

基本面的量化分析与投资的回报 – 上篇
基本面分析
百度上给出的定义:基本分析法是从影响证券价格变动的敏感因素出发,分析研究证券市场的价格变动的一般规律,为投资者作出正确决策提供科学依据的分析方法。主要有三个层次:一是宏观社会经济类影响因素; 二是行业(或产业)类影响因素; 三是公司类影响因素。三类影响证券价格的因素构成证券投资基本分析的三个部分,即宏观经济分析、行业分析和微观企业 (公司) 分析。 我的以下分析主要集中在企业的数据上。
公司的基本面分析和打分
我的打分系统主要涉及到10个方面:营收,营利增长率,毛利率,期间费用,库存周转率,经营性现金流,净资产收益率,总资产收益率,市净率,市盈率。满分为一百分,分数越高,代表着公司的整体基本面越优秀(前提假设是公司没有做假账)。整套打分系统的源代码是由我的量化导师Cutehand所制作,我只是后期加工而已,如有需要请关注联系我的导师。所有的数据都是从Tushare上获取的,请自行去其官网进行注册,按照自己的需求来进行购买充值。
代码及分析 – 基础数据
首先说一下本代码是 .ipynb格式,也就是我们说的Jupyter Notebook格式。 另外我的代码分析不构成任何的投资推荐,请斟酌!
import pandas as pd
import numpy as np
import tushare as ts
import time
from datetime import datetime as dt
from pyfinance import TSeries
token = '你的tushare密钥'
ts.set_token(token)
pro = ts.pro_api(token)
- 首先我们来读取我过去根据我导师的加工后的代码所获取的每个季度,A股上市公司的经营情况的打分。
df_20214 = pd.DataFrame(pd.read_csv("D:\\BaiduNetdiskWorkspace\\股票候选\\季度3连涨候选人_2021年第肆季.csv", encoding='GBK', index_col=0))
df_20221 = pd.DataFrame(pd.read_csv("D:\\BaiduNetdiskWorkspace\\股票候选\\季度3连涨候选人_2022年第壹季.csv", encoding='GBK', index_col=0))
df_20222 = pd.DataFrame(pd.read_csv("D:\\BaiduNetdiskWorkspace\\股票候选\\季度3连涨候选人_2022年第贰季.csv", encoding='GBK', index_col=0))
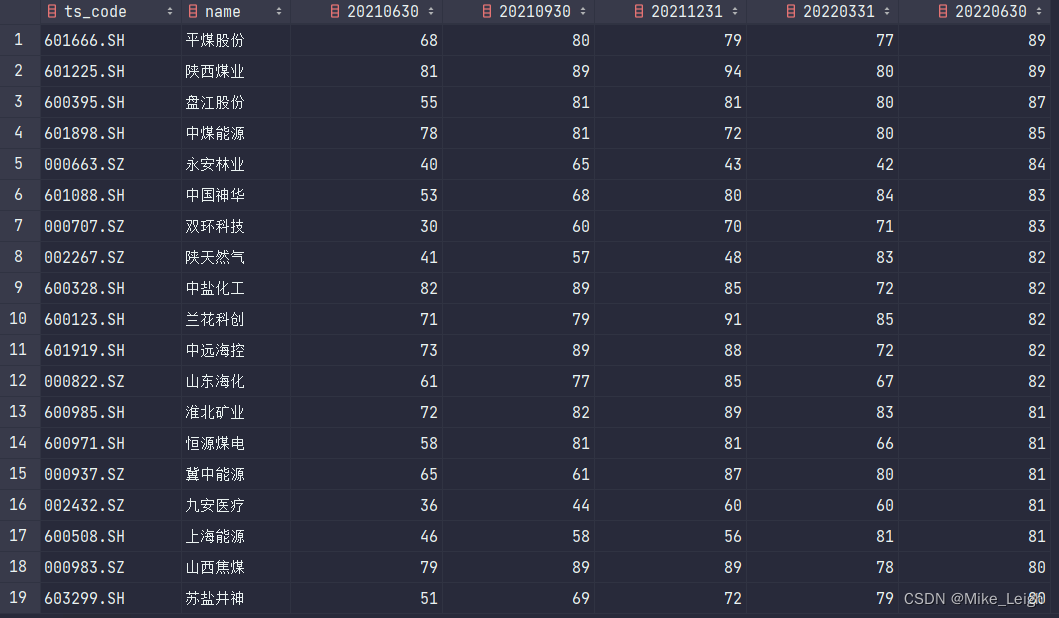

2. 其次我们看看这三张表里面,每张表大概有多少只股票。
len(df_20214),len(df_20221),len(df_20222)输出分别为179,509,594。3. 当我们把分值缩小至66分以上,它们的输出缩小为55,105,132。
df_20214_66 = df_20214[df_20214[df_20214.columns[-1]] > 66]
df_20221_66 = df_20221[df_20221[df_20221.columns[-1]] > 66]
df_20222_66 = df_20222[df_20222[df_20222.columns[-1]] > 66]
- 我们来看看在过去的半年里表现一直很亮眼的候选人的名单:
set_stocklist = set(list_20214) & set(list_20221) & set(list_20222)
df_result_list = pd.DataFrame({'ts_code':list(set_stocklist)})
df_result = pd.merge(df_result_list, df_20222, on='ts_code')
df_result = df_result.sort_values(by=df_result.columns[-1], ascending=False).reset_index(drop=True)
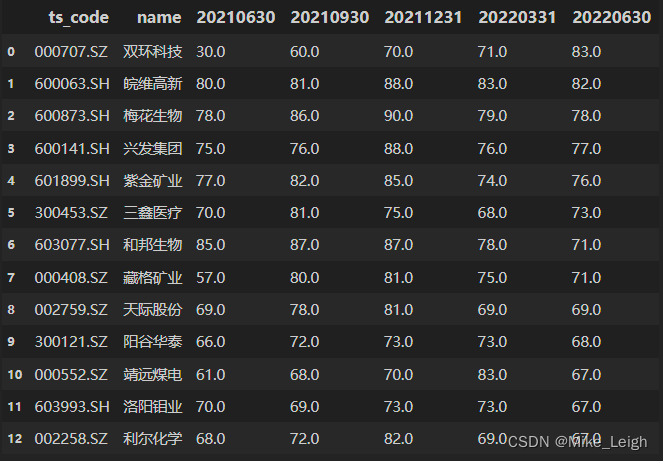
5. 截至到这里我们发现,在2021年~2022年中的表现来看,我们的候选人从我的3张表中筛选出来的 概率只有10%
代码及分析 – 股票行情
- 以下的展示代码可以通过导师的这个帖子来学习获得,请自行阅读获取。
- 首先我们来封装一个从tushare上获取数据的并以时间排序的数据。
def get_data(code,start='2021-01-01',end=''):
if code.startswith('399'):
df=pro.index_daily(ts_code=code,start_date=start,end_date=end)
else:
df=ts.pro_bar(code,start_date=start,end_date=end,adj='qfq',freq='D')
df=df.sort_values('trade_date', ascending=True)
df.index=pd.to_datetime(df.trade_date)
ret=df.close/df.close.shift(1)-1
return TSeries(ret.dropna())
- 将重要的指标进行封装,有什么不明白的地方请参阅本贴。还有一个可能大家会遇到的问题就是计算标准差这里,很多指标会用到它,但是设计的时候又不让大家传
freq=的参数。建议大家pip install pyfinance库后,去pyfinance的文件夹找一个叫做returns.py的文件,把牵扯到anlzd_stdev()的公式,统统将参数freq=250进行固定年化设置。
def performance(code):
tss=get_data(code)
benchmark=get_data('399300.SZ').loc[tss.index]
dd={}
dd['年化收益率']=tss.anlzd_ret()
dd['累计收益率']=tss.cuml_ret()
dd['alpha']=tss.alpha(benchmark)
dd['beta']=tss.beta(benchmark)
dd['年化标准差']=tss.anlzd_stdev(freq=250)
dd['下行标准差']=tss.semi_stdev(freq=250)
dd['最大回撤']=tss.max_drawdown()
dd['信息比率']=tss.info_ratio(benchmark)
dd['特雷纳指数']=tss.treynor_ratio(benchmark)
dd['夏普比率']=tss.sharpe_ratio()
dd['索提诺比率']=tss.sortino_ratio(freq=250)
dd['calmar比率']=tss.calmar_ratio()
df=pd.DataFrame(dd.values(),index=dd.keys()).round(4)
return df
- 最后将分析逻辑进行封装,获取最后的分析数据矩阵。
def analysis():
df=pd.DataFrame(index=performance('600110.SH').index)
name = df_result.name.values[:]
code = df_result.ts_code.values[:]
stocks = dict(zip(name,code))
for name,code in stocks.items():
try:
df[name] = performance(code).values
except:
continue
return df
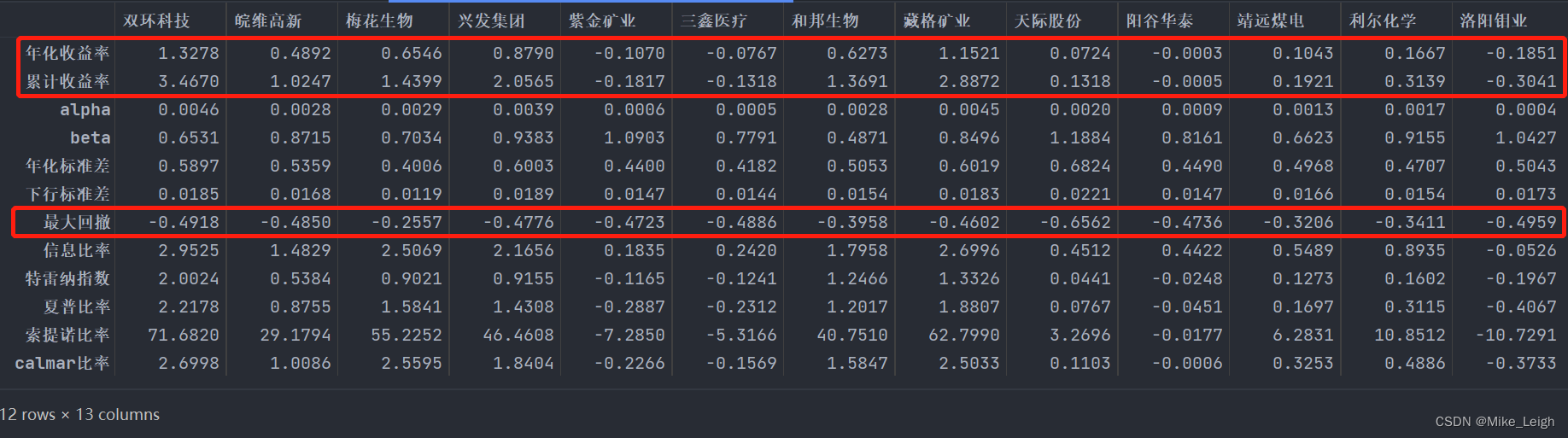
- 最终的输出的结果是这样的:
总结
- 从我们的最终结果来看,这13支股票的最大回撤相当的惊人。不难看出最近大A表现得非常难看,与大环境有很大的关系:欧洲打仗,能源暴涨,通货膨胀,国内疫情,最重磅的还有美国持续大力度加息。我们其实是可以通过对大盘的数据进行分析来规避一定的损失,在后期我希望我有机会可以跟大家分享我的理解和心得。
- 这次分析我们有拿未来数据来套娃,因为毕竟基本面分析是有一定的滞后性的,所以我们要计算我们有多大的概率从中筛选出好的标的。第三季度财报下个月已经快出炉了,后面的策略按照个人的理解可以稍微进行调整。我们也可以通过技术指标分析来进行筛选是否进行投资,如何投资,投资多少。
- 希望我的这个思路可以对大家有所启迪。
参考资料
- 【手把手教你】使用pyfinance进行证券收益分析
- 【手把手教你如何从Tushare库下载股票数据,并保存在硬盘当中,第一篇数据过滤】
- 我已经把基本面数据上传到了”下载“这里,有需要的朋友可以自行下载。
Original: https://blog.csdn.net/weixin_44736043/article/details/127338222
Author: Mike_Leigh
Title: 【基本面的量化分析与投资的回报可能 – 上篇】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/739763/
转载文章受原作者版权保护。转载请注明原作者出处!