

版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/zhr1030635594/article/details/97617615
由于经历一些调试,所以代码结构不一定最优,适合数据处理的新手,大神欢迎提出改进
数据来源:
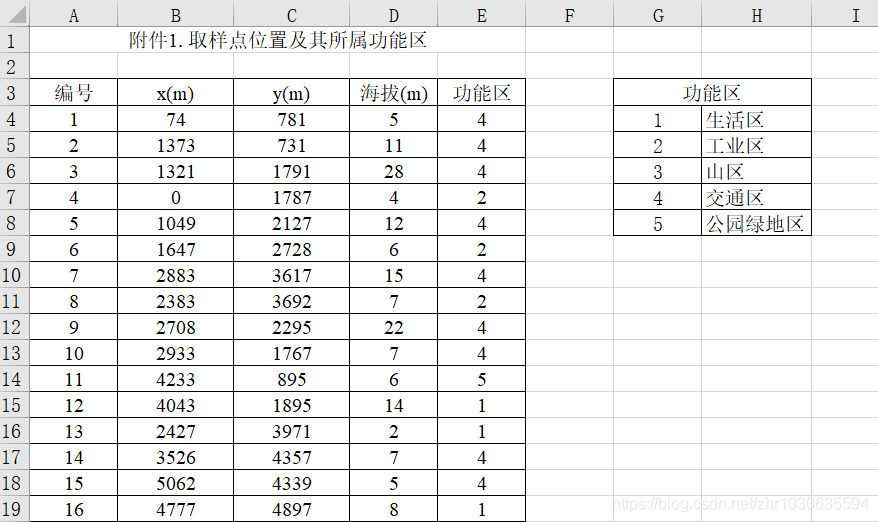

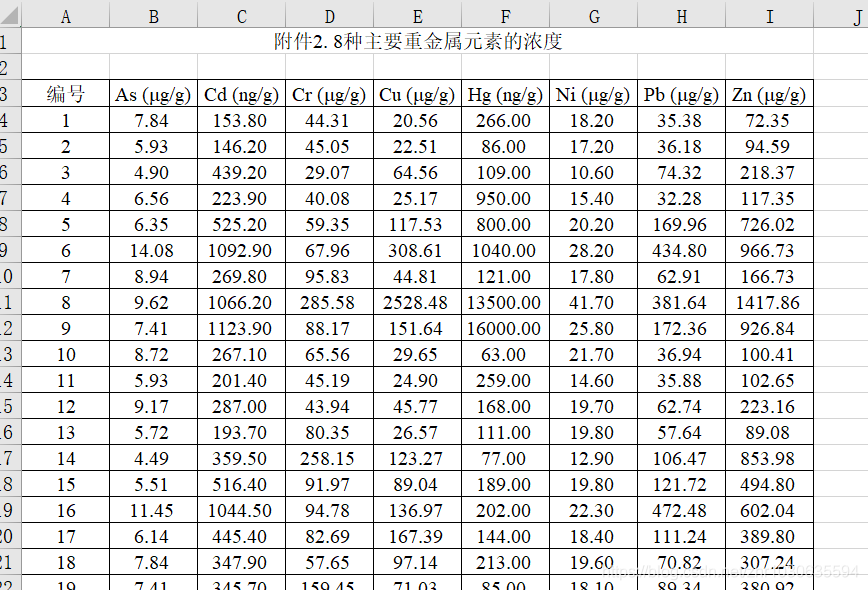
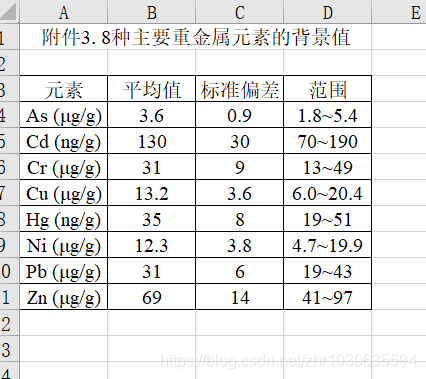
设p为均值,s为标准差
由表三可知,元素背景值在[p-s, p+s],所以应用到表一,将不符合的数据剔除
上代码
[code]import numpy as np
import pandas as pd
[code]path = “E:/Model_building/A/cumcm2011A附件_数据.xls”
s1 = pd.read_excel(path, sheet_name=”附件1″)
s2 = pd.read_excel(path, sheet_name=”附件2″)
s3 = pd.read_excel(path, sheet_name=”附件3″) # 读入一个文件中的三个表
s1 = s1.values # 转化为数值形式
s2 = s2.values
s3 = s3.values
s1 = pd.DataFrame(s1) # 转化为dataframe形式
s2 = pd.DataFrame(s2)
s3 = pd.DataFrame(s3)
print(s1)
[code]s1 = s1.iloc[2:, 0:5]
s2 = s2.iloc[2:, 0:9]
s3 = s3.iloc[2:, :] # 去掉表头等不需要的部分,如表一的右边
print(s1,’\n’)
print(s2,’\n’)
print(s3,’\n’)
[code]l = []
for c in range(1,9): # 将各元素标准差放到列表
a = s2.iloc[: ,c].std()
l.append( a )
print(a,’\n’)
p = []
for c in range(1,9): # 各元素均值放到列表
a = s2.iloc[:, c].mean()
p.append( a )
for c in range(0,8):
themin = p[c] – 2*l[c]
themax = p[c] + 2*l[c]
print(themin, ‘ ‘, themax)
s2 = s2[(s2.iloc[:, c+1] >= themin )& (s2.iloc[:, c+1]
Original: https://blog.csdn.net/weixin_39564151/article/details/113508103
Author: weixin_39564151
Title: python剔除列表异常值_Python数据分析处理(一)——处理剔除异常值 以全国数学建模(CUMCM 2011 A题)为实例…
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/743015/
转载文章受原作者版权保护。转载请注明原作者出处!