

今天看到一篇文章
参考:对比不同主流存储格式(csv, feather, jay, h5, parquet, pickle)的读取效率
然后我自己也试了一下,感觉发现了”新大陆”,T_T~到现在才知道还有这些存储形式,比这excel、csv快多了。
上次实习的时候,因为不知道可以存为其他格式,把多个几十个G的dataframe处理完后存为csv,过后又要读出来
心态瞬间崩了~
搞数据都搞了好久,浪费时间~拐求
文章目录
- desk 读取CSV文件
- 一、excel 存储格式(xlsx)
- 二、csv 存储格式
- 三、pickle 存储格式
- 四、feather 存储格式
- 五、parquet 存储格式
- 六、jay 存储格式
- 七、hdf5 存储格式
多的不说,直接看效果
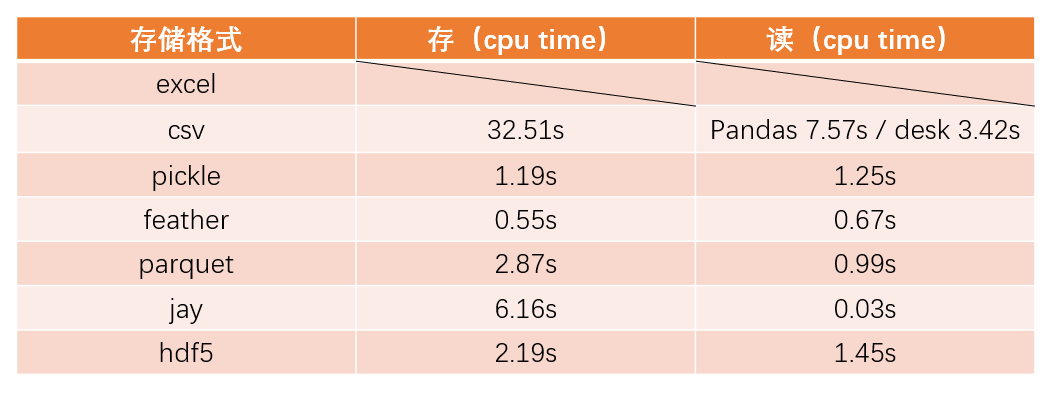

这个结论直接借一下参考文章的,有需要的可以详细看参考文章

还有就是,数据稍微大一点,最好不要存为 excel 格式,这真的~慢
最后最后,在借用这位大兄弟的一句话

; desk 读取CSV文件
读
import time
import dask
import dask.dataframe as dd
from dask.diagnostics import ProgressBar
from numba import jit
import pandas as pd
import numpy as np
import sys
switchDict = {
0 : 'TEST',
1 : 'ALL'
}
status = switchDict[1]
@jit
def importData(fileName):
if status == 'TEST':
df = dd.read_csv(fileName, header=None, blocksize="100MB").head(17000)
else:
df = dd.read_csv(fileName, blocksize="64MB").compute()
df.index = pd.RangeIndex(start=0, stop=len(df))
return df
t0=time.time()
t1= time.perf_counter()
with ProgressBar():
data = importData('train.csv')
t2=time.time()
t3= time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 3.421277699999337
wall time: 3.421303749084473
'''
print(f"当前数据框占用内存大小:{sys.getsizeof(data)/1024/1024:.2f}M")
data.shape
一、excel 存储格式(xlsx)
存
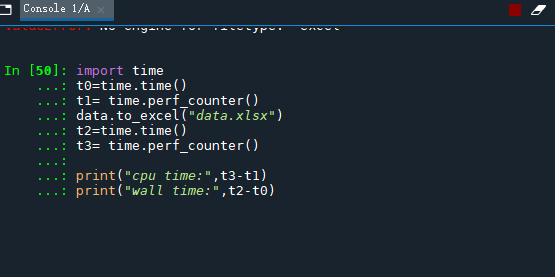
存为excel表,真的慢到天荒~拉胯啊
import time
t0=time.time()
t1= time.perf_counter()
data.to_excel("data.xlsx")
t2=time.time()
t3= time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
等了十几分钟,算了~
读
import time
t0=time.time()
t1= time.perf_counter()
data_excel = pd.read_excel("./data.xlsx")
t2=time.time()
t3= time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
二、csv 存储格式
存
import time
t0=time.time()
t1= time.perf_counter()
data.to_csv("data.csv")
t2=time.time()
t3= time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 32.49002720000135
wall time: 32.48996901512146
'''
读
import time
t0=time.time()
t1= time.perf_counter()
data_csv = pd.read_csv("./data.csv")
t2=time.time()
t3= time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 7.5742819999995845
wall time: 7.574833154678345
'''
三、pickle 存储格式
Pickle:用于序列化和反序列化Python对象结构
详细百度八~
存
import time
t0=time.time()
t1= time.perf_counter()
data.to_pickle("data.pkl.gzip")
t2=time.time()
t3= time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 1.1933384000002625
wall time: 1.1980044841766357
'''
读
import time
t0=time.time()
t1= time.perf_counter()
data_pickle = pd.read_pickle("./data.pkl.gzip")
t2=time.time()
t3= time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 1.246990000000551
wall time: 1.246736764907837
'''
四、feather 存储格式
Feather:一个快速、轻量级的存储框架
网上很多推荐这个存储格式的
详细百度八~
存
import time
t0=time.time()
t1= time.perf_counter()
data.to_feather("data.feather")
t2=time.time()
t3= time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 0.5462657999996736
wall time: 0.5466225147247314
'''
读
t0=time.time()
t1=time.perf_counter()
data_feather = pd.read_feather("./data.feather")
t2=time.time()
t3=time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 0.6685380999997506
wall time: 0.6682815551757812
'''
五、parquet 存储格式
Parquet:Apache Hadoop的列式存储格式
详细百度八~
存
import time
t0=time.time()
t1= time.perf_counter()
data.to_parquet("data.parquet")
t2=time.time()
t3= time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 2.874607599999763
wall time: 2.874359369277954
'''
读
t0=time.time()
t1=time.perf_counter()
data_parquet = pd.read_parquet("./data.parquet")
t2=time.time()
t3=time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 0.9940449000000153
wall time: 0.9959096908569336
'''
六、jay 存储格式
安装 datatable 包
pip install -i https://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com datatable
存
import datatable as dt
t0=time.time()
t1=time.perf_counter()
dt.Frame(data).to_jay("data.jay")
t2=time.time()
t3=time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 6.169269200000599
wall time: 6.168536901473999
'''
读
当我查看内容时,该对象是frame
t0=time.time()
t1=time.perf_counter()
data_jay = dt.fread("./data.jay")
t2=time.time()
t3=time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 0.03480849999959901
wall time: 0.034420013427734375
'''
data_jay.shape
七、hdf5 存储格式
存
普通格式存储
import time
t0=time.time()
t1= time.perf_counter()
h5 = pd.HDFStore('./data.h5','w')
h5['data'] = data
h5.close()
t2=time.time()
t3= time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 2.1860209000005852
wall time: 2.186391592025757
'''
压缩格式存储
import time
t0=time.time()
t1= time.perf_counter()
h5 = pd.HDFStore('./data.h5','w', complevel=4, complib='blosc')
h5['data'] = data
h5.close()
t2=time.time()
t3= time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 1.9893786000002365
wall time: 1.9896411895751953
'''
读
t0=time.time()
t1=time.perf_counter()
data_hdf5 = pd.read_hdf('./data.h5',key='data')
t2=time.time()
t3=time.perf_counter()
print("cpu time:",t3-t1)
print("wall time:",t2-t0)
'''
cpu time: 1.4497185000000172
wall time: 1.4497275352478027
'''
Original: https://blog.csdn.net/qq_42374697/article/details/121282994
Author: 卖山楂啦prss
Title: Python Dataframe之excel、csv、pickle、feather、parquet、jay、hdf5 文件存储格式==》存读效率对比
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/739569/
转载文章受原作者版权保护。转载请注明原作者出处!