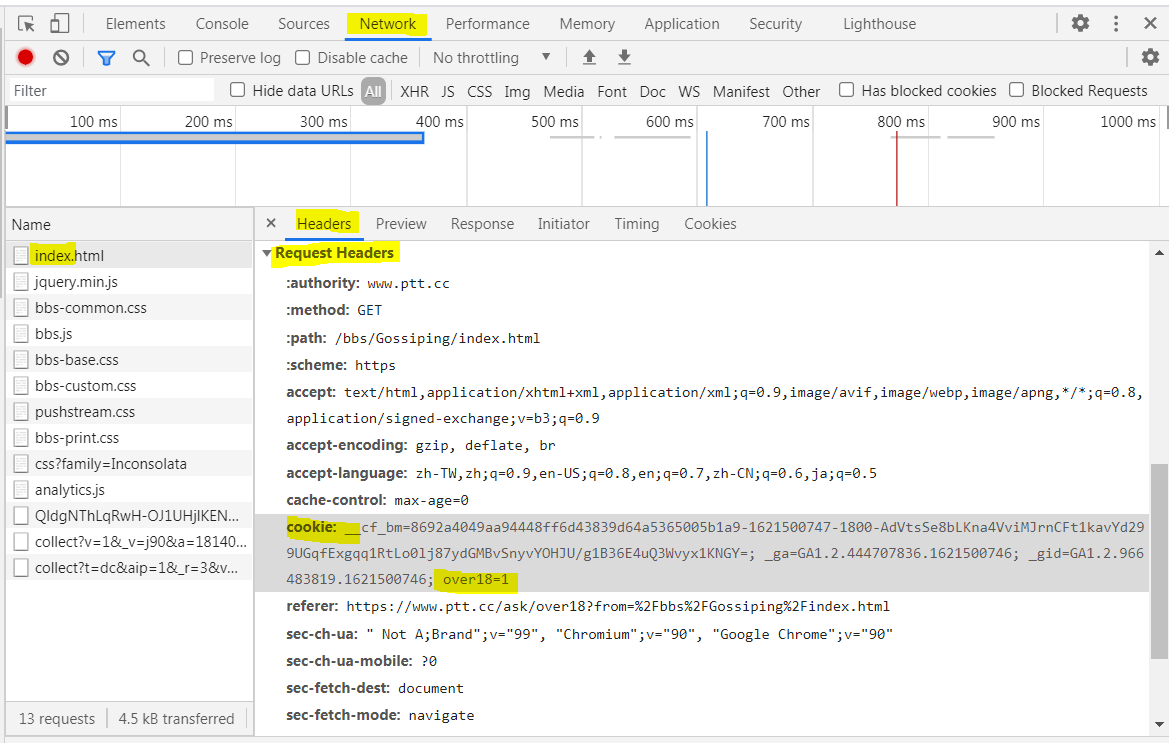
把cookie放在headers中
request=req.Request(url, headers={
=="cookie":"over18=1",==
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36"
})
不斷抓別的頁面
觀察八卦版的頁面
上頁 是一個超連結,也就是一個
所以概念很簡單,抓到第一個頁面後動態的去抓上一頁抓取連結
- 對【上一頁】右鍵 > 【檢查】
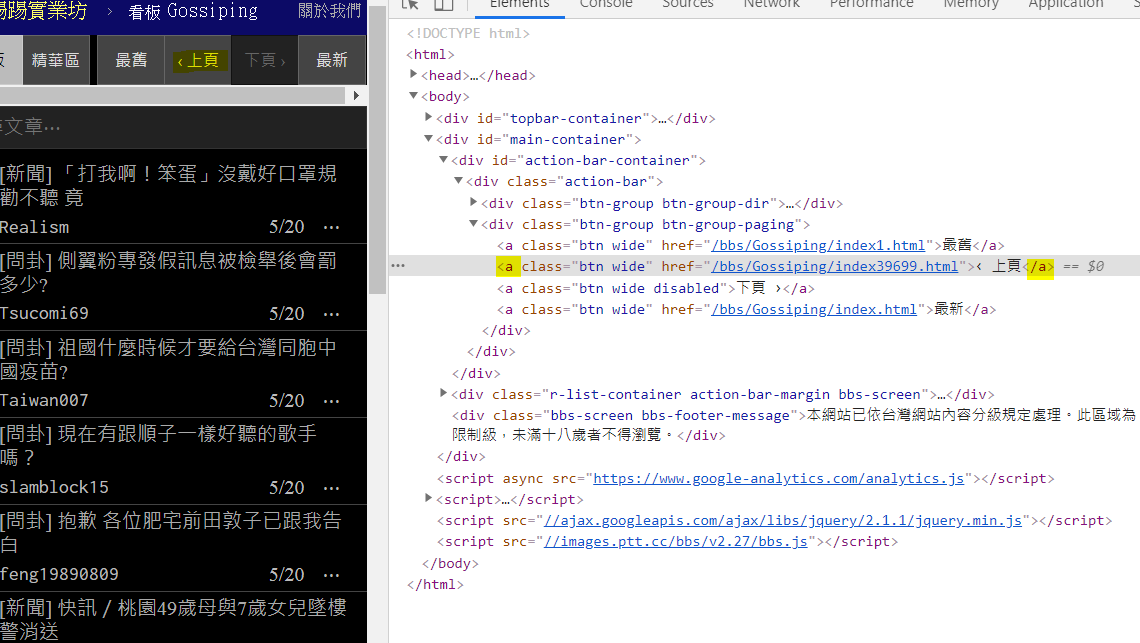
- 觀察這個程式沒什麼特別之處
利用篩選 ‹ 上頁 去抓取超連結的網址 (對文字按兩下就可以複製起來) - 再去code寫
nextLink=root.find("a",string="‹ 上頁")# 找到內文是 “‹ 上頁”的a標籤 - 定義一個函式
def getData(url):,且把url=...刪除 - 將底下程式進行縮排 成為一個function內容
- main程式 先設定原網址 呼叫getData(原網址)
包裝完畢確認能跑出一樣的結果
:::info
code
import urllib.request as req
def getData(url):
request=req.Request(url, headers={
"cookie":"over18=1",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36"
})
with req.urlopen(request) as response:
data=response.read().decode("utf-8")
import bs4
root=bs4.BeautifulSoup(data, "html.parser")
titles=root.find_all("div",class_="title")
for title in titles:
if title.a != None:
print(title.a.string)
nextLink=root.find("a",string="‹ 上頁")
return nextLink["href"]
pageURL="https://www.ptt.cc/bbs/Gossiping/index.html"
pageURL=getData(pageURL)
print(pageURL)
:::
7. 將pageURL 前面加 "https://www.ptt.cc" +getData(pageURL)
8. 增加 迴圈 算要抓幾個頁面
count=0
while count<3 :
pageURL="https://www.ptt.cc"+getData(pageURL)
count+=1
PTT 八卦板 連續抓3頁標題
import urllib.request as req
def getData(url):
request=req.Request(url, headers={
"cookie":"over18=1",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36"
})
with req.urlopen(request) as response:
data=response.read().decode("utf-8")
import bs4
root=bs4.BeautifulSoup(data, "html.parser")
titles=root.find_all("div",class_="title")
for title in titles:
if title.a != None:
print(title.a.string)
nextLink=root.find("a",string="‹ 上頁")
return nextLink["href"]
pageURL="https://www.ptt.cc/bbs/Gossiping/index.html"
count=0
while count<3 :
pageURL="https://www.ptt.cc"+getData(pageURL)
count+=1
AJAX / XHR 網站技術分析實務
AJAX 網頁前端的JavaScript程式技術
網頁載入後持續和伺服器互動的技術

從第二次請求之後額外的動作在網頁的前端 都稱做address的技巧
:::info
傳統網頁運作流程

:::
; Medium 文章列表 (舊版)
抓取知名網站medium.com的首頁文章列表
- 分析網站運作模式
2.1 仔細觀察網站資料的載入時間點
html > F5 會瞬間跑出來
ajax > F5 會重新跑出一個殼 才慢慢把內容秀出來
2.2 檢查原始碼是否包含網站資料
html > 撿查網頁原始碼 html原始碼內有文章標題名稱
ajax > 原始碼沒有文章標題名稱
:::info
關鍵問題
認出網站運作模式,找出 真正能抓到資料的網址
(現在medium不給抓取了 可以參考下一部最新的爬蟲教學哦)
::: - 【F12 or 開發人員工具】>【XHR】>【F5】
就會紀錄所有採用ajax技術所發送的連線
列出一堆連線:代表著這些網站中有跑一些javascript程式 然後去跟網站伺服器作連線
在這些列表連線中有沒有包含文章標題資訊 也就是address技術
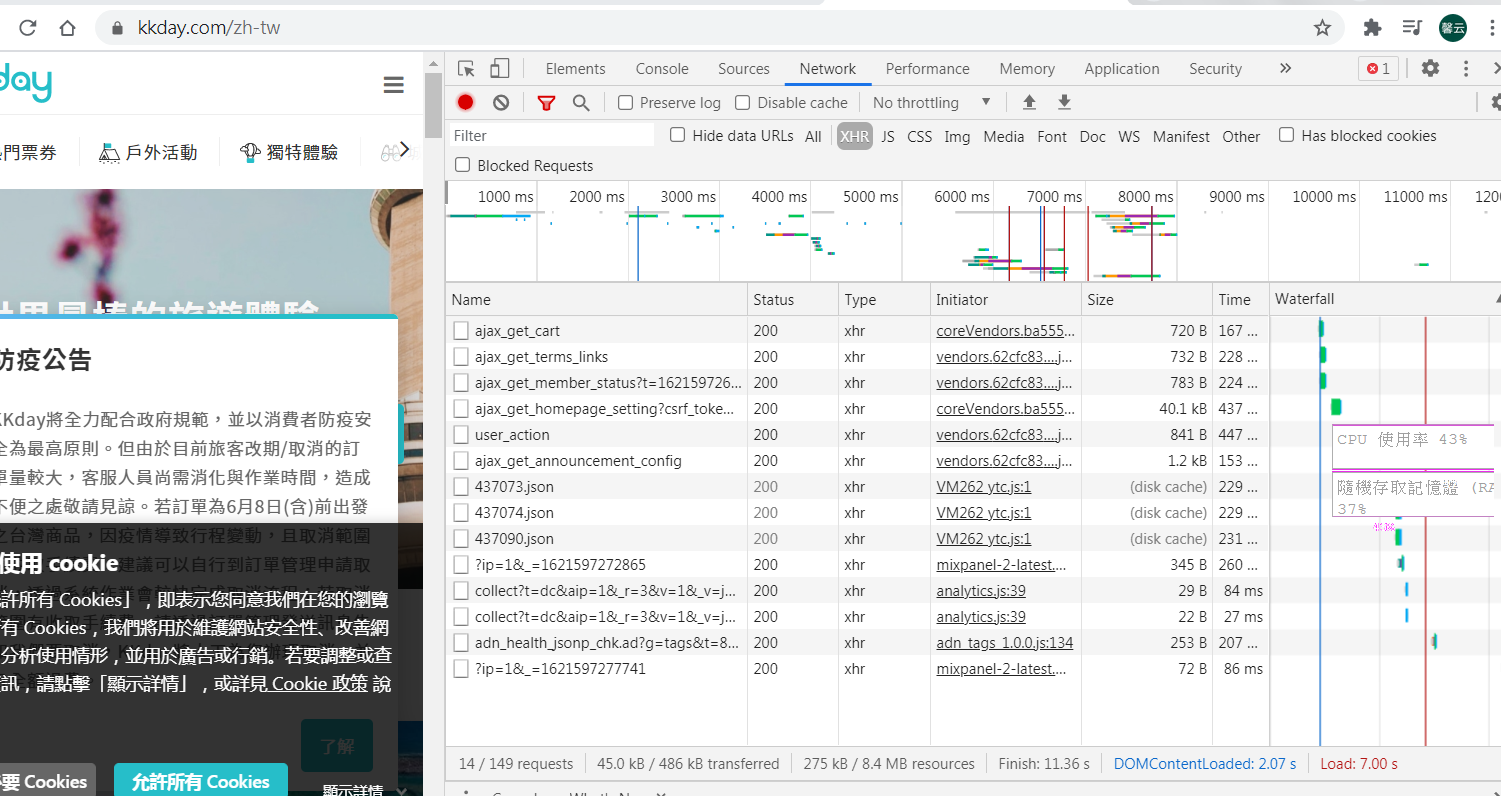
- 點擊每個【連線】> 會提供連線的資訊 > 【Preview】連線發出去得到的結果/【Response】原始的JSON格式 > Name很像會跟標題做連結的
- 【Preview】JSON格式 >【Payload】> 底下一個個點開看有沒有文章標題的資訊
- 網址
https://medium.com/_/api/home-feed - 在PTT電影版的程式中做一些修改
:::info
code
import urllib.request as req
url="https://medium.com/_/api/home-feed"
request=req.Request(url, headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36"
})
with req.urlopen(request) as response:
data=response.read().decode("utf-8")
import json
data=json.loads(data)
print(data)
:::
- 發現【Preview】code前面有多一個
])}while(1);很奇怪,影響到JSON格式的解析 - 對data使用replace進行奇怪文字的替換,在進行JSON解析
python=1
JSON格式需要用python內建的json模組
import json
data=data.replace("])}while(1);","") # 把多出來會影響解析JSON格式的莫名其妙的文字替換掉
data=json.loads(data) # 把原始 JSON的資料 解析成 字典/列表的表示形式
print(data)</p>
<h1>if解析失敗,要在去觀察發生什麼事</h1>
<pre><code>3. 【Preview】> 在JSON的格式中尋找文章的標題在哪裡
在 payload > references > Post 底下有一整串的文章
import urllib.request as req
url="https://medium.com/_/api/home-feed"
request=req.Request(url, headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36"
})
with req.urlopen(request) as response:
data=response.read().decode("utf-8")
import json
data=data.replace("])}while(1);","")
data=json.loads(data)
posts=data["payload"]["references"]["Post"]
for key in posts:
post=posts[key]
print(post["title"])
:::info
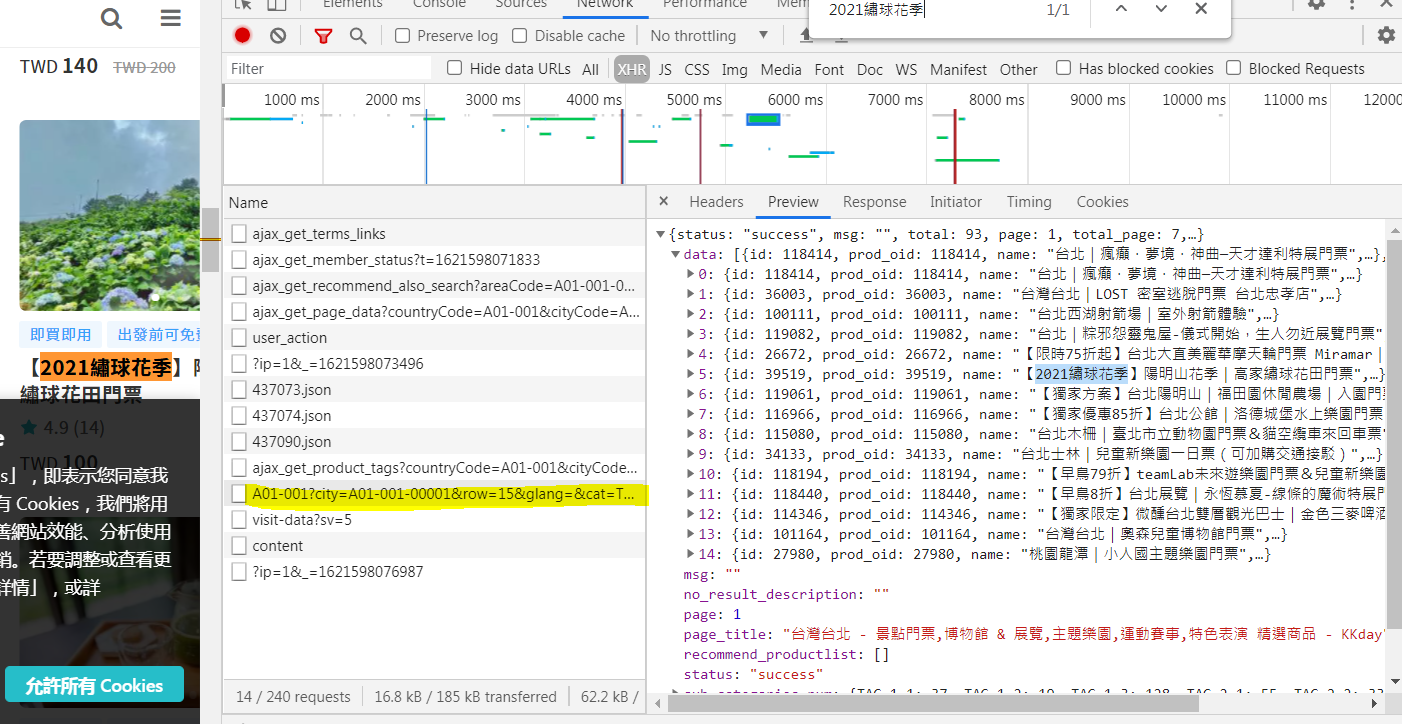
KKDAYS ajax
- 找到文章標題的連結
- 找到真正資料的網址
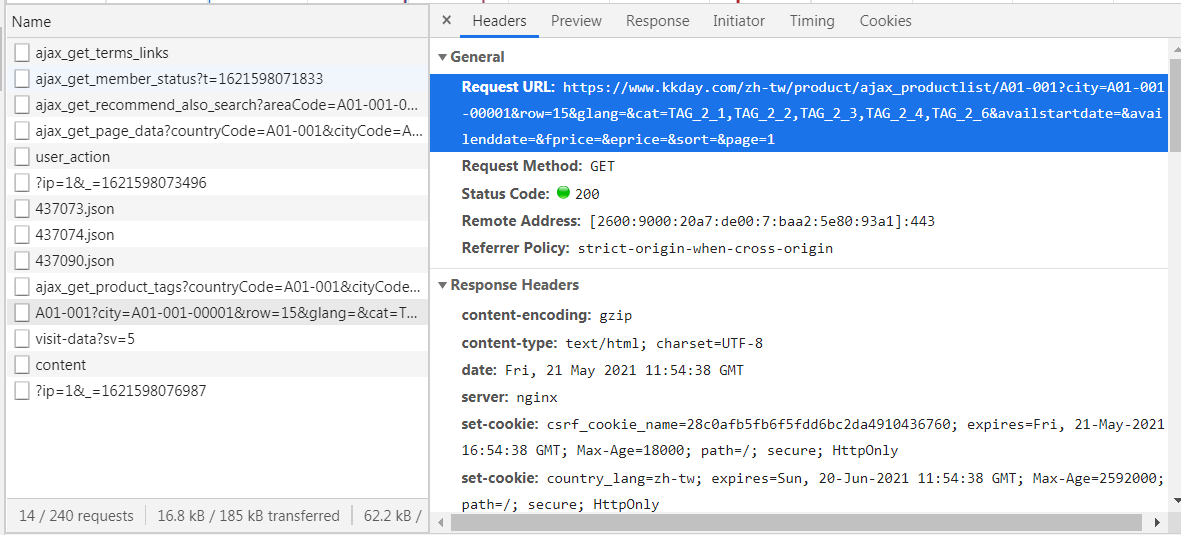
import urllib.request as req
url="https://www.kkday.com/zh-tw/product/ajax_productlist/A01-001?city=A01-001-00001&row=15&glang=&cat=TAG_2_1,TAG_2_2,TAG_2_3,TAG_2_4,TAG_2_6&availstartdate=&availenddate=&fprice=&eprice=&sort=&page=1"
request=req.Request(url, headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36"
})
with req.urlopen(request) as response:
data=response.read().decode("utf-8")
import json
data=json.loads(data)
posts=data["data"]
for key in posts:
print(key["name"])
:::
Request Data 操作實務
抓取 Medium.COM 網站的文章列表資料 2021 版
- 什麼是 Request Data
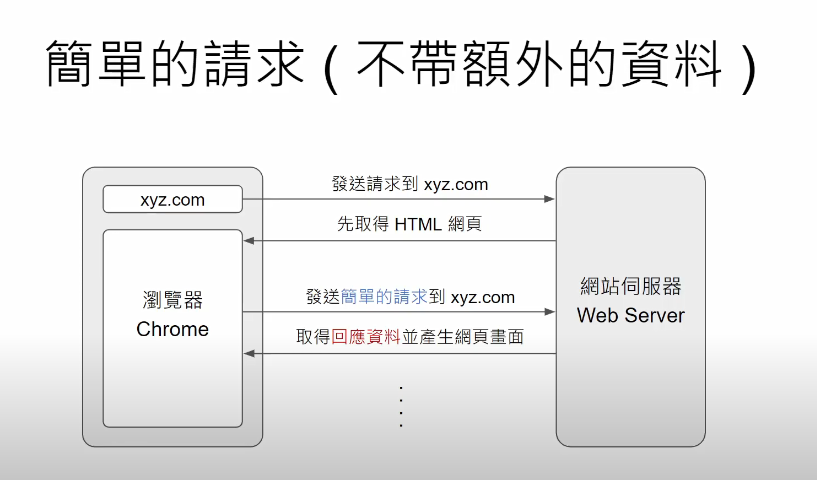
1.1 簡單的請求 v.s 複雜的請求
簡單的請求: 發出request的時候,不夾帶任何除了標頭headers以外的資料
複雜的請求: 發出request的時候,除了header資料還夾帶額外的資料
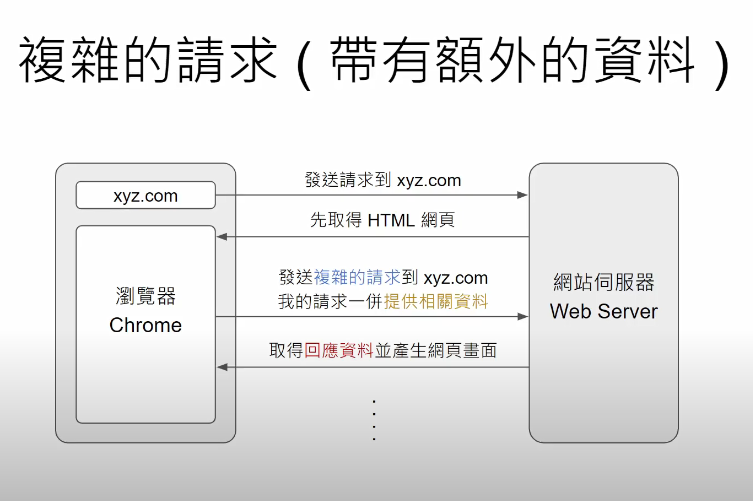
1.2 Request Data
請求中附加的額外資料叫做Request Data(Request Payload, Request Body)
; 抓取 Medium.COM 網站實務操作
:::info
關鍵問題
認出網站的AJAX模式,並懂得發出複雜的請求
:::
2. 複雜請求的觀察
2.1 注意是否有 Request Payload 資訊
2.2 注意 Content-Type 標頭的設定
- 實務操作 Medium.COM 爬蟲 2021 版
3.1 觀察網站運作
3.2 找到首頁文章標題資料網址和相關特性
3.3 利用爬蟲程式,處理標頭、Request Data 等細節後,連線抓取
觀察步驟
- 開起無痕視窗
- 【F12】 (開發者工具)
- 【Network】
- 【重新整理網頁F5】
- 找title相關的地方 一個個去找
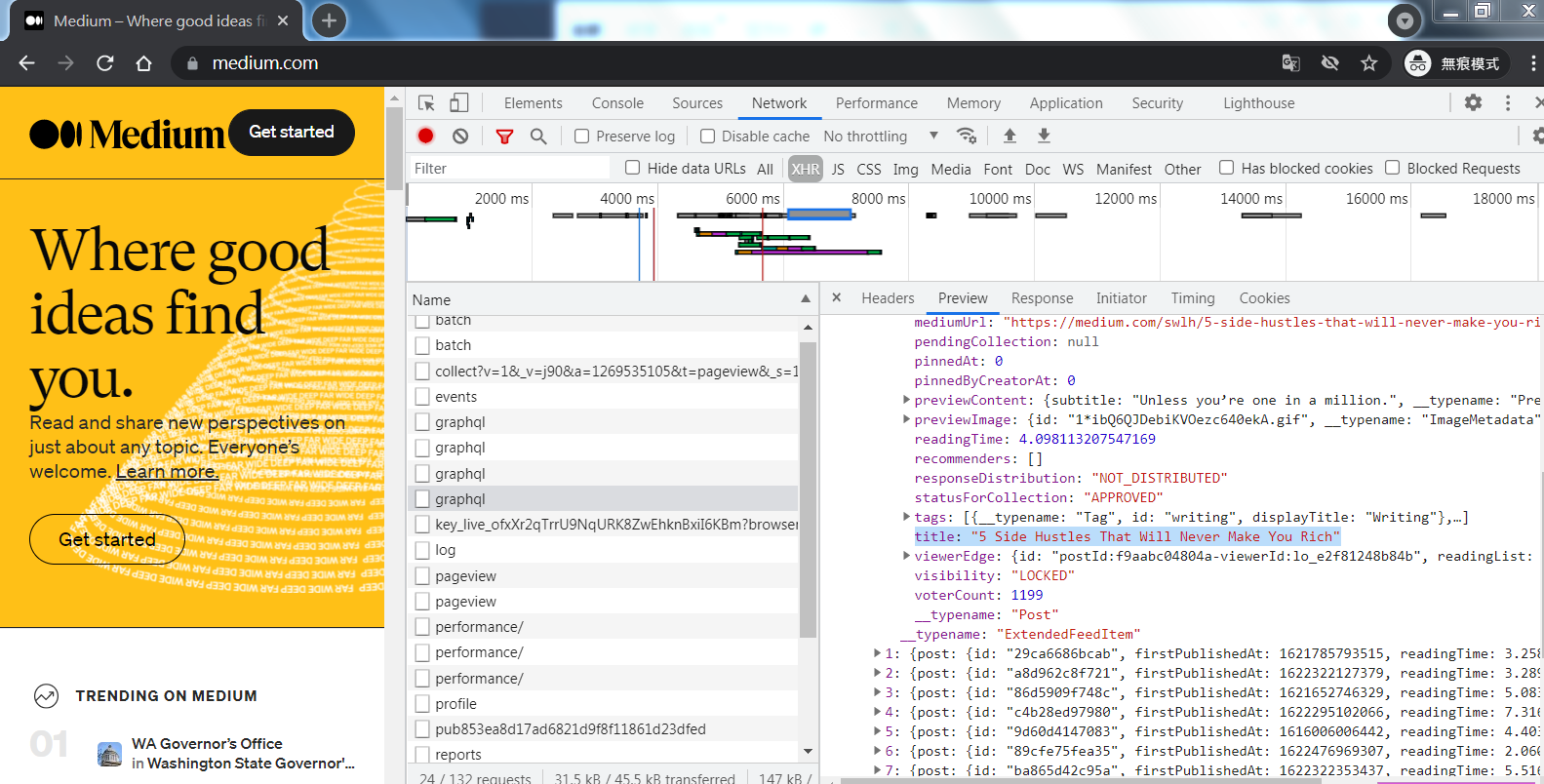
- 【Header】 Request URL: https://medium.com/_/graphql
- Request Payload 就是我們發送請求的附加資訊,一定要附上資訊才會執行
- Request Payload(Request Data) >
view source>Show more> 要全部複製 - Request Headers > user-agent 資訊也要代上 user-agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36
- 多一個header要做,會提供附加資訊的格式 Request Headers > content-type: application/json
:::info
application/json 是JSON的全名
::: - 寫code > 研究格式資料 確認標題有在資料中subtitle
- Preview > 找出title在哪一層
import urllib.request as req
import json
url="https://medium.com/_/graphql"
requestData={"operationName":"ExtendedFeedQuery","variables":{"items":[{"postId":"f9aabc04804a","topicId":""},{"postId":"29ca6686bcab","topicId":""},{"postId":"a8d962c8f721","topicId":""},{"postId":"86d5909f748c","topicId":""},{"postId":"c4b28ed97980","topicId":""},{"postId":"9d60d4147083","topicId":""},{"postId":"89cfe75fea35","topicId":""},{"postId":"ba865d42c95a","topicId":""},{"postId":"e884883c0173","topicId":""},{"postId":"5c1283b297e7","topicId":""},{"postId":"bd3a18d9432e","topicId":""},{"postId":"56d4844f34fd","topicId":""},{"postId":"b6360bed7b06","topicId":""},{"postId":"77daca52c0f1","topicId":""},{"postId":"3ae61539e92a","topicId":""},{"postId":"a4e8468435e5","topicId":""},{"postId":"334f246f5894","topicId":""},{"postId":"1ed2b625b4cf","topicId":""},{"postId":"8b9d9adb7ddd","topicId":""},{"postId":"78cd10656656","topicId":""}]},"query":"query ExtendedFeedQuery($items: [ExtendedFeedItemOptions!]!) {\n extendedFeedItems(items: $items) {\n post {\n ...PostListModulePostPreviewData\n __typename\n }\n metadata {\n topic {\n id\n name\n __typename\n }\n __typename\n }\n __typename\n }\n}\n\nfragment PostListModulePostPreviewData on Post {\n id\n firstPublishedAt\n readingTime\n createdAt\n mediumUrl\n previewImage {\n id\n __typename\n }\n title\n collection {\n id\n domain\n slug\n name\n navItems {\n url\n __typename\n }\n logo {\n id\n __typename\n }\n avatar {\n id\n __typename\n }\n __typename\n }\n creator {\n id\n name\n username\n imageId\n mediumMemberAt\n ...userUrl_user\n __typename\n }\n visibility\n isProxyPost\n isLocked\n ...HomeFeedItem_post\n ...HomeReadingListItem_post\n ...HomeTrendingModule_post\n __typename\n}\n\nfragment HomeFeedItem_post on Post {\n __typename\n id\n title\n firstPublishedAt\n mediumUrl\n collection {\n id\n name\n domain\n logo {\n id\n __typename\n }\n __typename\n }\n creator {\n id\n name\n username\n imageId\n mediumMemberAt\n __typename\n }\n previewImage {\n id\n __typename\n }\n previewContent {\n subtitle\n __typename\n }\n readingTime\n tags {\n ...TopicPill_tag\n __typename\n }\n ...BookmarkButton_post\n ...CreatorActionOverflowPopover_post\n ...PostPresentationTracker_post\n ...PostPreviewAvatar_post\n}\n\nfragment TopicPill_tag on Tag {\n __typename\n id\n displayTitle\n}\n\nfragment BookmarkButton_post on Post {\n ...SusiClickable_post\n ...WithSetReadingList_post\n __typename\n id\n}\n\nfragment SusiClickable_post on Post {\n id\n mediumUrl\n ...SusiContainer_post\n __typename\n}\n\nfragment SusiContainer_post on Post {\n id\n __typename\n}\n\nfragment WithSetReadingList_post on Post {\n ...ReadingList_post\n __typename\n id\n}\n\nfragment ReadingList_post on Post {\n __typename\n id\n viewerEdge {\n id\n readingList\n __typename\n }\n}\n\nfragment CreatorActionOverflowPopover_post on Post {\n allowResponses\n id\n statusForCollection\n isLocked\n isPublished\n clapCount\n mediumUrl\n pinnedAt\n pinnedByCreatorAt\n curationEligibleAt\n mediumUrl\n responseDistribution\n visibility\n ...useIsPinnedInContext_post\n pendingCollection {\n id\n name\n creator {\n id\n __typename\n }\n avatar {\n id\n __typename\n }\n viewerEdge {\n id\n isEditor\n __typename\n }\n domain\n slug\n __typename\n }\n creator {\n id\n viewerEdge {\n id\n isBlocking\n __typename\n }\n ...MutePopoverOptions_creator\n ...auroraHooks_publisher\n __typename\n }\n collection {\n id\n name\n creator {\n id\n __typename\n }\n avatar {\n id\n __typename\n }\n viewerEdge {\n id\n isEditor\n __typename\n }\n domain\n slug\n ...MutePopoverOptions_collection\n ...auroraHooks_publisher\n __typename\n }\n viewerEdge {\n clapCount\n id\n shareKey\n __typename\n }\n ...ClapMutation_post\n __typename\n}\n\nfragment MutePopoverOptions_creator on User {\n id\n __typename\n}\n\nfragment MutePopoverOptions_collection on Collection {\n id\n __typename\n}\n\nfragment ClapMutation_post on Post {\n __typename\n id\n clapCount\n viewerEdge {\n id\n clapCount\n __typename\n }\n ...MultiVoteCount_post\n}\n\nfragment MultiVoteCount_post on Post {\n id\n ...PostVotersNetwork_post\n __typename\n}\n\nfragment PostVotersNetwork_post on Post {\n voterCount\n viewerEdge {\n id\n clapCount\n __typename\n }\n recommenders {\n name\n __typename\n }\n __typename\n id\n}\n\nfragment useIsPinnedInContext_post on Post {\n id\n collection {\n id\n __typename\n }\n pendingCollection {\n id\n __typename\n }\n pinnedAt\n pinnedByCreatorAt\n __typename\n}\n\nfragment auroraHooks_publisher on Publisher {\n __typename\n ... on Collection {\n isAuroraEligible\n isAuroraVisible\n viewerEdge {\n id\n isEditor\n __typename\n }\n __typename\n id\n }\n ... on User {\n isAuroraVisible\n __typename\n id\n }\n}\n\nfragment PostPresentationTracker_post on Post {\n id\n visibility\n previewContent {\n isFullContent\n __typename\n }\n collection {\n id\n slug\n __typename\n }\n __typename\n}\n\nfragment PostPreviewAvatar_post on Post {\n __typename\n id\n collection {\n id\n name\n ...CollectionAvatar_collection\n ...collectionUrl_collection\n __typename\n }\n creator {\n id\n username\n name\n ...UserAvatar_user\n ...userUrl_user\n __typename\n }\n}\n\nfragment CollectionAvatar_collection on Collection {\n name\n avatar {\n id\n __typename\n }\n ...collectionUrl_collection\n __typename\n id\n}\n\nfragment collectionUrl_collection on Collection {\n id\n domain\n slug\n __typename\n}\n\nfragment UserAvatar_user on User {\n __typename\n username\n id\n name\n imageId\n mediumMemberAt\n ...userUrl_user\n}\n\nfragment userUrl_user on User {\n __typename\n id\n customDomainState {\n live {\n domain\n __typename\n }\n __typename\n }\n username\n hasSubdomain\n}\n\nfragment HomeReadingListItem_post on Post {\n id\n title\n creator {\n id\n name\n username\n ...UserAvatar_user\n __typename\n }\n mediumUrl\n createdAt\n readingTime\n collection {\n id\n name\n navItems {\n url\n __typename\n }\n ...CollectionAvatar_collection\n __typename\n }\n visibility\n __typename\n}\n\nfragment HomeTrendingModule_post on Post {\n id\n ...HomeTrendingPostPreview_post\n __typename\n}\n\nfragment HomeTrendingPostPreview_post on Post {\n id\n title\n mediumUrl\n readingTime\n firstPublishedAt\n ...PostPreviewAvatar_post\n ...PostPresentationTracker_post\n __typename\n}\n"}
request=req.Request(url, headers={
"Content-Type":"application/json",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36"
}, data=json.dumps(requestData).encode("utf-8"))
with req.urlopen(request) as response:
result=response.read().decode("utf-8")
result=json.loads(result)
items=result["data"]["extendedFeedItems"]
for item in items:
print(item["post"]["title"])
Flask 網站架設
基礎環境建置
- 安裝 Flask
pip install Flask - 建立專案資料夾 網站專案,撰寫程式
在電腦中的任一位置建立”專案資料夾”
撰寫第一支網站伺服器端的程式
2.1 認識__name__代表目前執行的模組名稱
2.2 認識函式的裝飾 (function decorators):附加在函式上的功能 - 啟動網站 伺服器、測試網站
3.1 學會啟動網站(使用命令列執行py程式,即起動網站)
測試網站: 將網址貼到瀏覽器的網址列中,測試網站運作
3.2 網站程式的基礎觀念
3.3 網站的路徑 (path) 處理
:::warning
此部分只有在自己主機才能運作
:::
專案建立步驟
- 在電腦中建立一個資料夾
- VScode打開剛剛的資料夾
- 在Terminal 安裝 pip install Flask
- 建立新的python程式app.py檔
:::info
如果成功啟動,會出現
* Running on http://127.0.0.1:5000/
如果要測試的話 直接按住ctrl+點擊 http://127.0.0.1:5000/
:::
from flask import Flask
app=Flask(__name__)
@app.route("/")
def home():
return "Hello Flask"
if __name__=="__main__":
app.run()
如果在網址 http://127.0.0.1:5000/test
後面加上 test會無法找到網頁
這部分可以額外處理
@app.route("/test")
def test():
return "this is test"
Heroku 雲端主機教學
- 建立Flask專案描述檔
1.1 建立 runtime.txt
描述使用的python環境
1.2 建立 requirements.txt
描述程式運作所需要的套件
1.3 建立 Procfile
告訴Heroku如何執行程式 - 安裝 Git Tool
:::info
請搜尋Git ,下載並安裝Git tool
::: - 建立 Heroku App 應用程式
選擇建立App應用程式
3.1 註冊帳號,注意信箱驗證
3.2 建立 Heroku 應用程式 -
部屬到 Heroku App
4.1 安裝 Heroku CLI 命令列工具
按照Heroku官網,應用程式中的指示安裝
4.2 執行初始化命令
4.3 執行部屬命令 -
使用命令列模式 > 以下步驟使用命令列模式執行
- 登入Heroku > Heroku login
- 初始化專案:未來專案不用一直做 這2行命令在一開始做一次就好
git init
heroku git:remote -a 專案名稱
- 更新專案:只要新程式要送到雲端更新 就要跑這3行命令
git add .
git commit -m "更新的訊息"
git push heroku master
- 將程式部屬到Heroku App並測試
建立檔案
runtime.txt
runtime.txt=1
python-3.6.8</p>
<pre><code>
**requirements.txt**
.txt=1
Flask
gunicorn
:::info
gunicorn用途: 在heroku上面啟動我的專案
:::
Procfile
procfile=1
web gunicorn app:app</p>
<pre><code>
:::info
Procfile沒有附檔名,不用附檔名
主要用途 告訴heroku要怎麼啟動我們的專案
第一個app 對應的是app.py檔案
第二個app 對應的是code中
=
app=Flask(__name__) # __name__ 代表目前執行的模組
:::
瘋狂點擊next完成安裝
測試開發用,密碼:
- 點
New>create new app - 建立 App name:
python-training-sunnychoose region(主機位址) >create app - 找到
Deploy(部屬) >
安裝Download and install the Heroku CLI
也是閉眼安裝
:::info
在CMD 確認有無裝好,CMD打以下 如果沒有error,有詳細訊息就是已經裝好了
git
usage: git [--version] [--help] [-C <path>] [-c <name>=<value>]
[--exec-path[=<path>]] [--html-path] [--man-path] [--info-path]
[-p | --paginate | -P | --no-pager] [--no-replace-objects] [--bare]
[--git-dir=<path>] [--work-tree=<path>] [--namespace=<name>]
[--super-prefix=<path>] [--config-env=<name>=<envvar>]
<command> [<args>]
</args></envvar></name></path></name></path></path></path></value></name></path>
heroku
VERSION
heroku/7.53.0 win32-x64 node-v12.21.0
:::
Heroku 專案
- Terminal中打上,即登入heroku的帳號密碼
cmd=1
Heroku login</p>
<pre><code>* 初始化專案 (Terminal中) 只須做一次,未來不用在做
=1
git init #回傳Initialized empty Git repository in F:/VS/Programs/FlaskWeb_py/.git/
heroku git:remote -a python-training-sunny
:::info
如果有出現更新需求,可以不用理他
» Warning: heroku update available from 7.53.0 to 7.54.0.
:::
- 部屬Heroku App
cmd=1
git add .
git config --global user.email "XXX@gmail.com"
git config --global user.name "NAME"
git commit -m "First Deploy"
git push heroku master
會回傳目前雲端再發生的事情,需要等他一下
remote: https://python-training-sunny.herokuapp.com/ deployed to Heroku</p>
<pre><code>* 前往 https://python-training-sunny.herokuapp.com/
* 確認 https://python-training-sunny.herokuapp.com/test 也有出現
#### 如果修改程式,還沒反應到線上
* 重新部屬
Terminal上
=1
git add .
git commit -m "Second Deploy"
git push heroku master
:::success
建議:
如果在本機端覺得測試OK了,差不多了
在用部屬命令 部屬到雲端會比較快
:::
argparse
Argparse 教學
Python实用模块(二十六)argparse
- nargs – 命令行参数应当消耗的数目,可选值为:?为0或1个参数;*为0或所有参数;+所有,并且至少一个参数
- name or flags – 一个命名或者一个选项字符串的列表,例如 weight 或 -w, –weight
- action – 当参数在命令行中出现时使用的动作基本类型。store_true和store_false是store_const分别用作存储True和False值的特殊用例,它们的默认值分别为False和True
- const – 被一些action和nargs选择所需求的常数
- default – 当参数未在命令行中出现时使用的默认值
- type – 命令行参数应当被转换成的类型
- choices – 参数值只能从几个选项里面选择
- required – 此命令行选项是否可省略,如果为True,不设置的话,会报错
- help – 一个此选项作用的简单描述
- metavar – 在使用方法消息中使用的参数值示例
- dest – 设置参数在代码中的变量名
Finish [name=Sunny] [time=Sun, Jun 10, 2021] [color=#907bf7]
Original: https://blog.csdn.net/fan84sunny/article/details/123670389
Author: fan84sunny
Title: 【繁中】Python 教學 爬蟲基礎
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/750309/
转载文章受原作者版权保护。转载请注明原作者出处!