

前言
本文主要介绍Pandas中两个重要的数据结构:Series 和 DataFrame。二者在pandas数据分析与处理中是使用最多的数据结构。
因此,学习Pandas这两个重要的数据结构,对于使用Python进行数据分析与处理非常重要。
Series
Series介绍
Series是一个有索引(或者说标签)的由同一类型数据组成的一组数据,其数据是一维的。
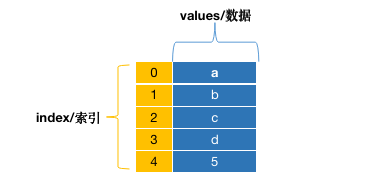

Series创建
Series创建:使用pd.Series()创建对象。
pd.Series(
    data=None,#可以为列表、元组、字典、numpy.ndarray
    index=None,#可省略,省略后默认从0开始创建
dtype=None,
name=None,
copy=False,
fastpath=False,
)
显示给出index则为显式索引,没有显式给出索引index则系统默认提供一个从0开始递增的索引。
显式索引:即定义/创建时给出的index。
隐式索引:系统默认提供一个从0开始递增的整数索引。
例子-新建Series,给定索引index
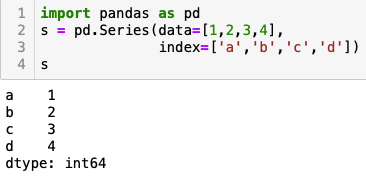
上例,显式索引为a、b、 c、 d ,隐式索引为 0、 1、 2、 3.
例子-新建Series,省略index
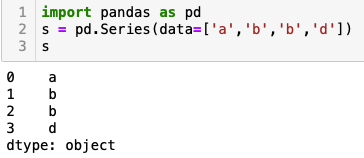
未给出显式索引,系统会自动创建从0开始递增的索引。
Series属性
Series.index 获取/查看索引(index)部分
Series.values 获取/查看数据(data)部分
查看index和values属性

Series操作
索引访问与切片
- Series支持显示/隐式index索引访问数据与切片操作。
- Sereis 提供索引方式iloc和loc访问数据。
显式/隐式index数据访问及切片
s = pd.Series(data=list('春眠不觉晓'),
index=list('abcde'))
print(s['c']) # 显式index读数据
print(s[2]) # 隐式index读数据
print('--------')
print(s['a':'d']) #显式index切片
print(s[0:3]) #隐式index切片

⬆️注意区分Series显式index切片和隐式index切片的不同之处,显示索引是闭合,隐式索引切片同Python切片。
索引方式iloc和loc
- Series.loc[ 显式索引 ]
- Series.iloc[ 隐式索引 *]
s.loc['c'] #Series.loc-显式索引
s.iloc[2] #Seried.iloc-隐式索引
s.loc['a':'c'] #切片
s.iloc[0:2] #切片

loc和iloc切莫混用显式和隐式索引,否则会报错。

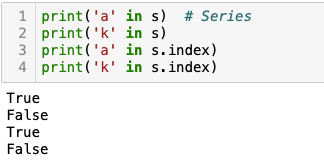
index支持in判断
Series可使用显式index做in操作,判断Series中有无该index。
更新index次序
Series.reindex(index=None)
调整显式index次序,返回一个新的Series,reindex不改变原Series对象。
此外更新的index为原来已存在的,如果index不存在则对应的value为NaN。

DataFrame
DataFrame介绍
DataFrame 是一种类似表格的二维数据结构的对象。DataFrame 既有行索引也有列索引,它可以被看做是一组共用index的Series组成的二维数据。

DataFrame创建
DataFrame创建的根据数据的来源,可以将DataFramec创建分为两种
第一种:直接创建/定义 (这种方式实际很少用)
pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
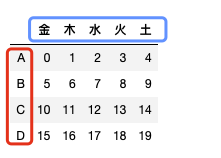
例-直接创建/定义
import pandas as pd
import numpy as np
x = pd.DataFrame(data=np.arange(0,20).reshape(4,5),
index=list('ABCD'),
columns=list('金木水火土'))
第二种:从外部文件中读取/导入(常用方式)
panda可以导入以下各种数据格式:
- CSV 2.EXCEL 3.SQL
4.HTML 5.Json 6.pdf 等
对应的pandas方法形如pd.read_xxxx(),如读取csv为pd.read_csv()、excel为pd.read_excel()。
#从CSV
pd.read_csv(
filepath_or_buffer: Union[str, pathlib.Path, IO[~AnyStr]],
sep=',',
delimiter=None,
header='infer',
names=None,
    index_col=None
    )
例-从文件中导入

DataFrame属性
- index 行索引
- columns 列名/列索引名
- shape 数据形状
- dtype 查看数据类型
例-查看上图DataFrame的属性
DataFrame操作
访问数据
访问整行或整列数据以及访问指定行列位置的数据,访问数据可分为两类,即 通过列columns访问和 通过index行访问。
通过列访问:根据使用列名的方式不同可以分为:列名 作为下标访问或者列名 作为属性访问
例-列名作为下标访问数据
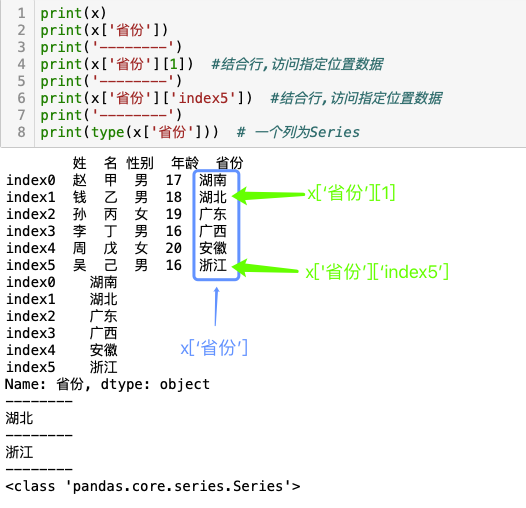
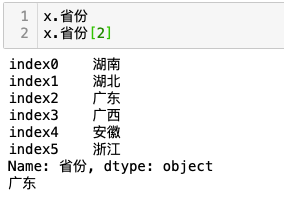
例-列名作为属性访问数据
通过行访问: loc[显式index], iloc[隐式index],以及ix[]
iloc行用隐式index访问行,即行为整数
loc 行用显式名访问(如果定义了行名)
ix 混用,即行列可以用隐式或者显式(该方法已过时)
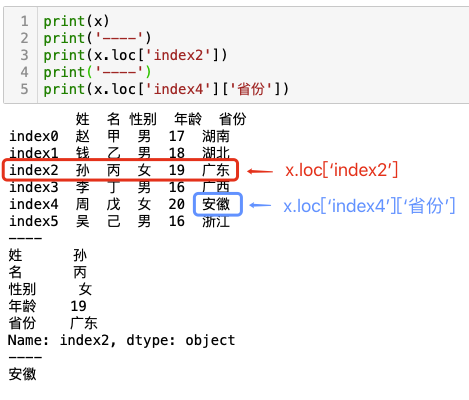
例-loc[显式index]访问行数据
例-使用iloc[隐式index]访问行数据
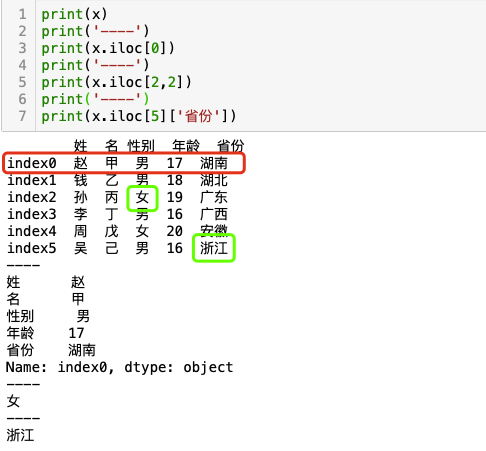
例-ix[行索引 ,列索引],访问指定位置数据
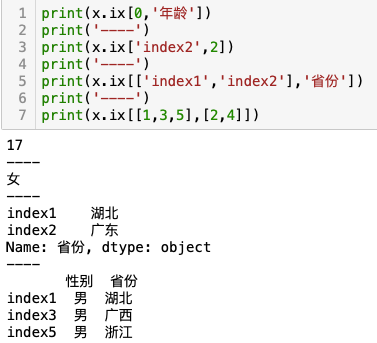
由于ix的方式已经过时,因此通过行与列访问指定数据,一般建议loc 和 iloc的方式。
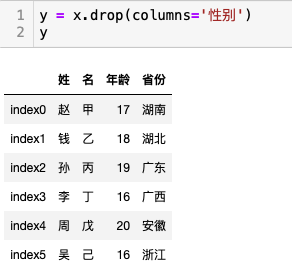
删除数据
使用drop()方法删除数据。drop()方法默认不修改数据本身,如果inplace=True 则会修改原数据。
x.drop(
labels=None,
axis=0,
index=None,
columns=None,
level=None,
inplace=False,
errors='raise',
)
例-删除指定行

例-删除指定列
–End–

分享
Original: https://blog.csdn.net/weixin_42147780/article/details/125135496
Author: 金融科技自习生
Title: Pandas数据分析(上)|一文读懂Series和DataFrame
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/739864/
转载文章受原作者版权保护。转载请注明原作者出处!