

文章目录
第二章数据清洗和特征处理
2.1 缺失值观察与处理
2.1.1 缺失值观察



缺失值统计



; 2.1.2对缺失值进行处理
1.可使用的函数有 dropna 函数和fillna函数

df.dropna().head(3)
df[df['Age']==None]=0
df[df['Age'].isnull()] = 0
df[df['Age'] == np.nan] = 0
df.fillna(0)
df.fillna({'Age':0})


chunker.loc[chunker['Age'].isnull(),'Age']=0

查看检验方法
chunker.isnull.sum()
2.2 重复值的观察与处理
df.duplicated()
查看是否有重复值

df[df.duplicated()]没有显示任何一行表明没有重复值
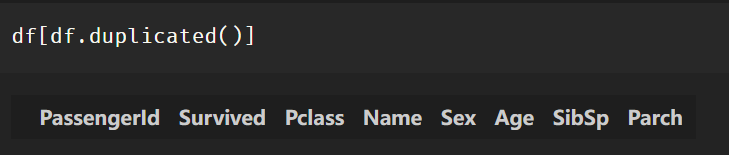
删除重复行
a.drop_duplicates()
将前面清洗好的数据保存为csv
df.to_csv(‘train_clear.csv’)
; 特征观察和处理

- 数值型数据
- 离散型数据
- 连续型数据
- 文本型特征
首先进行分箱操作
1.分箱操作是什么
pandas.cut将数据分成离散的区间
必须是一维的
- 第一个参数是那列的数据
- bins 怎么分段
- right 右边是闭的还是开的
- labels 标签 默认没有标签
如果出现异常的值




对文本变量进行转换
列对象.unique()查看有什么种类

value_counts()数有多少个

replace 替换【】,【】 ,
inplace=
df['Sex_num'] = df['Sex'].replace(['male','female'],[1,2])
df.head()
map方法
df['Sex_num'] = df['Sex'].map({'male': 1, 'female': 2})
from sklearn.preprocessing import LabelEncoder
种类很多的时候可以导入这个包

df['Cabin']=LabelEncoding().fit_transform(df['Cabin'])
//这个函数可以把文本变量变成数字变量
//要么是文本要么是数字
df.head()

one-hot编码
abcd ,value


这些数据是不可比较的,所以用0-10表示是没有对应的意义的 大小
处理的数据只有0和1提高计算效率
转换的函数
x=pd.get_dummies(df['Age'],prefix='Age')
//将变量转换为
df=pd.getconcat([df,x],axis=1)
//在原来的表中进行拼接
df.head()
循环合并
for column in['Cabin','Embarked']:
x= pd.get_dummies(df[column],prefix=column)
df=pd.getconcat([df,x],axis=1)
df.head()
join方法合并
将指定列进行get_dummies 后合并到 元数据中
df = df.join(pd.get_dummies(df.color))
join和concat之间的区别
Series.str.extract字符串提取函数
从纯文本Name特征里提取出Titles的特征所谓的Titles就是Mr,Miss,Mrs等
正则表达式
df['Title']=df.Name.str.extract('([A-Za-z]+)\.')
df
按百分比分段qcut
Original: https://blog.csdn.net/m0_52024881/article/details/121324404
Author: speoki
Title: python进行数据分析第二章task02
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/739747/
转载文章受原作者版权保护。转载请注明原作者出处!