

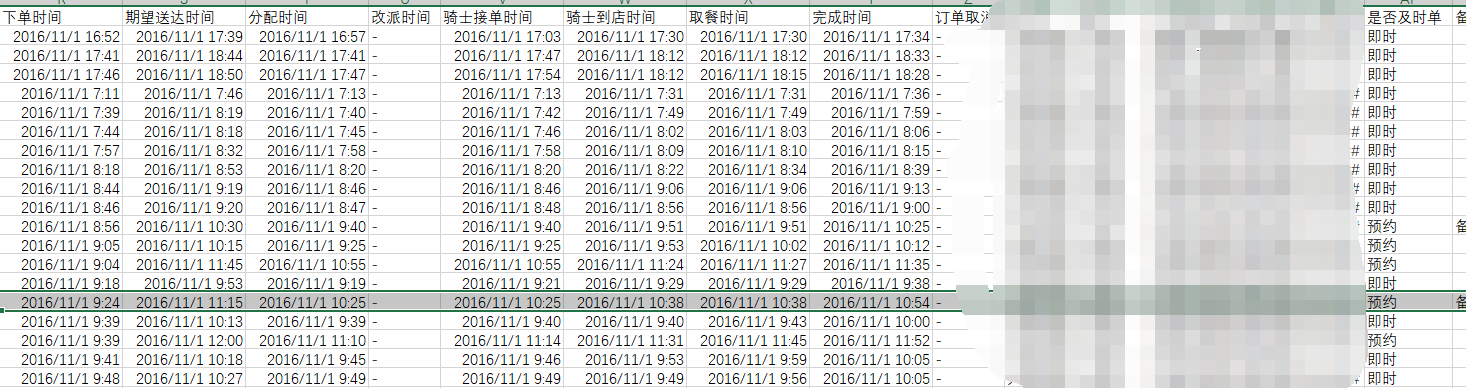
在外卖订单中,我们获取订单的下单时间和订单的交付时间,想知道他们之间隔了由多少分钟。数据如下:

使用pandas读取excel数据:
import pandas as pd
testData = pd.read_excel('data20.xlsx') # 读取测试数据
读取数据之后,我们需要将 【是否为及时单】列的预约数据给剔除掉:
写法1:
filterData = testData[~testData['是否及时单'].str.contains('预约')]
写法2:
filterData = testData[testData['是否及时单'].str.contains('预约') == False]
过滤掉不想要的数据后,我们就可以计算下单时间和订单完成时间之间的分钟数:
xiadanSJ = filterData['下单时间']
wanchengSJ = filterData['完成时间']
diff = wanchengSJ-xiadanSJ
结果如下:
0 0 days 00:05:00
1 0 days 00:00:00
2 0 days 00:01:00
3 0 days 00:02:00
4 0 days 00:01:00
5 0 days 00:01:00
6 0 days 00:01:00
7 0 days 00:02:00
8 0 days 00:02:00
9 0 days 00:01:00
13 0 days 00:01:00
15 0 days 00:00:00
17 0 days 00:04:00
18 0 days 00:01:00
dtype: timedelta64[ns]
可以看到:数据中的五条预约数据记录已经被移除,只留下了我们的想要的分钟数。
转化为数值类型:
diffMin = [d.total_seconds()/60 for d in diff]
转换结果:
[42.0, 52.0, 42.0, 25.0, 20.0, 22.0, 18.0, 21.0, 29.0, 14.0, 20.0, 21.0, 24.0, 17.0]
关于清除某列包含某个值的数据的说明:
pandas取出包含某个值的所有行
df = df[df['from_account'].str.contains('fcwhx')]
pandas取出不包含某个值的所有行
df = df[~df['from_account'].str.contains('fcwhx','na=False')]
或
df = df[df['from_account'].str.contains('fcwhx')==False]
如果有空值,报错:TypeError: bad operand type for unary ~: 'float' 则用这个方法
df.other_group = df.other_group.fillna('####@')
df2 = df[~df['other_group'].str.contains('####@')]
Original: https://blog.csdn.net/weixin_45624300/article/details/123201221
Author: 运筹码仓
Title: Python基础语法04:pandas剔除某值的行及计算日期差
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/743188/
转载文章受原作者版权保护。转载请注明原作者出处!