

python代码基础知识总结(三)
一、理论分析
如果说,numpy是解决了python运算速度慢了短板,因为numpy底层是C语言编写的。那么pandas的诞生注定是为了数据的处理,他的基础是numpy,提供高性能矩阵的运算。这个包里面有两个数据类型series和dataframe。对处理csv、excel、txt、josn等文件十分方便与快捷。你可以在pandas包里的一个封装函数输入对应参数来实现你所需要的所用功能,读入数据后,也方便对数据的行和列进行处理。
此外pandas被广泛应用到数据挖掘,数据分析。提供数据清洗功能。
1.1 Series
- 类似一维数组对象
- 通过list构建Series(ser_obj = pd.Series(range(10))
- 由数据和索引组成(左侧索引,右侧数据,索引自动生成)
- 获取数据和索引(ser_obj.index,ser_obj.values)
- 预览数据(ser_obj.head(n))预览数据的前n行数据
- 通过索引获取数据(ser_obj[idx])
- 索引与数据的对应关系仍保持在数组运算的结果中
- 通过dict构建Series
- name属性(ser_obj.name,ser_obj.index.name)
- 可以像列表一样切分和取值,行索引
import pandas as pd
ser_obj = pd.Series(range(10))
print("series 索引",ser_obj.index)
print("series 值",ser_obj.values)
print("预览series前10行\n",ser_obj.head(10))
print("series 索引0的值",ser_obj[0])
运行结果
series 索引 RangeIndex(start=0, stop=10, step=1)
series 值 [0 1 2 3 4 5 6 7 8 9]
预览series前10行
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
dtype: int64
series 索引0的值 0
import pandas as pd
ser_obj = pd.Series({i:i*i for i in range(10)})
ser_obj.name = "new series"
ser_obj.index.name = 'idx'
print("series 索引",ser_obj.index)
print("series 值",ser_obj.values)
print("预览series前10行\n",ser_obj.head(10))
print("series 索引0的值",ser_obj[0])
print("name 属性",ser_obj.name,ser_obj.index.name)
运行结果
series 索引 Int64Index([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype='int64', name='idx')
series 值 [ 0 1 4 9 16 25 36 49 64 81]
预览series前10行
idx
0 0
1 1
2 4
3 9
4 16
5 25
6 36
7 49
8 64
9 81
Name: new series, dtype: int64
series 索引0的值 0
name 属性 new series idx
1.2 DataFrame
- 通过ndarray构建DataFrame
- 通过dict构建DataFrame
- 通过列索引获取列数据(Series类型)(df_obj[col_idx] 或 df_obj.col_idx)
- 增加列数据,类似dict添加key-value (df_obj[new_col_idx]=data)
- 删除列 (del df_obj[col_idx])
import numpy as np
import pandas as pd
a = np.array([range(10) for _ in range(10)])
print("原数据",a)
df = pd.DataFrame(a)
print("处理后数据",df)
print("根据索引1,取出列元素",df[1])
df[10] = np.array(range(10,20))
print("添加列后的数据\n",df)
del df[10]
print("删除列后的数据\n",df)
运行结果
原数据 [[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]]
处理后数据 0 1 2 3 4 5 6 7 8 9
0 0 1 2 3 4 5 6 7 8 9
1 0 1 2 3 4 5 6 7 8 9
2 0 1 2 3 4 5 6 7 8 9
3 0 1 2 3 4 5 6 7 8 9
4 0 1 2 3 4 5 6 7 8 9
5 0 1 2 3 4 5 6 7 8 9
6 0 1 2 3 4 5 6 7 8 9
7 0 1 2 3 4 5 6 7 8 9
8 0 1 2 3 4 5 6 7 8 9
9 0 1 2 3 4 5 6 7 8 9
根据索引1,取出列元素 0 1
1 1
2 1
3 1
4 1
5 1
6 1
7 1
8 1
9 1
Name: 1, dtype: int32
添加列后的数据
0 1 2 3 4 5 6 7 8 9 10
0 0 1 2 3 4 5 6 7 8 9 10
1 0 1 2 3 4 5 6 7 8 9 11
2 0 1 2 3 4 5 6 7 8 9 12
3 0 1 2 3 4 5 6 7 8 9 13
4 0 1 2 3 4 5 6 7 8 9 14
5 0 1 2 3 4 5 6 7 8 9 15
6 0 1 2 3 4 5 6 7 8 9 16
7 0 1 2 3 4 5 6 7 8 9 17
8 0 1 2 3 4 5 6 7 8 9 18
9 0 1 2 3 4 5 6 7 8 9 19
删除列后的数据
0 1 2 3 4 5 6 7 8 9
0 0 1 2 3 4 5 6 7 8 9
1 0 1 2 3 4 5 6 7 8 9
2 0 1 2 3 4 5 6 7 8 9
3 0 1 2 3 4 5 6 7 8 9
4 0 1 2 3 4 5 6 7 8 9
5 0 1 2 3 4 5 6 7 8 9
6 0 1 2 3 4 5 6 7 8 9
7 0 1 2 3 4 5 6 7 8 9
8 0 1 2 3 4 5 6 7 8 9
9 0 1 2 3 4 5 6 7 8 9
import numpy as np
import pandas as pd
a = {i:range(10) for i in range(10)}
print("原数据\n",a)
df = pd.DataFrame(a)
print("处理后数据\n",df)
print("根据索引1,取出列元素\n",df[1])
df[10] = np.array(range(10,20))
print("添加列后的数据\n",df)
del df[10]
print("删除列后的数据\n",df)
运行结果
原数据
{0: range(0, 10), 1: range(0, 10), 2: range(0, 10), 3: range(0, 10), 4: range(0, 10), 5: range(0, 10), 6: range(0, 10), 7: range(0, 10), 8: range(0, 10), 9: range(0, 10)}
处理后数据
0 1 2 3 4 5 6 7 8 9
0 0 0 0 0 0 0 0 0 0 0
1 1 1 1 1 1 1 1 1 1 1
2 2 2 2 2 2 2 2 2 2 2
3 3 3 3 3 3 3 3 3 3 3
4 4 4 4 4 4 4 4 4 4 4
5 5 5 5 5 5 5 5 5 5 5
6 6 6 6 6 6 6 6 6 6 6
7 7 7 7 7 7 7 7 7 7 7
8 8 8 8 8 8 8 8 8 8 8
9 9 9 9 9 9 9 9 9 9 9
根据索引1,取出列元素
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
Name: 1, dtype: int64
添加列后的数据
0 1 2 3 4 5 6 7 8 9 10
0 0 0 0 0 0 0 0 0 0 0 10
1 1 1 1 1 1 1 1 1 1 1 11
2 2 2 2 2 2 2 2 2 2 2 12
3 3 3 3 3 3 3 3 3 3 3 13
4 4 4 4 4 4 4 4 4 4 4 14
5 5 5 5 5 5 5 5 5 5 5 15
6 6 6 6 6 6 6 6 6 6 6 16
7 7 7 7 7 7 7 7 7 7 7 17
8 8 8 8 8 8 8 8 8 8 8 18
9 9 9 9 9 9 9 9 9 9 9 19
删除列后的数据
0 1 2 3 4 5 6 7 8 9
0 0 0 0 0 0 0 0 0 0 0
1 1 1 1 1 1 1 1 1 1 1
2 2 2 2 2 2 2 2 2 2 2
3 3 3 3 3 3 3 3 3 3 3
4 4 4 4 4 4 4 4 4 4 4
5 5 5 5 5 5 5 5 5 5 5
6 6 6 6 6 6 6 6 6 6 6
7 7 7 7 7 7 7 7 7 7 7
8 8 8 8 8 8 8 8 8 8 8
9 9 9 9 9 9 9 9 9 9 9
DataFrame 操作
- 索引操作1:.loc,标签索引
- 索引操作2:.iloc,位置索引
- 索引可以看作是ndarray,切片索引包含末尾位置。
- 排序1:sort_index,索引排序
- 排序2:sort_values(by=’label’)按照值排序
- 判断缺失值 (ser_obj.isnull(),df_obj.isnull())
- 丢弃缺失数据 (dropna)
- 填充缺失数据 (fillna)
import numpy as np
import pandas as pd
a = {i*i:range(10) for i in range(10)}
print("原数据\n",a)
df = pd.DataFrame(a)
print("处理后数据\n",df)
df.loc[4,1]=np.nan
df.iloc[1,0]=np.nan
print("处理后数据\n",df)
df[16] = np.array(range(10,0,-1))
print("处理后数据\n",df)
df.sort_values(by=16,inplace=True)
print("处理后数据\n",df)
df[df.isnull()==True] = 0
print("处理后数据\n",df)
运行结果
原数据
{0: range(0, 10), 1: range(0, 10), 4: range(0, 10), 9: range(0, 10), 16: range(0, 10), 25: range(0, 10), 36: range(0, 10), 49: range(0, 10), 64: range(0, 10), 81: range(0, 10)}
处理后数据
0 1 4 9 16 25 36 49 64 81
0 0 0 0 0 0 0 0 0 0 0
1 1 1 1 1 1 1 1 1 1 1
2 2 2 2 2 2 2 2 2 2 2
3 3 3 3 3 3 3 3 3 3 3
4 4 4 4 4 4 4 4 4 4 4
5 5 5 5 5 5 5 5 5 5 5
6 6 6 6 6 6 6 6 6 6 6
7 7 7 7 7 7 7 7 7 7 7
8 8 8 8 8 8 8 8 8 8 8
9 9 9 9 9 9 9 9 9 9 9
处理后数据
0 1 4 9 16 25 36 49 64 81
0 0.0 0.0 0 0 0 0 0 0 0 0
1 NaN 1.0 1 1 1 1 1 1 1 1
2 2.0 2.0 2 2 2 2 2 2 2 2
3 3.0 3.0 3 3 3 3 3 3 3 3
4 4.0 NaN 4 4 4 4 4 4 4 4
5 5.0 5.0 5 5 5 5 5 5 5 5
6 6.0 6.0 6 6 6 6 6 6 6 6
7 7.0 7.0 7 7 7 7 7 7 7 7
8 8.0 8.0 8 8 8 8 8 8 8 8
9 9.0 9.0 9 9 9 9 9 9 9 9
处理后数据
0 1 4 9 16 25 36 49 64 81
0 0.0 0.0 0 0 10 0 0 0 0 0
1 NaN 1.0 1 1 9 1 1 1 1 1
2 2.0 2.0 2 2 8 2 2 2 2 2
3 3.0 3.0 3 3 7 3 3 3 3 3
4 4.0 NaN 4 4 6 4 4 4 4 4
5 5.0 5.0 5 5 5 5 5 5 5 5
6 6.0 6.0 6 6 4 6 6 6 6 6
7 7.0 7.0 7 7 3 7 7 7 7 7
8 8.0 8.0 8 8 2 8 8 8 8 8
9 9.0 9.0 9 9 1 9 9 9 9 9
处理后数据
0 1 4 9 16 25 36 49 64 81
9 9.0 9.0 9 9 1 9 9 9 9 9
8 8.0 8.0 8 8 2 8 8 8 8 8
7 7.0 7.0 7 7 3 7 7 7 7 7
6 6.0 6.0 6 6 4 6 6 6 6 6
5 5.0 5.0 5 5 5 5 5 5 5 5
4 4.0 NaN 4 4 6 4 4 4 4 4
3 3.0 3.0 3 3 7 3 3 3 3 3
2 2.0 2.0 2 2 8 2 2 2 2 2
1 NaN 1.0 1 1 9 1 1 1 1 1
0 0.0 0.0 0 0 10 0 0 0 0 0
处理后数据
0 1 4 9 16 25 36 49 64 81
9 9.0 9.0 9 9 1 9 9 9 9 9
8 8.0 8.0 8 8 2 8 8 8 8 8
7 7.0 7.0 7 7 3 7 7 7 7 7
6 6.0 6.0 6 6 4 6 6 6 6 6
5 5.0 5.0 5 5 5 5 5 5 5 5
4 4.0 0.0 4 4 6 4 4 4 4 4
3 3.0 3.0 3 3 7 3 3 3 3 3
2 2.0 2.0 2 2 8 2 2 2 2 2
1 0.0 1.0 1 1 9 1 1 1 1 1
0 0.0 0.0 0 0 10 0 0 0 0 0
二、代码实现
为了更可以说明我们代码的有效性,我们现在模拟一个数据集。以下数据集摘自movielens,他是著名的电影评分数据集,第一列代表用户的编号,第二列代表电影的编号,第三列代表用户对电影的评分,第四列代表用户对电影评分的时间。为了方便读者练习,我们可以仅仅对很小的一部分数据进行处理,其实都一样,不同的是处理大型数据时间要更久而已。
读者可以复制下列的数据集,新建txt文件,命名为dataset.txt。
1::122::5::838985046
1::185::5::838983525
1::231::5::838983392
1::292::5::838983421
1::316::5::838983392
1::329::5::838983392
1::355::5::838984474
1::356::5::838983653
1::362::5::838984885
1::364::5::838983707
1::370::5::838984596
1::377::5::838983834
1::420::5::838983834
1::466::5::838984679
1::480::5::838983653
1::520::5::838984679
1::539::5::838984068
1::586::5::838984068
1::588::5::838983339
1::589::5::838983778
1::594::5::838984679
1::616::5::838984941
2::110::5::868245777
2::151::3::868246450
2::260::5::868244562
2::376::3::868245920
2::539::3::868246262
2::590::5::868245608
2::648::2::868244699
2::719::3::868246191
2::733::3::868244562
2::736::3::868244698
2::780::3::868244698
2::786::3::868244562
2::802::2::868244603
2::858::2::868245645
2::1049::3::868245920
2::1073::3::868244562
2::1210::4::868245644
2::1356::3::868244603
2::1391::3::868246006
2::1544::3::868245920
现在需要所有用户评分大于所给评价平均值的数据,然后将数据按照时间顺序降序排列。输出所需的数据,同一行数据用制表符号创建。
import pandas as pd
df= pd.read_csv("./dataset.txt",sep='::',header=None,names=['user','item','rating','time'],engine='python')
print("预览前5行",df.head(5))
print("df数据类型",type(df))
print("数据信息\n")
df.info()
df1 = df[df['user']==1]
a = df1['rating'].mean()
print("用户1的平均值",a)
运行结果
预览前5行 user item rating time
0 1 122 5 838985046
1 1 185 5 838983525
2 1 231 5 838983392
3 1 292 5 838983421
4 1 316 5 838983392
df数据类型 <class 'pandas.core.frame.DataFrame'>
数据信息
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 42 entries, 0 to 41
Data columns (total 4 columns):
user 42 non-null int64
item 42 non-null int64
rating 42 non-null int64
time 42 non-null int64
dtypes: int64(4)
memory usage: 1.4 KB
用户1的平均值 5.0
一个个计算平均值太慢了,我们可以设计一个字典来存储用户平均值。
import pandas as pd
df= pd.read_csv("./dataset.txt",sep='::',header=None,names=['user','item','rating','time'],engine='python')
train_df = df.values.tolist()
user_score = {}
for x in train_df:
if x[0] in user_score:
user_score[x[0]].append(x[2])
else:
user_score[x[0]] = [x[2]]
print(user_score)
user_mean = dict()
for key,value in user_score.items():
user_mean[key] = sum(value)/len(value)
print(user_mean)
goal_data = []
for x in train_df:
if(x[2]>=user_mean[x[0]]):
goal_data.append(x)
df_goal = pd.DataFrame(goal_data,columns=['user','item','rating','time'])
df_goal.sort_values(by='time',inplace=True)
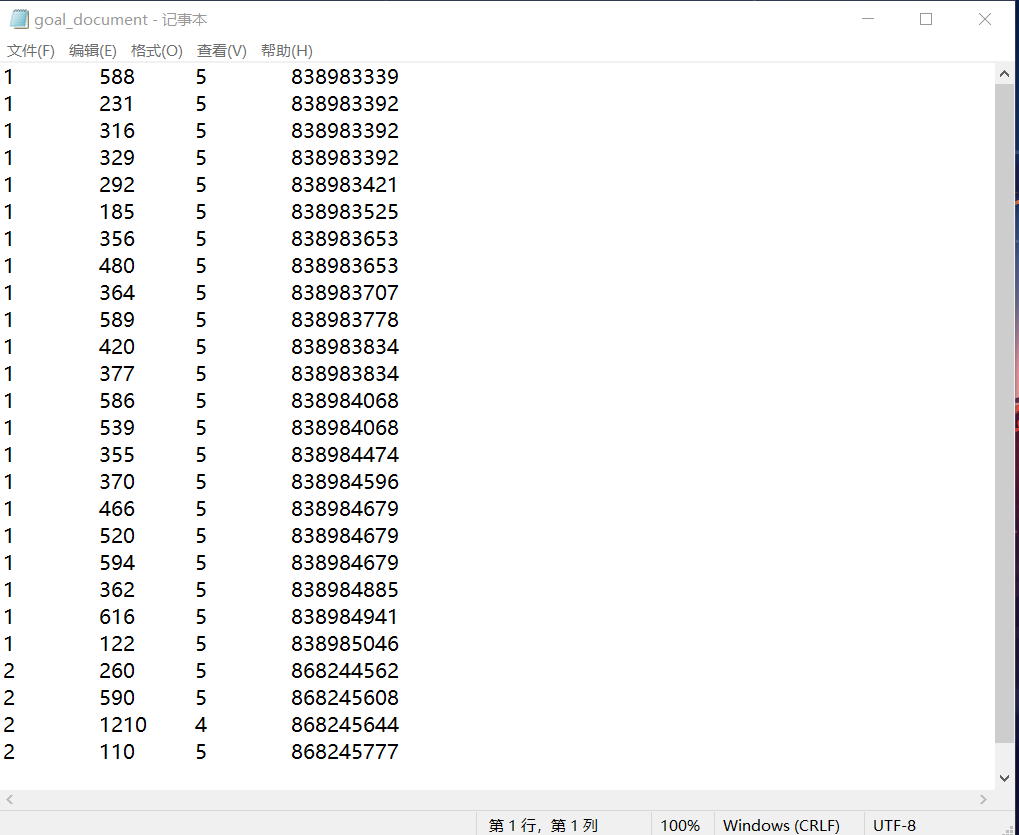
df_goal.to_csv("goal_document",sep='\t',header=None,index=None)
print("存储数据成功!")
运行结果:
{1: [5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5], 2: [5, 3, 5, 3, 3, 5, 2, 3, 3, 3, 3, 3, 2, 2, 3, 3, 4, 3, 3, 3]}
{1: 5.0, 2: 3.2}
存储数据成功!
代码同目录下,出现goal_document文件,输出格式符合要求

Original: https://blog.csdn.net/qq_26274961/article/details/121564471
Author: 啥都不懂的小程序猿
Title: python代码基础知识总结(三)(pandas库简单总结)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/739666/
转载文章受原作者版权保护。转载请注明原作者出处!