

文章目录
- python编程快速上手(持续更新中…)
* - python爬虫从入门到精通
- urllib2概述
–- python2与python3对比
- urlopen
- Request
+ - User-Agent
- 添加更多的Header信息
- urllib2默认只支持HTTP/HTTPS的GET和POST方法
+ - URL编码转换:urllib.parse.urlencode
- 模拟百度搜索
- 批量爬取百度贴吧页面数据
- 获取AJAX加载的内容(接口json)
- 有道词典翻译网站
- 处理HTTPS请求 SSL证书验证
- 关于CA(了解)
- Handler处理器 和 自定义Opener
+ - 简单的自定义opener()
- ProxyHandler处理器(代理设置)
- HTTPPasswordMgrWithDefaultRealm()
- ProxyBasicAuthHandler(代理授权验证)
- HTTPBasicAuthHandler处理器(Web客户端授权验证)
- Cookie原理
+ - Cookie应用(126邮箱)
- cookielib库 和 HTTPCookieProcessor处理器
+ - cookielib 库
- 1)获取Cookie,并保存到CookieJar()对象中
- 2. 访问网站获得cookie,并把获得的cookie保存在cookie文件中
- 3. 从文件中获取cookies,做为请求的一部分去访问
- urllib2 的异常错误处理
+ - URLError
- HTTPError
- 改进版
urllib2概述
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中抓取出来。在Python中有很多库可以用来抓取网页,我们先学习urllib2。
urllib2 是 Python2.7 自带的模块(不需要下载,导入即可使用)
urllib2 官方文档:https://docs.python.org/2/library/urllib2.html
urllib2 源码:https://hg.python.org/cpython/file/2.7/Lib/urllib2.py
python2与python3对比
在 python3 中,urllib2 被改为urllib.request
python2python3import urllib2import urllib.request,urllib.errorimport urllibimport urllib.request,urllib.error,urllib.parseimport urlparseimport urllib.parseimport urlopenimport urllib.request.urlopenimport urlencodeimport urllib.parse.urlencodeimport urllib.quoteimport urllib.request.quotecookielib.CookieJarhttp.CookieJarurllib2.Requesturllib.request.Request
urlopen
我们先来段代码:
Python2
urllib2_urlopen.py
导入urllib2 库
import urllib2
向指定的url发送请求,并返回服务器响应的类文件对象
response = urllib2.urlopen("http://www.baidu.com")
类文件对象支持 文件对象的操作方法,如read()方法读取文件全部内容,返回字符串
html = response.read()
打印字符串
print html
python3
导入urllib3 库
from urllib.request import urlopen
import urllib.request
向指定的url发送请求,并返回服务器响应的类文件对象
response = urllib.request.urlopen("http://www.baidu.com")
类文件对象支持 文件对象的操作方法,如read()方法读取文件全部内容,返回字符串
html = response.read()
打印字符串
print (html)
实际上,如果我们在浏览器上打开百度主页, 右键选择”查看源代码”,你会发现,跟我们刚才打印出来的是一模一样。也就是说,上面的4行代码就已经帮我们把百度的首页的全部代码爬了下来。
一个基本的url请求对应的python代码真的非常简单。
Request
在我们第一个例子里,urlopen()的参数就是一个url地址;
但是如果需要执行更复杂的操作,比如增加HTTP报头,必须创建一个 Request 实例来作为urlopen()的参数;而需要访问的url地址则作为 Request 实例的参数。
python2
urllib2_request.py
import urllib2
url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib2.Request("http://www.baidu.com")
Request对象作为urlopen()方法的参数,发送给服务器并接收响应
response = urllib2.urlopen(request)
html = response.read()
print html
python3
#
import urllib.request
url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request("http://www.baidu.com")
Request对象作为urlopen()方法的参数,发送给服务器并接收响应
response = urllib.request.urlopen(request)
html = response.read()
print (html)
运行结果是完全一样的:
新建Request实例,除了必须要有 url 参数之外,还可以设置另外两个参数:
data(默认空):是伴随 url 提交的数据(比如要post的数据),同时 HTTP 请求将从 “GET”方式 改为 “POST”方式。
headers(默认空):是一个字典,包含了需要发送的HTTP报头的键值对。
User-Agent
用不同的浏览器在发送请求的时候,会有不同的User-Agent头。
#urllib2_useragent.py
import urllib.request
url = "http://www.baidu.cn"
#IE 9.0 的 User-Agent,包含在 ua_header里
ua_header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
url 连同 headers,一起构造Request请求,这个请求将附带 IE9.0 浏览器的User-Agent
request = urllib.request.Request(url, headers = ua_header)
向服务器发送这个请求
response = urllib.request.urlopen(request)
html = response.read()
print (html)
添加更多的Header信息
在 HTTP Request 中加入特定的 Header,来构造一个完整的HTTP请求消息。
可以通过调用Request.add_header() 添加/修改一个特定的header 也可以通过调用Request.get_header()来查看已有的header。
添加一个特定的header
urllib2_headers.py
import urllib.request
url = "http://www.baidu.cn"
#IE 9.0 的 User-Agent
header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
request = urllib.request.Request(url, headers = header)
#也可以通过调用Request.add_header() 添加/修改一个特定的header
request.add_header("Connection", "keep-alive")
也可以通过调用Request.get_header()来查看header信息
request.get_header(header_name="Connection")
response = urllib.request.urlopen(request)
print (response.code) #可以查看响应状态码
html = response.read()
print (html)
随机添加/修改User-Agent
urllib2_add_headers.py
import urllib.request
import random
url = "http://www.baidu.cn"
ua_list = [
"Mozilla/5.0 (Windows NT 6.1; ) Apple.... ",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0)... ",
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X.... ",
"Mozilla/5.0 (Macintosh; Intel Mac OS... "
]
user_agent = random.choice(ua_list)
request = urllib.request.Request(url)
#也可以通过调用Request.add_header() 添加/修改一个特定的header
request.add_header("User-Agent", user_agent)
get_header()的字符串参数,第一个字母大写,后面的全部小写
request.get_header("User-agent")
print (request)
response = urllib.request.urlopen(request)
html = response.read()
print (html)
urllib2默认只支持HTTP/HTTPS的GET和POST方法
URL编码转换:urllib.parse.urlencode
编码工作使用urllib的函数,帮我们将这样的键值对,转换成这样的字符串,解码 import urllib.request.quote
import urllib.parse
import urllib.request
word = {"wd" : "你好"}
通过urllib.urlencode()方法,将字典键值对按URL编码转换,从而能被web服务器接受。
urllib.parse.urlencode(word)
print(urllib.parse.urlencode(word))
通过urllib.unquote()方法,把 URL编码字符串,转换回原先字符串。
print (urllib.parse.unquote("wd=%E4%BD%A0%E5%A5%BD"))
一般HTTP请求提交数据,需要编码成 URL编码格式,然后做为url的一部分,或者作为参数传到Request对象中。
获取方式
GET请求一般用于我们向服务器获取数据,比如说,我们用百度搜索:https://www.baidu.com/s?wd=上海
浏览器的url会跳转成如图所示:
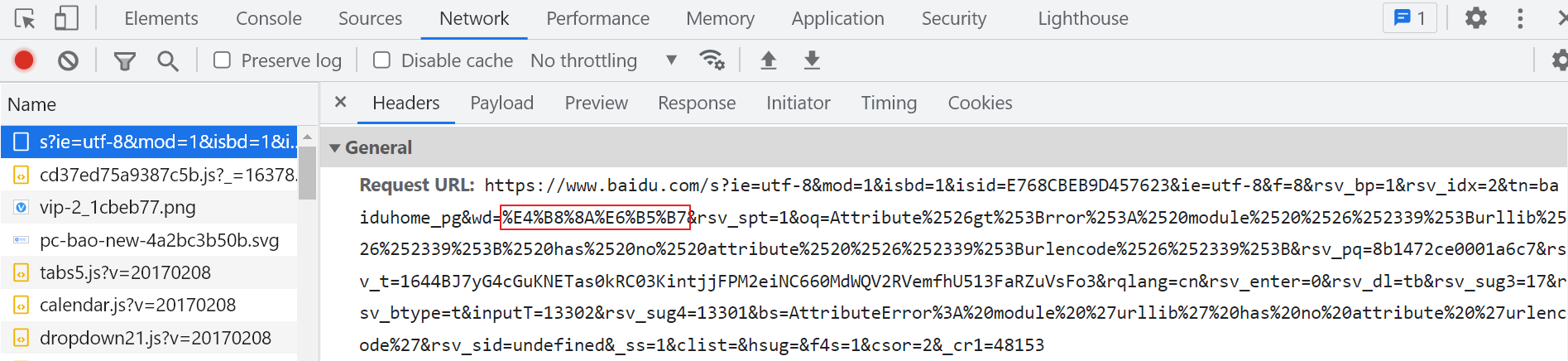

在其中我们可以看到在请求部分里, 之后出现一个长长的字符串,其中就包含我们要查询的关键词传智播客,于是我们可以尝试用默认的Get方式来发送请求。http://www.baidu.com/s?
模拟百度搜索
import urllib.parse #负责url编码处理
import urllib.request
url = "http://www.baidu.com/s"
word = {"wd":"上海"}
word = urllib.parse.urlencode(word) #转换成url编码格式(字符串)
newurl = url + "?" + word # url首个分隔符就是 ?
headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}
request = urllib.request.Request(newurl, headers=headers)
response = urllib.request.urlopen(request)
html = response.read()
with open('百度搜索.html', 'wb') as f:
f.write(html)
print (str)
批量爬取百度贴吧页面数据
输入一个百度贴吧的地址,以及起始页和结束页,就能将所有的网页源码下载并保存到本地。
比如百度贴吧LOL吧:
第一页:http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=0
第二页: http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=50
第三页: http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=100
发现规律了吧,贴吧中每个页面不同之处,就是url最后的pn的值,其余的都是一样的,我们可以抓住这个规律。
1.先写一个main,提示用户输入要爬取的贴吧名,并用urllib.urlencode()进行转码,然后组合url,假设是lol吧,那么组合后的url就是:http://tieba.baidu.com/f?kw=lol
模拟 main 函数
if __name__ == "__main__":
kw = input("请输入需要爬取的百度贴吧:")
# 输入起始页和终止页,str转成int类型
beginPage = int(input("请输入起始页:"))
endPage = int(input("请输入终止页:"))
url = "http://tieba.baidu.com/f?"
key = urllib.parse.urlencode({"kw" : kw})
# 组合后的url示例:http://tieba.baidu.com/f?kw=lol
url = url + key
tiebaSpider(url, beginPage, endPage)
2.接下来,我们写一个百度贴吧爬虫接口,我们需要传递3个参数给这个接口, 一个是main里组合的url地址,以及起始页码和终止页码,表示要爬取页码的范围。
def tiebaSpider(url, beginPage, endPage):
"""
作用:负责处理url,分配每个url去发送请求
url:需要处理的第一个url
beginPage: 爬虫执行的起始页面
endPage: 爬虫执行的截止页面
"""
for page in range(beginPage, endPage + 1):
pn = (page - 1) * 50
filename = "第" + str(page) + "页.html"
# 组合为完整的 url,并且pn值每次增加50
fullurl = url + "&pn=" + str(pn)
#print fullurl
# 调用loadPage()发送请求获取HTML页面
html = loadPage(fullurl, filename)
# 将获取到的HTML页面写入本地磁盘文件
writeFile(html, filename)
3.我们已经之前写出一个爬取一个网页的代码。现在,我们可以将它封装成一个小函数loadPage,供我们使用。
def loadPage(url, filename):
'''
作用:根据url发送请求,获取服务器响应文件
url:需要爬取的url地址
filename: 文件名
'''
print ("正在下载" + filename)
headers = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
request = urllib.request.Request(url, headers = headers)
response = urllib.request.urlopen(request)
return response.read()
4.最后如果我们希望将爬取到了每页的信息存储在本地磁盘上,我们可以简单写一个存储文件的接口。
def tiebaSpider(url, beginPage, endPage):
"""
作用:负责处理url,分配每个url去发送请求
url:需要处理的第一个url
beginPage: 爬虫执行的起始页面
endPage: 爬虫执行的截止页面
"""
for page in range(beginPage, endPage + 1):
pn = (page - 1) * 50
filename = "第" + str(page) + "页.html"
# 组合为完整的 url,并且pn值每次增加50
fullurl = url + "&pn=" + str(pn)
#print fullurl
# 调用loadPage()发送请求获取HTML页面
html = loadPage(fullurl, filename)
# 将获取到的HTML页面写入本地磁盘文件
writeFile(html, filename)
获取AJAX加载的内容(接口json)
有些网页内容使用AJAX请求加载,这种数据无法直接对网页url进行获取。但是只要记住,AJAX请求一般返回给网页的是JSON文件,只要对AJAX请求地址进行POST或GET,就能返回JSON数据了。
如果非要从HTML页面里获取展现出来的数据,也不是不可以。但是要记住,作为一名爬虫工程师,你更需要关注的是数据的来源。
import urllib.request
import urllib.parse
url = "https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&"
headers={"User-Agent": "Mozilla...."}
变动的是这两个参数,从start开始往后显示limit个
formdata = {
'start':'0',
'limit':'10'
}
data = urllib.parse.urlencode(formdata)
request = urllib.request.Request(url + data, headers = headers)
response = urllib.request.urlopen(request)
print (response.read())
请求方式:POST
之前我们说了,Request请求对象的里有data参数,它就是用在POST里的,我们要传送的数据就是这个参数data,data是一个字典,里面要匹配键值对。
有道词典翻译网站
import urllib.request
import urllib.parse
POST请求的目标URL
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null"
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"}
formdata = {
"i":"我爱python",
"from":"AUTO",
"to":"AUTO",
"doctype":"json",
}
data = urllib.parse.urlencode(formdata).encode("utf-8")
request = urllib.request.Request(url, data = data, headers = headers)
response = urllib.request.urlopen(request)
print (response.read().decode("utf-8"))
发送POST请求时,需要了解的headers一些属性:
Content-Length: 144: 是指发送的表单数据长度为144,也就是字符个数是144个。
Content-Type: application/x-www-form-urlencoded: 表示浏览器提交 Web 表单时使用,表单数据会按照name1=value1&name2=value2键值对形式进行编码。
X-Requested-With: XMLHttpRequest:表示AJAX异步请求。
处理HTTPS请求 SSL证书验证
现在随处可见 https 开头的网站,urllib2可以为 HTTPS 请求验证SSL证书,就像web浏览器一样,如果网站的SSL证书是经过CA认证的,则能够正常访问,如:等…https://www.baidu.com/
如果SSL证书验证不通过,或者操作系统不信任服务器的安全证书,比如浏览器在访问邮乐网如:http://www.ule.com/的时候,会警告用户证书不受信任
import urllib.request
url = "https://www.ule.com"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
request = urllib.request.Request(url, headers = headers)
response = urllib.request.urlopen(request)
print (response.read())
在访问的时候则会报出SSLError:(未出现)
import urllib
import urllib.request
1. 导入Python SSL处理模块
import ssl
2. 表示忽略未经核实的SSL证书认证
context = ssl._create_unverified_context()
url = "https://www.ule.com"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
request = urllib.request.Request(url, headers = headers)
3. 在urlopen()方法里 指明添加 context 参数
response = urllib.request.urlopen(request, context = context)
print (response.read().decode("utf-8"))
关于CA(了解)
CA(Certificate Authority)是数字证书认证中心的简称,是指发放、管理、废除数字证书的受信任的第三方机构,如北京数字认证股份有限公司、上海市数字证书认证中心有限公司等…
CA的作用是检查证书持有者身份的合法性,并签发证书,以防证书被伪造或篡改,以及对证书和密钥进行管理。
现实生活中可以用身份证来证明身份, 那么在网络世界里,数字证书就是身份证。和现实生活不同的是,并不是每个上网的用户都有数字证书的,往往只有当一个人需要证明自己的身份的时候才需要用到数字证书。
普通用户一般是不需要,因为网站并不关心是谁访问了网站,现在的网站只关心流量。但是反过来,网站就需要证明自己的身份了。
比如说现在钓鱼网站很多的,比如你想访问的是www.baidu.com,但其实你访问的是www.daibu.com”,所以在提交自己的隐私信息之前需要验证一下网站的身份,要求网站出示数字证书。
一般正常的网站都会主动出示自己的数字证书,来确保客户端和网站服务器之间的通信数据是加密安全的。
Handler处理器 和 自定义Opener
opener是 urllib2.OpenerDirector 的实例,我们之前一直都在使用的urlopen,它是一个特殊的opener(也就是模块帮我们构建好的)。
但是基本的urlopen()方法不支持代理、cookie等其他的HTTP/HTTPS高级功能。所以要支持这些功能:
使用相关的 Handler处理器 来创建特定功能的处理器对象;
然后通过 urllib2.build_opener()方法使用这些处理器对象,创建自定义opener对象;
使用自定义的opener对象,调用open()方法发送请求。
如果程序里所有的请求都使用自定义的opener,可以使用urllib2.install_opener() 将自定义的 opener 对象 定义为 全局opener,表示如果之后凡是调用urlopen,都将使用这个opener(根据自己的需求来选择)
简单的自定义opener()
import urllib.request
构建一个HTTPHandler 处理器对象,支持处理HTTP请求
http_handler = urllib.request.HTTPHandler()
构建一个HTTPHandler 处理器对象,支持处理HTTPS请求
http_handler = urllib2.HTTPSHandler()
调用urllib2.build_opener()方法,创建支持处理HTTP请求的opener对象
opener = urllib.request.build_opener(http_handler)
构建 Request请求
request = urllib.request.Request("http://www.baidu.com/")
调用自定义opener对象的open()方法,发送request请求
response = opener.open(request)
获取服务器响应内容
print (response.read())
这种方式发送请求得到的结果,和使用urllib2.urlopen()发送HTTP/HTTPS请求得到的结果是一样的。
如果在 HTTPHandler()增加 debuglevel=1参数,还会将 Debug Log 打开,这样程序在执行的时候,会把收包和发包的报头在屏幕上自动打印出来,方便调试,有时可以省去抓包的工作。
仅需要修改的代码部分:
构建一个HTTPHandler 处理器对象,支持处理HTTP请求,同时开启Debug Log,debuglevel 值默认 0
http_handler = urllib.request.HTTPHandler(debuglevel=1)
构建一个HTTPHSandler 处理器对象,支持处理HTTPS请求,同时开启Debug Log,debuglevel 值默认 0
https_handler = urllib.request.HTTPSHandler(debuglevel=1)
ProxyHandler处理器(代理设置)
使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的。
很多网站会检测某一段时间某个IP的访问次数(通过流量统计,系统日志等),如果访问次数多的不像正常人,它会禁止这个IP的访问。
所以我们可以设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
urllib2中通过ProxyHandler来设置使用代理服务器,下面代码说明如何使用自定义opener来使用代理:
import urllib.request
构建了两个代理Handler,一个有代理IP,一个没有代理IP
使用时更换IP
httpproxy_handler = urllib.request.ProxyHandler({"http" : "103.216.103.25"})
nullproxy_handler = urllib.request.ProxyHandler({})
proxySwitch = True #定义一个代理开关
通过 urllib2.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
根据代理开关是否打开,使用不同的代理模式
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler)
request = urllib.request.Request("http://www.baidu.com/")
1. 如果这么写,只有使用opener.open()方法发送请求才使用自定义的代理,而urlopen()则不使用自定义代理。
response = opener.open(request)
2. 如果这么写,就是将opener应用到全局,之后所有的,不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
urllib2.install_opener(opener)
response = urlopen(request)
print (response.read())
免费的开放代理获取基本没有成本,我们可以在一些代理网站上收集这些免费代理,测试后如果可以用,就把它收集起来用在爬虫上面。
免费短期代理网站举例:
西刺免费代理IP
快代理免费代理
Proxy360代理
全网代理IP
如果代理IP足够多,就可以像随机获取User-Agent一样,随机选择一个代理去访问网站。
import urllib2
import random
proxy_list = [
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"}
]
随机选择一个代理
proxy = random.choice(proxy_list)
使用选择的代理构建代理处理器对象
httpproxy_handler = urllib2.ProxyHandler(proxy)
opener = urllib2.build_opener(httpproxy_handler)
request = urllib2.Request("http://www.baidu.com/")
response = opener.open(request)
print response.read()
但是,这些免费开放代理一般会有很多人都在使用,而且代理有寿命短,速度慢,匿名度不高,HTTP/HTTPS支持不稳定等缺点(免费没好货)。
所以,专业爬虫工程师或爬虫公司会使用高品质的私密代理,这些代理通常需要找专门的代理供应商购买,再通过用户名/密码授权使用(舍不得孩子套不到狼)。
其次可以自己开发代理池:
HTTPPasswordMgrWithDefaultRealm()
HTTPPasswordMgrWithDefaultRealm()类将创建一个密码管理对象,用来保存 HTTP 请求相关的用户名和密码,主要应用两个场景:
1.验证代理授权的用户名和密码 (ProxyBasicAuthHandler())
2.验证Web客户端的的用户名和密码 (HTTPBasicAuthHandler())
ProxyBasicAuthHandler(代理授权验证)
如果我们使用之前的代码来使用私密代理,会报 HTTP 407 错误,表示代理没有通过身份验证:
urllib2.HTTPError: HTTP Error 407: Proxy Authentication Required
所以我们需要改写代码,通过:
HTTPPasswordMgrWithDefaultRealm():来保存私密代理的用户密码
ProxyBasicAuthHandler():来处理代理的身份验证。
#urllib2_proxy2.py
import urllib2
import urllib
私密代理授权的账户
user = "mr_mao_hacker"
私密代理授权的密码
passwd = "sffqry9r"
私密代理 IP
proxyserver = "61.158.163.130:16816"
1. 构建一个HTTP密码管理对象,用来保存需要处理的用户名和密码
#passwdmgr = urllib2.HTTPPasswordMgrWithDefaultRealm()
2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码
#passwdmgr.add_password(None, proxyserver, user, passwd)
3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象
注意,这里不再使用普通ProxyHandler类了
#proxyauth_handler = urllib2.ProxyBasicAuthHandler(passwdmgr)
BTW:
工作中常用下面的方式直接创建一个附带私密代理验证的处理器,使用更加简洁明了,并不需要上面3步的代码
1. 构建一个附带Auth验证的的ProxyHandler处理器类对象
proxyauth_handler = urllib2.ProxyHandler({"http" : "mr_mao_hacker:sffqry9r@61.158.163.130:16816"})
2. 通过 build_opener()方法使用这个代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler
opener = urllib2.build_opener(proxyauth_handler)
3. 构造Request 请求
request = urllib2.Request("http://www.baidu.com/")
4. 使用自定义opener发送请求
response = opener.open(request)
5. 打印响应内容
print response.read()
HTTPBasicAuthHandler处理器(Web客户端授权验证)
有些Web服务器(包括HTTP/FTP等)的有些页面并不想提供公共访问权限,或者某些页面不希望公开,但是可以让特定的客户端访问。那么用户在访问时会要求进行身份认证。
爬虫直接访问会报HTTP 401 错误,表示访问身份未经授权:
urllib2.HTTPError: HTTP Error 401: Unauthorized
如果我们有客户端的用户名和密码,我们可以通过下面的方法去访问爬取:
import urllib.request
用户名
user = "test"
密码
passwd = "123456"
Web服务器 IP
webserver = "http://36.110.230.138"
1. 构建一个密码管理对象,用来保存需要处理的用户名和密码
passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 Web服务器、用户名、密码
passwdmgr.add_password(None, webserver, user, passwd)
3. 构建一个HTTP基础用户名/密码验证的HTTPBasicAuthHandler处理器对象,参数是创建的密码管理对象
httpauth_handler = urllib.request.HTTPBasicAuthHandler(passwdmgr)
4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler
opener = urllib.request.build_opener(httpauth_handler)
5. 可以选择通过install_opener()方法定义opener为全局opener
urllib.request.install_opener(opener)
6. 构建 Request对象
request = urllib.request.Request("http://192.168.199.107")
7. 定义opener为全局opener后,可直接使用urlopen()发送请求
response = urllib.request.urlopen(request)
8. 打印响应内容
print (response.read())
Cookie原理
HTTP是无状态的面向连接的协议, 为了保持连接状态, 引入了Cookie机制 Cookie是http消息头中的一种属性,包括:
Cookie名字(Name)
Cookie的值(Value)
Cookie的过期时间(Expires/Max-Age)
Cookie作用路径(Path)
Cookie所在域名(Domain),
使用Cookie进行安全连接(Secure)。
前两个参数是Cookie应用的必要条件,另外,还包括Cookie大小(Size,不同浏览器对Cookie个数及大小限制是有差异的
Cookie由变量名和值组成,根据 Netscape公司的规定,Cookie格式如下:
Set-Cookie: NAME=VALUE;Expires=DATE;Path=PATH;Domain=DOMAIN_NAME;SECURE
Cookie应用(126邮箱)
Cookies在爬虫方面最典型的应用是判定注册用户是否已经登录网站,用户可能会得到提示,是否在下一次进入此网站时保留用户信息以便简化登录手续。
import urllib.request
1. 构建一个已经登录过的用户的headers信息
headers = {
"Host":"mail.126.com",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36",
"Accept":"*/*",
"Accept-Language":"zh-CN,zh;q=0.9",
# 便于终端阅读,表示不支持压缩文件
# Accept-Encoding: gzip, deflate, sdch,
# 重点:这个Cookie是保存了密码无需重复登录的用户的Cookie,这个Cookie里记录了用户名,密码(通常经过RAS加密)
"Cookie": "nts_mail_user=zhoudoujun@126.com:-1:1; locale=; face=js6; starttime=; NTES_SESS=tu1OyQMVsxTGmw1XuucnAwZ1daMQieCs66W6ZKNqEu2PzSAkzfcxNLXOhLSHGgZcvjPNWjQLuCizeLs1M7t3kO.y8qk81xtrtdGBpfx._r4lh.7pDREL5IvynYZ1Ij7uQG1S0PCLy7SbQ792s9XgOcrp94uDPQ6TAUBn4Gea5iSiUzf1HYkLF2ab98kMRS9yWlZehSqqxdDtb9Eqqek._zMdb; S_INFO=1637825976|0|#3&80#|zhoudoujun@126.com; P_INFO=zhoudoujun@126.com|1637825976|0|mail126|00&99|shh&1637818969&carddav#shh&null#10#0#0|&0|mail126|zhoudoujun@126.com; df=mail163_letter; mail_upx=t10hz.mail.126.com|t11hz.mail.126.com|t12hz.mail.126.com|t13hz.mail.126.com|t5hz.mail.126.com|t6hz.mail.126.com|c4bj.mail.126.com|c5bj.mail.126.com|c6bj.mail.126.com|c7bj.mail.126.com|c1bj.mail.126.com|c2bj.mail.126.com|c3bj.mail.126.com; mail_upx_nf=; mail_idc=""; Coremail=55568781d357f%OBZyGliOwHSOWsAAbgOOMRnabfFmBSoM%g1a57.mail.126.com; MAIL_ENTRY_INFO=1|0|mail126|mail163_letter|58.246.226.97|f2462aa68af7fddab2d3985fbc31a98f_v1|; MAIL_ENTRY_CS=1eb529110d8f0417e82261c893af88dd; cm_last_info=dT16aG91ZG91anVuJTQwMTI2LmNvbSZkPWh0dHBzJTNBJTJGJTJGbWFpbC4xMjYuY29tJTJGanM2JTJGbWFpbi5qc3AlM0ZzaWQlM0RPQlp5R2xpT3dIU09Xc0FBYmdPT01SbmFiZkZtQlNvTSZzPU9CWnlHbGlPd0hTT1dzQUFiZ09PTVJuYWJmRm1CU29NJmg9aHR0cHMlM0ElMkYlMkZtYWlsLjEyNi5jb20lMkZqczYlMkZtYWluLmpzcCUzRnNpZCUzRE9CWnlHbGlPd0hTT1dzQUFiZ09PTVJuYWJmRm1CU29NJnc9aHR0cHMlM0ElMkYlMkZtYWlsLjEyNi5jb20mbD0tMSZ0PS0xJmFzPXRydWU=; MAIL_SESS=tu1OyQMVsxTGmw1XuucnAwZ1daMQieCs66W6ZKNqEu2PzSAkzfcxNLXOhLSHGgZcvjPNWjQLuCizeLs1M7t3kO.y8qk81xtrtdGBpfx._r4lh.7pDREL5IvynYZ1Ij7uQG1S0PCLy7SbQ792s9XgOcrp94uDPQ6TAUBn4Gea5iSiUzf1HYkLF2ab98kMRS9yWlZehSqqxdDtb9Eqqek._zMdb; MAIL_SINFO=1637825976|0|#3&80#|zhoudoujun@126.com; MAIL_PINFO=zhoudoujun@126.com|1637825976|0|mail126|00&99|shh&1637818969&carddav#shh&null#10#0#0|&0|mail126|zhoudoujun@126.com; secu_info=1; mail_entry_sess=19a654707d81ff01c7b94ea0ff61a57e06aeedb297086ab04c2d106125a78a7c35dfcfaf4f989b0ec30267cace80b630a0b2f1aecb83f357a4f504c92c762f2270a0ed1d273a3dfdca73bae4211ff0df4041125b4228c686796f2ecffcba027f81b24b6a6c551f0848342ad3f029a4f1eb60fa1d4473a9c1af51bb9d55b8d567b7a1899330e640b9b81642102ab7c578d1be00116536512a58fe90100780d95b60c5b432fd7c982d72a2790c30040cb9ac86d52aef029703feadcf4d747a3222; JSESSIONID=6CE971703B07F115BB3D8932435CFD09; Coremail.sid=OBZyGliOwHSOWsAAbgOOMRnabfFmBSoM; mail_style=js6; mail_uid=zhoudoujun@126.com; mail_host=mail.126.com"
}
2. 通过headers里的报头信息(主要是Cookie信息),构建Request对象
request = urllib.request.Request("https://mail.126.com/js6/main.jsp?sid=OBZyGliOwHSOWsAAbgOOMRnabfFmBSoM", headers = headers)
3. 直接访问renren主页,服务器会根据headers报头信息(主要是Cookie信息),判断这是一个已经登录的用户,并返回相应的页面
response = urllib.request.urlopen(request)
4. 打印响应内容
print (response.read().decode("utf-8"))
但是这样做太过复杂,我们先需要在浏览器登录账户,并且设置保存密码,并且通过抓包才能获取这个Cookie,那有么有更简单方便的方法呢
在Python处理Cookie,一般是通过cookielib模块和 urllib2模块的HTTPCookieProcessor处理器类一起使用。
cookielib模块:主要作用是提供用于存储cookie的对象
HTTPCookieProcessor处理器:主要作用是处理这些cookie对象,并构建handler对象。
该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
CookieJar:管理HTTP cookie值、存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失。
FileCookieJar (filename,delayload=None,policy=None):从CookieJar派生而来,用来创建FileCookieJar实例,检索cookie信息并将cookie存储到文件中。filename是存储cookie的文件名。delayload为True时支持延迟访问访问文件,即只有在需要时才读取文件或在文件中存储数据。
MozillaCookieJar (filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与Mozilla浏览器 cookies.txt兼容的FileCookieJar实例。
LWPCookieJar (filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与libwww-perl标准的 Set-Cookie3 文件格式兼容的FileCookieJar实例。
其实大多数情况下,我们只用CookieJar(),如果需要和本地文件交互,就用 MozillaCookjar() 或 LWPCookieJar()
我们来做几个案例:
1)获取Cookie,并保存到CookieJar()对象中
import urllib.request
import http.cookiejar
构建一个CookieJar对象实例来保存cookie
cookiejar = http.cookiejar.CookieJar()
使用HTTPCookieProcessor()来创建cookie处理器对象,参数为CookieJar()对象
handler=urllib.request.HTTPCookieProcessor(cookiejar)
通过 build_opener() 来构建opener
opener = urllib.request.build_opener(handler)
4. 以get方法访问页面,访问之后会自动保存cookie到cookiejar中
opener.open("http://www.baidu.com")
## 可以按标准格式将保存的Cookie打印出来
cookieStr = ""
for item in cookiejar:
cookieStr = cookieStr + item.name + "=" + item.value + ";"
## 舍去最后一位的分号
print (cookieStr[:-1])
import urllib.request
import http.cookiejar
保存cookie的本地磁盘文件名
filename = 'cookie.txt'
声明一个MozillaCookieJar(有save实现)对象实例来保存cookie,之后写入文件
cookiejar = http.cookiejar.MozillaCookieJar(filename)
使用HTTPCookieProcessor()来创建cookie处理器对象,参数为CookieJar()对象
handler = urllib.request.HTTPCookieProcessor(cookiejar)
通过 build_opener() 来构建opener
opener = urllib.request.build_opener(handler)
创建一个请求,原理同urllib2的urlopen
response = opener.open("http://www.baidu.com")
保存cookie到本地文件
cookiejar.save()
import urllib.request
import http.cookiejar
创建MozillaCookieJar(有load实现)实例对象
cookiejar = http.cookiejar.MozillaCookieJar()
从文件中读取cookie内容到变量
cookie.load('cookie.txt')
使用HTTPCookieProcessor()来创建cookie处理器对象,参数为CookieJar()对象
handler = urllib.request.HTTPCookieProcessor(cookiejar)
通过 build_opener() 来构建opener
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com")
模拟登录要注意几点:
1.登录一般都会先有一个HTTP GET,用于拉取一些信息及获得Cookie,然后再HTTP POST登录。
2.HTTP POST登录的链接有可能是动态的,从GET返回的信息中获取。
3.password 有些是明文发送,有些是加密后发送。有些网站甚至采用动态加密的,同时包括了很多其他数据的加密信息,只能通过查看JS源码获得加密算法,再去破解加密,非常困难。
4.大多数网站的登录整体流程是类似的,可能有些细节不一样,所以不能保证其他网站登录成功。
这个测试案例中,为了想让大家快速理解知识点,我们使用的人人网登录接口是人人网改版前的隐藏接口(嘘…),登录比较方便。
当然,我们也可以直接发送账号密码到登录界面模拟登录,但是当网页采用JavaScript动态技术以后,想封锁基于 HttpClient 的模拟登录就太容易了,甚至可以根据你的鼠标活动的特征准确地判断出是不是真人在操作。
所以,想做通用的模拟登录还得选别的技术,比如用内置浏览器引擎的爬虫(关键词:Selenium ,PhantomJS),这个我们将在以后会学习到。
urllib2 的异常错误处理
在我们用urlopen或opener.open方法发出一个请求时,如果urlopen或opener.open不能处理这个response,就产生错误。
这里主要说的是URLError和HTTPError,以及对它们的错误处理。
URLError
URLError 产生的原因主要有:
没有网络连接
服务器连接失败
找不到指定的服务器
我们可以用try except语句来捕获相应的异常。下面的例子里我们访问了一个不存在的域名:
urllib2_urlerror.py
import urllib.error
request = urllib2.Request("http://www.ajkfhafwjqh.com")
try:
urllib2.urlopen(request, timeout=5)
except urllib.error.URLError as err:
print err
运行结果如下:
HTTPError
HTTPError是URLError的子类,我们发出一个请求时,服务器上都会对应一个response应答对象,其中它包含一个数字”响应状态码”。
如果urlopen或opener.open不能处理的,会产生一个HTTPError,对应相应的状态码,HTTP状态码表示HTTP协议所返回的响应的状态。
注意,urllib2可以为我们处理重定向的页面(也就是3开头的响应码),100-299范围的号码表示成功,所以我们只能看到400-599的错误号码。
import urllib.error
request = urllib2.Request("http://www.adou.cn/blog")
try:
urllib2.urlopen(request)
except urllib.error.HTTPError as err:
print err.code
print err
改进版
由于HTTPError的父类是URLError,所以父类的异常应当写到子类异常的后面,所以上述的代码可以这么改写:
import urllib.error
request = urllib2.Request("http://www.adou.cn/blog")
try:
urllib2.urlopen(request)
except urllib.error.HTTPError, err:
print err.code
except urllib.error.URLError aserr:
print err
else:
print "Good Job"
运行结果如下:
404
这样我们就可以做到,首先捕获子类的异常,如果子类捕获不到,那么可以捕获父类的异常。
Original: https://blog.csdn.net/u012441595/article/details/121546052
Author: IT瘾君
Title: python爬虫-urllib2的使用方法详解(python3)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/744586/
转载文章受原作者版权保护。转载请注明原作者出处!