

第二章第一节学习目录
*
– 2.1 缺失值观察与处理
–
+ 2.1.1 任务一:缺失值观
+ 2.1.2 任务二:对缺失值进行处理
– 2.2 重复值观察与处理
–
+ 2.2.1 任务一:查看数据中的重复值
+ 2.2.2 任务二:对重复值进行处理
+ 2.2.3 任务三:将前面清洗的数据保存为csv格式
– 2.3 特征观察与处理
–
+ 2.3.1 任务一:对年龄进行分箱(离散化)处理
+ 2.3.2 任务二:对文本变量进行转换
+ 2.3.3 任务三(附加):从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
– 【总结】
2.1 缺失值观察与处理
因为数据集会有缺失或者重复影响数据分析的效果,所以我们需要在分析之前进行数据的一些处理。
首先我们照旧需要引入相应的库和数据包。
#加载库
import numpy as np
import pandas as pd
#加载文件
df = pd.read_csv('train.csv')
2.1.1 任务一:缺失值观
(1) 查看每个特征缺失值个数
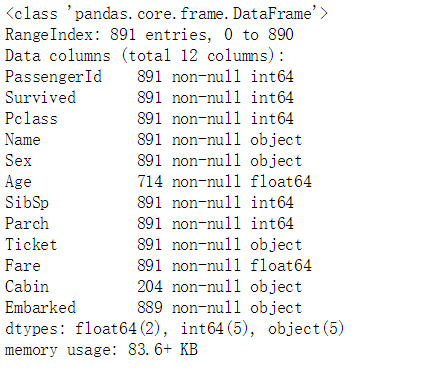
上一章我们就用过如下的函数查看各个参数的基本信息,在这些信息中表明了每个参数共有多少个值,从而,我们可以推断出有几个缺失值:
#查看缺失值
df.info()

当然,查看缺失值不止这一种方法,上一章提过的判空函数也可进行缺省值的查看:
df.isnull()
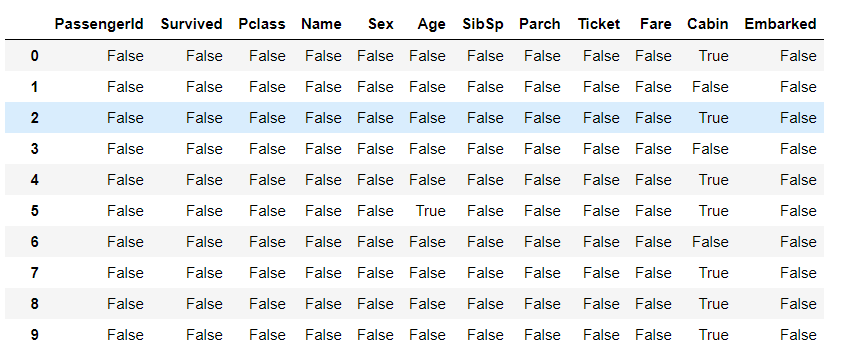
其中true表示数据缺失。
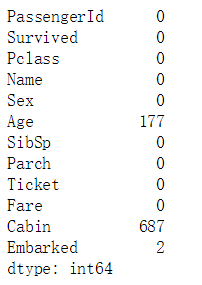
当然,我们也可以进行缺省值的统计:
df.isnull().sum()
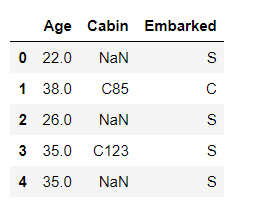
(2) 查看Age, Cabin, Embarked列的数据
这个在上一章的博客里也提到了如何查看指定列的信息。
df[['Age','Cabin','Embarked']].head()
2.1.2 任务二:对缺失值进行处理
(1)处理缺失值一般有几种思路
a.用同一个数字来补全,默认0
df.fillna()
b.相互填充(上面数据补下面数据,或下面数据补上面数据)
如下例子是向后填充,也就是上面数据补下面数据:
df.fillna(method='ffill')
如下例子是向前填充,也就是下面数据补上面数据:
df.fillna(method='bfill')
(2) 对Age列的数据的缺失值进行处理
处理方式同样有很多种:
a.用0来补全:
df.fillna({'Age':0})
因为只补全Age,所以需要在函数中注明。
b.用loc函数
df.loc[df['Age'].isnull(),'Age'] = 0
loc函数用于显示需要显示的值,这在上一章有提到过。
c.用none
df[df['Age']==None]=0
d.用isnull
df[df['Age'].isnull()] = 0
d.用np.nan
df[df['Age'] == np.nan] = 0
在这一个问题下面,在np.nan,None以及.isnull()几种方式中最好用np.nan,因为数值列读取数据后用None一般搜索不到浮点数的数据类型。而且在一般在实际应用中,np.nan多用于单个值的检验,pd.isnull()用于对一个DataFrame或Series(整体)的检验。
将几种方式分别进行使用及判空查看,则可发现Age已经没有空值了:
df.isnull().sum()
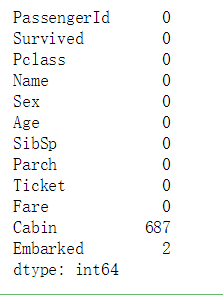
(3) 使用不同的方法直接对整张表的缺失值进行处理
上面已经运用了很多种补全方法,这里我们来补全一下整张表。
第一种方式:
df.dropna().head()
这种方式是丢弃有空值的行,当然想丢弃有空值的列可以在函数中设置参数,即可改变,这个函数有五个参数,我们可以进行设置来达到我们的目的。
第二种方式:
这种方式就是在上两个问题中所使用的,它用来补全数据而非删除,这里我们用0来统一补全数据。
#用0补全整张表
df=df.fillna(0)
df.isnull().sum()
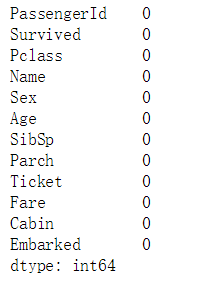
(需要记得赋值,否则只是显示,而没有真正进行保存)
我们可以从图中看出已经没有了空缺值。
2.2 重复值观察与处理
2.2.1 任务一:查看数据中的重复值
#查看重复行
df[df.duplicated()]
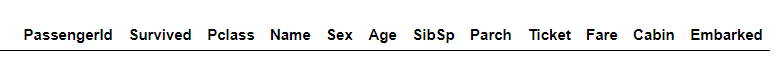
我们可以从图中看出此数据集中没有重复行。
2.2.2 任务二:对重复值进行处理
先设一个有重复值的数据集:
a=pd.DataFrame({'a':['1','1','2','2','2'],
'b':['3','3','3','4','4'],
'c':[5,5,3.5,15,5]})
a
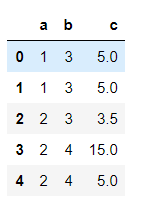
(1)查看重复行:
a[a.duplicated()]
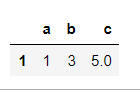
我们从索引得知,第二行重复了。
(2)重复值的清理
#清除重复值
a = a.drop_duplicates()
a.head()

我们可以观察到,第一行已经被清除了。
2.2.3 任务三:将前面清洗的数据保存为csv格式
#将前面清洗的数据保存为csv格式
df.to_csv('test_clear.csv')
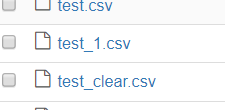
我们可以看到文件已经生成并保存在当前目录下了。
2.3 特征观察与处理
对数据进行观察,我们可以发现特征主要分为两种类型:数值类型和文本类型。
数值类型可直接进行模型的训练,但是文本类型需要先进行数值转换,才能进行分析运用。
2.3.1 任务一:对年龄进行分箱(离散化)处理
(1) 分箱操作是什么?
分箱操作,即是分箱离散化,将数据进行离散化的归类,是一种无监督离散化方法,主要分为两类:等距离分箱和等频度分箱。
其中,等距离分箱即等宽度分箱,设有K个空间,则每个空间的间距 I=(Max-Min)/K;等频率分箱,即等深度分箱。
使用分箱操作可以剔除那些异常的数据,防止后续模型训练出错。
(2) 将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
#将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
df['AgeBand'] = pd.cut(df['Age'], 5,labels = [1,2,3,4,5])
df.head()

我们可以看到,后面已经加入一列用于分箱的特征。
用直方图进行直观感受(五段即是16岁为一段,因为最大岁数80,最小0岁):
#画直方图
from matplotlib import pyplot as plt
plt.hist(df['Age Bins'])
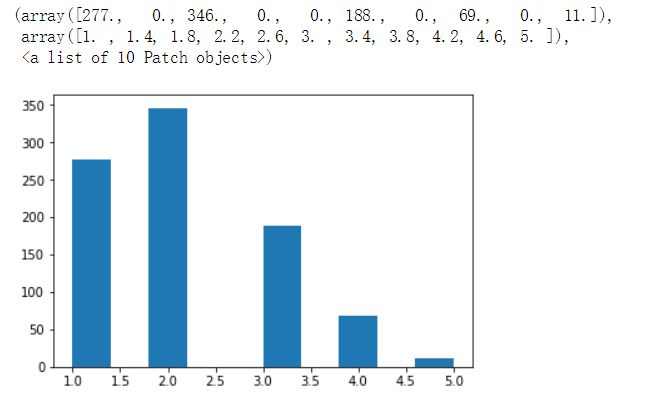
我们可以从中看出40岁以内的人占大多数人。
保存数据:
df.to_csv('test_ave.csv')
(3) 将连续变量Age划分为(0,5] (5,15] (15,30] (30,50] (50,80]五个年龄段
#right默认左闭右开,这里需改变参数值
df['Age Bins'] = pd.cut(df['Age'], [0,5,15,30,50,80],right=False)
df.head()
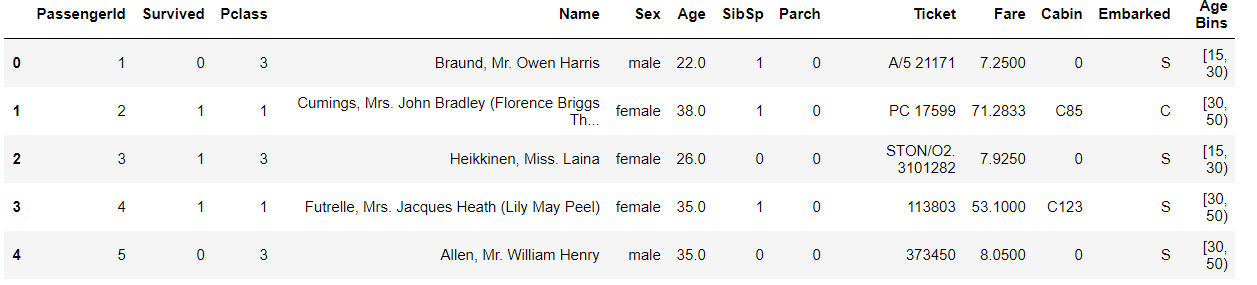
我们可以清楚的看到每个人年龄的区间。
保存数据:
df.to_csv('test_cut.csv')
(4) 将连续变量Age按10% 30% 50% 70% 90%五个年龄段,并用分类变量12345表示
注意:代码里的注释很重要
#Bin edges must be unique,所以我们需要用到另一个参数duplicates,取消唯一性
Bin labels must be one fewer than the number of bin edges,所以标签必须为四个而不是五个
df['Age Bins'] = pd.qcut(df['Age'],[0,0.1,0.3,0.5,0.7,0.9],duplicates='drop',labels = [1,2,3,4])
df.head(10)
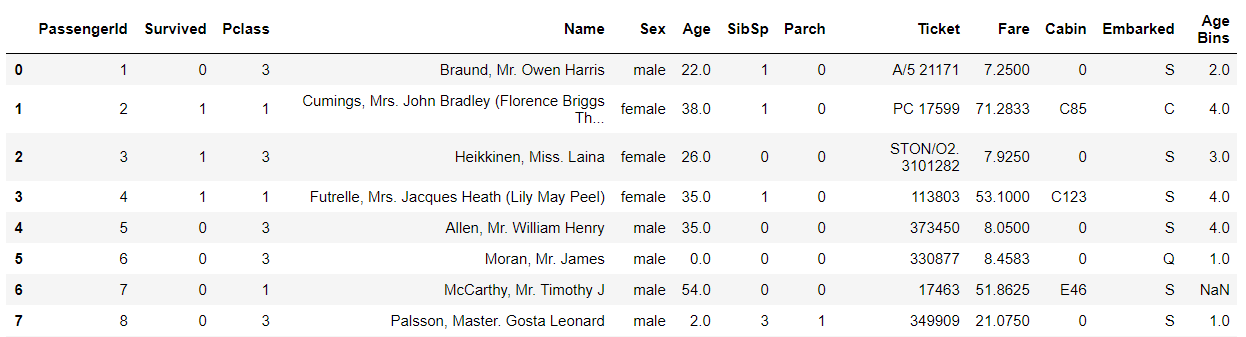
这种方法会导致Age Bins特征下属于5的标签变为空值。后来进行研究,发现需要在0.9后再加上1,补全整个百分制才可以显示正确。如下所示:
df['Age Bins'] = pd.qcut(df['Age'],[0,0.1,0.3,0.5,0.7,0.9,1],duplicates='drop',labels = [1,2,3,4,5])
df.head(10)
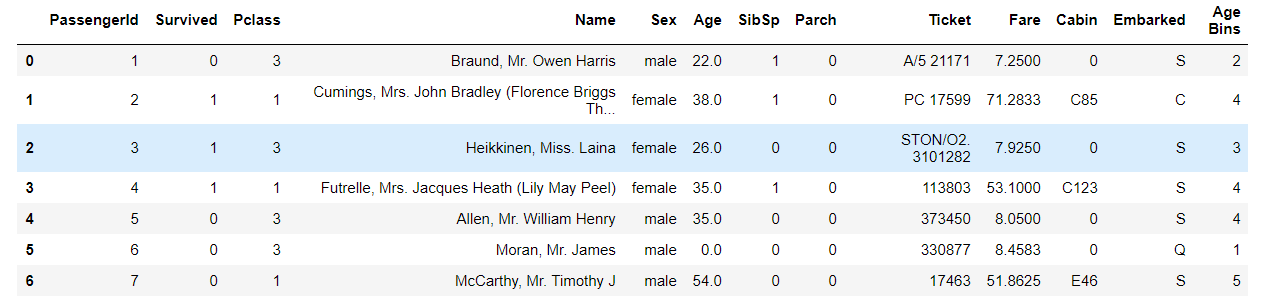
保存数据:
df.to_csv('test_pr.csv')
2.3.2 任务二:对文本变量进行转换
(1) 查看文本变量名及种类
方法一:
Sex:
df['Sex'].unique()
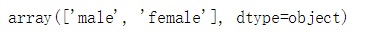
Cabin:
df['Cabin'].unique()

Embarked:
df['Embarked'].unique()

在图中,我们可以清楚的看到各个特征有哪些值和类型是什么。
方法二:
Sex:
df['Sex'].value_counts()

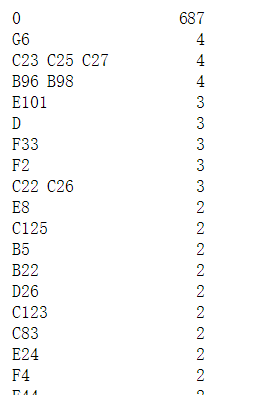
Cabin:
df['Cabin'].value_counts()
Embarked:
df['Embarked'].value_counts()

从图中我们可以看出,各个特征值有哪些,每个值有几个。
(2) 将文本变量Sex, Cabin ,Embarked用数值变量12345表示
方法一:
Sex:
#方法一: replace
df['Sex_num'] = df['Sex'].replace(['male','female'],[1,2])
df.head()
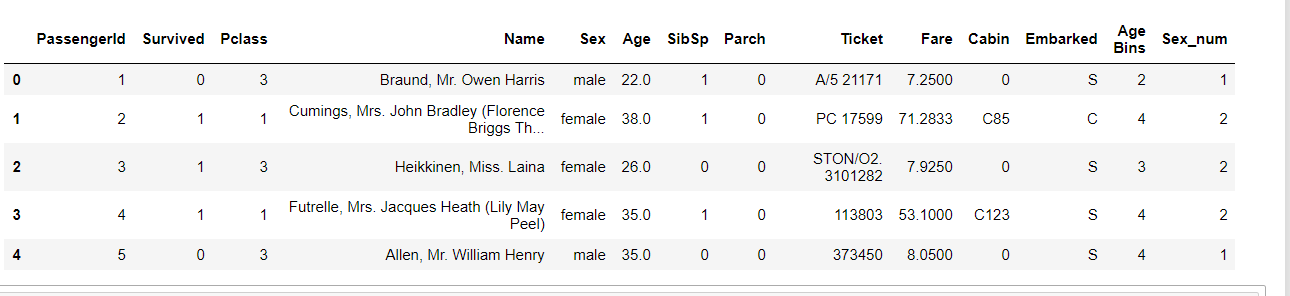
这里我们将1设置为男性,2设置为女性。
方法二:
Cabin:
由于Cabin的值太多,我们引入处理包sklearn.preprocessing来进行快速处理。
注意 此函数只能用于全是文本的数据,之前补缺失值的时候有数值加入,这里需要将0转为文本类型(astype(str)))。
#进行多数值的文本向数值类型转化
from sklearn.preprocessing import LabelEncoder
df['Cabin_num']= LabelEncoder().fit_transform(df['Cabin'].astype(str))
df.head()
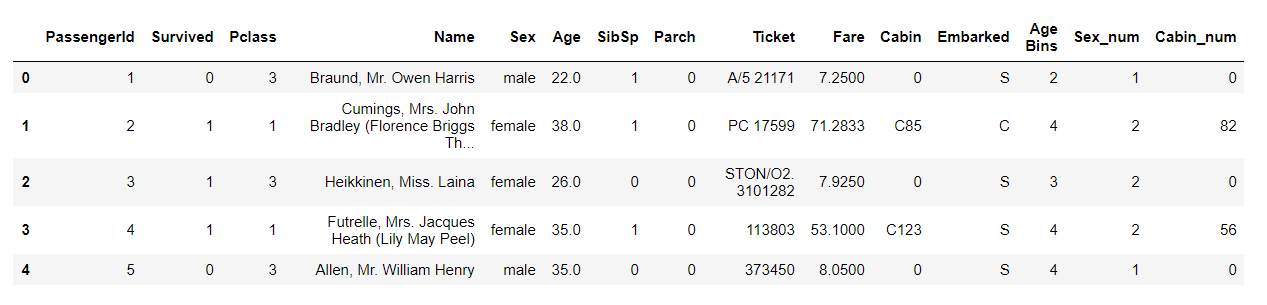
方法三:
Embarked:
#方法三: map
df['Embarked_num'] = df['Embarked'].map({'S':1,'C':2,'Q':3,0:4})
df.head()
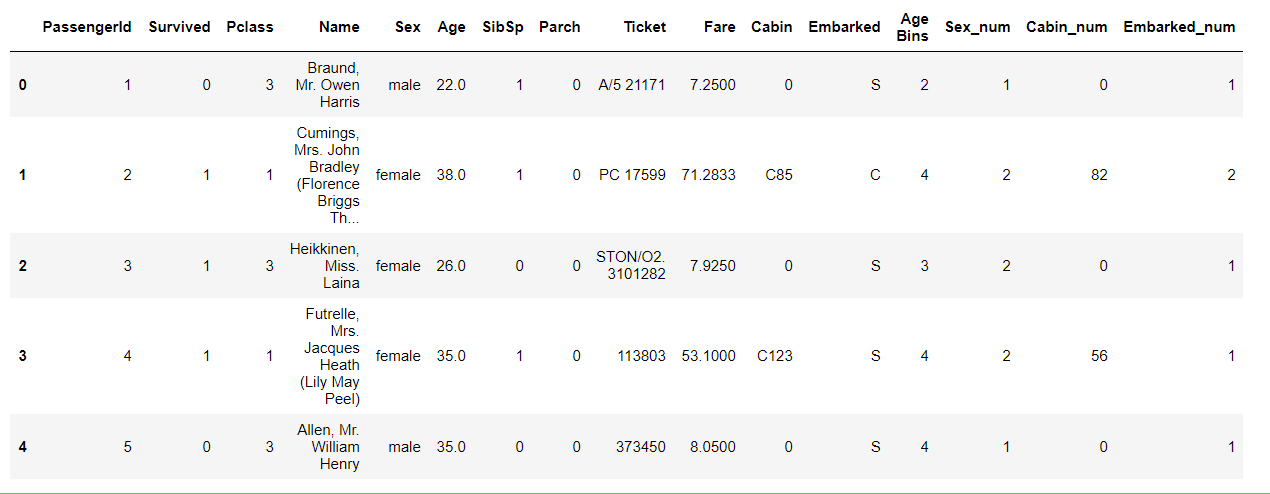
(3) 将文本变量Sex, Cabin, Embarked用one-hot编码表示
one-hot编码:One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。这样可以有效的对特征进行分类,也有利于后续的比较。
下面,为了加快速度,我们用循环的方式将三个参数设为one-hot编码。
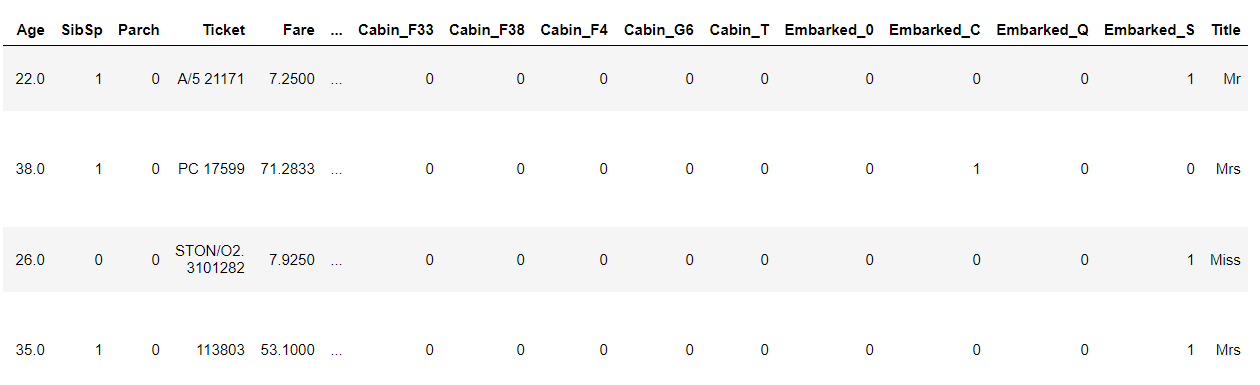
#将类别文本转换为one-hot编码
for feat in ["Sex","Cabin","Embarked"]:
x = pd.get_dummies(df[feat], prefix=feat)
df = pd.concat([df, x], axis=1)
#df[feat] = pd.get_dummies(df[feat], prefix=feat)
df.head()

2.3.3 任务三(附加):从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
我们可以使用如下方法:
df['Title'] = df.Name.str.extract('([A-Za-z]+)\.')
df.head()
如图所示,我们就已经提取出了名字前的前缀:
保存本节结论:
df.to_csv('test_fin.csv')
【总结】
在本章本节主要学习了数据缺失值和重复值的处理,以及对文本数据向数值类型转化和处理的方法。利用本节所学,我们可以更清晰更直观的了解到我们的数据是什么样的,该如何去处理它们,让他们为我们所用,在后期对模型的训练具有重要的意义。
Original: https://blog.csdn.net/weixin_43356993/article/details/121970199
Author: 北辰若星⭐
Title: 一起动手学数据分析 task02 数据清洗及特征处理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/743623/
转载文章受原作者版权保护。转载请注明原作者出处!