

🔥一个人走得远了,就会忘记自己为了什么而出发,希望你可以不忘初心,不要随波逐流,一直走下去🎶
🦋 欢迎关注🖱点赞👍收藏🌟留言🐾
🦄 本文由 程序喵正在路上 原创,CSDN首发!
💖 系列专栏:Python数据挖掘
🌠 首发时间:2022年8月31日
✅ 如果觉得博主的文章还不错的话,希望小伙伴们三连支持一下哦
阅读指南
- 一、学习目标
- 二、Pandas简介
- 三、Pandas的优点
- 四、DataFrame
* - DataFrame的引入
- DataFrame的结构
- DataFrame的属性
- DataFrame的方法
- DataFrame索引的设置
- 设置新索引案例
- 五、MultiIndex与Panel
* - MultiIndex
- Panel
- 六、Series
* - 创建Series
- Series获取索引和值
- 七、总结
一、学习目标
- 了解 Numpy 与 Pandas 的不同
- 了解 Pandas 的 MultiIndex 与 panel 结构
- 说明 Pandas 的 Series 与 Dataframe 两种结构的区别
二、Pandas简介


- 2008 年 WesMcKinney 开发的库
- 一个专门用于数据挖掘的开源 Python 库
- 以 Numpy 为基础,借力 Numpy 模块在计算方面性能高的优势
- 基于 Matplotlib,能够进行简便地画图
- 独特的数据结构
; 三、Pandas的优点
Numpy 已经能够帮助我们处理数据,能够结合 matplotlib 解决部分数据展示等问题,那么学习 Pandas 的目的是什么呢?
便捷的数据处理功能
- 读取文件方便
- 封装了 Matplotlib、 Numpy 的画图和计算
Pandas 拥有三大数据结构 —— DataFrame、 Panel、 Series
四、DataFrame
DataFrame的引入
回顾我们在 Numpy 当中创建的股票涨跌幅数据的形式?
import numpy as np
stock_change = np.random.normal(0, 1, (10, 5))
会得到类似于下面的一组数据:
array([[-0.76262691, -1.53906032, -1.19438127, -1.81317422, -0.3470865 ],
[ 0.59125622, -2.19342596, -0.64091173, 0.71351875, -0.09791594],
[-0.43086545, 0.25453646, -0.15989081, -2.37560652, 0.14228323],
[-0.59931837, 0.92769144, -1.32584091, -0.50051822, -0.91595638],
[ 0.97610619, 0.01210933, -0.40116201, 0.67677703, 0.07081736],
[ 0.48321613, 1.03806051, 0.64154591, -0.05624017, 1.14431186],
[ 0.50118994, -0.41052898, 0.90930519, -1.99978121, -0.91814337],
[-0.08912512, -2.38287704, -2.13710752, 0.29732938, -1.50453318],
[ 0.18190879, -0.72589502, -1.07843733, -1.33786192, 0.11145101],
[ 0.40291687, -1.09541242, -0.81029028, -0.47490371, -1.90883155]])
上面数据的结构为:既有行索引,又有列索引的二维数组
但是这样的数据形式 很难看到存储的是什么样的数据,并且也很难获取相应的数据,比如需要获取某个指定股票的数据,就很难去获取
问题:如何让数据更加有意义地去显示出来?
import pandas as pd
pd.DataFrame(stock_change)
运行代码,会出现下图的效果,默认索引是从 0 开始:
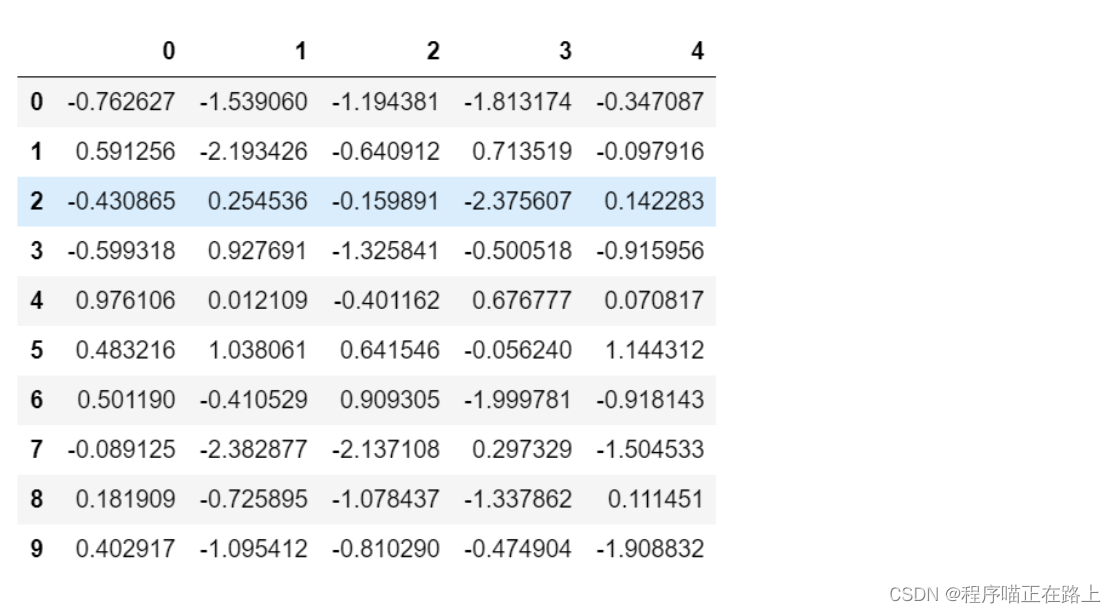
这样效果还不是很好,我们可以给股票涨跌幅数据增加行列索引,这样显示效果更佳
- 添加行索引
stock = ["股票{}".format(i) for i in range(10)]
pd.DataFrame(stock_change, index=stock)
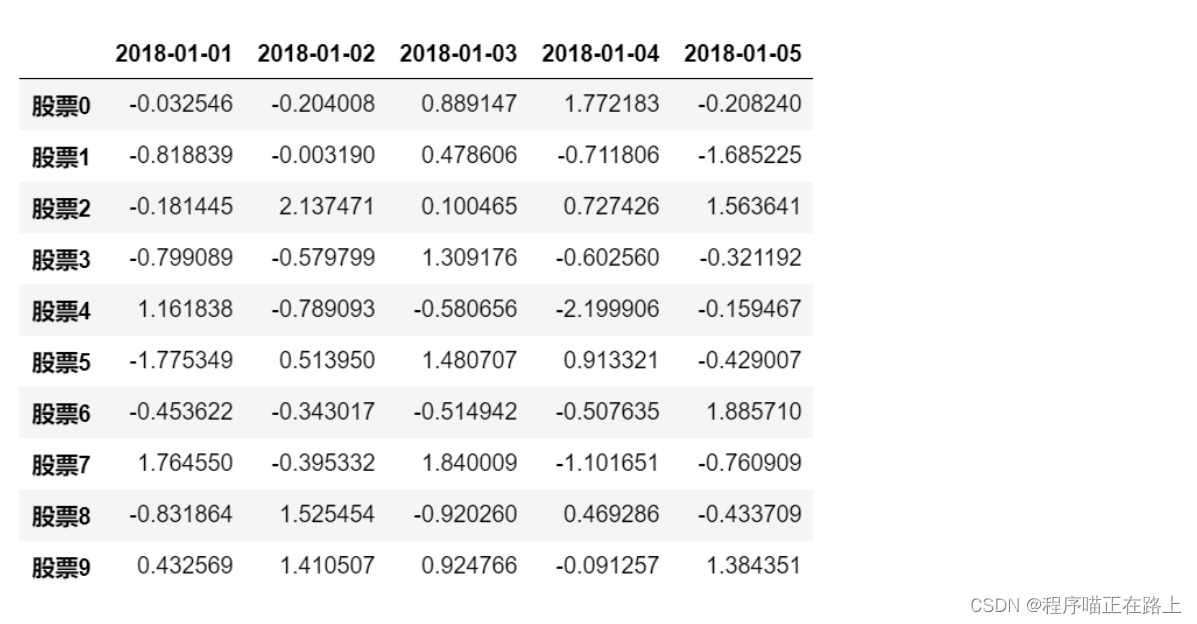
- 添加行索引
date = pd.date_range(start="20180101", periods=5, freq="B")
pd.DataFrame(stock_change, index=stock, columns=date)
最终呈现效果如下:
DataFrame的结构
DataFrame 对象既有行索引,又有列索引,类似于二维表
- 行索引,表明不同行,横向索引,称为 index
- 列索引,表明不同列,纵向索引,称为 *columns
DataFrame的属性
将刚才得到的表用变量保存起来
data = pd.DataFrame(stock_change, index=stock, columns=date)
常用属性:
- shape
data.shape

- index
data.index

- columns
data.columns

- values
data.values

- T
data.T

DataFrame的方法
- head()
data.head(3)
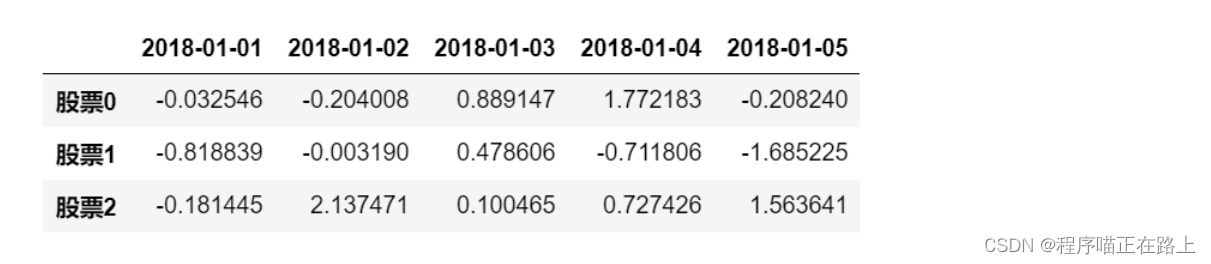
- tail()
data.tail(2)

DataFrame索引的设置
- 修改行列索引值
请注意:以下修改方式是错误的, 不能单独修改某一个索引
data.index[3] = '股票_3'
正确的方式:
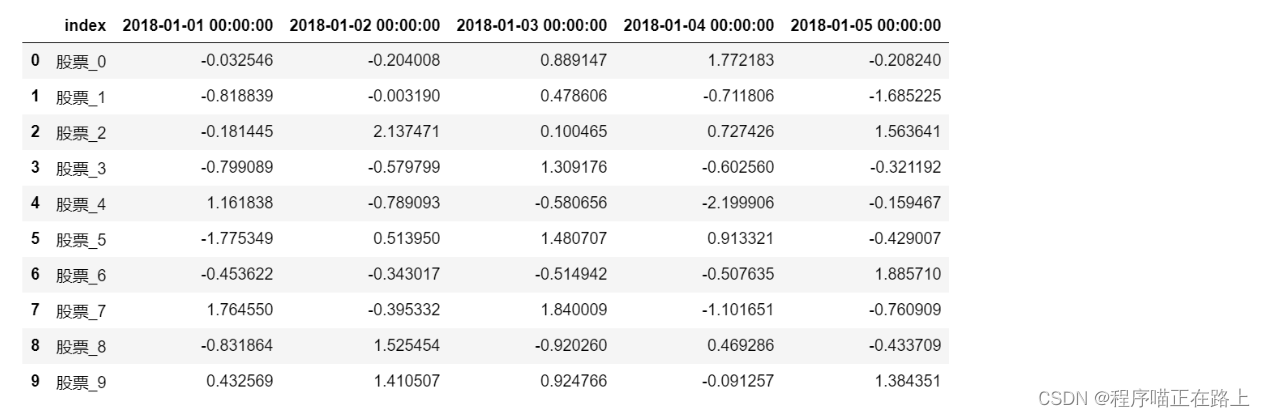
stock_code = ["股票_" + str(i) for i in range(stock_change.shape[0])]
data.index = stock_code
效果如下:

- 重设索引
- reset_index(drop=False)
- 设置新的下标索引
- drop:默认为 False,不删除原来索引,如果为 True,删除原来的索引
data.reset_index()
data.reset_index(drop=True)

- 以某列值设置为新的索引
- set_index(keys, drop=True)
- keys:列索引名称或者列索引名称的列表
- drop: boolean、 default True,当作新的索引,删除原来的列
设置新索引案例
- 创建
import pandas as pd
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale': [55, 40, 84, 31]})
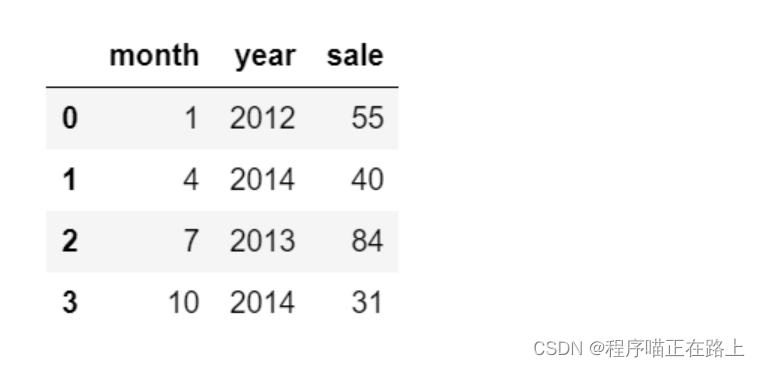
- 设置一个索引,以月份为例
df.set_index("month", drop=True)

- 设置多个索引,以年和月份为例
new_df = df.set_index(["year", "month"])
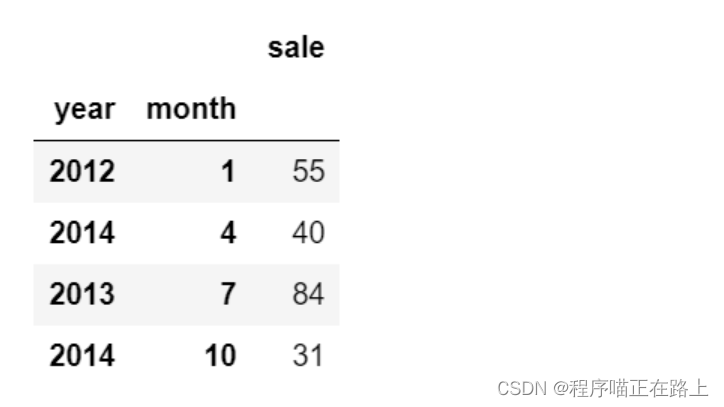
请注意:通过我们刚才的一波操作,这个 DataFrame 已经变成了一个具有 MultiIndex 的 DataFrame
查看它的行索引,可以发现已经改变了
new_df.index
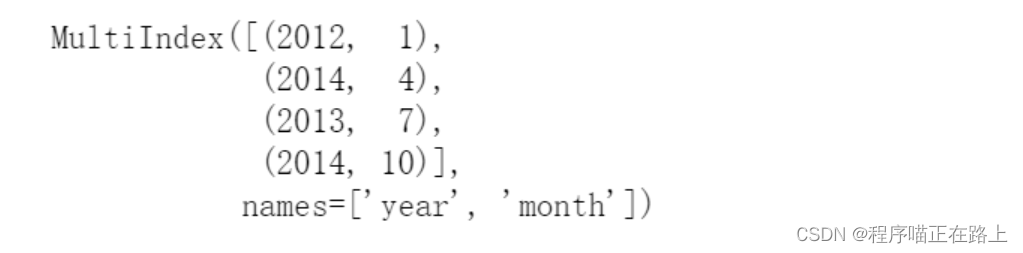
五、MultiIndex与Panel
MultiIndex
多级或分层索引对象
- index属性
- names: levels 的名称
- levels:每个 level 的元组值
new_df.index.names

new_df.index.levels

Panel
- class pandas.Panel(data=None, items=None, major_axis=None, minor_axis=None, copy=False, dtype=None)
- 存储 3 维数组的 Panel 结构
p = pd.Panel(np.arange(24).reshape(4, 3, 2),
items=list('ABCD'),
major_axis=pd.date_range('20130101', periods=3),
minor_axis=['first', 'second'])
- items —— axis 0,每个项目对应于内部包含的数据帧( DataFrame)
- major_axis —— axis 1,它是每个数据帧( DataFrame)的索引(行)
- minor_axis —— axis 2,它是每个数据帧( DataFrame)的列
请注意:Pandas 从版本 0.20.0 开始弃用,现在推荐用于表示 3D 数据的方法是 DataFrame 上的 MultiIndex 方法,也就是类似于前面的 new_df
六、Series
- *series结构只有行索引
我们将之前的涨跌幅数据进行转置,然后获取 ‘股票0’ 的所有数据
创建Series
通过已有数据创建
- 指定内容,默认索引
pd.Series(np.arange(10))

- 指定索引
pd.Series([6.7, 5.6, 3, 10, 2], index=[1, 2, 3, 4, 5])

通过字典数据创建
pd.Series({'red':100, 'blue':200, 'green':500, 'yellow':1000})

Series获取索引和值
- index
- *values
七、总结
- DataFrame 是 Series 的容器
- Panel 是 DataFrame 的容器
Original: https://blog.csdn.net/weixin_62511863/article/details/126618912
Author: 程序喵正在路上
Title: 【数据挖掘】Pandas介绍
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/739698/
转载文章受原作者版权保护。转载请注明原作者出处!