

python数据分析高阶应用技巧-pandas库聚合案例【 groupby().apply()写法强化】
文章目录


熟练掌握groupby().apply()写法,有助于将碎片化的数据处理、步骤代码整合起来,这对提高工作效率是大有裨益的。

; 1. 准备数据
首先准备一组代码生成的DataFrame数据,代码如下所示:
import pandas as pd
df = pd.DataFrame({'品种': list('AAAABBBCCD'),
'类型': list('abcdccdadd'),
'金额': [1, 2, 1, 3, 2, 1, 3, 2, 3, 1]
})
数据如下所示:

(如果您对DataFrame的apply()存在疑问,欢迎点击这篇博客学习:python数据分析apply(),map(),applymap()用法归纳。)
- 对DataFrame对象使用apply()
apply()方法有两个重要的参数,第一个参数是一个自定义的函数(下边用fun()表示),第二个参数则是axis参数。
axis参数为0表示对列操作,设置为1则表示对行操作。
因为是以函数为参数,所以我们在解决实际问题时,还有一个要考虑的因素就是,这个”函数参数”的参数x指代的是什么。(即fun(x)中的x)
这里对上边得到的df做一个简单的示例来说明,对列操作,打印出每个x:
df.apply(lambda x: print(x))
可以看到x即每一列与索引组成的Series对象。因为除了打印没有任何操作,最后返回的是一个Values为None的Series。

如果要求和,则结果显而易见地容易理解:
df.apply(lambda x: x.sum())
可以看到结果如下:

- 对groupby()聚合的结果使用apply()
对DataFrame对象使用apply(),每个x是一个Series;
对groupby()聚合的结果使用apply(),得到每个x则会是一个DataFrame。
这是我们首先需要知道的,知道了这一点,后边的逻辑才能清晰。对变量df的”品种”列进行聚合,然后使用apply()方法打印每个x如下:
import pandas as pd
df = pd.DataFrame({'品种': list('AAAABBBCCD'),
'类型': list('abcdccdadd'),
'金额': [1, 2, 1, 3, 2, 1, 3, 2, 3, 1]
})
df.groupby(['品种']).apply(lambda x: print(x))
x打印结果如下:

可以看到,每个x都是一个DataFrame,且是按照”品种”列划分为四类品种的。
如果fun()功能是求和,则实现了先聚合,后求和:
df.groupby(['品种']).apply(lambda x: x.sum())

这将不同于直接使用sum()方法:
对比结果以感受其差别
df.groupby(['品种']).sum()

- 案例分享
下边给出一个略微复杂些的案例,通过groupby()+apply()的方法,可以更快捷地实现。
生成数据的代码及数据如下:
import pandas as pd
df = pd.DataFrame({'品种': list('AAAABBBCCD'),
'类型': list('abcdccdadd'),
'金额': [1, 2, 1, 3, 2, 1, 3, 2, 3, 1]
})
df

需求:求出每个品种的合计金额,每个品种中类型为a,b,c(不包括d)的合计金额,以及每个品种中 类型为a,b,c(不包括d)的合计金额,占该品种合计金额的比例。输出一个DataFrame。
先定义一个fun()函数,使其与groupby().apply()组合,最后再对结果的索引列稍作优化即可。
def fun(s):
b = s['金额'].sum()
t = 0
for key, value in s['类型'].items():
if ((value == 'a') | (value == 'b') | (value == 'c')):
t += s['金额'][key]
return pd.DataFrame([(t, b, t / b)], columns=['属于abc类型的金额汇总', '按品种汇总金额', '占比'])
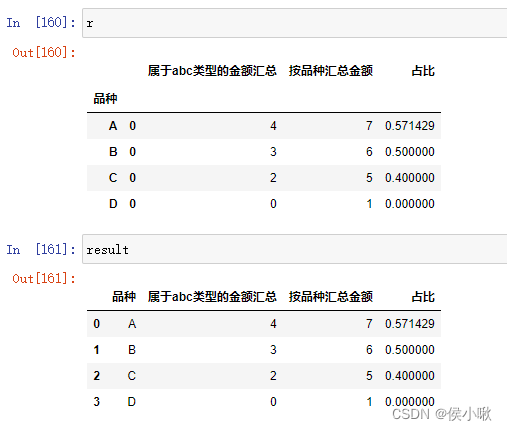
r = df.groupby(['品种']).apply(fun)
result = r.reset_index().drop(['level_1'],axis=1)
因为r是双列索引,稍作优化,result的最终结果:
本次分享就到这里,小啾感谢您的关注与支持!
🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ
Original: https://blog.csdn.net/weixin_48964486/article/details/127588129
Author: 侯小啾
Title: python数据分析高阶应用技巧-pandas库聚合案例【 groupby().apply()写法强化】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/739587/
转载文章受原作者版权保护。转载请注明原作者出处!