

python数据分析-数据清洗与整理
又开始我的好好学习之旅,这周学习数据分析,居老师日常动力!


今天要跟着罗罗攀(公众号:luoluopan1)学pandas数据清洗、合并、重塑以及字符串处理,数据均来自罗罗攀,敲棒~
1.数据清洗
处理缺失值
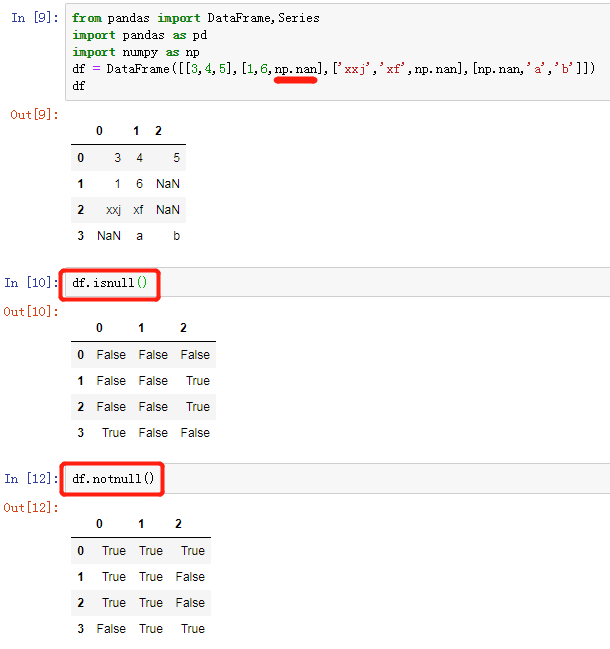
第一步:找出缺失值 主要通过 isnull和 notnull方法返回 布尔值来判断什么位置有缺失值 (注:使用juypter notebok)
from pandas import DataFrame,Series
import pandas as pd
import numpy as np
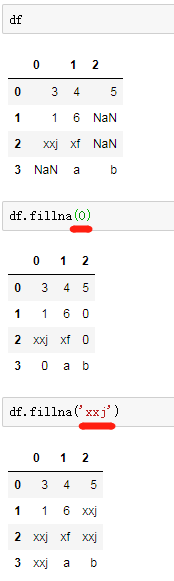
df = DataFrame([[3,4,5],[1,6,np.nan],['xxj','xf',np.nan],[np.nan,'a','b']])
df.isnull()
df.notnull()
df.isnull().sum()
df.isnull().sum().sum()

df2 = DataFrame(np.arange(12).reshape(3,4))
df2[3]=np.nan
df2.iloc[2,:]=np.nan
df2.dropna(how='all')
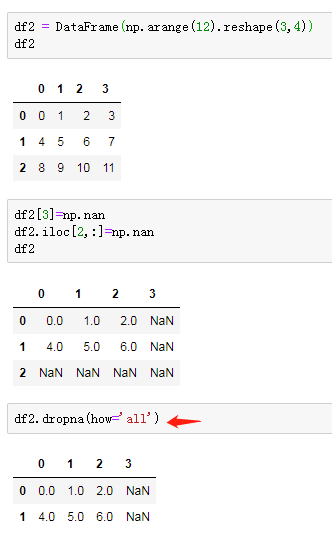
df2.dropna(how='all',axis=1)

df.fillna(0)
df.fillna?
移除重复数据
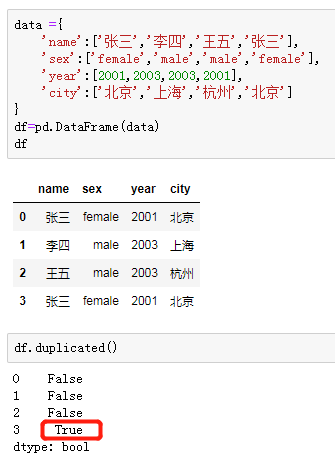
替换值

函数
map:将函数套用在Series的 每个元素中; apply:将函数要用在DataFrame的行和列上; applymap:讲函数套用在DataFrame的每个元素上 这里可以用map,也可以用apply
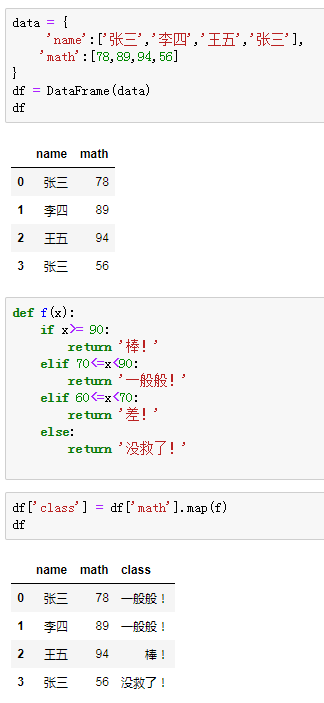
data = {
'name':['张三','李四','王五','张三'],
'math':[78,89,94,56]
}
df = DataFrame(data)
def f(x):
if x>= 90:
return '棒!'
elif 70检测异常值通常使用可视化来看不正常的数据,但不代表所有离群点都是异常值,可能他本来就是这样的 通常会用散点图来观察plot(kind='scatter') 虚拟变量在机器学习中,只有数值型的数据才能被学习,对于一些分类变量则需要转换成虚拟变量(也就是0,1矩阵,有是1,没有是0),通过get_dummies函数即可实现 df = DataFrame({
'朝向':['东','南','西','东','北','东'],
'价格':[1200,2300,2100,2900,1400,5600]
})
pd.get_dummies(df['朝向']) 对于多类别的数据而言,需要通过函数来解决,dummies没有办法直接处理 dummies = df2['朝向'].apply(lambda x : Series(x.split('/')).value_counts())
dummies = dummies.fillna(0).astype(int)
dummies2.数据合并和重塑merge合并通过merge函数按照一个或多个键将两个DataFrame按行合并起来 连接方式有:inner内连接,left左连接,right右连接,outer外连接 merge默认是inner,即返回的为交集,只连接都有的值 可以指定按什么键链接 pd.merge(amount,price,on='fruit')
pd.merge(amount,price,left_on='fruit2',right_on='fruit1') 不同的连接方式: 以上是多对一的连接,因为price的fruit都是唯一值,如果是多对多,则会出现笛卡尔积 可以通过多个键进行合并 合并时可能存在重名,默认操作是加后缀 _x 和 _y 我们也可以利用 suffixes 进行自定义 可能连接的键是在DataFrame的索引上,可通过 left_index=True 或者 right_index=True 来指定索引作为连接键 DataFrame有join方法,可以按索引合并 注:列表名不能一样,这里是value1和value2,如果一样会报错concat连接如果合并的数据没有连接键,则不能使用 merge ,可以使用 concat 方法 默认情况下concat是axis=0,即垂直连接进行堆积 也可以水平连接 这样进行连接,在pd里会生成DataFrame,类似于外连接 concat只有内连接和外连接,通过join='inner'实现内连接 通过join_axes=[]来改变索引的顺序 连接对象在结果中是无法分开的,可通过keys参数给连接的对象创建一个层次化索引 如果按列进行连接,keys就成了列索引 combine_first合并如果需要合并的两个DataFrame存在重复的列索引,可以使用combine_first方法,类似于打补丁。 4. 数据重塑两个常用方法:stack方法将DF的列"旋转"为行,unstack方法将DF的行"旋转"为列 df = DataFrame(np.arange(9).reshape(3,3),
index=['a','b','c'],
columns=['one','two','three'])
df.index.name = 'alpha'
df.columns.name = 'number'
result = df.stack()
result df.unstack是互逆的 默认下,数据重塑操作都是最内层的,也可以通过级别的编号和名称制定其他级别进行重塑 数据重塑的操作是最内层的,操作结果也是使旋转轴位于最低级别 3. 字符串处理字符串方法,通过使用pandas中str属性 字符串处理还可以用正则表达式 4. 综合案例第一步:数据来源 Iris(鸢尾花卉)数据 第二步:定义问题 按照鸢尾花特征分出鸢尾花的分类 第三步:清洗数据 (1)检查数据是否有异常 对数据进行简单描述,用describe()函数 通过unique函数检查类别有几种(数据被修改过方便做练习——《从零开始学python数据分析》) 应该是三种类别,这里有5种,可以发现类别的名字写错了,应该是Iris_setosa,Iris_virginica,Iris_versicolor这三种。 对原始数据进行修改 iris_data.loc[iris_data['class']=='versicolor','class']='Iris-versicolor'
iris_data.loc[iris_data['class']=='Iris-setossa','class']='Iris-setosa' sns.pairplot(iris_data,hue='class') 先观察第一列:有几个Iris_versicolor样本中的sepal_length_cm偏离了大部分数据 切数据均小于0.1,通过索引选取Iris_versicolor样本中sepal_length_cm值小于0.1的数据,且假设这些数据是因为单位设置问题,即*100 iris_data.loc[(iris_data['class']=='Iris-versicolor') & (iris_data['sepal_length_cm'] < 0.1),'sepal_length_cm'] *=100
iris_data.loc[(iris_data['class']=='Iris-versicolor')] 观察第二行:一个Iris_setosa样本的sepal_width_cm偏离了大部分的点 通过对Iris_setosa的花萼宽度回执直方图进行观察 为了观察的更仔细,可以发现异常值都大于2.5cm,所以先把小于2.5cm的过滤掉 (2)检查数据是否有缺失 可以发现其中花瓣宽度有5条缺失值 把缺失值删除掉 注:inplace是指在原始数据进行修改 最后对清洗好的数据进行保存,一遍后续的数据探索 第四步:数据探索 还是利用之前的散点矩阵代码,对新的数据进行可视化 还可以绘制其他的图形,如直方图
Original: https://blog.csdn.net/marraybug/article/details/118341877
Author: marraybug
Title: 【python数据分析】-数据清洗与整理python数据分析-数据清洗与整理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/741102/
转载文章受原作者版权保护。转载请注明原作者出处!