

目录
引入库(数据分析常用三件套)
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline
读取文件(excel、csv)
//读取excel文件
data = pd.read_excel("C:\del\desktop\111.xlsx",sheet_name="Sheet1")
//读取csv文件
data = pd.read_csv("Data_Path")
Tips:注意,由于python语言会将”\”当作转义字符,因此在填写文件地址时,一定要将”\”字符转换成”/”,特别是当出现下面这个报错的时候,那就是地址写错了!!!
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escapec
查看数据集
df.head(10) //查看前10行的数据
df.shape //显示数据集的大小,如行和列的总数
df.info() //查看每个变量的数据类型,返回变量、数据类型、内存使用量和关于每个变量的缺失值情况
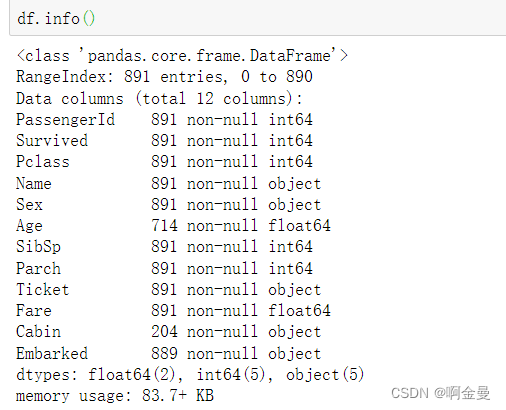

也可以使用isnull方法检查 “Age” 和 “Cabin” 两列中缺失的数值
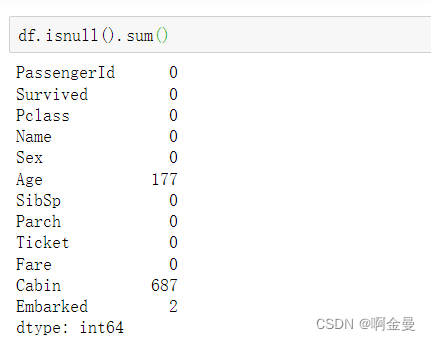
填充缺失值
很多时候我们需要将缺失值替换成有效的数值。
虽然可以通过 isnull() 方法建立掩码来填充缺失值,但是 Pandas 为此专门提供了一个fillna() 方法,它将返回填充了缺失值后的数组副本。
用一个单独的值来填充缺失值:
data.fillna(0)
用缺失值前面的有效值从前往后填充(forward-fill):
data.fillna(method=’ffill’)
series的话可以上述那样直接填充,如果是DataFrame还需要在填充时需要设置坐标轴参数 axis:
df.fillna(method=’ffillna’,axis=1)
需要注意,在从前往后填充时,如果需要填充的缺失值前面没有值,那么它就仍然是缺失值。
分组填充缺失值:举例填充平均值
//简单逻辑的方法:先获得该分组下的平均值,再一个个根据分组情况填充
df.groupby(["Pclass","Sex"])["Age"].mean()
df.loc[df.Age.isnull() & (df.Sex == "male") & (df.Pclass == 1),"Age"] = 40.0
df.loc[df.Age.isnull() & (df.Sex == "female") & (df.Pclass == 1),"Age"] = 35.0
df.loc[df.Age.isnull() & (df.Sex=="male") & (df.Pclass == 2),"Age"] = 30.0
df.loc[df.Age.isnull() & (df.Sex == "female") & (df.Pclass == 2),"Age"] = 28.0
df.loc[df.Age.isnull() & (df.Sex=="male") & (df.Pclass == 3),"Age"] = 25.0
df.loc[df.Age.isnull() & (df.Sex=="female") & (df.Pclass == 3),"Age"] = 21.5
//用transform 和 fillna函数快速实现
data["DA_num"] = data.groupby(["industry","Year"])["DA_num"].transform(lambda x: x.fillna(x.mean()))
查看,截取(切片)数据集
loc是 利用index的名称,来获取想要的行(或列)。(名称导向的这个特点,使得df[df.loc[‘col_name’] == ‘condition’, ‘col_name’] = value_1成立。
iloc利用index的具体位置(所以它只能是 整数型参数),来获取想要的行(或列)。
df.iloc[:3] //返回的是前3行的数
df.iloc[:3,:] //返回的是前3行,所有列的数,本质上与上条命令一致,默认省略
//根据位置和名称信息混搭的取数,例如想提取c行及其之前所有的,同时属于前4列的数
df.iloc[:df.index.get_loc('c') + 1, :4]
//get_loc 获取名称对象在index的位置(整数)
//因为iloc[num_of_row_start : num_of_row_end, num_of_column_start : num_of_column_end]不包含num_of_end,所以需要 +1才能包含c行
分组:groupby命令
参考:https://zhuanlan.zhihu.com/p/101284491
单一分组变量:例如根据公司进行分组
data.groupby("company")
多个分组变量:例如根据行业、年份进行分组
data.groupby(["industry","Year"])
得到的是DataFrameGroupBy object,为了方便查看,可以将其转换成list(data)
<pandas.core.groupby.generic.dataframegroupby object at 0x000002b7e2650240></pandas.core.groupby.generic.dataframegroupby>
groupby分组之后,就能够对数据进行聚合操作了
聚合:agg命令
data.groupby("company").agg('mean')
///可用的聚合函数有:max\min\sum\mean\median\std(标准差)\var(方差)\count
如果针对不同的列进行不同方式的聚合,比如要计算不同公司员工的平均年龄以及薪水的中位数,可以 利用字典进行聚合操作的指定:
聚合:transform命令
其与agg的区别是什么?
如果现在需要在原数据集中新增一列avg_salary,代表 员工所在的公司的平均薪水(相同公司的员工具有一样的平均薪水),该怎么实现呢?
如果用agg,按照正常的步骤来计算,需要先求得不同公司的平均薪水,然后按照员工和公司的对应关系填充到对应的位置,实现代码如下:
avg_salary_dict = data.groupby('company')['salary'].mean().to_dict()
​
data['avg_salary'] = data['company'].map(avg_salary_dict)
使用transform的话,仅需要一行代码:
data['avg_salary'] = data.groupby('company')['salary'].transform('mean')
​
聚合:apply命令
它相比前两种而言更加灵活,能够传入任意自定义的函数,实现复杂的数据操作。
假如要获取各个公司年龄最大员工的数据:
def get_oldest_staff(x):
...: df = x.sort_values(by = 'age',ascending=True)
...: return df.iloc[-1,:]
...:
​
oldest_staff = data.groupby('company',as_index=False).apply(get_oldest_staff)
删除操作
删除某一列(某个变量)
df.drop(columns = “Cabin”,inplace=True)
导出文件
将处理后的文件导出为excel/csv:
data.to_excel("data_path")
data.to_csv("data_path")
//更具体的导出参数设置,见参考链接
Original: https://blog.csdn.net/weixin_43726651/article/details/125335045
Author: 啊金曼
Title: Pandas库常用命令汇总——自用备查(挖坑,持续更新)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/743834/
转载文章受原作者版权保护。转载请注明原作者出处!