

目录
一. 介绍
①scrapy对前程无忧网址进行数据爬取
②数据存入mysql
③spark数据清洗
④flask+echarts数据可视化
二.步骤
Scrapy详细介绍:https://blog.csdn.net/ck784101777/article/details/104468780?
1.分析网页
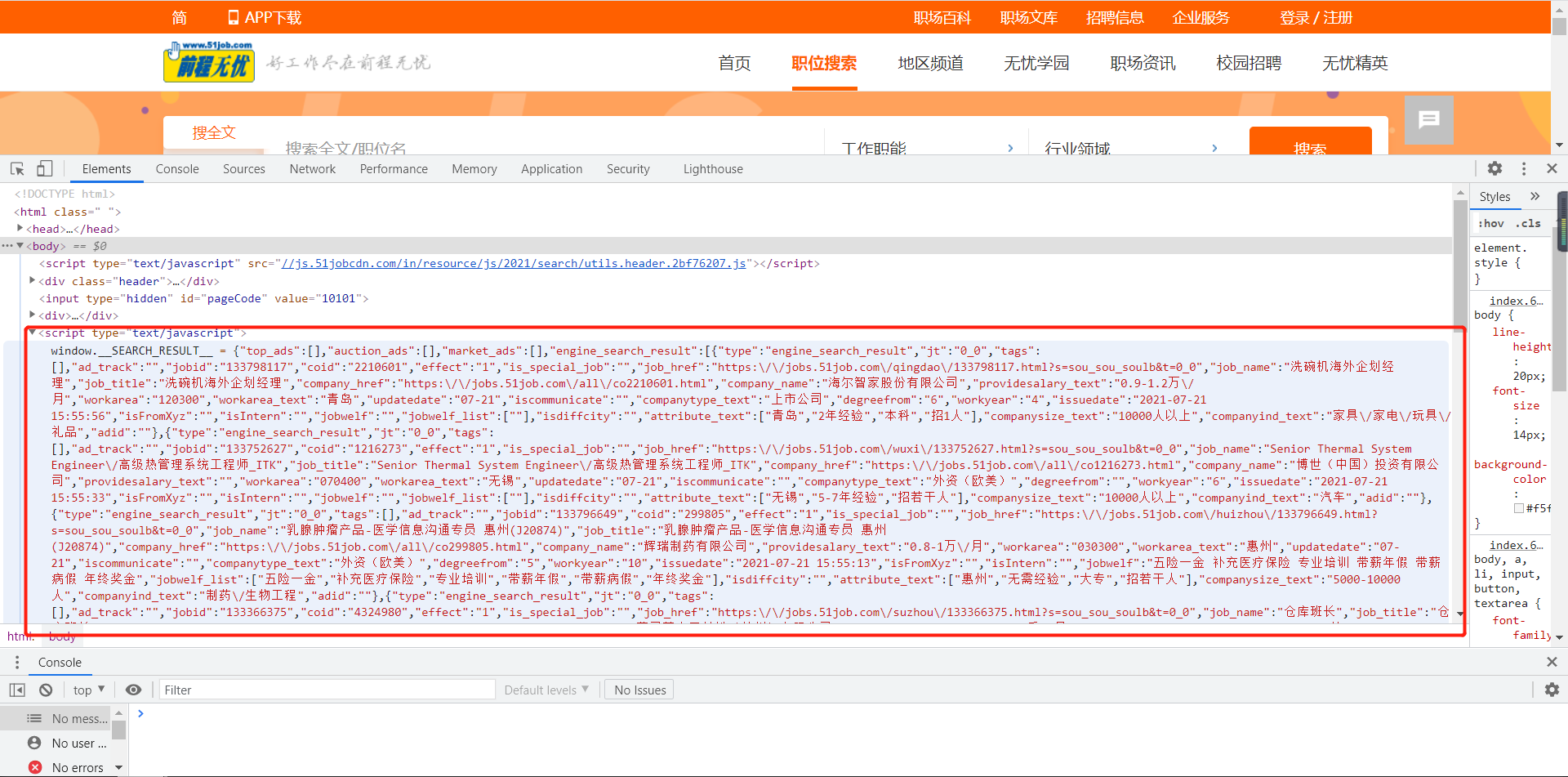

①51job的岗位信息都在 标签中,并且为json格式
②url解析

③URL拼接+翻页操作
class JobSpider(scrapy.Spider):
name = 'job'
allowed_domains = ['search.51job.com']
# start_urls = ['http://search.51job.com/']
job_name = input("请输入岗位:")
# 岗位解析后的代码
keyword = urllib.parse.quote(job_name) + ",2,"
# 页数
# start_urls = f'https://search.51job.com/list/000000,000000,0000,00,9,99,{keyword},2,1.html?'
start_urls = []
# 生成url
for i in range(1, 101):
url_pre = 'https://search.51job.com/list/000000,000000,0000,00,9,99,'
url_end = '.html?'
url = url_pre + keyword + str(i) + url_end # URL拼接
start_urls.append(url) # 将url添加至start_urls
2.爬虫项目代码
创建爬虫
scrapy startproject job51
创建爬虫程序
cd job51
scrapy genspider job search.51job.com
创建执行文件,与scrapy.cfg同级
from scrapy import cmdline
cmdline.execute("scrapy crawl job".split())
settings.py
爬虫名
BOT_NAME = 'job51'
SPIDER_MODULES = ['job51.spiders']
NEWSPIDER_MODULE = 'job51.spiders'
日志等级
LOG_LEVEL = "WARNING"
机器人协议
ROBOTSTXT_OBEY = False
并发执行度
CONCURRENT_REQUESTS = 100
CONCURRENT_REQUESTS_PER_DOMAIN = 100
CONCURRENT_REQUESTS_PER_IP = 100
请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
开启管道
ITEM_PIPELINES = {
'job51.pipelines.Job51Pipeline': 300,
}
pipeline.py
import pymysql
打印logging日志
import logging
logger = logging.getLogger(__name__)
日志输出打印
class Job51Pipeline:
def process_item(self, item, spider):
# 连接MySQL数据库
connect = pymysql.connect(host='localhost', user='root', password='123456', db='spark', port=3306,
charset="utf8")
cursor = connect.cursor()
# 往数据库里面写入数据
try:
cursor.execute(
"insert into scrapy_job VALUES ('{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}')".format(
item["job_id"], item["job_name"], item["job_price"], item["job_url"], item["job_time"],
item["job_place"], item["job_edu"], item["job_exp"], item["job_well"], item["company_name"],
item["company_type"], item["company__mag"], item["company_genre"]))
connect.commit()
except Exception as error:
# 出现错误时打印错误日志
logging.warning(error)
# 关闭数据库
cursor.close()
connect.close()
return item
job.py
import json
import scrapy
import urllib.parse
import re
class JobSpider(scrapy.Spider):
name = 'job'
allowed_domains = ['search.51job.com']
# start_urls = ['http://search.51job.com/']
job_name = input("请输入岗位:")
# 岗位解析后的代码
keyword = urllib.parse.quote(job_name) + ",2,"
# 页数
# start_urls = f'https://search.51job.com/list/000000,000000,0000,00,9,99,{keyword},2,1.html?'
start_urls = []
# 生成url
for i in range(1, 351):
url_pre = 'https://search.51job.com/list/000000,000000,0000,00,9,99,'
url_end = '.html?'
url = url_pre + keyword + str(i) + url_end # URL拼接
start_urls.append(url) # 将url添加至start_urls
def parse(self, response):
# with open("job.html", "w", encoding="gbk") as f:
# f.write(response.text)
re1 = re.compile("""(.*?)""")
selectors = re.findall(re1, response.text)
req2 = response.xpath("/html/body/script/text()").extract_first()[29:]
# with open("job.json", "w", encoding="utf-8") as f:
# f.write(req2)
selectors = json.loads(req2)["engine_search_result"]
item = {}
for selector in selectors:
# job_id, job_name, job_price, job_url: String, job_time: String, job_place: String, job_edu: String, job_exp: String, job_well: String, company_name: String, company_type: String, company_mag: String, company_genre: String
item["job_id"] = selector["jobid"]
item["job_name"] = selector["job_name"]
if (selector["providesalary_text"]):
item["job_price"] = selector["providesalary_text"]
else:
item["job_price"] = ''
item["job_url"] = selector["job_href"]
item["job_time"] = selector["issuedate"]
item["job_place"] = selector["workarea_text"]
if (len(selector["attribute_text"]) > 3):
item["job_edu"] = selector["attribute_text"][2]
else:
item["job_edu"] = "无要求"
item["job_exp"] = selector["attribute_text"][1]
if (selector["jobwelf"]):
item["job_well"] = selector["jobwelf"]
else:
item["job_well"] = " 无福利 "
item["company_name"] = selector["company_name"]
item["company_type"] = selector["companytype_text"]
item["company__mag"] = selector["companysize_text"]
if (selector["companysize_text"]):
item["company__mag"] = selector["companysize_text"]
else:
item["company__mag"] = ""
item["company_genre"] = selector["companyind_text"]
yield item
3.mysql建表
create table scrapy_job(
job_id varchar(100), job_name varchar(200), job_price varchar(100), job_url varchar(100), job_time varchar(100),
job_place varchar(100), job_edu varchar(100), job_exp varchar(100), job_well varchar(200), company_name varchar(100),
company_type varchar(100), company_mag varchar(100), company_genre varchar(100)
)
4.执行程序

查看数据库中的数据
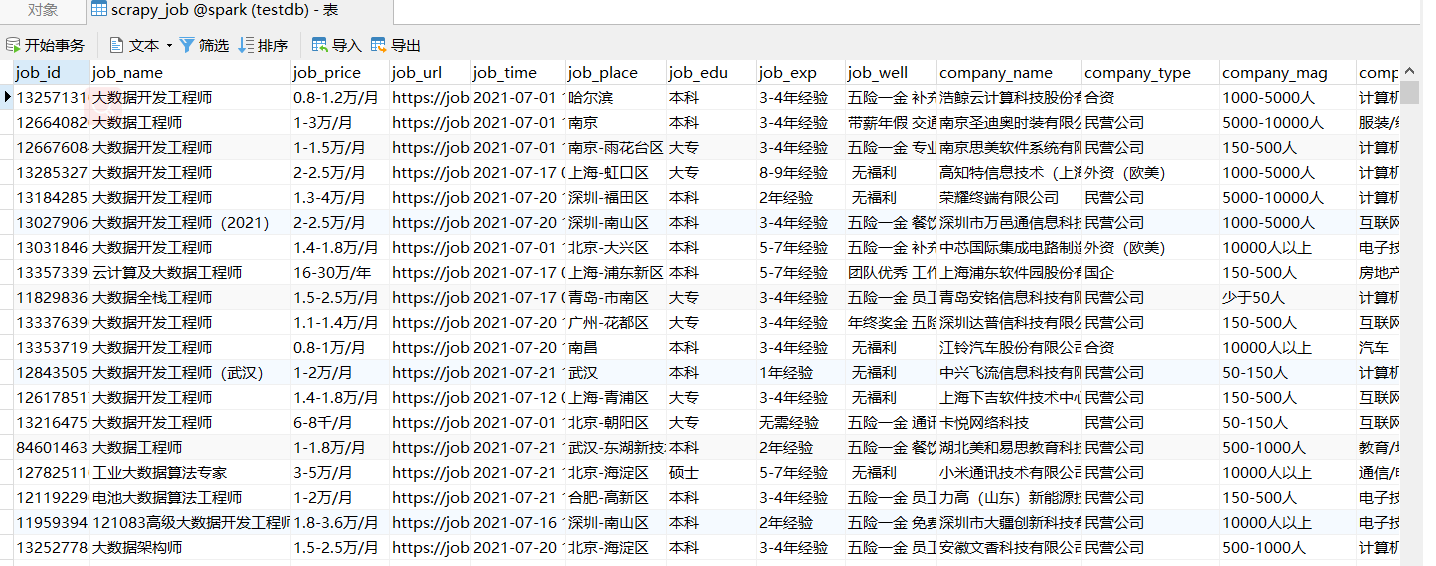
6.Spark数据清洗
① job_exp :取最大数值,例如:5-7年经验 ->7,无需经验则为0,空值设为0
② job_price:取平均工资,1-1.5万/月 ->12500,空值设为0
③ job_time:精确到日期,2021-04-19 13:31:43->2021-04-19,空值设为无发布时间
④ company_type:去掉括号以及括号里的数据
⑤ company_mag:取最大数,150-500人->500,空值设为0
⑥ company_genre:去掉括号以及括号里的数据
⑦ 去重
pom.xml
org.apache.spark
spark-core_2.11
2.1.1
org.apache.spark
spark-sql_2.11
2.1.1
mysql
mysql-connector-java
8.0.21
org.apache.spark
spark-streaming_2.11
2.1.1
com.alibaba
fastjson
1.2.66
com.fasterxml.jackson.core
jackson-core
2.10.1
数据库中copy一份爬虫阶段的表格式,表名为scrapy_job_copy1,用来存放清洗后的数据
代码
package job
import org.apache.spark.sql.{SaveMode, SparkSession}
import java.text.SimpleDateFormat
import java.util.{Date, Properties}
import java.util.regex.{Matcher, Pattern}
object HomeWork1 {
def main(args: Array[String]): Unit = {
/**
* job_exp :取最大数值,例如:5-7年经验 ->7,无需经验则为0,空值设为0
* job_price:取平均工资,1-1.5万/月 ->12500,空值设为0
* job_time:精确到日期,2021-04-19 13:31:43->2021-04-19,空值设为无发布时间
* company_type:去掉括号以及括号里的数据
* company_mag:取最大数,150-500人->500,空值设为0
* company_genre:去掉括号以及括号里的数据
* 去重
*/
//经验
val regex = """\d+""".r
val pattern = Pattern.compile("\\d+")
//薪水
val salary1 = Pattern.compile("""^(\d+?\.?\d*?)\-(\d+?\.?\d*?)万/年$""")
val salary2 = Pattern.compile("""^(\d+?\.?\d*?)\-(\d+?\.?\d*?)万/月$""")
val salary3 = Pattern.compile("""^(\d+?\.?\d*?)\-(\d+?\.?\d*?)千/月$""")
//时间
val format: SimpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val toformat: SimpleDateFormat = new SimpleDateFormat("yyyy-MM-dd")
//去掉括号
val company = Pattern.compile("""(.*?)""")
//mysql
val properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
val session = SparkSession.builder().master("local[1]").appName("te").getOrCreate()
//val rdd = session.read.option("delimiter", ",").option("header", "true").csv("a/job.csv").distinct().rdd
val rdd = session.read.jdbc("jdbc:mysql://localhost:3306/spark?serverTimezone=UTC", "scrapy_job", properties).rdd
val value = rdd.map({
item => {
//TODO job_exp :取最大数值,例如:5-7年经验 ->7,无需经验则为0,空值设为0
var jobexp = "0"
if (item.isNullAt(7) || item.equals("") || ((!item.isNullAt(7)) & item.getAs[String](7).equals("无需经验"))) {
jobexp = "0"
} else {
val iterator = regex.findAllIn(item(7).toString)
iterator.foreach{
x=>{
if(x.toInt > jobexp.toInt){
jobexp = x
}
}
}
// TODO 薪水 job_price:取平均工资,1-1.5万/月 ->12500,空值设为0
var jobprice = 0.0
if(item.isNullAt(2)){
jobprice=0.0
}else {
val matcher1 = salary1.matcher(item.getAs(2)) // 万/年
val matcher2 = salary2.matcher(item.getAs(2)) // 万/月
val matcher3 = salary3.matcher(item.getAs(2)) // 千/月
if(matcher1.find()){
jobprice =(matcher1.group(1).toDouble + matcher1.group(2).toDouble) * 10000 / 24
//print("万/年",jobprice)
}else if(matcher2.find()){
jobprice = (matcher2.group(1).toDouble +matcher2.group(2).toDouble) * 10000 / 2
//print("万/月",jobprice)
}else if(matcher3.find()){
jobprice = (matcher3.group(1).toDouble + matcher3.group(2).toDouble) * 1000
//print("千/月",jobprice)
}
}
//TODO job_time:精确到日期,2021-04-19 13:31:43->2021-04-19,空值设为无发布时间
var jobtime = "无发布时间"
if(!item.isNullAt(4)){
jobtime = toformat.format(format.parse(item.getAs[String](4)))
}
//TODO company_type:去掉括号以及括号里的数据
var companytype = ""
if(!item.isNullAt(10)){
companytype = item.getAs(10).toString.replaceAll("\\(.*?\\)|\\(.*?\\)","")
}
//TODO company_mag:取最大数,150-500人->500,空值设为0
var companymag = 0
if (!item.isNullAt(11)){
val matcher2 = pattern.matcher(item.getAs(11))
while (matcher2.find()) {
if (matcher2.group().toInt > companymag.toInt) {
companymag = matcher2.group().toInt
}
}
}
//TODO company_genre:去掉括号以及括号里的数据
var companygenre = ""
if (!item.isNullAt(12)){
companygenre = item.getString(12).replaceAll("\\(.*?\\)","")
}
Res(item(0).toString,item(1).toString,jobprice.toInt.toString,item(3).toString,jobtime,item(5).toString,item(6).toString,jobexp,item(8).toString,item(9).toString,companytype,companymag.toString,companygenre)
}
})
import session.implicits._
//追加数据到Mysql
value.toDF().write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://localhost:3306/spark?serverTimezone=UTC", "scrapy_job_copy1", properties)
}
case class Res(job_id: String, job_name: String, job_price: String, job_url: String, job_time: String, job_place: String, job_edu: String, job_exp: String, job_well: String, company_name: String, company_type: String, company_mag: String, company_genre: String)
}
7.可视化
1.创建vlsual.py
2.项目结构图
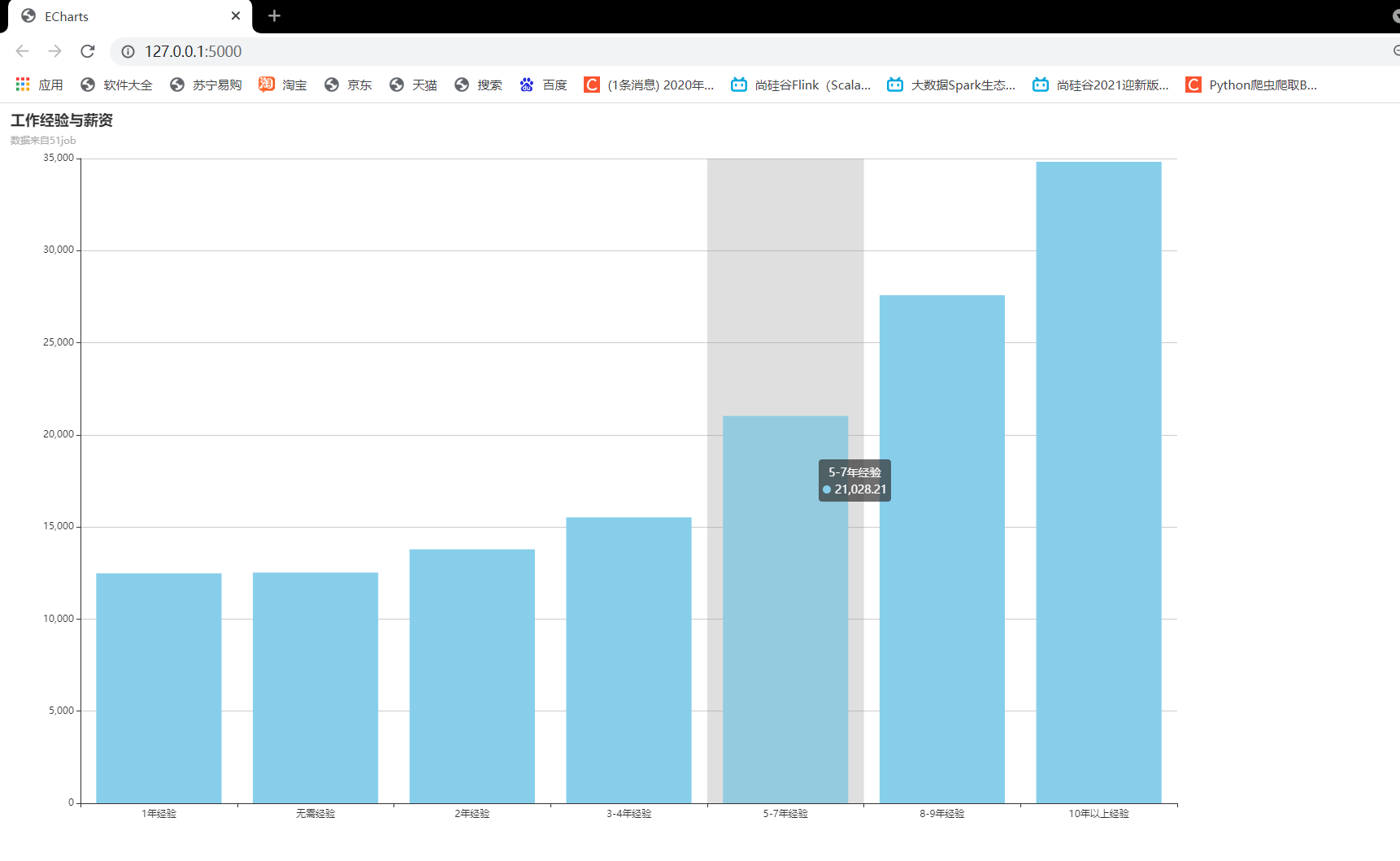
1.工作经验与薪资的情况
1和2用echarts可视化处理
3和4用的是pyecharts
之前对数据清洗时把工作经验取最大值了,所以数据清洗代码把工作经验的处理注释
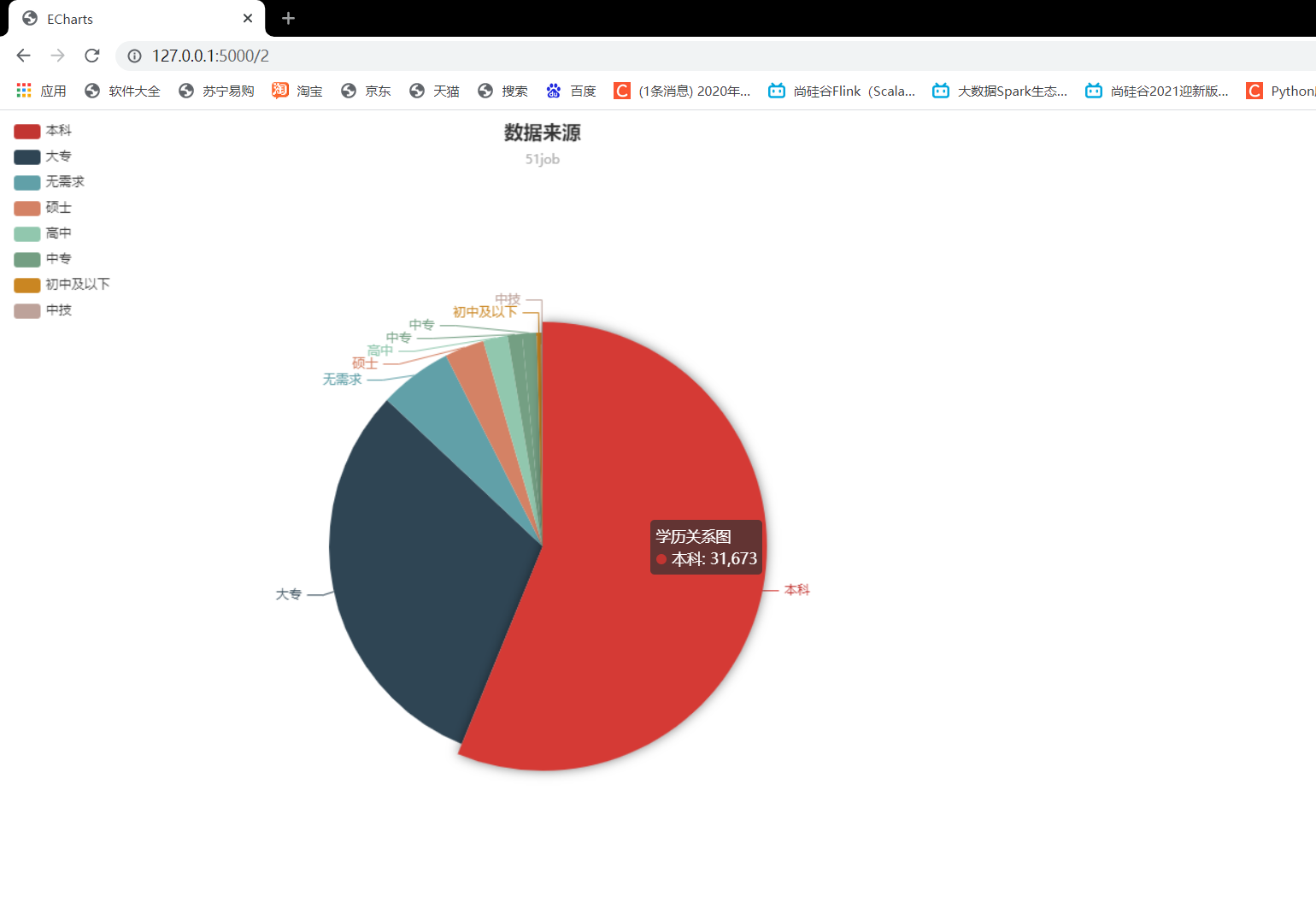
2.岗位对学历的要求关系
1和2的可视化代码
import json
from flask import Flask, render_template
import pymysql
app = Flask(__name__)
def con_mysql(sql):
# 连接
con = pymysql.connect(host='localhost', user='root', password='123456', database='spark', charset='utf8')
# 游标
cursor = con.cursor()
# 执行sql
cursor.execute(sql)
# 获取结果
result = cursor.fetchall()
return result
def extract_all(result):
nianFen = []
chanLiang = []
for i in result:
nianFen.append(i[0])
chanLiang.append(float(i[1]))
return (nianFen, chanLiang)
工作经验
@app.route("/")
def hello_world():
# sql
sql = "SELECT job_exp,TRUNCATE(avg(job_price),2) as salary FROM scrapy_job_copy1 GROUP BY job_exp having job_exp like'%经验' ORDER BY salary asc"
result = con_mysql(sql)
list = extract_all(result)
print(list)
return render_template("req2-2.html", nianFen=list[0], chanLiang=list[1])
学历关系
@app.route('/2')
def get_data():
sql = "select count(job_edu) as cnt from scrapy_job_copy1 GROUP BY job_edu ORDER BY cnt asc"
result = con_mysql(sql)
cnt = []
for i in result:
cnt.append(i[0])
print(result)
return render_template("req3.html", cnt=cnt)
@app.route("/1")
def hello_world():
# sql
sql = "select job_edu,count(job_edu)as cnt from scrapy_job_copy1 GROUP BY job_edu ORDER BY cnt asc"
result = con_mysql(sql)
list = extract_all(result)
print(list)
return render_template("req2.html", nianFen=list[0], chanLiang=list[1])
if __name__ == '__main__':
app.run()
需求1,2运行效果
3.公司福利词云图
需要将字段job_well 例如:[五险一金 餐饮补贴 通讯补贴 绩效奖金 定期体检]
进行wordCount处理 —–> (五险一金,200)。
创建一个结果表,create table job_well( job_well varchar(20) , cnt int)
Spark代码
package job
import org.apache.spark.sql.{SaveMode, SparkSession}
import java.util.Properties
object Job_well {
def main(args: Array[String]): Unit = {
// todo 福利词云图
//session
val spark = SparkSession.builder()
.appName("51job")
.master("local[*]")
.getOrCreate()
// mysql连接
val properties = new Properties()
properties.setProperty("user", "root")
properties.setProperty("password", "123456")
// 读取mysql数据
//隐式转换
import spark.implicits._
//source
val dataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/spark?serverTimezone=UTC", "scrapy_job_copy1", properties)
dataFrame.distinct().createTempView("job")
val dataSql = spark.sql(""" SELECT job_well from job """).rdd
val value = dataSql.flatMap {
row => {
// 成都-武侯区
val strings = row.toString().replaceAll("[\\[\\]]", "").split(" ")
strings
}
}
val result = value.map((_, 1)).reduceByKey(_ + _)
//result.foreach(println)
val frame = result.toDF("job_well", "cnt")
//sink
frame.write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://localhost:3306/spark?serverTimezone=UTC", "job_well", properties)
//资源释放
spark.close()
}
}
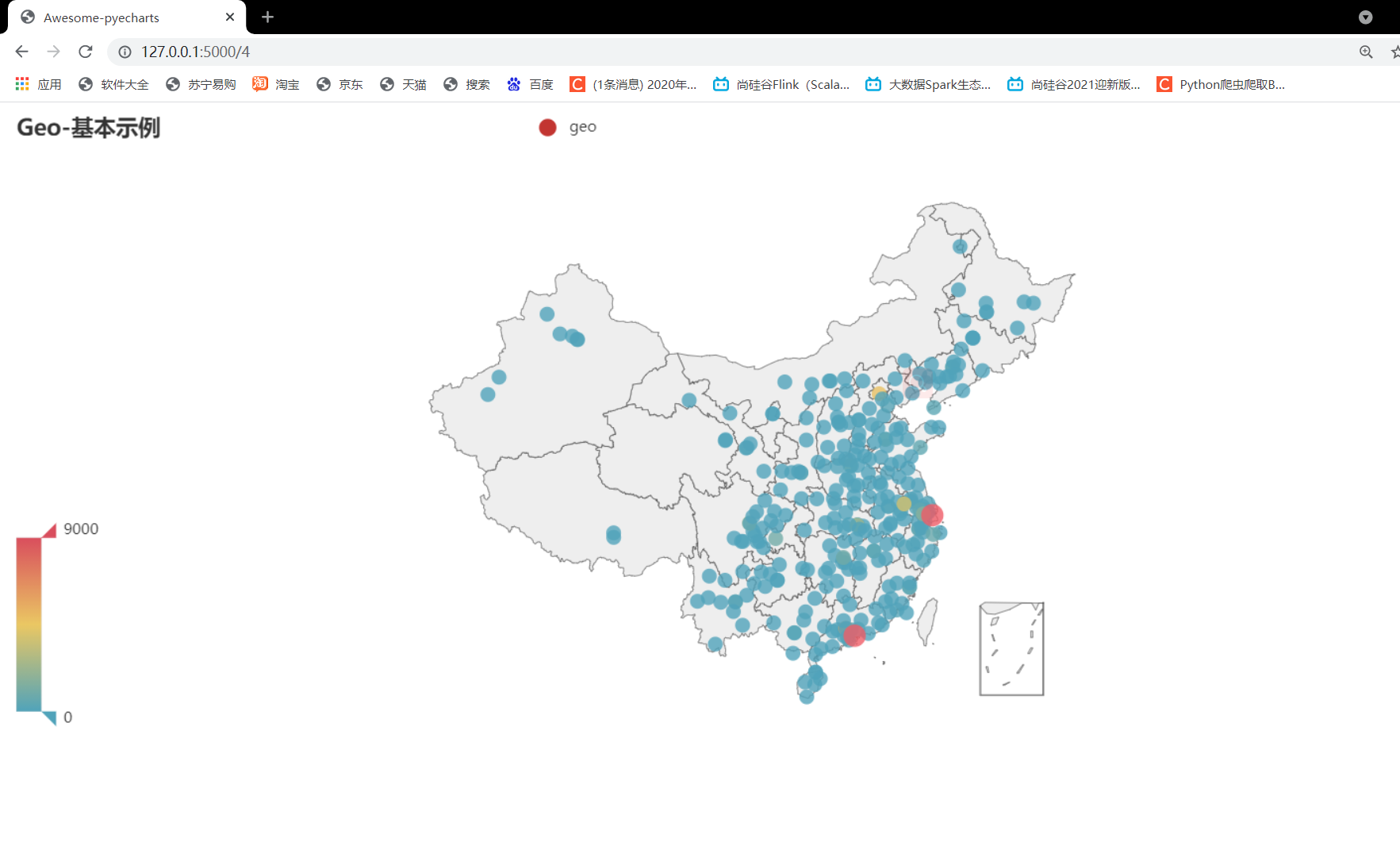
4.大数据工作城市分布
需要将字段job_place 例如:乌鲁木齐-天山区 —> 乌鲁木齐 在进行分组聚合
采用spark 得到数据,存入mysql在进行可视化
job_place.scala
import org.apache.spark.sql.{SaveMode, SparkSession}
import java.util.Properties
object Job_place {
def main(args: Array[String]): Unit = {
// todo 对地区字段进行切分聚合
//session
val spark = SparkSession.builder()
.appName("51job")
.master("local[*]")
.getOrCreate()
// mysql连接
val properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
// 读取mysql数据
//隐式转换
import spark.implicits._
//source
val dataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/spark?serverTimezone=UTC", "scrapy_job", properties)
dataFrame.createTempView("job")
val dataSql = spark.sql(""" SELECT job_place from job """).rdd
val value = dataSql.flatMap{
row => {
// 成都-武侯区
val strings = row.toString()
.replaceAll("[\\[\\]]","")
.split("\\-.+$")
strings
}
}
val result = value.map((_, 1)).reduceByKey(_ + _)
//result.foreach(println)
val frame = result.toDF("job_place", "cnt")
//sink
frame.write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://localhost:3306/spark?serverTimezone=UTC", "job_place", properties)
//资源释放
spark.close()
}
}
python数据可视化,这里采用的式pyecharts
visual.py
import re
from flask import Flask, render_template
import pymysql
from pyecharts import options as opts
from pyecharts.charts import Geo
from pyecharts.charts import WordCloud
import jieba
import collections
app = Flask(__name__)
连接mysql 输入查询语句获得结果集
def init_mysql(sql):
con = pymysql.connect(host="localhost", user="root", password="123456", database="spark", charset="utf8", port=3306)
cursor = con.cursor()
cursor.execute(sql)
result = cursor.fetchall()
arr = []
for i in result:
# a = (re.findall("^..",i[0]))
a = re.split("\-.+$", i[0])
b = i[1]
arr.append((a[0], b))
return arr
@app.route("/4")
def req14():
sql = """SELECT * FROM job_place """
result = init_mysql(sql)
print(result)
c = (
Geo()
.add_schema(maptype="china")
.add("geo", result)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
visualmap_opts=opts.VisualMapOpts(),
title_opts=opts.TitleOpts(title="Geo-基本示例"),
)
)
c.render("./job51/templates/大数据工作城市分布.html")
return render_template("大数据工作城市分布.html")
@app.route("/3")
def req3():
sql = """SELECT * FROM job_well """
result = init_mysql(sql)
print(result)
wc = WordCloud()
wc.add(series_name="福利词云图", data_pair=result)
wc.render_notebook()
wc.render("./job51/templates/福利词云图.html")
return render_template("福利词云图.html")
if __name__ == '__main__':
app.run()
这里运行时会报一个找不到 字段job_place’黔东南’的错,所以把这些都干掉,有点小麻烦。
delete from job_place
where job_place='燕郊开发区' or '黔东南' or '怒江' or '雄安新区' or '普洱' or '黔南' or '延边'
需求3,4运行效果
第一次运行后把c.render(“./job51/templates/大数据工作城市分布.html”)注释掉
因为不会传参,只能在html网页中把最大值手动传入,
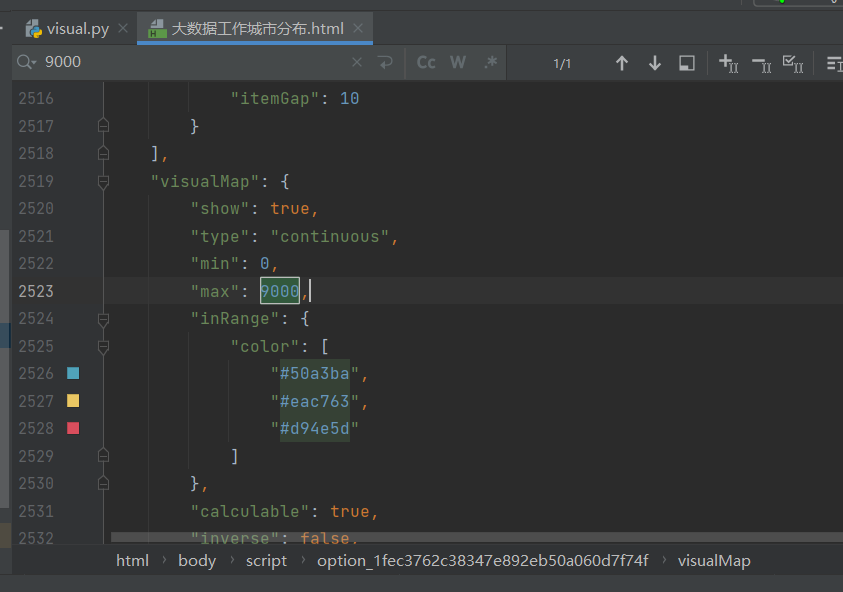

三。总结
本人是大二大专生,第一次发博客,希望个位程序猿多多指点。这篇博客也是参考了博客上的很多资料,项目加博客也码了3天,不断挣扎出来。最后祝个位能早日拿到offer。
作者:loding…
来源:CSDN
版权声明:本文为博主原创文章,转载请附上博文链接!
Original: https://blog.csdn.net/qq_54219755/article/details/118968677
Author: loding…
Title: Scrapy爬取51job
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/746555/
转载文章受原作者版权保护。转载请注明原作者出处!