

目录
- 去除重复行 .drop_duplicates()
8.1 .drop_duplicates() 语法
Help on method drop_duplicates in module pandas.core.frame:
drop_duplicates(subset: 'Optional[Union[Hashable, Sequence[Hashable]]]' = None, keep: 'Union[str, bool]' = 'first', inplace: 'bool' = False, ignore_index: 'bool' = False) -> 'Optional[DataFrame]' method of pandas.core.frame.DataFrame instance
Return DataFrame with duplicate rows removed.
Considering certain columns is optional. Indexes, including time indexes
are ignored.
Parameters
----------
subset : column label or sequence of labels, optional
Only consider certain columns for identifying duplicates, by
default use all of the columns.
keep : {'first', 'last', False}, default 'first'
Determines which duplicates (if any) to keep.
- 8.1.1 .drop_duplicates() 语法结构
DataFrame.drop_duplicates(subset: ‘Optional[Union[Hashable, Sequence[Hashable]]]’ = None, keep: ‘Union[str, bool]’ = ‘first’, inplace: ‘bool’ = False, ignore_index: ‘bool’ = False)
8.1.2 .drop_duplicates() 参数说明
subset:列标识或者列的序列,可选。默认值是None,即使用所有的列进行检测,如果 subset 指定了部分列,则只考虑 subset 指定列是否重复。
keep:可选的集合 {‘first’, ‘last’, False},默认是 ‘first’。这个域决定了如何去保留重复行。
‘first’:重复的行中,除了第一行,其余删除
‘last’:重复的行中,除了最后行,其余删除
False:删除所有重复的行
inplace:布尔值,默认为 False。决定是否原地改变还是返回一个副本。
ignore_index:布尔值,默认为 False。 如果为 True,那么起作用的轴则会标记为 0,1,….n-1
返回值:数据结构为 DataFrame 或者 None。当 inplace=True 且所有的行都被删除时候,得到是 None
8.2 .drop_duplicates() 范例
准备数据
dict_data={"a":list("abcdaa"),"b":list("abfccc"),"c":list("ggijgg")}
df=pd.DataFrame.from_dict(dict_data)
df


8.2.1 subset
默认情况,针对所有列进行判断,4、5 、6 行重复,只保留 4 行

subset 只针对少量列,针对 ‘a’ 列进行判断,3、4、5 、6 行重复,只保留 3 行

8.2.2 keep
keep=’last’,只保留最后一行,针对 ‘a’ 列进行判断,3、4、5 、6 行重复,只保留 6 行

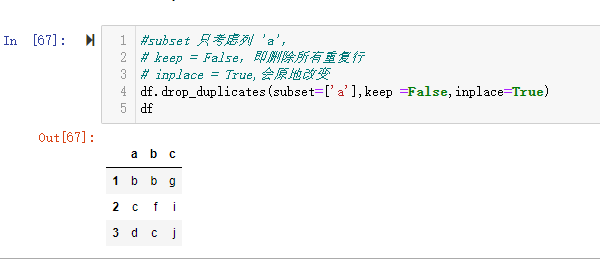
keep=False,删除所有行,针对 ‘a’ 列进行判断,3、4、5 、6 行重复,全部被删除了

8.2.3 inplace
inplace:布尔值,默认为 False。决定是否原地改变还是返回一个副本。
inplace 为 False 时候,不会进行原地改变,而 inplace 设置为 True 时候,会原地改变。
8.2.4 ignore_index
ignore_index:布尔值,默认为 False。 如果为 True,那么起作用的轴则会标记为 0,1,….n-1
为了使用这个参数,重新设计测试数据
dict_data={"a":list("abcdaaa"),"b":list("abfcccc"),"c":list("ggijggg")}
df=pd.DataFrame.from_dict(dict_data)
df.index=["A","B","C","D","E","F","G"]
df

ignore_index=True,起作用的轴则会标记为 0,1,….n-1
#subset 只考虑列 'a',
keep = False,即删除所有重复行
ignore_index=True,起作用的轴则会标记为 0,1,....n-1
df.drop_duplicates(subset=['a'],keep =False,ignore_index=True)

ignore_index=False,保留原来的 index name
#subset 只考虑列 'a',
keep = False,即删除所有重复行
ignore_index=False,保留原来的 index name
df.drop_duplicates(subset=['a'],keep =False,ignore_index=False)

Original: https://blog.csdn.net/u010701274/article/details/121831149
Author: 江南野栀子
Title: Pandas 模块-操纵数据(8)-去除重复行 .drop_duplicates()
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/741296/
转载文章受原作者版权保护。转载请注明原作者出处!