

concat:
- Pandas函数
- 可以垂直和水平地连接两个或多个pandas对象
- 只用索引对齐
- 索引出现重复值时会报错
- 默认是外连接(也可以设为内连接)
join:
- DataFrame方法
- 只能水平连接两个或多个pandas对象
- 对齐是靠被调用的DataFrame的列索引或行索引和另一个对象的行索引(不能是列索引)
- 通过笛卡尔积处理重复的索引值
- 默认是左连接(也可以设为内连接、外连接和右连接)
merge:
- DataFrame方法
- 只能水平连接两个DataFrame对象
- 对齐是靠被调用的DataFrame的列或行索引和另一个DataFrame的列或行索引
- 通过笛卡尔积处理重复的索引值
- 默认是内连接(也可以设为左连接、外连接、右连接)
用户自定义的display_frames函数,可以接收一列DataFrame,然后在一行中显示:
from IPython.display import display_html
years = 2016, 2017, 2018
stock_tables = [pd.read_csv('data/stocks_{}.csv'.format(year), index_col='Symbol') for year in years]
def display_frames(frames, num_spaces=0):
t_style = '
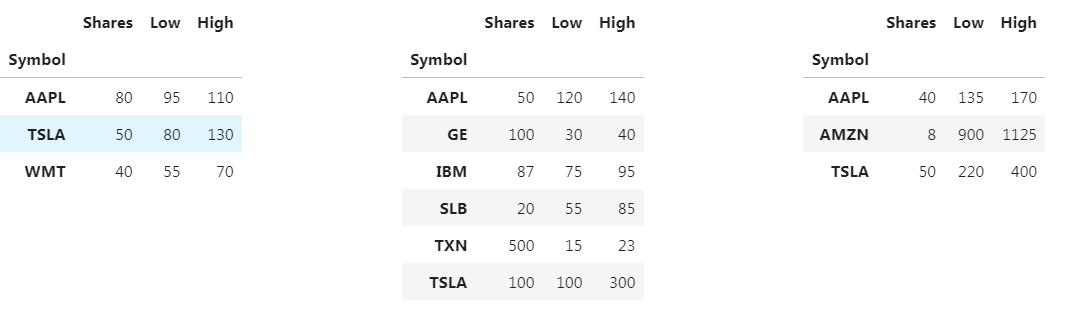

concat是唯一一个可以将DataFrames垂直连接起来的函数
pd.concat(stock_tables, keys=[2016, 2017, 2018])
SharesLowHigh Symbol 2016AAPL8095110TSLA5080130WMT4055702017AAPL50120140GE1003040IBM877595SLB205585TXN5001523TSLA1001003002018AAPL40135170AMZN89001125TSLA50220400
pd.concat(dict(zip(years,stock_tables)), axis='columns')
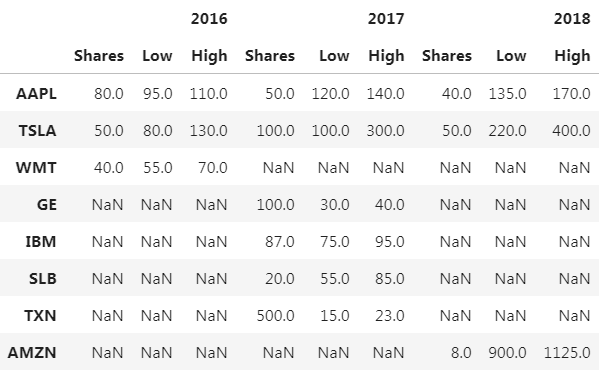
用join将DataFrame连起来;如果列名有相同的,需要设置lsuffix或rsuffix以进行区分
stocks_2016.join(stocks_2017, lsuffix='_2016', rsuffix='_2017', how='outer')

stocks_2016
Shares Low High
Symbol
AAPL 80 95 110
TSLA 50 80 130
WMT 40 55 70
要重现前面的concat方法,可以将一个DataFrame列表传入join
other = [stocks_2017.add_suffix('_2017'), stocks_2018.add_suffix('_2018')]
stocks_2016.add_suffix('_2016').join(other, how='outer')

检验这两个方法是否相同
stock_join = stocks_2016.add_suffix('_2016').join(other, how='outer')
stock_concat = pd.concat(dict(zip(years,stock_tables)), axis='columns')
stock_concat.columns = stock_concat.columns.get_level_values(1) + '_' + stock_concat.columns.get_level_values(0).astype(str)
stock_concat

step1 = stocks_2016.merge(stocks_2017, left_index=True, right_index=True, how='outer', suffixes=('_2016', '_2017'))
stock_merge = step1.merge(stocks_2018.add_suffix('_2018'), left_index=True, right_index=True, how='outer')
stock_concat.equals(stock_merge)
#True
stock_merge

查看food_prices和food_transactions两个小数据集
names = ['prices', 'transactions']
food_tables = [pd.read_csv('data/food_{}.csv'.format(name)) for name in names]
food_prices, food_transactions = food_tables
display_frames(food_tables, 30)

通过键item和store,将food_transactions和food_prices两个数据集融合
food_transactions.merge(food_prices, on=['item', 'store'])
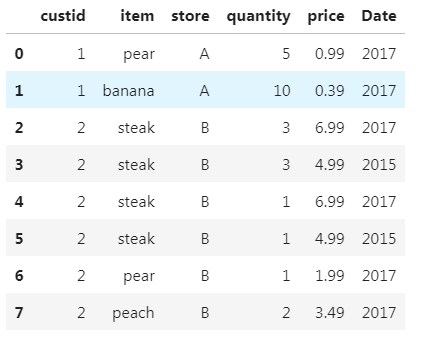
因为steak在两张表中分别出现了两次,融合时产生了笛卡尔积,造成结果中出现了四行steak;因为coconut没有对应的价格,造成结果中没有coconut
下面只融合2017年的数据
food_transactions.merge(food_prices.query('Date == 2017'), how='left')

使用join复现上面的方法,需要将要连接的food_prices列转换为行索引
food_prices_join = food_prices.query('Date == 2017').set_index(['item', 'store'])
food_prices_join

join方法只对齐传入DataFrame的行索引,但可以对齐调用DataFrame的行索引和列索引;
要使用列做对齐,需要将其传给参数on
food_transactions.join(food_prices_join, on=['item', 'store'])

要使用concat,需要将item和store两列放入两个DataFrame的行索引。但是,因为行索引值有重复,造成了错误
#pd.concat([food_transactions.set_index(['item', 'store']),food_prices.set_index(['item', 'store'])], axis='columns')
###ValueError: cannot handle a non-unique multi-index!
glob模块的glob函数可以将文件夹中的文件迭代取出,取出的是文件名字符串列表,可以直接传给read_csv函数
#glob用它可以查找符合特定规则的文件路径名。使用该模块查找文件,只需要用到: "*", "?", "[]"这三个匹配符;
import glob
df_list = []
for filename in glob.glob('data/gas prices/*.csv'):
df_list.append(pd.read_csv(filename, index_col='Week', parse_dates=['Week']))
gas = pd.concat(df_list, axis='columns')
gas.head()

Original: https://blog.csdn.net/weixin_48135624/article/details/113994207
Author: 缘 源 园
Title: concat, join, 和merge的区别在Python中
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/743228/
转载文章受原作者版权保护。转载请注明原作者出处!