

数据分析-数据预处理
处理重复值
duplicated( )查找重复值
import pandas as pd
a=pd.DataFrame(data=[['A',19],['B',19],['C',20],['A',19],['C',20]],
columns=['name','age'])
print(a)
print('--------------------------')
a=a.duplicated()
print(a)
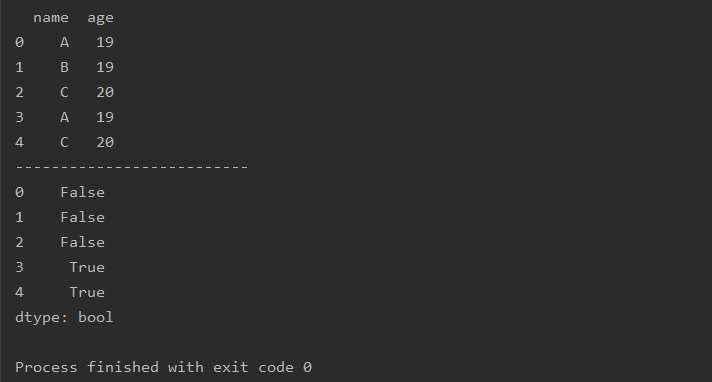

只判断全局不判断每个
any()
import pandas as pd
a=pd.DataFrame(data=[['A',19],['B',19],['C',20],['A',19],['C',20]],
columns=['name','age'])
print(a)
print('--------------------------')
a=any(a.duplicated())
print(a)

drop_duplicates( )删除重复值
参数inplace 是否在原数据上修改
import pandas as pd
a=pd.DataFrame(data=[['A',19],['B',19],['C',20],['A',19],['C',20]],
columns=['name','age'])
print(a)
print('--------------------------')
b=a.drop_duplicates(inplace=False)
a.drop_duplicates(inplace=True)
print(a)
print('--------------------------')
print(b)

处理缺失值
NaN表示缺失值
import pandas as pd
a=pd.read_csv(r'text.csv')
print(a)
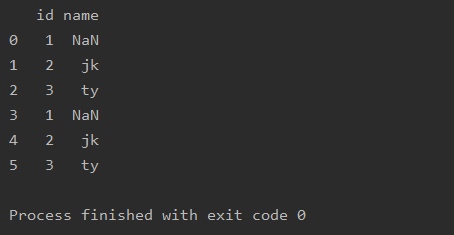
isnull( )判断所有位置元素是否缺失
import pandas as pd
a=pd.read_csv(r'text.csv')
print(a.isnull())
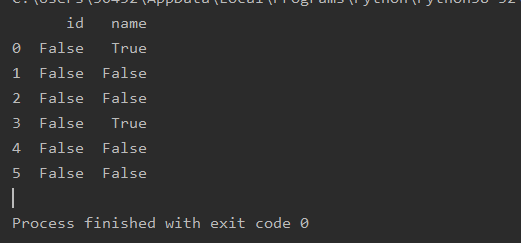
any( )判断行列元素是否缺失
import pandas as pd
a=pd.read_csv(r'text.csv')
print(a.isnull().any())
print(a.isnull().any(axis=1))
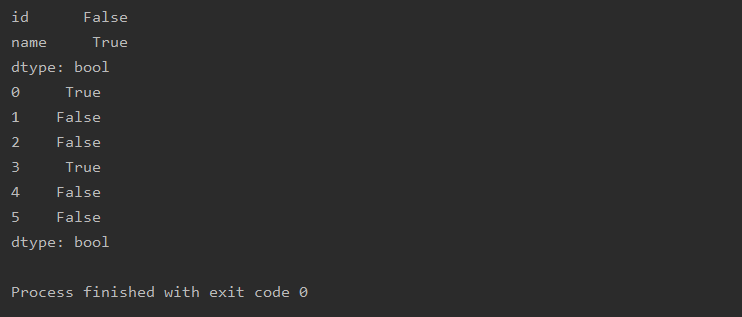
del( )dropna( )删除
import pandas as pd
a=pd.read_csv(r'text.csv')
del a['name']
print(a)
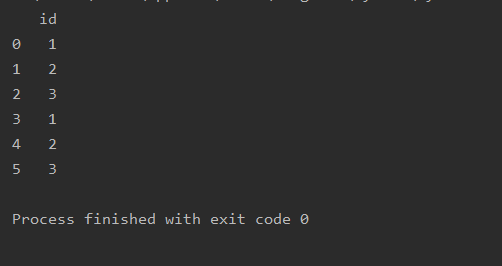
import pandas as pd
a=pd.read_csv(r'text.csv')
b=a.dropna(axis=0)
print(b)
c=a.dropna(axis=1)
print(c)
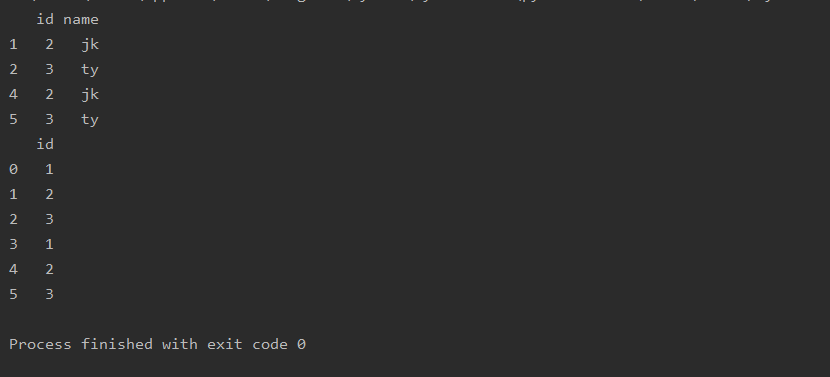
del( )删除指定列,dropna( )删除含有缺失值的列(行)
fillna( )缺失值填补
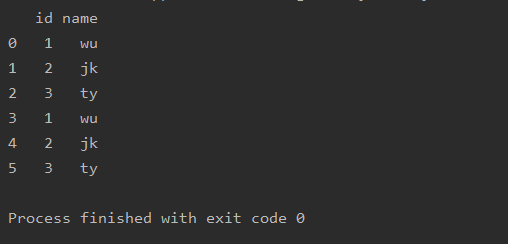
import pandas as pda=pd.read_csv(r'text.csv')a=a.fillna('wu')print(a)
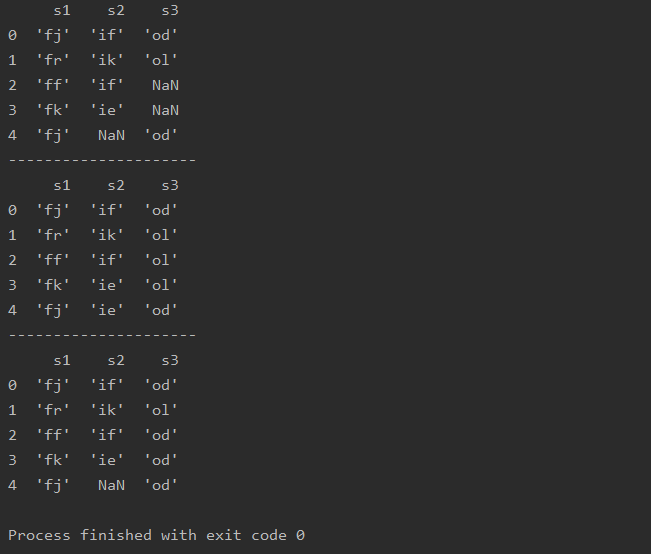
根据上(下)数据填充
pad / ffill: 按照上一行进行填充
backfill / bfill: 按照下一行进行填充
import pandas as pda=pd.read_csv(r'text.csv')print(a)print('---------------------')b=a.fillna(method='pad')print(b)print('---------------------')c=a.fillna(method='bfill')print(c)
数值型数据填充
平均值mean()
每列的平均值填充
import pandas as pda=pd.read_csv(r'text.csv')
print(a)
print('---------------------')
a=a.fillna(a.mean())
print(a)
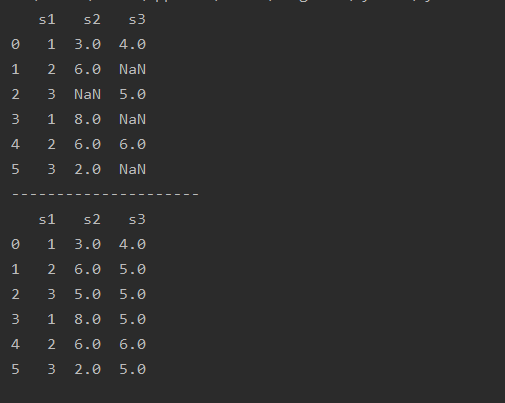
中位数median( )
import pandas as pd
a=pd.read_csv(r'text.csv')
print(a)print('---------------------')
a=a.fillna(a.median( ))
print(a)
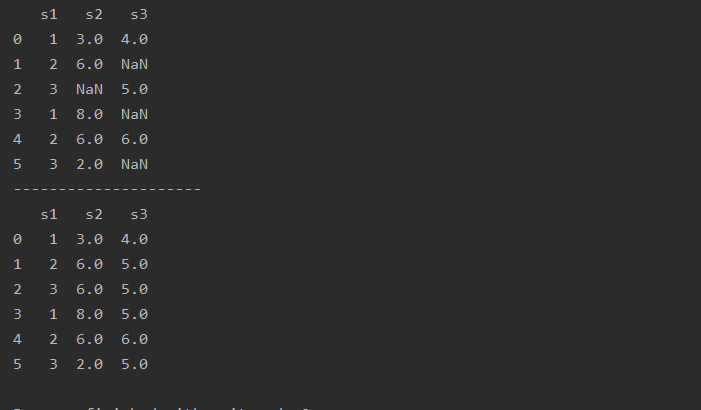
字符型数据填充
众数mode( )
import pandas as pd
a=pd.read_csv(r'text.csv')
print(a)
print('---------------------')
for i in a.columns:
a[i] = a[i].fillna(a[i].mode()[0])
print(a)

数据变换
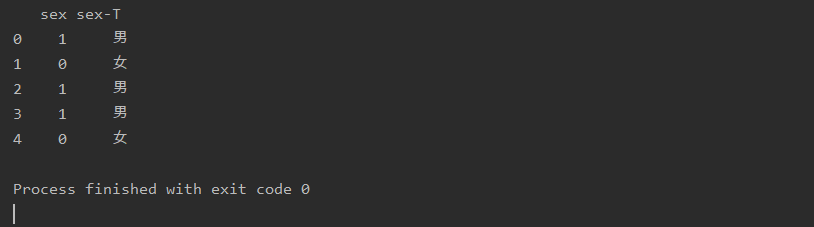
map( )数据转换
import pandas as pd
data={'sex':[1,0,1,1,0]}
a=pd.DataFrame(data)
a['sex-T']=a['sex'].map({1:'男',0:'女'})
print(a)
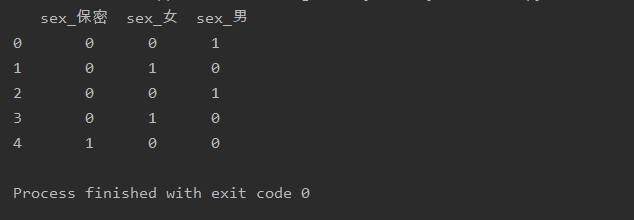
哑变量
import pandas as pd
data={'sex':['男','女','男','女','保密']}
a=pd.DataFrame(data)
a=pd.get_dummies(a)
print(a)
Original: https://blog.csdn.net/weixin_42403632/article/details/121435675
Author: 小旺不正经
Title: 数据分析-数据预处理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/740893/
转载文章受原作者版权保护。转载请注明原作者出处!