

前言:pandas主要分为两大块,Series和datafram,下面对这两块分别进行总结。其次,在看该篇文章时候,需有一点numpy的知识,后面我都会将其类型转换的numpy的数据类型进行处理。
目录
- 1、Series
* - 1.1、创建Series
– - 1.2、切片和索引
– - 1.3、Series获取index和value
- 1.4、修改Series的和value
- 2、DataFrame
* - 2.1、读取csv文件
- 2.2、创建一个DataFrame
– - 2.3、修改DataFrame索引
– - 2.4、合并两个DataFram
– - 2.5、删除DataFrame
– - 2.6、DataFrame基础属性
- 2.7、DataFrame排序
– - 2.8、DataFrame取值
– - 2.9、DataFrame的str(常用函数)
– - 3.0、缺失值处理
– - 3.1、DataFrame分组(groupby)
– - 3.2、日期处理
– - 3.3、日期重采样(resample)
–
1、Series
1.1、创建Series
1.1.1、通过列表创建
data = pd.Series(np.arange(10))
dd = pd.Series([1,2,3,4],index=list('abcf')) #还可以指定索引
结果:


1.1.2、通过字典创建
#推导式创建一个字典
a = { string.ascii_uppercase[i]:i for i in np.arange(10)}
装换成Seriers
data = pd.Series(a)
结果:

注意:Seriers中,index的数量必须和值的个数一样多,但是可以此时给的index可以和之前的一样,也可以不一样,此时,不一样的将以nan填充。
eg:

1.2、切片和索引
1.2.1、通过切片与步长进行数据获取

; 1.2.2通过索引进行数据获取

这里data[[1,2,3]]和data[[‘F’,’G’,’H’]]等价,应为通过1,2,3也可以唯一的确定数据。这里的1,2,3表示坐标。
这里特别注意,若索引也为数值的话,当在使用data[[1,2,3]]这种写法时候,这里的1,2,3不在表示坐标,而是表示键

可以看到这里的2,3,4不是去的第2,3,4坐标的位置的值,而是取的对应键的值。
1.2.3、布尔索引
通过布尔进行数据获取:

; 1.3、Series获取index和value
获取index:
s = data.index ##这里获取的s的类型为RangeIndex,可以将其装换位ndarray类型
s = s.to_numpy() ##转化为numpy类型
获取value:
s = data.values #这里获取的类型直接就位ndarray类型
1.4、修改Series的和value
data[:]=[要修改的值]
2、DataFrame
2.1、读取csv文件
准备数据:在一个csv文件中填入如下数据:

读数据:
data = pd.read_csv("./c.csv") #这里读出来的数据类型为DataFrame
在读取csv文件的时候我们可以指定一些参数。
index_col=1 #指定以那一列作为行索引,这里1表示以第1列作为索引
#不指定会默认生成以0开头的index作为索引。
encoding='gbk' #指定以什么编码格式解析数据,这里以gbk
看一下data:

上面DataFrame和上面为dataFrame总的列索,用columns表示。最左边为行索引,用index表示。
2.2、创建一个DataFrame
2.2.1、直接通过列表创建
data = pd.DataFrame(np.arange(12).reshape(3,4)) #创建一个3行4列的dataFrame

DataFrame对象既有行索引,也有列索引:
行索引:表明不同行,横向索引,叫index,0轴,axis=0
列索引:表明不同列,纵向索引,叫columns,1轴,axis= 1
注意:通过列表创建时如果是二维的。那么创建的dataframe就和原list的格式一样,但若是一维数,那么它每个数等价为一维数据。如下所示。
二维:
data = pd.DataFrame([[1,2,3],[4,5,6]])
data

一维:
data = pd.DataFrame([1,2,3])
data

2.2.2、通过字典创建
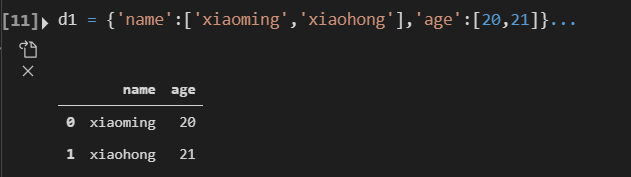
d1 = {'name':['xiaoming','xiaohong'],'age':[20,21]}
df = pd.DataFrame(d1)
df
2.2.3、通过列表字典创建
d1 = [{'name':'xiaohong','age':'32'},{'name':"xiaohong",'tel':10086}]
df = pd.DataFrame(d1)
df

2.3、修改DataFrame索引
2.3.1、重设索引:
data.reset_index(inplace=True) #该方法会将索引列提出来,并重新生成新的以0开始编号的index.如果不想将索引列提出来,可以使用drop参数,设置为False即可
2.3.2、修改行索引或列索引某一个值:
data.rename({'b':'first'},axis=1,inplace=True) #修改columns某个值为另一个值
data.rename({0:'修改'},axis=0,inplace=True) #修改index某个值为另一个值
结果:

2.3.4、插入一列
直接写入要插入的columns值即可:
data["插入"]=np.nan

2.3.5、插入一行
通过列表字典形式插入:
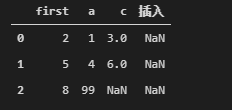
data = data.append([{"first":8,'a':99}],ignore_index=True)
#其中ignore_index为True会让索引重新从0开始编号,为False为添加索引号为0,不建议这样使用。
通过Series插入:
dd = pd.Series([1,2,3,4],index=list('abcf'))
res1 = res.append(dd,ignore_index=True)

在通过Series插入的时候实质和字典一样,都会进行columns查询,若又则对应位置插入,若没有,则创建新的一列,上一个表没有该数据则填为nan.
2.4、合并两个DataFram
2.4.1、水平合并
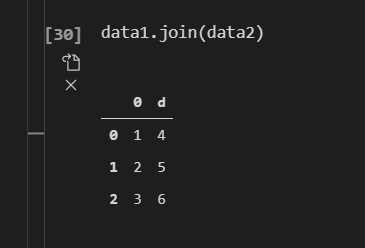
data1.join(data2) #会将行标签相同的放在一起,若data1的标签大于data2个数,则data2中在data1没有的标签行会以nan显示,若data1的小于data2的index数量,那么data2多余的index将会被截掉。

2.4.2、垂直合并1(直接在后拼接append)
通过append方法进行合并:
res = pd.DataFrame() #这种方法可以进行迭代,在合并的时候会自动检查columns,若上一个表不存在会创建一个columns,上一个表因为没有该columns,值会默认全为nan
res = res.append(data,ignore_index=True)
res = res.append(data1,ignore_index=True)


2.4.3、垂直合并2(根据某一列键进行合并merge)
2.4.3.1、内连接(inner)
使用merge进行合并,会指定一个on参数,该参数指定以某一列的键值进行合并,如果两边根据同一键进行合并时,出现了不同的其他columns,那么会生成一个x_XX,和一个y_XX.
eg:有两组数据:
res:

data:

通过b这一列进行合并:
res.merge(data,on="b")

上述结果解析:因为通过b这一列键进行合并的,在res中,b这一列数据有两列为1,而data中有一列为1,因此,res中这两列1将会和data中这一列进行匹配,因此res就会将1这两列拿出来,然后将data中这一列拿出来,然后res中取出来的每一行和data中取出来的这一行进行合并,因此合并完之后总共的数据就是两列,这里因为res和data中都有a,因此为了避免数据的冲突,这里会自动生成x_a.y_a.
2.4.3.2、外连接(outer)
合并参数how指定
在进行合并的时候,如果不指定how参数,那么默认会是inner方式,就是去交集,如上面的合并。另外还可以指定outer,即以并集的方式进行合并:
eg:
data:

res:

data.merge(res,on="b",how='outer')

2.4.3.3、左连接(left)
左连接以左边数据为准,然后去找右边数据,如果有,则进行合并,如果没有,就进行舍弃:
eg:
data:

res:

左连接:
data.merge(res,on="b",how='left')

2.4.3.4、右连接(right)
同理,右链接将以右边数据为准:
eg:
data:

res:

右连接:
data.merge(res,on="b",how='right')

2.4.3.5、concat
1.2 横向表拼接(行对齐)
1.2.1 axis
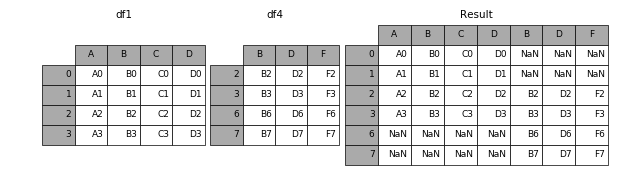
当axis = 1的时候,concat就是行对齐,然后将不同列名称的两张表合并
result = pd.concat([df1, df4], axis=1)
加上join参数的属性,如果为’inner’得到的是两表的交集,如果是outer,得到的是两表的并集。
result = pd.concat([df1, df4], axis=1, join='inner')
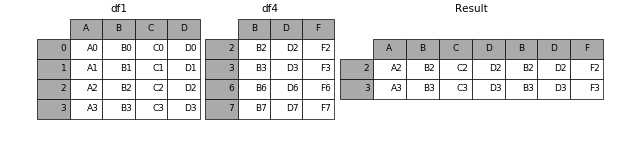
如果有join_axes的参数传入,可以指定根据那个轴来对齐数据
例如根据df1表对齐数据,就会保留指定的df1表的轴,然后将df4的表与之拼接
result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])

更多关于concat的使用请参考这篇文章:
连接
2.5、删除DataFrame
2.5.1、删除某一列
df.drop(['age'],axis=1) #['age']代表选中age这一列,也可以使用labels属性
#等价于df.drop(axis=1,labels='age')
2.5.2、删除某一行
d1 = [{'name':'xiaohong','age':'32'},{'name':"xiaohong",'tel':10086}]
df = pd.DataFrame(d1)
df.drop([0],axis=0,inplace=True) # [0]表示选中这一行,也可以使用labels,等价于labels='0'
df.reset_index(drop=True,inplace=True)
df
注意,这里删除某一列之后要记得进行重设索引,还有这里要记得使用drop参数,否者会在原数据中新增加一列。

2.6、DataFrame基础属性
df.shape #行数 列数
df.dtypes # 列数据类型
df.ndim # 数据维度
df.index # 行索引
df.columns # 列索引
df.values #对象值,二维的ndarray
df['某列属性'].unique() # 取唯一的值,只有Series含有该方法
df.head(5) # 显示前5行
df.tail(5) #显示后5行
df.info() # 显示数据信息,可以查是否为空,那一列有数据缺失
df.describe() # std:标准差。mean:均值,min:最小值,25%:1/4中位数,50%:中位数,75%:3/4中位数,max:最大值
2.7、DataFrame排序
2.7.1、根据某一列数据进行排序
res.sort_values(by='a',ascending=False,inplace=True)
res
ascending参数是定是否升序。
2.8、DataFrame取值
2.8.1、切片
在dataFrame数据结构中我们也可以进行切片,而且切片还可以通过指定infdex的名字进行(index不是数值型)
通过当前位置进行切片:
res[1:6:2] #1表示起始,6表示终止,2表示步长。

通过index名进行切片:
res['a':'f':1]

2.8.2、索引(loc,iloc)及其强大
首先说一下loc和iloc的区别,后面就直接使用loc进行演练,因为我比较喜欢使用loc,而且用起来也比较顺手。大家可以根据自己的喜好自由选择。
语法:
loc[行索引,列索引] #
loc和iloc其实在使用上区别不大,唯一的区别就在于loc是通过标签进行索引的,而iloc是通过位置进行索引的。举个例子:

如上数据:
我们可以使用loc使用标签(abcd)这些标签进行索引,但是就不能使用位置进行索引了。
res.loc['a':'f',:] #正确,loc通过标签进行索引
res.loc[1:4,:] # 错误,loc只能通过标签进行
res.iloc['a':'f',:] #错误,iloc只能通过位置进行索引
res.iloc[1:4,:] #正确,iloc通过位置进行索引
以上就是loc和iloc的区别,下面将以loc进行用法讲解,iloc其实也试用,只需要将对应的标签换成位置坐标即可。
2.8.2.1、取行取列
不适用loc函数的时候,方括号写数组表示取行,方括号写字符串,表示取列,但是在使用loc函数的时候,方括号不管是写数组还是写字符串,都表示取行,这是因为在使用loc函数的时候,如果只写一个参数,他会默认是逗号后面为空,也就是所有列,这样看来,就是取该行的所有列。
eg:
针对数据:

res[:'a'] #是取行

res['a'] #是取列

但是在使用loc函数的时候:
res.loc['a'] #表示取行

res.loc[['a','s']]

若要取列,只需要在loc中通过逗号分割填入列名即可:
res.loc[['a','s'],'d']

2.8.3、pandas多条件取值
data = pd.DataFrame([[1,2,3],[4,5,6],[7,8,6]])
data[(data[2]>3)&(data[1]<8)] < code></8)]>
这里注意只能使用&不能使用and,使用and会报错。
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
2.9、DataFrame的str(常用函数)
2.9.1、cat字符串拼接
cat() 拼接字符串,在使用此方法时必须保证所操作的该列为str类型,否则会报 Can only use .str accessor with string values!的错误!
因此在使用cat函数时,可以先试用astype进行转一下:
res['e'] = res['e'].astype(np.str)
res.loc[:,'e'] = res.loc[:,'e'].str.cat(['1','2','3','4','5','6','70'],sep='|')
sep表示使用什么作为分隔符

2.9.2、split() 切分字符串
res.loc[:,'d'] = res.loc[:,'d'].str.split('|') #在使用之前也需要保证操作列为str类型

2.9.3、get()获取指定位置的字符串
res['d'].str.get(1)

2.9.4、join() 对每个字符都用给点的字符串拼接起来
对于数据:

使用|进行凭借e
res['e'] = res['e'].str.join('|')

2.9.5、contains() 是否包含表达式
res['d'].str.contains("4")

2.9.6、replace() 替换
res['e'] = res['e'].str.replace('|','_')

2.9.7、wrap() 在指定的位置加回车符号
res['e'] = res['e'].str.wrap(2)

3.0、缺失值处理
3.0.1、判断是否含nan
pd.isnull(res)

3.0.2、选中a列含有nan的行
res[pd.isnull(res['a'])]
3.0.3、删除nan
res.dropna(axis=0,how='any') #只要含有nan就删除这一行或这一列,删除行还是列,有axis指定。how若为any表示只要已出现nan就删除该行或该列,all表示该行该列全部为nan才进行删除
3.0.3、填充nan
在填充数据之前先来看几个重要的数:
res.describe():

其中的数据都是跳过nan进行统计的。
第二种方式获取均值
res['a'].mean() #通过mean方法进行获取
3.0.3.1、全填充
res.fillna(axis=0,method='ffill') #指定轴 使用前一个填充nan
ffill使用前一个填充,bfill使用后一个填充
res.fillna(axis =0,value=0) #使用指定值填充
3.0.3.2、指定某一列填充
res['a'] = res['a'].fillna(value=res['a'].mean())

3.0.4、异常0处理
对于异常0,我们通常把它变为nan,因为变成nan之后,在使用diecribe和mean等方法是,就不会统计该项,非常方便。
res[res==0]=np.nan
3.1、DataFrame分组(groupby)
groupby:返回的是一个可迭代对象:内置了许多可用的方法.
3.1.1、sum
dd = data.groupby(by='订单号').sum() #sum函数统计每个分组每项数据的和,如果遇到字符串,则自动忽略该项。
返回的是一个DataFrame
3.1.2、count
dd = data.groupby(by='订单号').count() #count统计分组之后每组的个数,会自动忽略nan
3.1.3、mean
dd = data.groupby(by='订单号').mean() #统计每个分组的均值
3.1.4、describe
dd = data.groupby(by='订单号').describe() #统计每个分组的描述信息,包括最大值,最小值,均值、方差等
3.1.5、遍历每个分组
for i in data.groupby(by='订单号'):
print(type(i))
break
返回是一个元组: <class 'tuple'></class>
(“分组的组名” ,该组名对应的数据,为DataFrame格式)
3.2、日期处理
3.2.1、生成日期序列
pd.date_range(start=None,end=None,periods=None,freq='D')
start表示起始时间
end 表示结束时间
period 表示 时间段,一共的个数,常常和start配合使用,而不和end在一起使用。
生成一个时间序列:
pd.date_range(start='2020-3-1',end='2021-4-4',freq='D') #在这里start可以写"20200301"
#或2020-3-1“”或“2020-03-01”都是可以识别的。

关于D的参数:

3.2.2、格式化日期序列
3.2.2.1、转化字符串到标准格式
比如我们现在有这样一组时间序列:
data:

我们要将其date转换成pandas中标准的datetime64类型,我们可以调用to_datetime函数,并指定其格式化的方式:
data1['date'] = pd.to_datetime(data1['date'],format="%Y年%m月%d号")
#to_datetime功能及其强大,还可以直接将一个时间戳转化为标准date格式

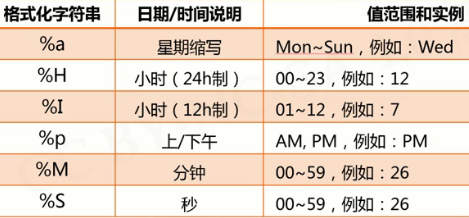
python时间格式化常用标语请参考如下:

3.2.2.2、转化时间戳到标准格式
比如我们有如下数据:
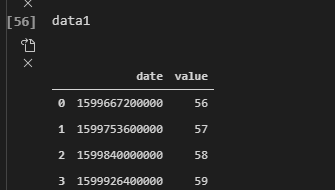
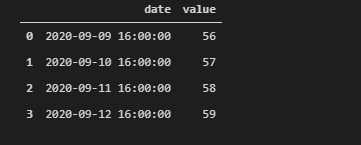
data1['date'] = pd.to_datetime(data1['date'],unit='ms',origin=pd.Timestamp('1970-01-01 00:00:00'))
#unit 表示时间戳的单位
#origin 表示起始时间
3.3、日期重采样(resample)
重采样:指的是将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据为降采样,低频率转化为高频率为升采样。
假设现在有一组这样的数据:

; 3.2.1、降采样
以采样值作为当前前,不进行累计求和。
hh = data.resample("3D").asfreq()#3D表示以每三天进行采样

统计个数:
hh = data.resample("3D").count()

统计求和,将所有采样值进行求和:
hh = data.resample("3D").sum()

统计求均值:
hh = data.resample("3D").mean()

3.2.2、增采样
hh = data.resample("0.5D").asfreq() #以每半天进行采样

没有的数据会填为nan。
Original: https://blog.csdn.net/sinat_33909696/article/details/117393138
Author: 思禾
Title: Pandas这一篇就够了(建议收藏)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/740093/
转载文章受原作者版权保护。转载请注明原作者出处!