

- DataFrame表示一个长方形表格,并包含排好序的列,每一列都可以是不同的数值类型(数字,字符串,布尔值)。DataFrame有行索引和列索引(row index, column index);可以看做是分享所有索引的由series组成的字典
本文代码可参考资源:https://download.csdn.net/download/weixin_43808138/82898438
(内含更全内容!可直接运行)
import pandas as pd
import numpy as np
一、DataFrame的基础
1.1 DataFrame的创建
data = pd.DataFrame({ 'a' : [1,2,3,4],
'b' : list('love'),
'c' : 1})
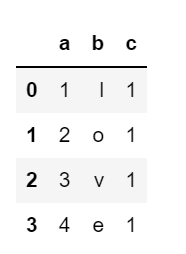

添加行索引
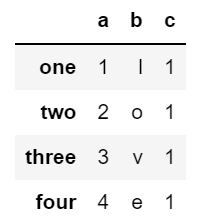
data = pd.DataFrame({ 'a' : [1,2,3,4],
'b' : list('love'),
'c' : 1},index = ['one','two','three','four'])
data
xuhao = ['one','two','three','four','five','six']
df = pd.DataFrame(np.random.randn(6,4), index=xuhao, columns=list('abcd'))
df

1.2 查看

对于一个较大的DataFrame,用head方法会返回前5行(注:这个函数在数据分析中经常使用,用来查看表格里有什么东西)
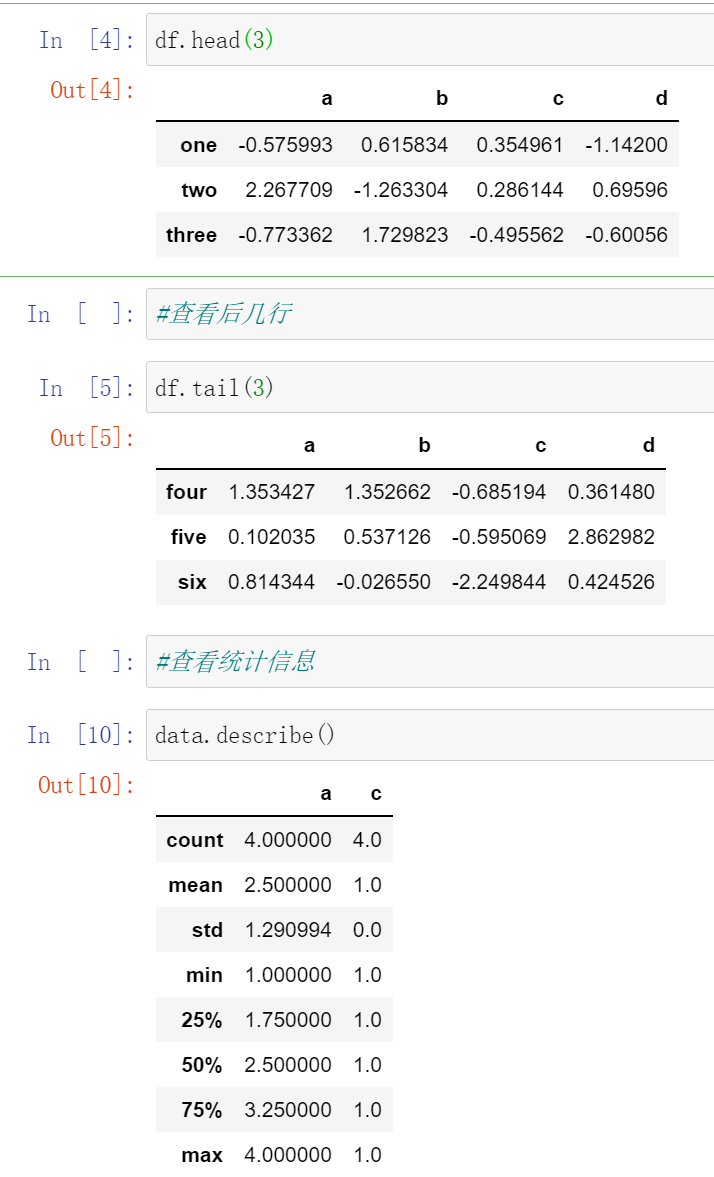
; 1.3 取值
取一列 :
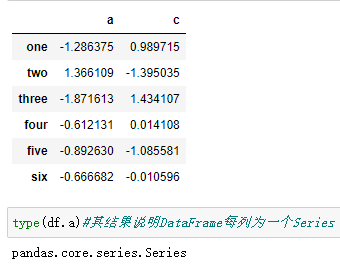
df['a']

取多列:
df[['a','c']]
df.loc['one']
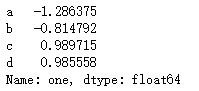
df.loc[['one','four']]
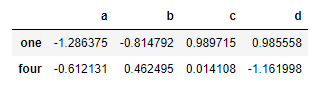
df[0:1]

取任意区域:
df.loc[['one','four'],'c']
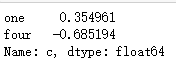
df.iloc[1:3,0:2]
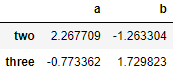
df.iloc[1:3,:]
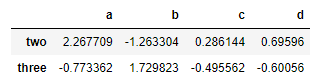
df.iloc[2,3]
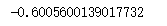
1.4 增、删、改
增加一列:
data['e'] = np.arange(4)
data['f'] = 100
data

删除一列:
del data['f']
data
也可以用drop删除列:
data.drop('a',axis =1)
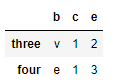
在DataFrame中,数据对齐同时发生在行和列上:
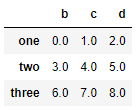
df1 = pd.DataFrame(np.arange(9.).reshape((3, 3)), columns=list('bcd'),
index=['one', 'two', 'three'])
df2 = pd.DataFrame(np.arange(12.).reshape((4, 3)), columns=list('bde'),
index=['three', 'four', 'five', 'six'])
df1
df2
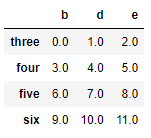
观察:df1和df2运算
df1+df2

对齐:对应项都有时,对应项进行运算,否则结果为NaN 所有的项都会出结果
二、DataFrame数据排序与重新索引
2.1 排序
import pandas as pd
import numpy as np
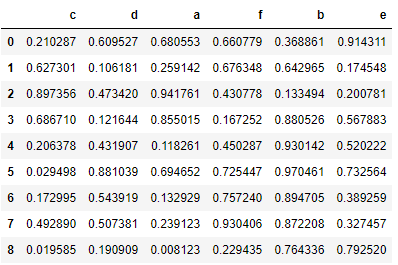
data = pd.DataFrame(np.random.rand(9,6),columns = list('cdafbe'))
data
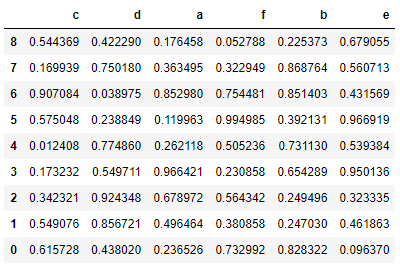
按照index序号来排序:
data.sort_index(ascending =False)
data.sort_index(axis =1)
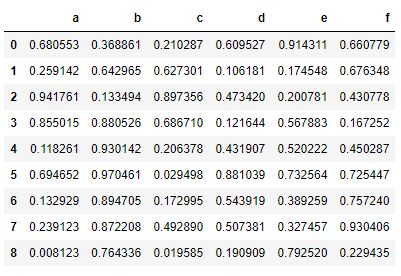
data.sort_values(by = 'c')
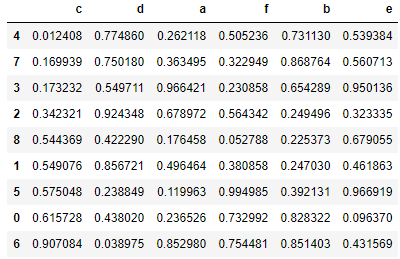
data.sort_values(by = ['c','d'])
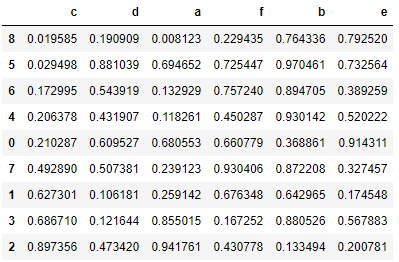
data.sort_values(by = ['c'])
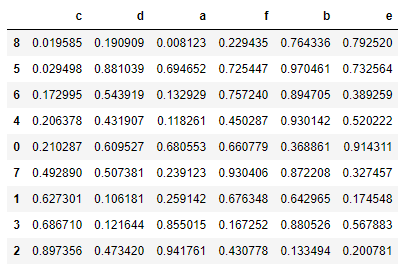
按照指定的顺序进行排序:
data.reindex(['a','e','f','b','c','d'],axis =1)
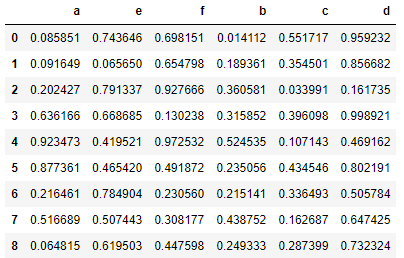
data.reindex(['a','e','f','b','c','d','d','r'],axis =1)

三、 DataFrame数据的汇总方法
data = pd.DataFrame(np.random.randn(9,6),columns = list('abcdef'))
data
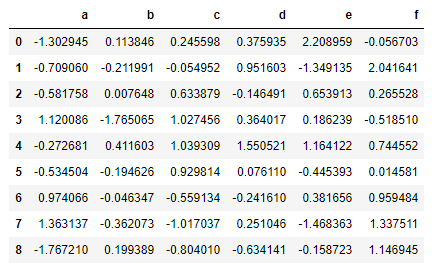
data.head()
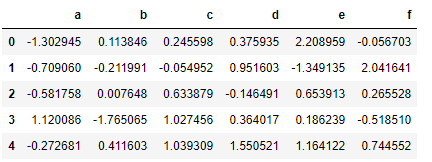
data.tail()
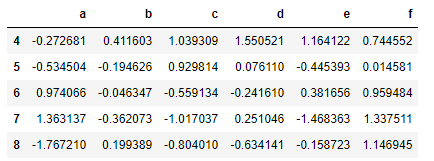
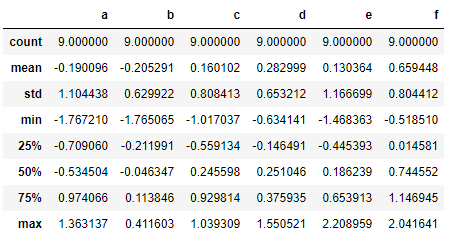
data.describe()
data.sum()
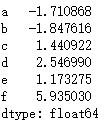
data.sum(1)

求均值:
data.mean()
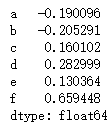
data.idxmax()

data.a[data.a.idxmax()]
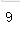
data = pd.DataFrame(np.random.randint(5,10,(5,6)),columns = list('abcdef'))
data

寻找唯一值:
data.a.unique()
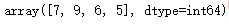
元素值统计
data.a.value_counts()

data = pd.DataFrame(np.random.randn(9,6),columns = list('abcdef'))
data
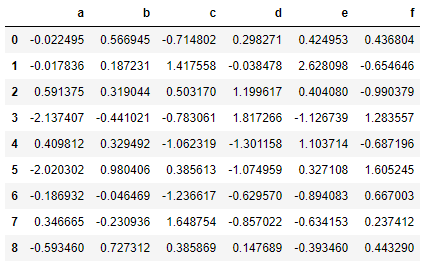
data.pct_change()
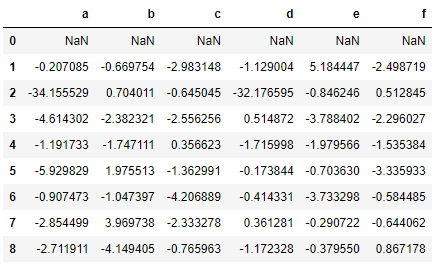
data.cumsum()
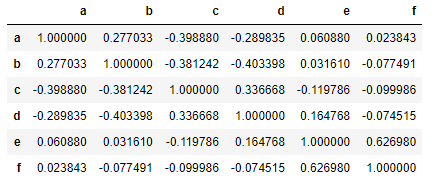
data.corr()
Original: https://blog.csdn.net/weixin_43808138/article/details/123191996
Author: zz神君
Title: DataFrame——基于jupyter
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/743981/
转载文章受原作者版权保护。转载请注明原作者出处!