

1实验环境
1.1本次实验采用python、flask、hadoop分布式集群。需要搭建的环境包括:Python、flask、MySql和hadoop分布式集群。编程主要在 Visual studio Code中进行。
1.2主要环境包括
1.2.1Flask环境配置
首先搭建flask,创建文件夹,在虚拟环境中运行。


virtualenv是一个虚拟的Python环境构建器。 帮助用户并行创建多个Python环境。 因此,它可以避免不同版本的库之间的兼容性问题。这里使用虚拟环境在开发和生产中管理项目的依赖关系。虚拟环境是独立的Python库组,每个项目一个环境。一个项目安装的软件包不会影响其他项目或操作系统的软件包,安装virtualenv。
pip install virtualenv
venv\scripts\activate
app.route(rule, options):rule 参数表示与该函数绑定的URL。options 是要转发给底层Rule对象的参数列表。
通过flak连接数据库和前端,结合python读取数据库数据,对数据进行分析和统计,将数值的结果反馈到前端。引入ECharts它是一个使用 JavaScript 实现的开源可视化库,使用它将数据动态展示出来。
下载:echarts.min.js
数据库:https:
1.2.2搭建hadoop分布式集群
集群的部署集群可以采用分布式集群或者伪分布式集群,我这里采用的是分布式集群原理和伪分布式集群一样。
主要实现的步骤如下:
- 静态ip的设置
将虚拟机IP设为静态,并进行配置
[root@ljc100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改为如下
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="e59bb0ad-2918-4de6-93fa-46bd94c0a474"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.87.100
GATEWAY=192.168.87.2
DNS1=192.168.87.2
- 主机名的设置
- hosts文件修改(ip和主机名的映射关系)
vim /etc/sysconfig/network-scripts/ifcfg-ens33
[root@hadoop100 ~]# hostname
hadoop100
[root@hadoop100 ~]# more /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.87.100 hadoop100
192.168.87.101 hadoop101
192.168.87.102 hadoop102
192.168.87.110 hadoop110
- 关闭防火墙(临时和永久)
关闭防火墙,关闭防火墙开机自启
[root@ljc100 ~]# systemctl stop firewalld
[root@ljc100 ~]# systemctl disable firewalld.service
- ssh免密码登录
实现在集群中免密码登录
主节点能免密码登录其他的从节点
cd /data
cd soft/hadoop-3.2.2
ssh-copy-id -i hadoop101
yes
Password:123456
ssh hadoop101
- JDK的安装(jdk1.8)
- hadoop伪分布式的安装,4个配置文件的配置
- 将配置文件拷贝到另两个从节点(hadoop101、hadoop102)
……配置文件过程忽略
将配置拷贝到其他
[root@hadoop100 hadoop-3.2.2]# cd ..
[root@hadoop100 soft]# scp -rq hadoop-3.2.2 hadoop101:/data/soft/
[root@hadoop100 soft]# scp -rq hadoop-3.2.2 hadoop102:/data/soft/
[root@hadoop100 hadoop-3.2.2]# jps
33072 SecondaryNameNode
33712 Jps
33353 ResourceManager
32827 NameNode
- 启动和关闭hadoop集群
这里注意我们可以简化工程量,只要做到主节点对两个从节点的免密码登录,下载hadoop后对文件进行配置完成后,需要对hadoop进行初始化一次,以后就不需要初始化,命令启动集群。
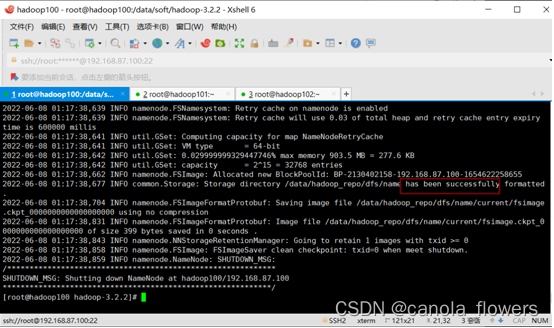
[root@hadoop100 hadoop-3.2.2]# bin/hdfs namenode -format

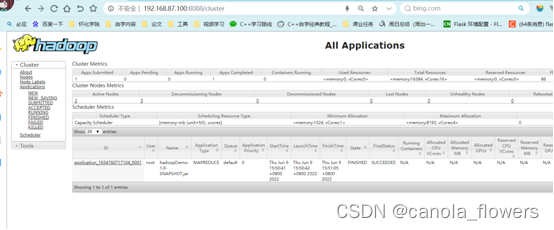
启动和关闭集群。搭建成功后可以通过浏览器查看集群实现的效果,我这里通过8088和9870两个端口可以查看。
启动:sbin/start-all.sh
关闭:sbin/stop-all.sh
2数据集选用及爬取
2.1数据集来源1
数据来源: http://xxfb.mwr.cn/sq_djdh.html,对”全国大江大河实时水情”进行动态的爬(real-time_rep.py),该网站的数据每一日都是变化的,也就是每日更新数据,过去的数据不展示,通过”任务计划程序”每日定时执行代码进行爬取。
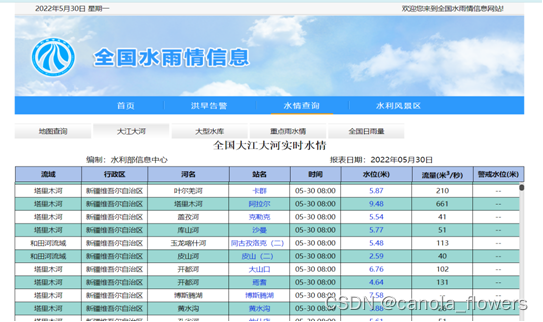
(该网页信息爬取有专门的一个博客介绍,可自行查找)
attributes = {
"poiAddv": "行政区",
"poiBsnm": "流域",
"ql": "流量",
"rvnm": "河名",
"stcd": "站点代码",
"stnm": "站名",
"tm": "时间",
"webStlc": "站址",
"wrz": "警戒水位",
"zl": "水位",
"dateTime": "日期"
}
requests.packages.urllib3.disable_warnings()
html = requests.get('http:
if html.status_code == 200:
resour = html.json()
rivers = dict(resour)["result"]["data"]#转数组了
river_table = pd.DataFrame(rivers[0], index=[0])
for i in range(1, len(rivers)):
river_table = pd.concat([river_table, pd.DataFrame(rivers[i], index=[0])])
for str_col_name in ["poiAddv", "poiBsnm", "rvnm", "stnm", "webStlc"]:
river_table[str_col_name] = river_table[str_col_name].apply(lambda s: s.strip())
river_table.columns=(attributes.get(i) for i in river_table.columns)
river_table.index = range(len(river_table.index))
river_temp = river_table["时间"].values[0].split(" ")[0]
print (river_table["时间"].values[0].split(" ")[0])
out_csv = os.path.join('./data/全国大江大河实时水情/', "全国大江大河实时水情{0}.csv".format(river_temp))
river_table.to_csv(out_csv, encoding="utf_8_sig")
将爬取得到的数据保存到csv文件中,然后通过realata.py选择性的将数据导入数据库中。
conn = pymysql.connect(
host='localhost',
user='root',
passwd='root',
db='bigdate',
port=3306,
charset='utf8'
)
# 获得游标
cur = conn.cursor()
# 创建插入SQL语句
query = 'insert into real-time_rep (id,日期,行政区,流域,流量,河名,站点代码,站名,时间,站址,警戒水位,水位) values (%s, %s, %s, %s, %s, %s,%s, %s, %s, %s, %s, %s)'
# 创建一个for循环迭代读取xls文件每行数据的, 从第二行开始是要跳过标题行
for r in range(1, sheet.nrows):
id = sheet.cell(r,0).value
日期 = sheet.cell(r,1).value
行政区 = sheet.cell(r, 2).value
流域 = sheet.cell(r, 3).value
流量 = sheet.cell(r, 4).value
河名 = sheet.cell(r, 5).value
站点代码 = sheet.cell(r, 6).value
站名 = sheet.cell(r, 7).value
时间 = sheet.cell(r, 8).value
站址 = sheet.cell(r, 9).value
警戒水位 = sheet.cell(r, 10).value
水位 = sheet.cell(r, 11).value
values = (id,日期,行政区,流域,流量,河名,站点代码,站名,时间,站址,警戒水位,水位)
# 执行sql语句
cur.execute(query, values)
cur.close()
conn.commit()
conn.close()
columns = str(sheet.ncols)
rows = str(sheet.nrows)
print ("导入 " +columns + " 列 " + rows + " 行数据到MySQL数据库!")
最后使用windows自带的”任务计划程序”来实现定时执行程序。
2.2数据集来源2
数据来源, http://www.stats.gov.cn/tjsj/ndsj/2021/indexch.htm。获取中国统计年鉴2021中8-9_水资源情况和8-10_供水用水情况的表单数据,然后通过real_time.py选择性的导入数据库中。水资源情况记录了从2005年到2020年的水资源组成数据。8-9_水资源情况由地下水、地表水、重复量、人均水资源四个部分组成。8-10_供水用水情况由农业、工业、生活、人工生态、人均用水量构成。
预处理:水资源是由年份和城市两个部分构成可以拆分成两个数据表存储。分别对年份和主城市进行分析,所以存储时构建两个表。该数据统计 2000-2005年间的数据是丢失的,所以在数据分析和挖掘的时候,应该对第一行数据进行舍弃避免对最后结果造成影响。
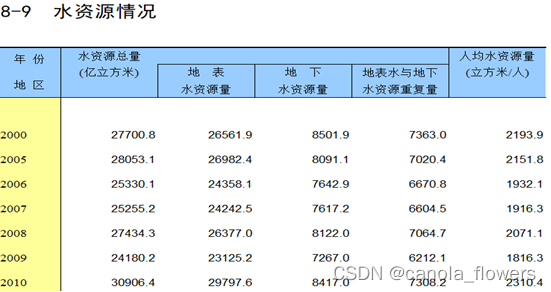
以下是数据库相关数据详细图



; 3 Hadoop集群对数据预处理和上传
爬取的数据water06-07.csv约有2000条左右,为了高效率的处理分析数据和保存海量数据,至此我们采用集群的方式进行处理。首先将数据集上传到虚拟机hadoop100的本地目录下。
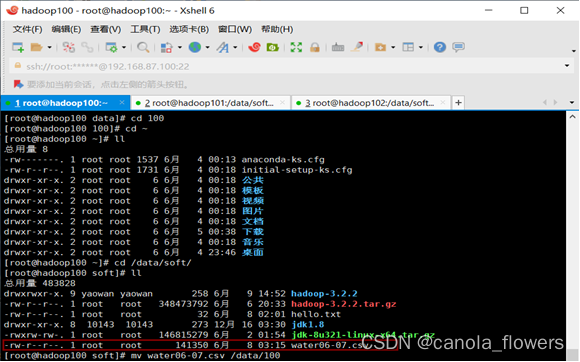
预处理:将数据的前5行进行打印。可以观察出数据中第一行是不需要的,其次可以观察出,日期和时间这两列数据是重复的,可以对其之一进行舍弃。
[root@hadoop100 100]# head -5 water06-07.csv
,日期,行政区,流域,流量,河名,站点代码,站名,时间,站址,警戒水位,水位
0,06-07 08:00,吉林省,黑龙江,745,嫩江,11203200,大赉,2022-06-07 08:00:00,吉-大安,131.74,126.55
1,06-07 08:00,吉林省,黑龙江,668,松花江,10901900,扶余,2022-06-07 08:00:00,吉-扶余,133.56,130.86
2,06-07 08:00,新疆维吾尔自治区,艾比湖,5,博尔塔拉河,00400050,温泉(合成),2022-06-07 08:00:00,新-温泉,0.05.74
3,06-07 08:00,新疆维吾尔自治区,艾比湖,24,精河,00401050,精河山口(三),2022-06-07 08:00:00,新-精河,0.0,.12
将数据中的第一行删除
[root@hadoop100 100]# sed -i '1d' water06-07.csv
[root@hadoop100 100]# head -5 water06-07.csv
0,06-07 08:00,吉林省,黑龙江,745,嫩江,11203200,大赉,2022-06-07 08:00:00,吉-大安,131.74,126.55
1,06-07 08:00,吉林省,黑龙江,668,松花江,10901900,扶余,2022-06-07 08:00:00,吉-扶余,133.56,130.86
通过脚本将重复列剔除然后重定向到out.txt文件里。
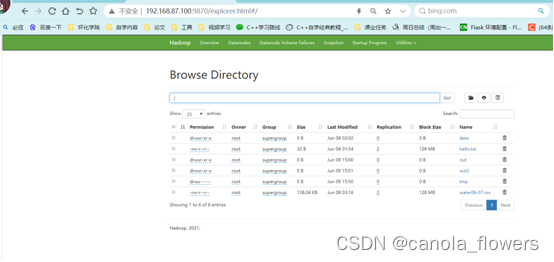
将out.txt文件上传到集群中保存。以后要使用数据,可以通过集群下载到本地进行使用。
[root@hadoop100 100]# cat pre_deal.sh
#!/bin/bash
infile=$1
outfile=$2
#注意,最后的$infile> $outfile必须跟在}'这两个字符的后面
awk -F "," '{
print $2"\t"$3"\t"$4"\t"$5"\t"$6"\t"$8"\t"$10"\t"$11"\t"$12
}' $infile> $outfile
[root@hadoop100 100]# vim pre_deal.sh
[root@hadoop100 100]# bash ./pre_deal.sh water06-07.csv out.txt
[root@hadoop100 100]# head -10 out.txt
06-07 08:00 吉林省 黑龙江 745 嫩江 大赉 吉-大安 131.74 126.55
06-07 08:00 吉林省 黑龙江 668 松花江 扶余 吉-扶余 133.56 130.86
06-07 08:00 新疆维吾尔自治区 艾比湖 5 博尔塔拉河 温泉(合成) 新-温泉 0.0
06-07 08:00 新疆维吾尔自治区 艾比湖 24 精河 精河山口(三) 新-精河 0.0 4.12
06-07 08:00 新疆维吾尔自治区 玛纳斯湖流域 45 玛纳斯河 肯斯瓦特 新-玛纳
06-07 08:00 新疆维吾尔自治区 内陆河 11 乌鲁木齐河 英雄桥 新-乌鲁木齐 0.0
06-07 08:00 新疆维吾尔自治区 内陆河湖 4 开垦河 开垦河(合成) 新-奇台 0.0
06-07 08:00 新疆维吾尔自治区 内陆河湖 2 阿拉沟 阿拉沟 新-吐鲁番
0.0
06-07 08:00 新疆维吾尔自治区 哈密、吐鲁番地区诸河 0 头道沟 头道沟 哈密市天山乡头
06-07 08:00 新疆维吾尔自治区 塔里木河 203 叶尔羌河 库鲁克栏干 新-塔什
[root@hadoop100 100]# hdfs dfs -put ./out.txt /data/
[root@hadoop100 100]# hdfs dfs -cat /data/out.txt | head -5
06-07 08:00 吉林省 黑龙江 745 嫩江 大赉 吉-大安 131.74 126.55
06-07 08:00 吉林省 黑龙江 668 松花江 扶余 吉-扶余 133.56 130.86
06-07 08:00 新疆维吾尔自治区 艾比湖 5 博尔塔拉河 温泉(合成) 新-温泉 0.0
06-07 08:00 新疆维吾尔自治区 艾比湖 24 精河 精河山口(三) 新-精河 0.0 4.12
06-07 08:00 新疆维吾尔自治区 玛纳斯湖流域 45 玛纳斯河 肯斯瓦特 新-玛纳
06-07 08:00 新疆维吾尔自治区 内陆河 11 乌鲁木齐河 英雄桥
cat: Unable to write to output stream.
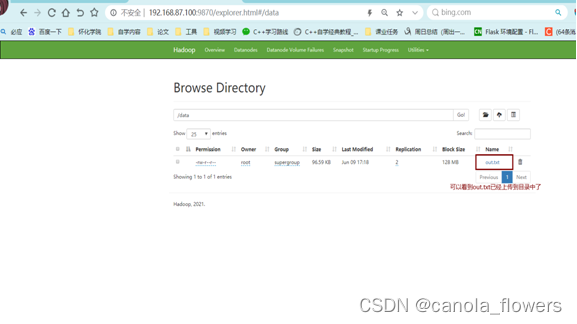
4 数据集分析
4.1统计技术
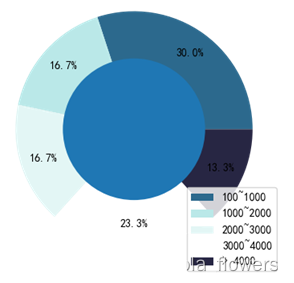
统计数据集中主城市按照按不同的人均用水量划分成5个级别:
- 人均用水量100~1000立方米/人
- 人均用水量1000~2000立方米/人
- 人均用水量2000~3000立方米/人
- 人均用水量3000~4000立方米/人
- 人均用水量 > 4000立方米/人
使用python连接数据库,将主城市按照以上五个级别进行划分,划分后从数据库中获取的数据再反馈到flask,由flask反馈到前端页面,由echarts展示。
通过环状图进行展示。通过观察可以发现,占30%的主城市的人均用水量在100~1000(立方米/人),只有少数的主要城市的用水量高达4000立方米/人以上,所以可以分析得出,全国主要城市还是处于水资源不足的状态,重视水资源,采取有效措施来存储和调用水资源是需要关注的重点。
def ring():
conn = pymysql.connect(
host='localhost',
user='root',
passwd='root',
db='bigdate',
port=3306,
charset='utf8'
)
data = {}
cur = conn.cursor()
sqlA = "SELECT COUNT(*)AS A FROM water_city WHERE 人均水资源100;"
cur.execute(sqlA)
Acount = cur.fetchall()[0]
data1 = {'value':Acount[0], 'name': '100~1000m³/人'}
4.2相关性分析
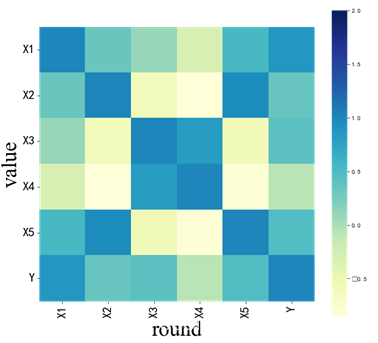
- 采用Person相关系数法求解原始数据,获得相关系数矩阵,分析出对用水总资源影响的因素。
- 按照属性中对于供水总量的影响因素的相关性矩阵,绘制相关性热力图,可以观察出生活用水和人均用水对用水总资源的影响比较明显。
- 将生成的图片保存,然后通过html展示出热力图。
inputfile = './data.csv'
data = pd.read_csv(inputfile)
description = [data.min(), data.max(), data.mean(), data.std()]
description = pd.DataFrame(description, index = ['Min', 'Max', 'Mean', 'STD']).T
print('描述性统计结果:\n',np.round(description, 2))
corr = data.corr(method='pearson')
print('相关系数矩阵为:\n',np.round(corr, 2))
#设置横纵坐标的名称及热力图名称以及对应字体格式
font1 = {'family' : 'Times New Roman',
'weight' : 'normal',
'size' :35,
}
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.subplots(figsize=(20, 20))
plt.figure(num=None, figsize=(10, 9), dpi=80, facecolor='w', edgecolor='k')
sns.heatmap(corr, annot=False, vmax=2, square=True, cmap='YlGnBu')
plt.title("相关性热力图", fontsize=25)
plt.xlabel('round',font1)
plt.ylabel('value',font1)
plt.xticks(fontsize=20,rotation=90)
plt.yticks(fontsize=20,rotation=0)
4.3 模型构建(序列分析)
- 数据预处理
将数据集中的2000年的数据舍弃,因为,2000~2005年的水资源记录数据损失,不利于对最终的序列分析。在数据存入数据库中时,删除偏离值。
- 采用灰色预测算法
灰色预测适合时间序列,尤其是对小数据集有很好的预测效果,结合数据集”供水用水情况”,记录了从2005年到2020年的供水资源的变化、组成和影响的因素,但是数据还是少量的所以还是选用灰度预测算法,通过灰度值构建出2021年和2022年的影响数值的预测值,为SVR算法对最终的供水量提供数值根据。
- SVR算法(支持向量回归)
  依据灰色预测的结果结合SVR,对2021年和2022年的供水总量的预测。
inputfile1 = './new_reg_data.csv'
inputfile2 = './data.csv'
new_reg_data = pd.read_csv(inputfile1) # 读取经过特征选择后的数据
data = pd.read_csv(inputfile2) # 读取总的数据
new_reg_data.index = range(2005, 2021)
new_reg_data.loc[2021] = None
new_reg_data.loc[2022] = None
l = ['x1', 'x2', 'x3', 'x4', 'x5']
for i in l:
f = GM11(new_reg_data.loc[range(2005, 2021),i].values)[0]
new_reg_data.loc[2021,i] = f(len(new_reg_data)-1)
new_reg_data.loc[2022,i] = f(len(new_reg_data))
new_reg_data[i] = new_reg_data[i].round(2)
outputfile = './new_reg_data_GM11.xls' # 灰色预测后保存的路径
y = list(data['y'].values)
y.extend([np.nan,np.nan])
new_reg_data['y'] = y
new_reg_data.to_excel(outputfile) # 结果输出
print('预测结果为:\n',new_reg_data.loc[2021:2022,:]) # 预测结果展示
#6-6
import matplotlib.pyplot as plt
from sklearn.svm import LinearSVR
inputfile = './new_reg_data_GM11.xls'
data = pd.read_excel(inputfile,index_col=0,header=0) # 读取数据
feature = ['x1', 'x2', 'x3', 'x4', 'x5']
data_train = data.loc[range(2005, 2021)].copy()
data_mean = data_train.mean()
data_std = data_train.std()
data_train = (data_train - data_mean)/data_std
x_train = data_train[feature].values
y_train = data_train['y'].values
linearsvr = LinearSVR()
linearsvr.fit(x_train,y_train)
x = ((data[feature] - data_mean[feature])/data_std[feature]).values
data[u'y_pred'] = linearsvr.predict(x) * data_std['y'] + data_mean['y']
outputfile = './new_reg_data_GM11_revenue.xls'
data.to_excel(outputfile)
print('真实值与预测值分别为:\n',data[['y','y_pred']])
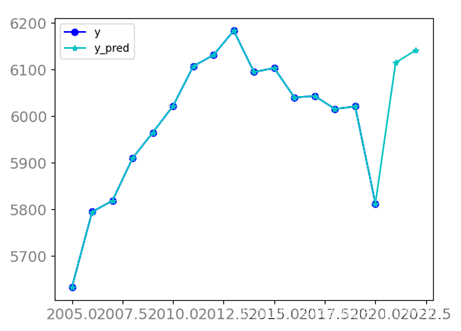
- 折线图可视化
观察可视化的图,明显的观察出,虽然2020年的水资源总量明显下降,但是通过对过去数据的分析,在2021年和2022年的水资源总量还是呈上升趋势。
4.4 结合flask
flask是目前最流行的Python Web框架之一。Flask是使用Python编写的Web微框架。 Flask有两个主 要依赖,一个是WSGI(Web Server Gateway Interface,Web服务器网关 接口)工具集,另一个是 Jinja2模板引擎。Flask只保留了Web开发的核心 功能,其他的功能都由外部扩展来实现,比如数据库集成、表单认证、 文件上传等。
通过flask将数据从数据库获取然后传递到web界面,实现前后端的数据交互。
echarts(Enterprise Charts,商业级数据图表)是一个使用 JavaScript 实现的开源可视化库,可以流畅的运行在 PC 和移动设备上。可以很好进行交互,也能动态展示出数据。
app = Flask(__name__)
#设置编码
app.config['JSON_AS_ASCII'] = False
@app.route('/ring_data')
def ring_data():
import ringPie
data = ringPie.ring()
# return Response(data)
return Response(json.dumps(data), mimetype='application/json')
@app.route('/pie_data')
def data_pit():
import getpart1
data = getpart1.part1()
return Response(json.dumps(data), mimetype='application/json')
@app.route('/')
def index():
import real_time
data = real_time.really()
return render_template('index.html', real_data = data)
if __name__ == '__main__':
app.debug=True
server = pywsgi.WSGIServer(('127.0.0.1', 5000), app)
server.serve_forever()
4.5 可视化展示效果
这里的页面效果是参照了b站的一个echarts的可视化视频教学改编的

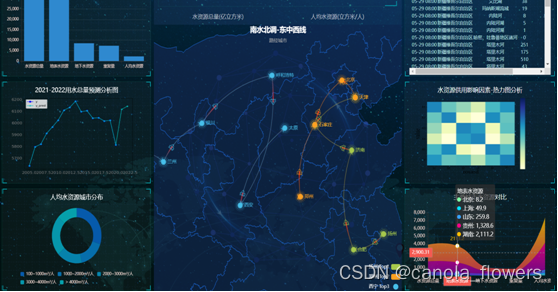
描述:中间部分是南水北调的东、中、西三条线路

使用的图标是由飞机修改得来
5 实验总结
一次可视化作业,让我发现了自己很多的不足,也学习到了很多。可能是对于python比较熟悉,我没有使用spark进行数据分析等,这是一种遗憾,遗憾没有做到所学即所用。通过这次大作业,让我掌握了很多比如对数据的展示,学习了flask和echarts的使用,并且很好的结合了数据挖掘中的很多算法技术,来实现这次的作业,能使用简单的数据挖掘算法。这个项目将前后端分离,将爬取和分析后的数据反馈到flask后,通过flask反馈到前端javascript,最终echarts实现展示。项目完成中出现了数据的传送,数据展示等等一系列问题。集群的搭建和配置对我也是一个巨大的挑战,搭建伪分布式集群和分布式集群,然后学习了一个简单实例,对大数据应用有了更加深刻的了解,使用集群对海量数据进行高效的预处理和多份保存,期间通过对问题的解决对自身的提升有很大的帮助,从项目中我学习到了很多,对自身的很多不足也有了很好的认识,对我是一次宝贵的经验。
希望我的项目分析能对你有所感悟,项目很小,所论述的也是自己的完成的流程和效果,但是通过实践的你可能会收获更大做的更好!
Original: https://blog.csdn.net/canola_flowers/article/details/126227494
Author: Weird奇谭
Title: (大数据应用考察)全国水资源分析可视化
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/747363/
转载文章受原作者版权保护。转载请注明原作者出处!