

echarts-数据可视化大屏展示
python-pandas-echarts-flask
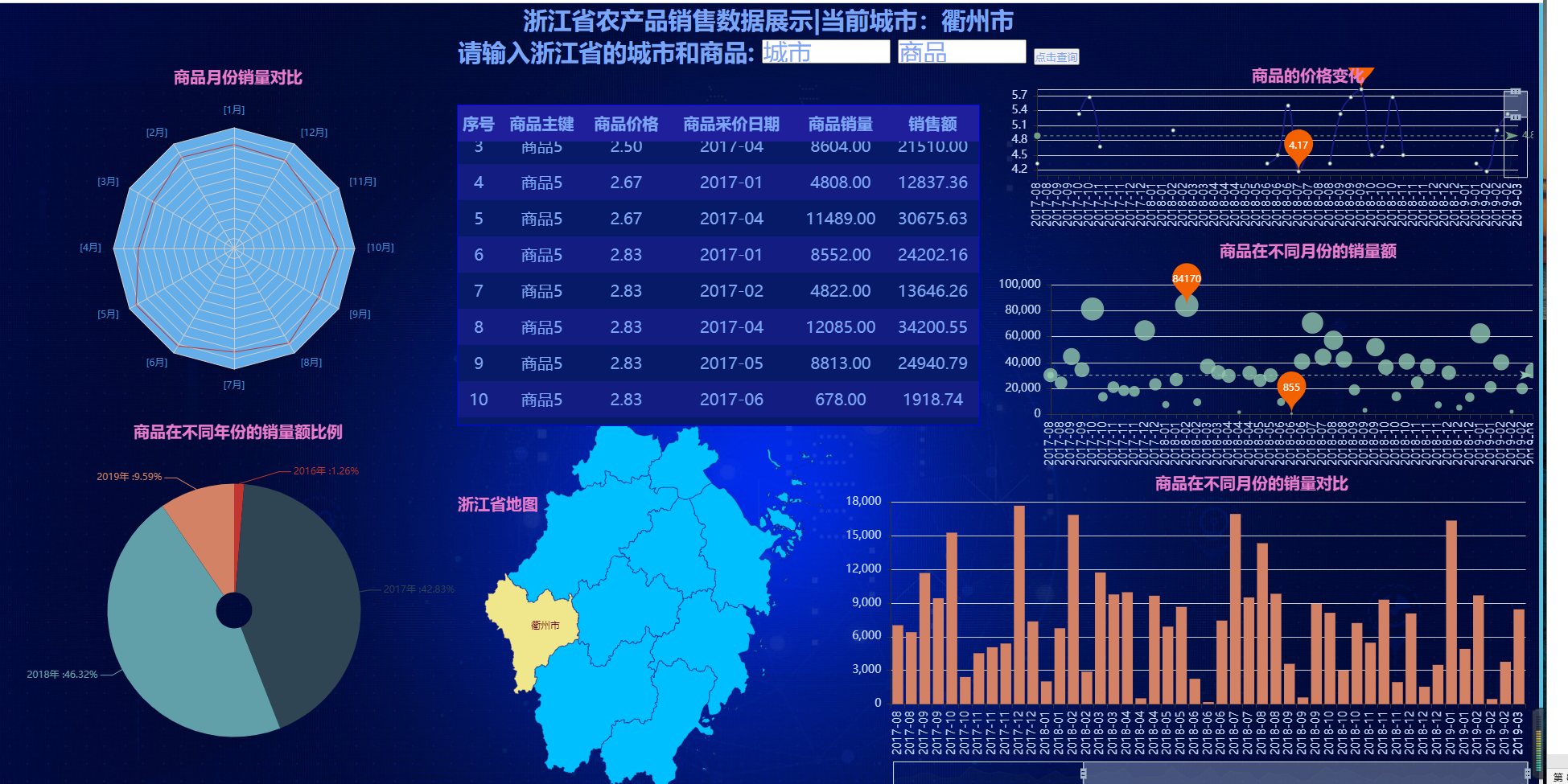

新手入门,还请指教。
文章目录
关注公众号: Time木
回复:浙江省农产品数据可视化
可获取所有数据源码文件等
若需要课设论文(6000字29页)可点击以下链接
大数据可视化大屏展示-源码,数据,文件,课设论文一次性全部打包
; 1 数据预处理
此部分使用jupyter
2.1.1导入包pandas包
import pandas as pd
2.1.2读取文件
(1)使用pandas读取导入6个数据文件。
data_1 = pd.read_csv('data\cata_6008_1.csv')
data_2 = pd.read_csv('data\cata_6008_2.csv')
data_3 = pd.read_csv('data\cata_6008_3.csv')
data_4 = pd.read_csv('data\cata_6008_4.csv')
data_5 = pd.read_csv('data\cata_6008_5.csv')
data_6 = pd.read_csv('data\cata_6008_6.csv')
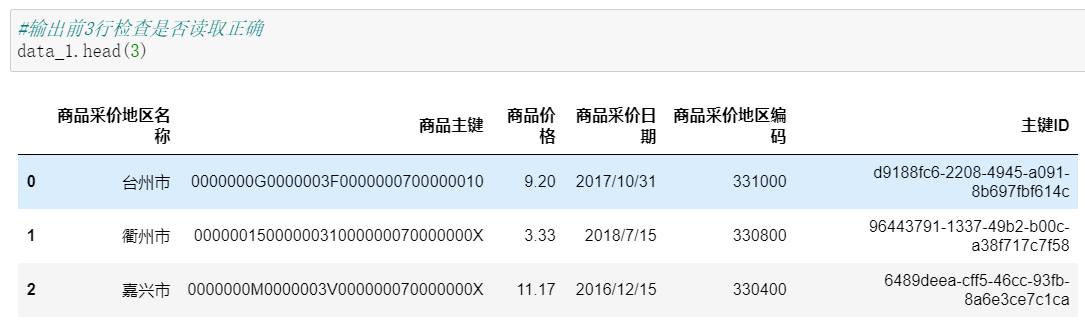
(2)查看数据导入是否正确,输出前三行。
输出前3行检查是否读取正确
data_1.head(3)
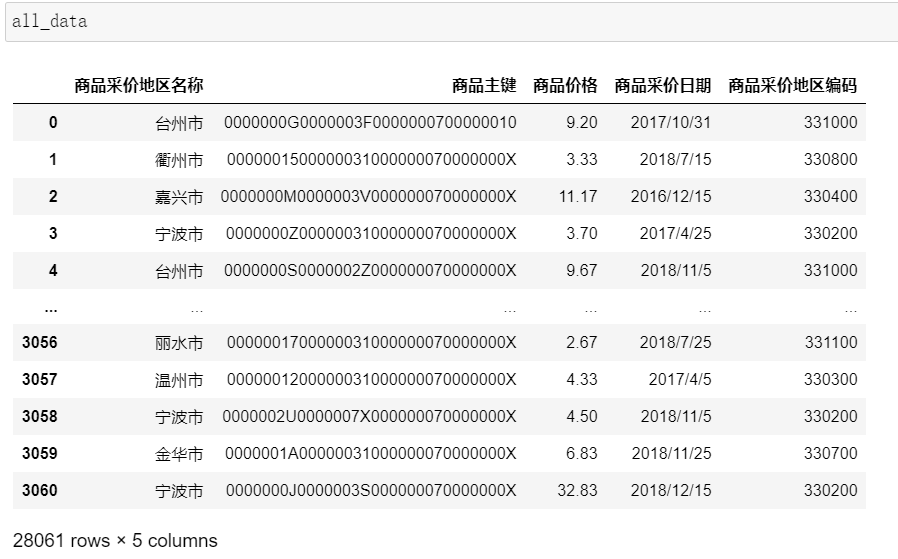
2.1.3删除每一个文件里的主键ID列,1且合并6个文件。
用iloc获取所有行,去除最后一列;并使用concat合并6个文件。
思想:用pandas的concat函数将六个表连接起来,并使用iloc()切去主键ID列,即可获取所有行非主键ID列。
all_data = pd.concat((data_1.iloc[:, 0:-1],data_2.iloc[:, 0:-1],data_3.iloc[:, 0:-1],
data_4.iloc[:, 0:-1],data_5.iloc[:, 0:-1],data_6.iloc[:, 0:-1]))
all_data
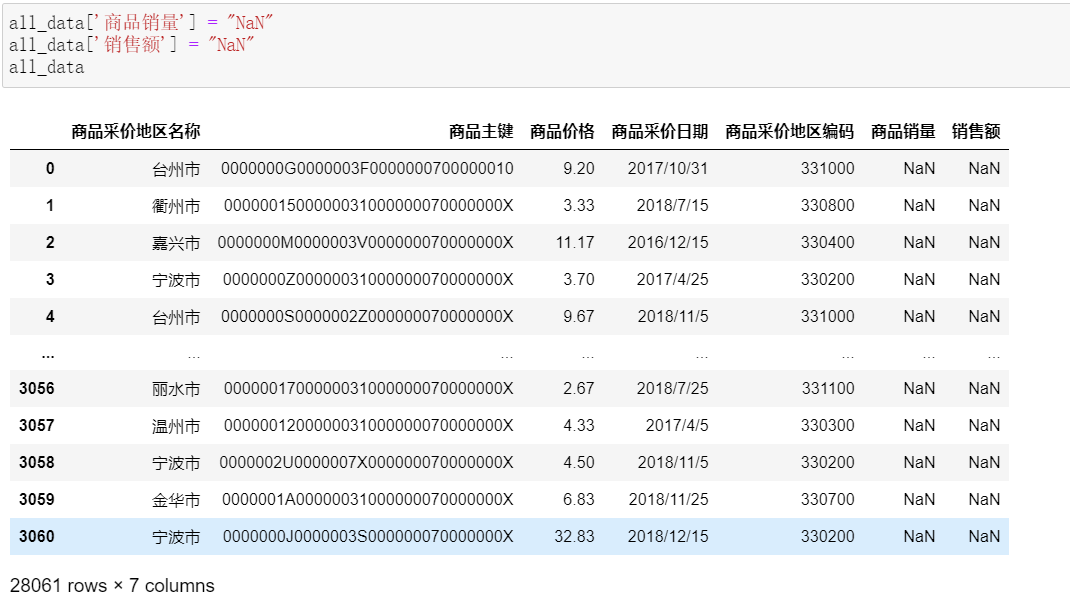
2.1.4在每个文件里创建商品销量和销售额两列, 即增加两列”商品销量”和”销售额”,并可先设值为NaN。
直接将空值赋给列”商品销量”和”销售额”列,即可增加两列。
all_data['商品销量'] = "NaN"
all_data['销售额'] = "NaN"
all_data
2.1.5删除所有采价地为浙江省的数据行。
思想:挑选非浙江省的数据,赋给新df
(1)查看浙江省数据,使用isin()函数挑选地区为浙江省的数据。
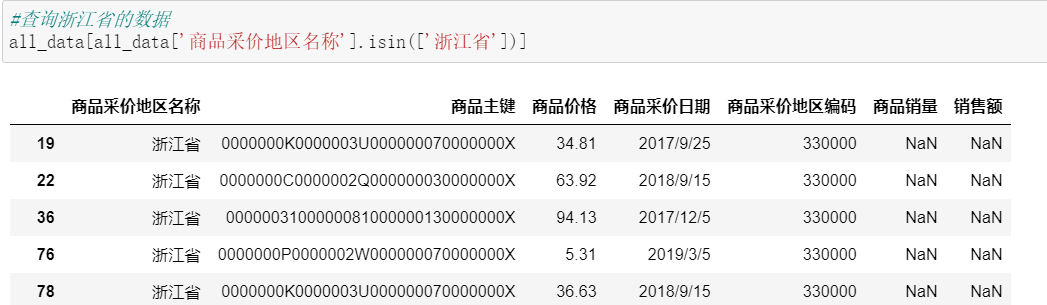
all_data=all_data[~all_data['商品采价地区名称'].isin(['浙江省'])]
all_data[all_data['商品采价地区名称'].isin(['浙江省'])]
(2)使用isin()函数并配合”~”挑选非浙江省数据并存为all_data,
已无浙江省数据
2.1.6填充”商品销量”和”销售额”列。
思想:判断数据文件整合后的长度,假设长度为n,以这个长度数据为基准,采用python里的随机数生成方法,生成n个数据,这n个数据作为”商品销量”列的数据。”销售额”列的数据为商品价格和商品销量列的乘积。
(1)查看所有行,即用shape查看形状,可以看到有25641行。
all_data.shape

引用numpy包的random方法来生成随机数并存为列表
import numpy as np
indata= np.random.randint(0,10000,25641)
indata

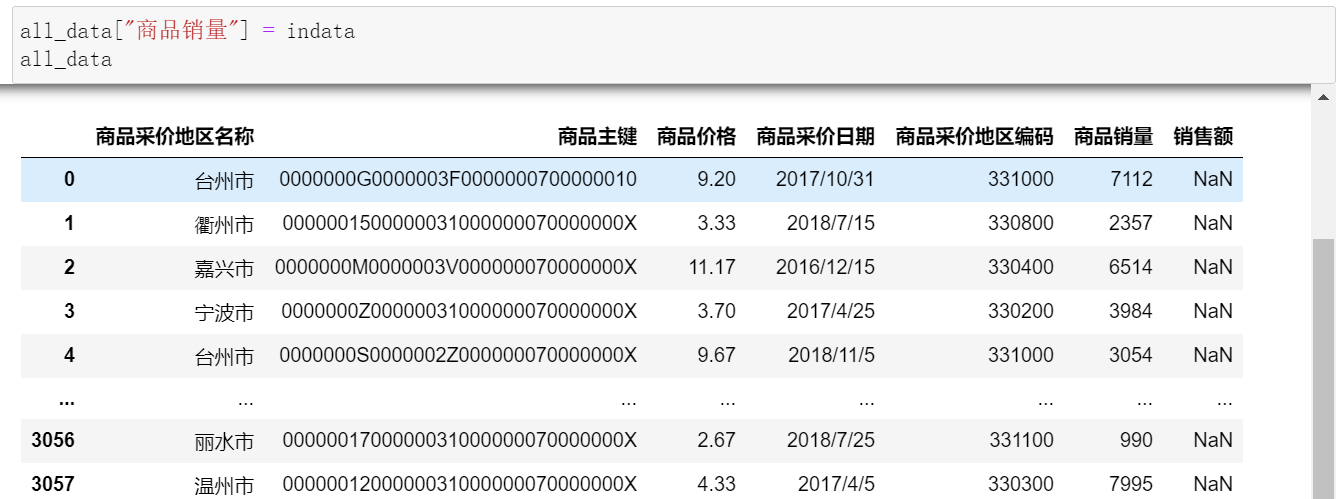
(2)赋值并查看所有数据,商品销量已经被随机数数组填充。
all_data["商品销量"] = indata
all_data
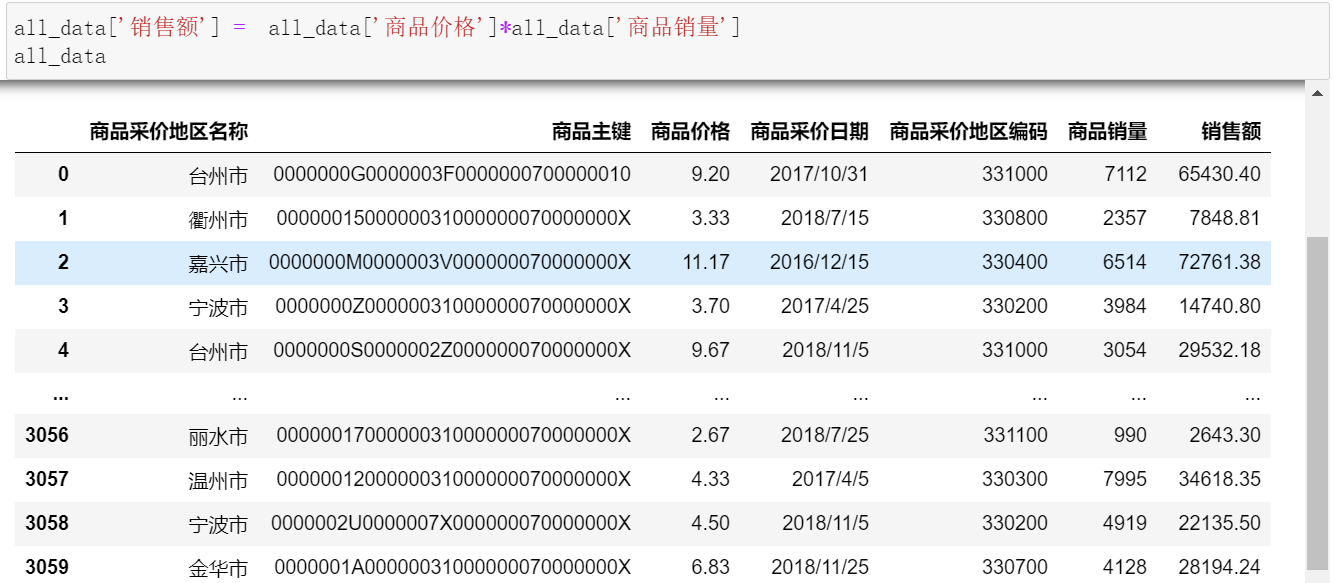
(3)直接将价格,销量两列相乘即可得到销售额的值。
all_data['销售额'] = all_data['商品价格']*all_data['商品销量']
all_data
2.1.7确定一共有多少个市以及多少种商品,将每个商品代码对应一个名称:商品1,商品2,商品3 ……,”商品”二字后面数字与set完成后的商品个数对应,使用set统计市并查看多少市。
思想:可以通过python中set方法来实现,商品代号与商品主键需用到字典,然后进行替换。
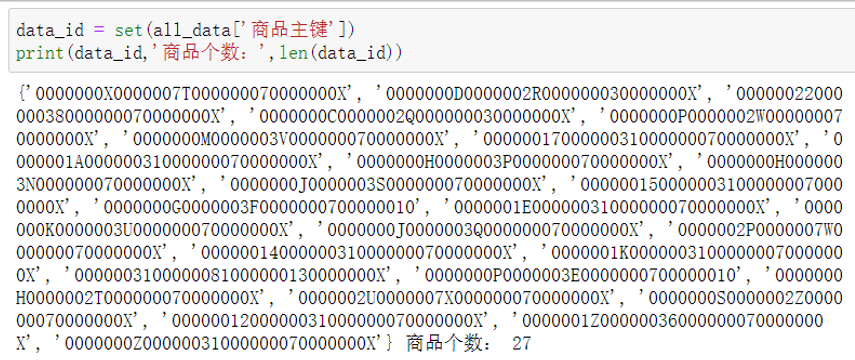
(1)查看商品主键及个数
data_id = set(all_data['商品主键'])
print(data_id,'商品个数:',len(data_id))
(2)查看城市及个数
data_shi = set(all_data['商品采价地区名称'])
print(data_shi,'地区个数:',len(data_shi))

(3)使用for循环将数字与商品进行配对并存入列表。
goods = []
for i in range(1,28):
goods.append('商品'+str(i))
print(goods)

(4)将商品主键和新商品主键进行字典配对以便后面替换操作。
data_id_l = list(data_id)
new_dict = {}
for i in range(0,27):
new_dict[data_id_l[i]] = goods[i]
new_dict

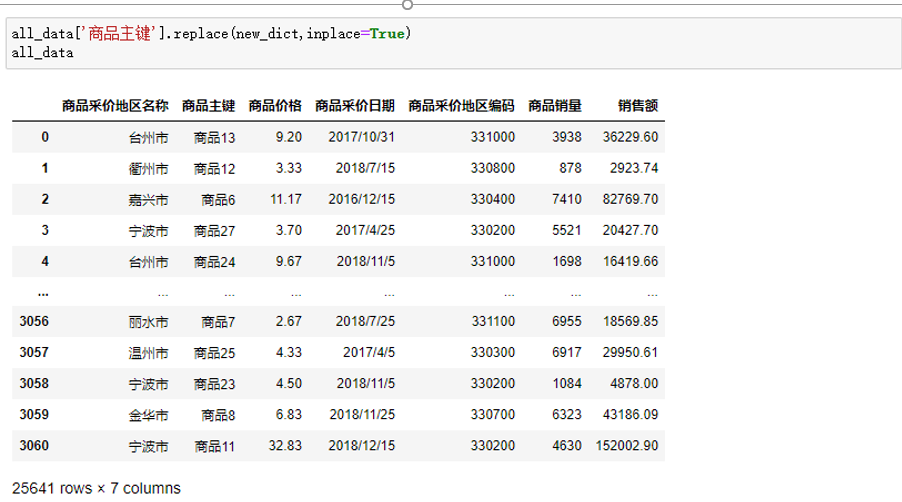
(5)使用replace()方法进行替换, 索引不变。
all_data['商品主键'].replace(new_dict,inplace=True)
all_data
2.1.8因为涉及展示商品在不同时间的销售情况,统计时间以月为单位,检查每一种商品在数据集里的采价时间是否有月份重合的,如有,则修改这种商品的销量。最终的结果是商品销量是数据集中这种商品在同一月份销量的总和,对应的销售额也应是同一月份销售额的总和。
思想:先将”日”(%d)删去,然后若”商品销量”和”销售额”以外的属性相同,则将”商品销量”和”销售额”数值相加。
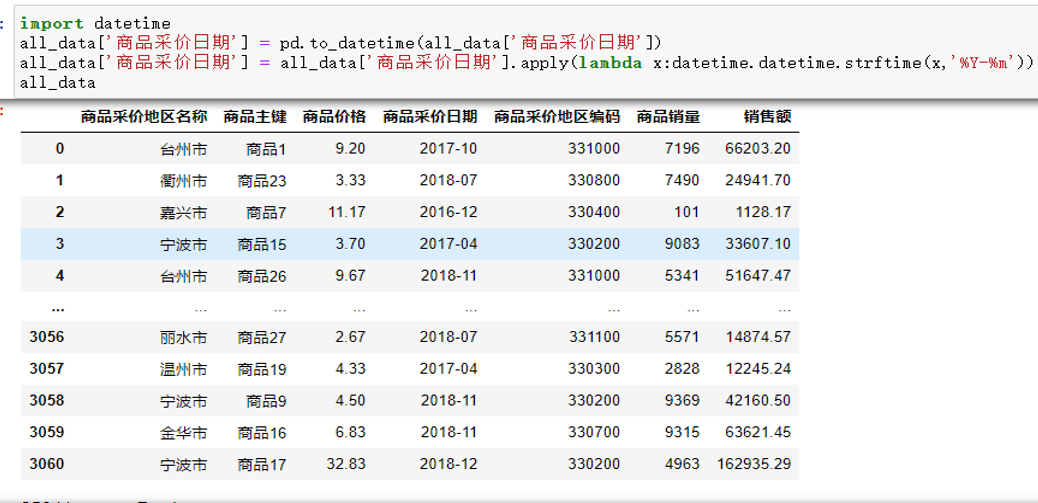
(1)先引入datetime包将日期格式进行日期格式化,在利用apply()将所有日期进行只保留年和月的格式。以方便后面drop()和sum()的使用。
import datetime
all_data['商品采价日期'] = pd.to_datetime(all_data['商品采价日期'])
all_data['商品采价日期'] = all_data['商品采价日期'].apply(lambda x:datetime.datetime.strftime(x,'%Y-%m'))
all_data
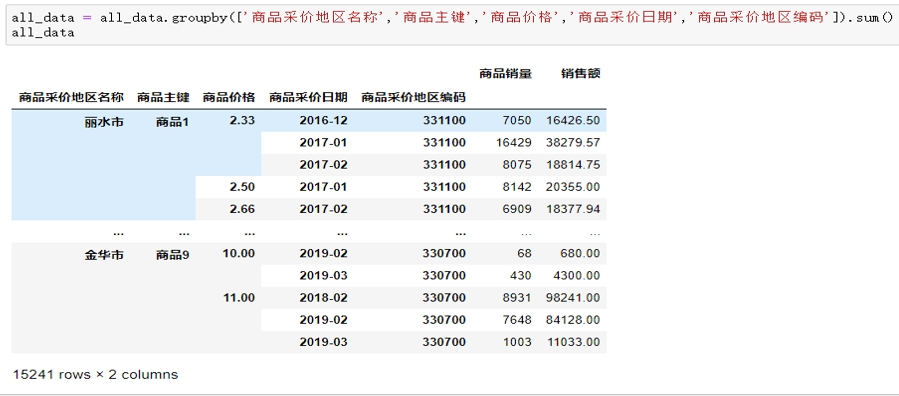
(2)将dropby()和sum()函数配合使用,当除了”商品销量”和”销售额”以外相同则将”商品销量”和”销售额”数值相加。
2.1.9将所有数据以采价地区区分,每个地区单独输出为一个txt或csv格式文件,文件内每一行各个属性间以’\t’作为分隔符
思想:根据城市为索引将数据进行分类,且输出为文本
(1)在上一步drop()的处理中,因为没设参数as_index=False,所以会自动将”商品采价地区”设为索引。
(2)先定义一个城市列表,再通过for循环在城市列表里面遍历将一个城市的数据赋给一个df并将df以文本形式输出到本地,且将文本命名为城市名称。
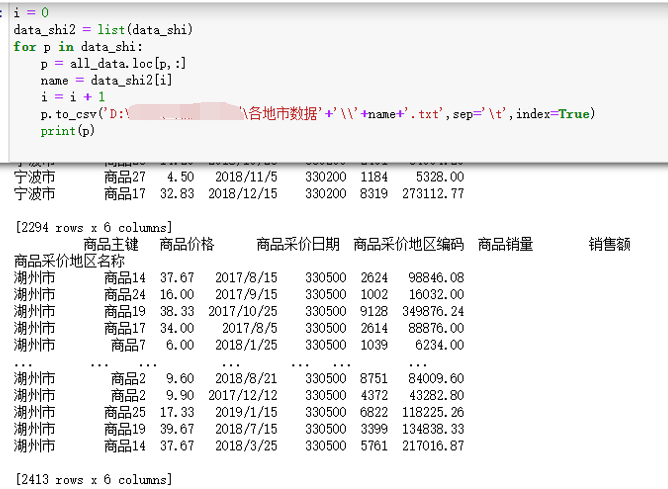
i = 0
data_shi2 = list(data_shi)
for p in data_shi:
p = all_data.loc[p,:]
name = data_shi2[i]
i = i + 1
p.to_csv('D:\(自己地址)\各地数据'+'\\'+name+'.txt',sep='\t',index=True)
print(p)
2可视化部分
此部分使用pycharm
2.1query.py
from flask import Flask, request, render_template
from getdata import get_data
app = Flask(__name__)
@app.route('/query', methods=['GET', 'POST'])
def query():
if request.method == 'POST':
urban = request.form.get('urban')
goods = request.form.get('goods')
dict_return = get_data(urban, goods)
return render_template('query.html', dict_return = dict_return)
else:
dict_return = get_data('杭州市','商品1')
return render_template('query.html', dict_return = dict_return)
if __name__ == '__main__':
app.run(port=4500,debug = True)
2.2get_data模块
import datetime
import pandas as pd
def read_urban(urban):
urban = pd.read_csv('data/' + urban + '.txt', sep="\t")
return urban
def get_data(urban, goods):
dict_return = {}
dict_return['urban'] = urban
dict_return['city_highlight'] = [{"name": urban, "selected": "true"}]
data_1 = read_urban(urban)
data_2 = data_1[data_1['商品主键'] == goods]
data_goods = data_2.sort_values(by='商品采价日期')
time_x = data_goods['商品采价日期']
sale_n_y = data_goods['商品销量']
price_y = data_goods['商品价格']
all_price_y = data_goods['销售额']
data_list = data_2.copy(deep=True)
num = []
n = data_list.shape[0]
for i in range(1, n):
num.append(str(i))
dict_return['diff_list'] = [ {'Ranking': item[0], '商品主键': item[1], '商品价格': item[2],
'商品采价日期': item[3], '商品销量': item[4],'销售额': item[5]}
for item in list(zip(num, data_list['商品主键'], data_list['商品价格'],
data_list['商品采价日期'], data_list['商品销量'],data_list['销售额']))]
print(dict_return['diff_list'])
data_year = data_goods.copy(deep=True)
data_year['商品采价日期'] = pd.to_datetime(data_year['商品采价日期'])
data_year['商品采价日期'] = data_year['商品采价日期'].apply(lambda x:datetime.datetime.strftime(x,'%Y'))
data_year = data_year.groupby([ '商品采价日期'],as_index=False).sum()
sale_Y_x = data_year['商品采价日期']
sale_Y_y = data_year['销售额']
dict_return['diff'] = [{"name": item[0], "value": item[1]} for item in
list(zip(sale_Y_x, sale_Y_y))]
data_Month = data_goods.copy(deep=True)
data_Month['商品采价日期'] = pd.to_datetime(data_Month['商品采价日期'])
data_Month['商品采价日期'] = data_Month['商品采价日期'].apply(lambda x: datetime.datetime.strftime(x, '%m'))
data_Month = data_Month.groupby(['商品采价日期'], as_index=False).sum()
sale_M_y = data_Month['销售额']
money = []
for item in sale_M_y:
money.append(int(item))
dict_return['diff_l'] = {"name": '月份销售总额', "value": money}
time_x = list(time_x)
sale_n_y = list(sale_n_y)
price_y = list(price_y)
all_price_y = list(all_price_y)
dict_return['time_x'] = time_x
dict_return['sale_n_y'] = sale_n_y
dict_return['price_y'] = price_y
dict_return['all_price_y'] = all_price_y
return dict_return
2.3html
代码过长,公众号可获取。
3网页展示方法
运行后,浏览器输入地址:http://127.0.0.1:4500/query
关注公众号: Time木
回复:浙江省农产品数据可视化
可获取所有数据源码文件等
若需要课设论文(6000字29页)包含更详细讲解可点击以下链接
大数据可视化大屏展示-源码,数据,文件,课设论文一次性全部打包
Original: https://blog.csdn.net/qq_43374681/article/details/118226708
Author: Time木0101
Title: echarts-python数据可视化大屏展示
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/746096/
转载文章受原作者版权保护。转载请注明原作者出处!