

大家好,作为一名互联网行业的小白,写博客只是为了巩固自己学习的知识,但由于水平有限,博客中难免会有一些错误出现,有不妥之处恳请各位大佬指点一二!
博客主页:链接:https://blog.csdn.net/weixin_52720197?spm=1018.2118.3001.5343
1 获取数据
1.1 新建数据
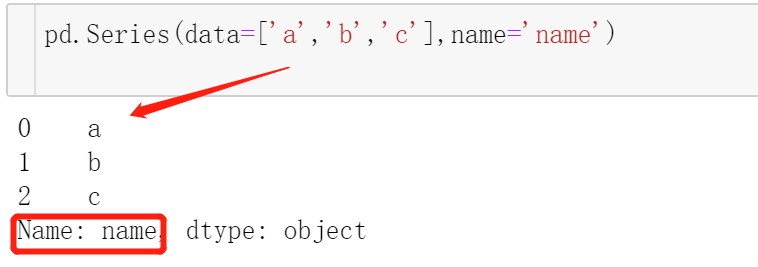
series
创建一列数据,在使用series时,Pandas 默认自动生成整数索引


pd.Series(
data=None :数据列表,字典格式肘直接同肘提供变量名
name=None : 变量名列表
)
DataFrame
DataFrame 是 Pandas 中的一个 表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame 即有行索引也有列索引,可以被看做是由Series 组成的字典
pd.DataFrame({
'name':['1','2','3'],
'sex':[1,1,0],
'age':18})

df1 =pd.DataFrame(data=[['zs1',1,18],['ls',0,19],['ww',1,16]],
columns=['name','sex','age'])
type(df1.name)

1.2 读入文本格式数据文件
pandas. read_csv (filename(文件名), encoding)
pandas.read_table():更通的文本文件读取命令
pd.read_csv(
filepath_or_buffer :要读入的文件路径
sep =,,;:切分隔符
header = ' infer ':指定数据中的第几行作为变量名
names = None :自定义变量名列表
index_col = None :将会被用作索引的列名,多列时只能使用序号列表
usecols = None :指定只读入某些列,使用索引列表或者名称列表均可。
[0,1,3],["名次","学校名称七"所在地区"]
encoding = None :读入文件的编码方式
utf-8/GBK,中文数据文件最好设定为 utf-8
na_values :指定将被读入为缺失值的数值列表,默认下列数据被读入为缺失值:
''A '#N/A* A '
'-l.#QNAN* A '-NaN1A '-nan'A 'l.#IND'A '1.#QNAN'A
'N/A* A 'NA。'NULL'A 'NaN'A 'n/a* A 'nan'A 'null'
):读取 CSV 格式文件,但也可通用于文本文件读取
用法:
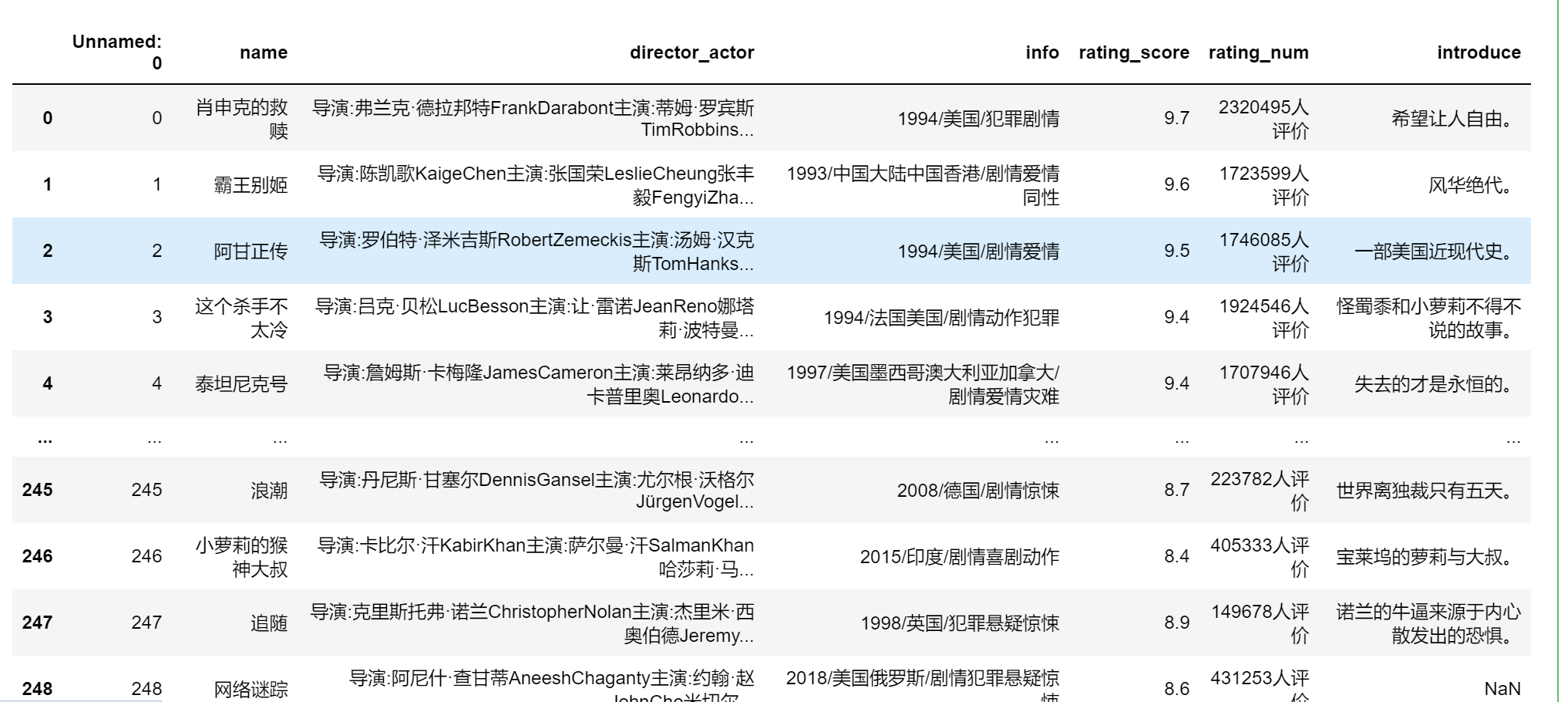
import pandas as pd
pd.read_csv('movie.csv',encoding='GBK')
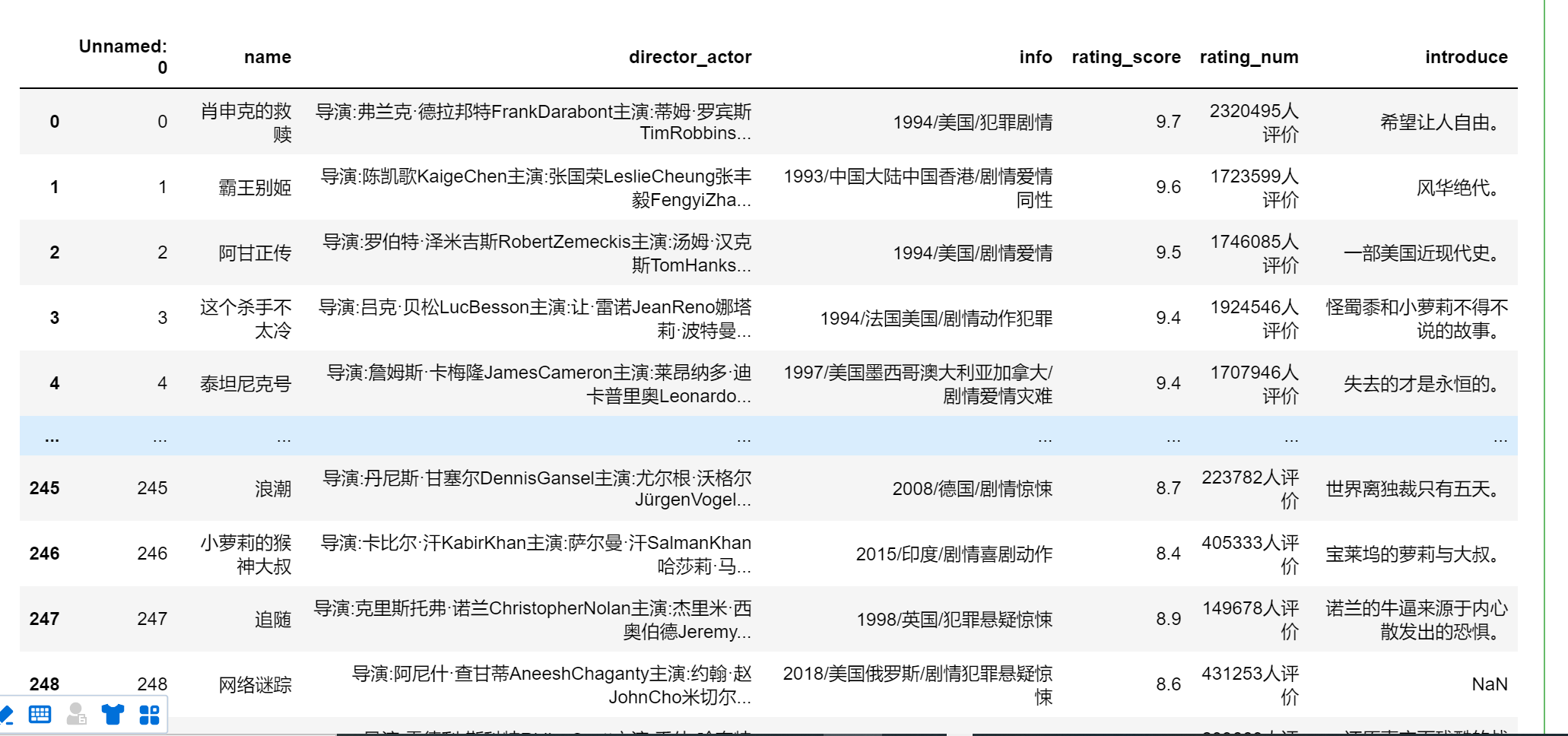
pd.read_table('movie.csv',encoding='gbk')

与pd.read_csv相比,此方法数据更紧凑一些
可以使用分隔符 sep = ‘,’ 来分开
pd.read_table('movie.csv',sep=',',encoding='gbk')
1.3 读取 EXCEL 文件
pd.read_excel(filepath_or_buf fer :要读入的文件路径
sheet_name:读入的工作簿,写字符串(工作薄的名字)或者数字序号均可,默认读入第一个)
df2 = pd.read_excel(filename, sheet_name = 0)
读取Target工作博
pd.read_excel('stu_data.xlsx',sheet_name='Target')

pd.read_excel('stu_data.xlsx',sheet_name=0)
1.4 读入数据库数据
1.4.1 配置 MySQL 连接引擎
conn = pymysql.connect(
host = 'localhost',
user = 'root',
passwd = '123456',
db = 'mydb',
port=3306,
charset = 'utf8'
)
1.4.2 读取数据表
pd.read_sql(
sql :需要执行的 SQL 语句/要读入的表名称
con : 连接引擎名称
index_col = None :将被用作索引的列名称
columns = None :当提供表名称时,需要读入的列名称 list
)
tbl = pd.read_sql ("select code, name from t_hero con = eng)
tbl = pd.read_sql ("select count (*) from t_hero con = eng)
用法;
import pymysql
eng = pymysql.connect(host='localhost',user='root',passwd='123',port=3306,db='pmysql',charset='utf8')
pd.read_sql('select * from t_hero',con = eng)

pd.read_sql('select name,gj,dw from t_hero',con = eng)
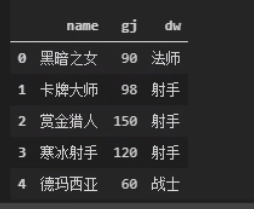
pd.read_sql('select count(1) from t_hero',con = eng)
2 保存数据
2.1 保存数据至外部文件
df.to_csv()
df.to_csv(
filepath_or_buf fer :要保存的文件路径
sep =:分隔符
columns :需要导出的变量列表
header = True :指定导出数据的新变量名,可直接提供 list
index = True :是否导出索引
mode = 'w' : Python 写模式,读写方式:r,r+ , w , w+ , a , a+
encoding = 'utf-8' :默认导出的文件编码格式
df2 . to_csv ('temp. txt')
df.to_excel(
filepath_or_buf fer :要读入的文件路径
sheet_name = 1 Sheetl1 :要保存的表单名称
df2.to_excel(' temp.xlsx' index = False sheet_name = data)
用法:
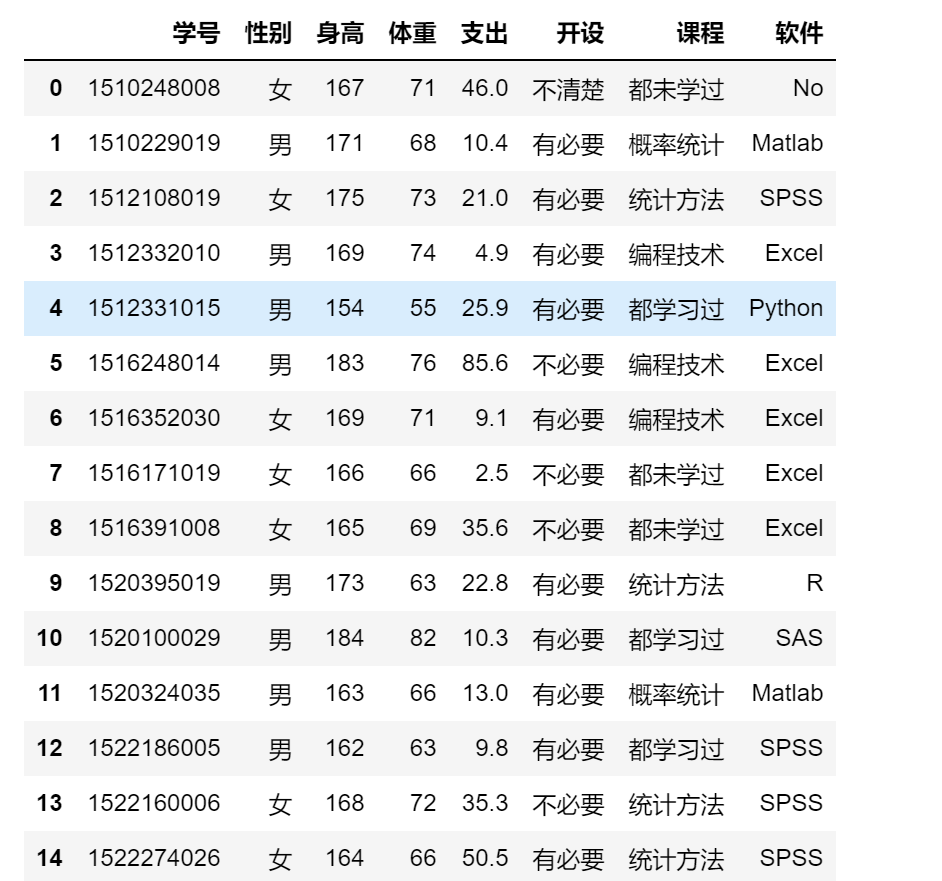
import pandas as pd
df = pd.read_excel('stu_data.xlsx')
df
df.to_csv('temp_csv.csv',columns=['学号','身高'])
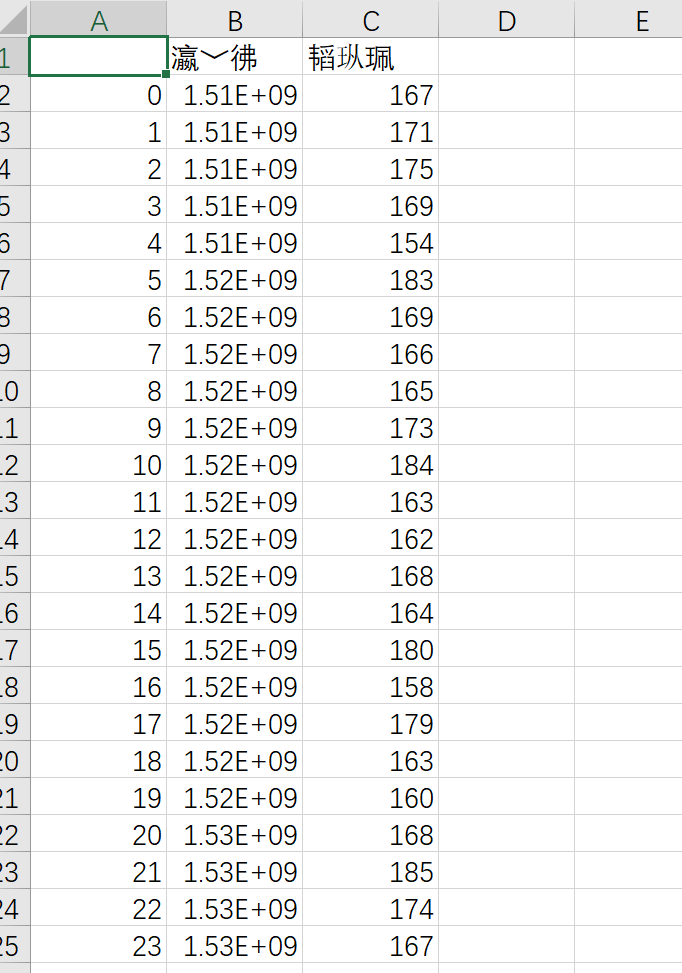
index=False去掉索引列
df.to_csv('temp_csv1.csv',columns=['学号','身高'],header=['no','height'],index=False)
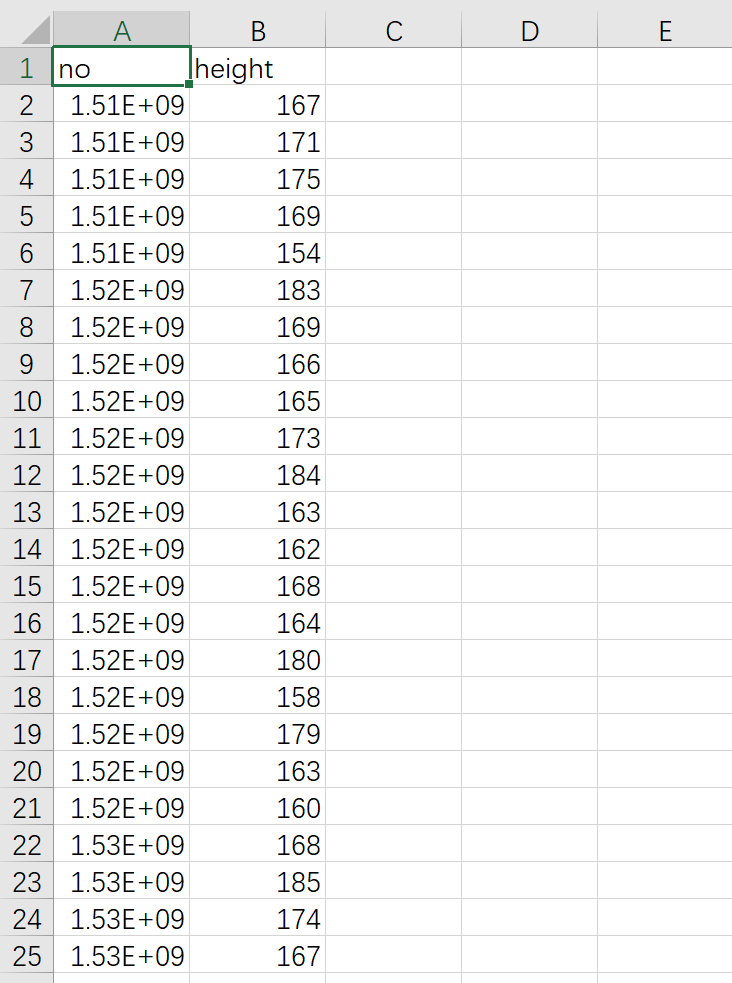
header=[‘名字1′,’名字2’]——修改列名
df.to_csv('temp_csv.csv',columns=['学号','身高'],header=['no','height'],index=False)
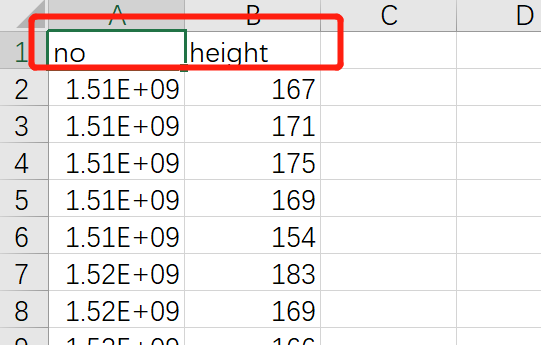
df.to_excel('temp_excel.xlsx',index=False)
2.2 保存数据至数据库
df.to_sql(
name :想把数据保存到哪个表中
con : 连接引擎名称
if_exists = 'fail' :对已存在的数据薄的操作
fail :不做任何处理(不插入新数据)
replace :删除原表并重建新表 append :在原表后插入新数据
index = True :是否导出索引
)
apptbl.to_sql(name=nj t_histrecn r con=engA
用法:
import pymysql
eng = pymysql.connect(host='localhost',user='root',passwd='123',db='pmysql',port=3306,charset='utf8')
df.to_sql('t_stu',eng,if_exists='append')
3 变量列的基本操作
当我们有了数据源以后,先别急着分析,应该先熟悉数据,只有对数据充分熟悉了,才能
更好的进行分析
3.1 了解数据基本情况
3.1.1 head()与 tail()
当数据表中包含了数据行数过多时,就可以把数据表中前几行或后几行数据显示出来进行查看
head()方法【 头部】
返回前 n 行(观察索引值),显示元素的数量默认是 5,但可以传递自定义数值
tail()方法【 尾部】
返回后 n 行观察索引值),显示元素的数量默认是 5,但可以传递自定义数值
df.head()
df .tail()
3.1.2 info()
熟悉数据的第一点就是看下数据的类型,不同的数据类型的分析思路是不一样的,
info()方法
查看数据表中的数据类型,而且不需要一列一列的查看,info()可以输出整个表中所有列的数据类型
df.info()

3.1.3 shape
第二点就是看数据表有多少行,多少列,此方法会以元组的形式返回行、列数。注意 shape 方法获取行数和列数时不会把索引和列索引计算在内
df.shape

52——行数
8——列数
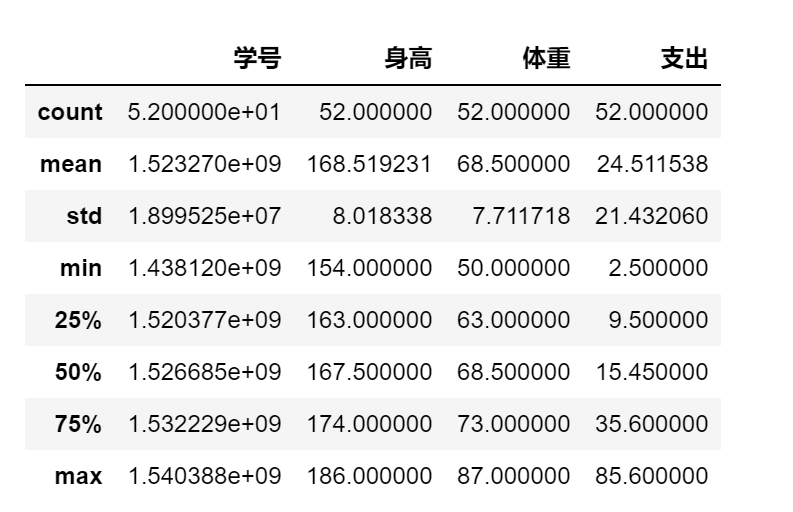
3.1.4 describe()
第三点,就是掌握数值的分布情况,即 数据总和count,均值mean是多少,最值max,min是多少,方差std及分位数分别是多少,可以获取所有数值类型字段的分布值
代码如下:
df.describe()
3.2 修改变量列名
3.2.1 columns
df. columns =新的名称 list
df.columns
df.columns

3.2.2 rename()
用来修改变量名
df.rename(
columns =新旧名称字典:{旧名称,:新名称,}
inplace = False :是否直接替换原数据框)
用法:
df.rename(columns = {'学号2':'学号'}, inplace= True)
3.3 筛选变量列
通过 df.var 或 df[var] 可以选择单列
注意:但只适用于已存在的列, 只能筛选单列,结果为 Series
代码如下:
df.var 单列的筛选结果为 Series
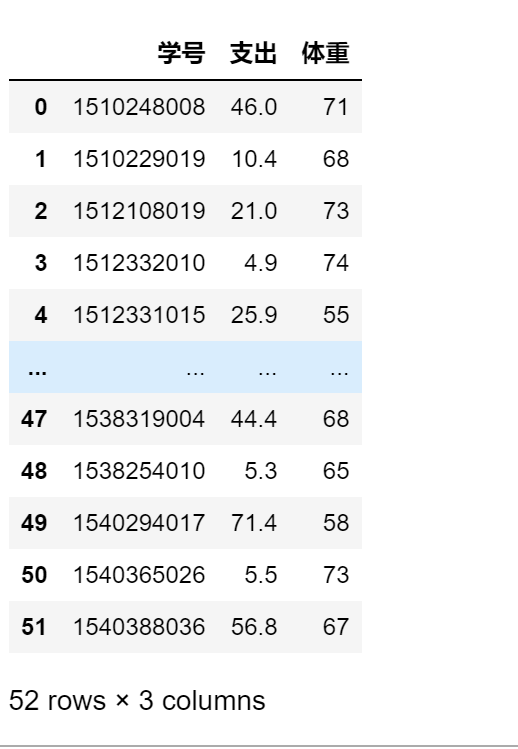
通过 df[[var]] 可以选择多列
代码如下:
df[[var]] 单列的筛选结果为 DataFream
df[['var1, 'var2']] 多列时,列名需要用列表形式提供(因此可使用列表中的切片操作) 多列的筛选结果
用法:
df.学号
df[['学号','支出','体重']]
3.4 删除变量列
df.drop(
index行 / columns列 =准备删除的行/列标签,多个时用列表形式提供
inplace = False :是否直接更改原数据框
)
代码如下:
df.drop(columns =['col1','col2'])
用法:
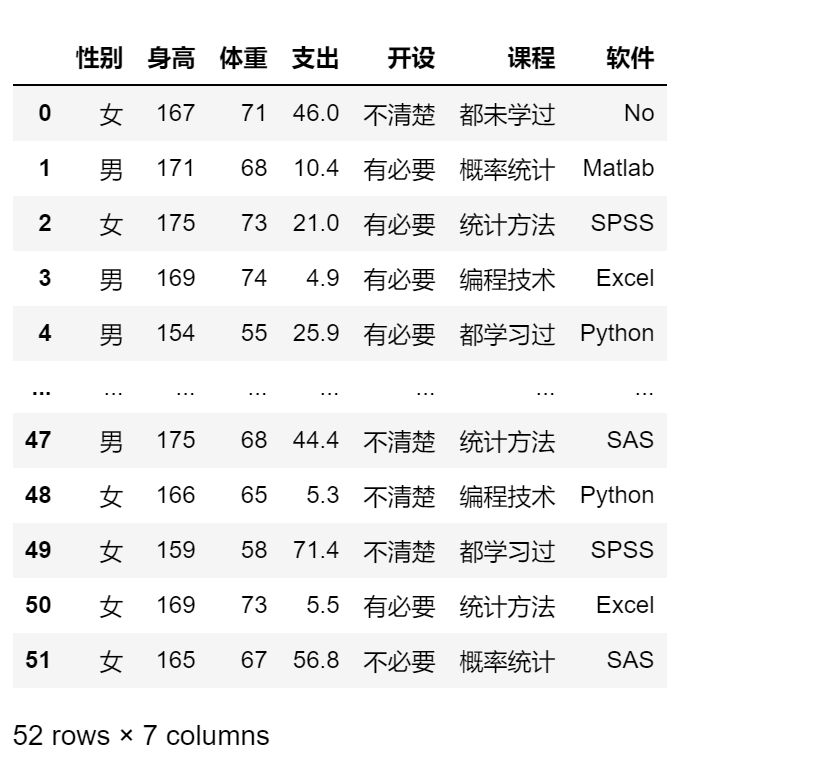
df.drop(columns = '学号')
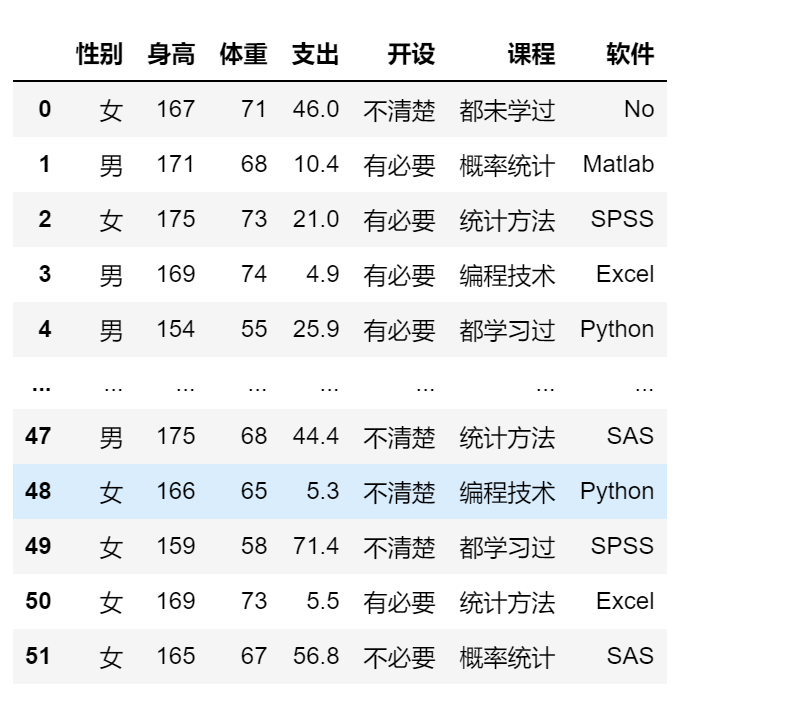
df.drop(columns = ['学号','身高'])

del df[”]
直接删除原数据框相应的一列,建议尽量少用
del df['column-name']
直接删除原数据框相应的一列,建议尽量少用
del df['学号']
df
3.5 变量类型的转换
3.5.1 Pandas 支持的数据类型
具体类型是 Python, Numpy 各种类型的混合,可以比下表分的更细
- float
- int
- string
- bool
- datetime64[nsr] ,datetime64[nsr,tz],timedelta[ns]、
- category
- object
df.dtypes :査看各列的数据类型
代码如下:
df.dtypes

3.5.2 在不同数据类型间转换
df.astype(
dtype :指定希望转换的数据类型,可以使用 numpy 或者 python 中的数据类型:
int/float/bool/str
copy = True :是否生成新的副本,而不是替换原数据框
errors = 'raise' : 转换出错时是否抛出错误,raise/ ignore )
df.astype('str').dtypes

df.支出.astype('str')

3.6 变量列的添加
给现有的数据增加新列可以使用如下方法:
3.6.1 根据新数据添加
df[添加新列表名称] = pd.Series([val,val2,val3],index=[c1,c2,c3])
3.6.2 根据原数据添加
df[添加新列表名称] = df[c2]+df[c3]
4 索引的使用
索引的用途:
1.用于在分析、可视化、数据展示、数据操作中标记数据行
2.提供数据汇总、合并、筛选时的关键,依据
3.提供数据重构时的关键依据
注意事项:
索引是不可直接修改的,只能增、删、替换,逻辑上索引不应当出现重复值,Pandas 对这种情况不会报错,但显然有潜在风险
4.1 建立素引
4.1.1 新建数据框时建立素引
所有的数据框默认都已经使用从 0 开始的自然数索引,因此这里的”建立”索引指的是自定义索引
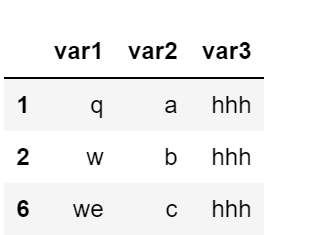
df = pd.DataFrame(
{'varl' : 1.0,
' var2 ' : [1,2,3,4],
' var3 ' : ['test', 'python','test', 'hello'] , ' var4' : ' cons'} ,
index = [0,1,2,6]
)
用法:
import pandas as pd
pd.DataFrame({
'var1':['q','w','we'],
'var2':['a','b','c'],
'var3':'hhh'
},
index=[1,2,6])
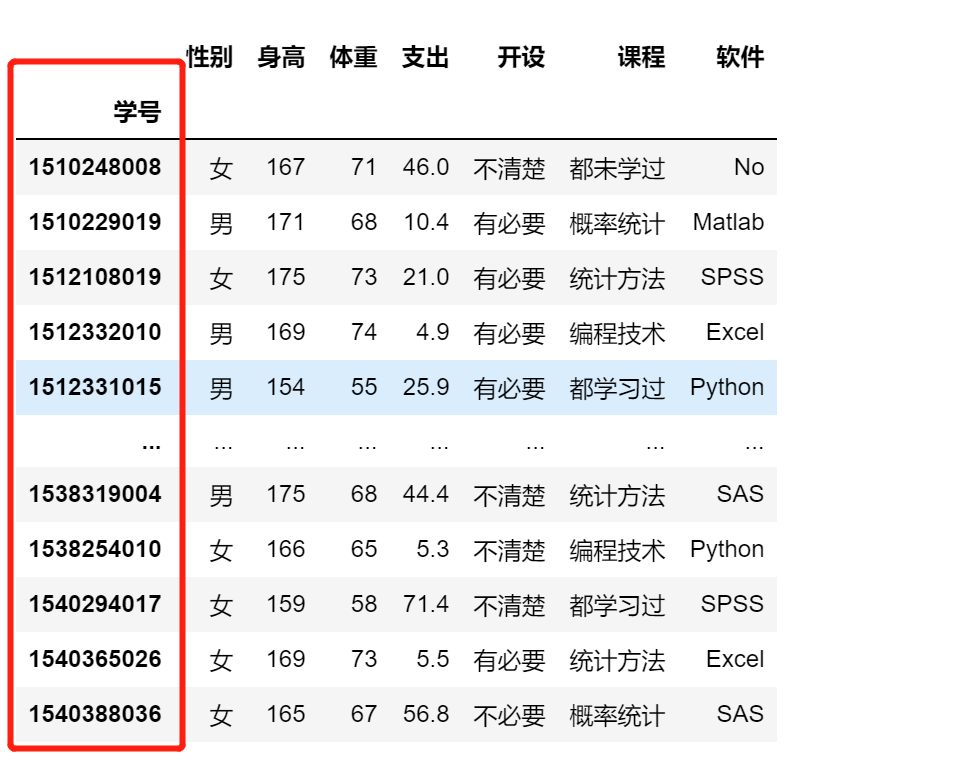
4.1.2 读入数据时建立素引
使用现有的列
df = pd. read_csv ("filename", index_col="column")
用法:
pd.read_excel('stu_data.xlsx',index_col = '学号')
使用复合列
df = pd. read_csv ("filename", index_col=["column1","column2"])
用法:
pd.read_excel('stu_data.xlsx',index_col = [0,1])
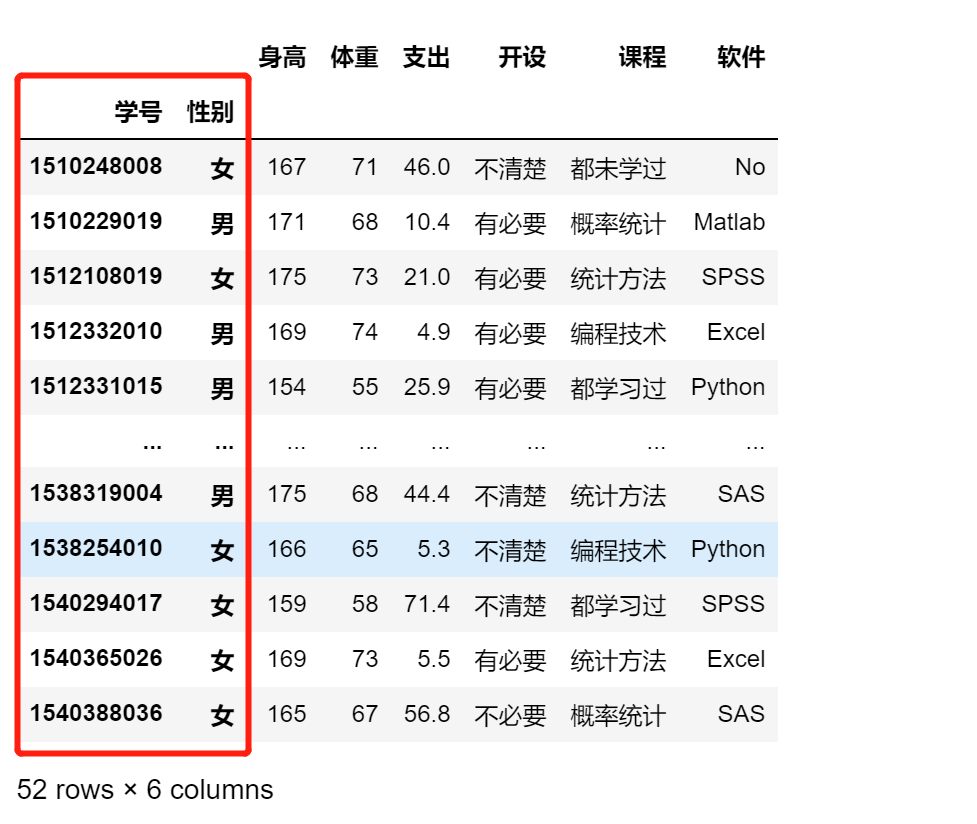
4.1.3 指定某列为素引列
df.set_index(
keys :被指定为索引的列名,复合索引用 list:格式提供
drop = True :建立索引后是否删除该列
append = False :是否在原索引基础上添加索引,默认是直接替换原索引
inplace = False :是否直接修改原数据框
)
用法:
df.set_index(keys='学号')
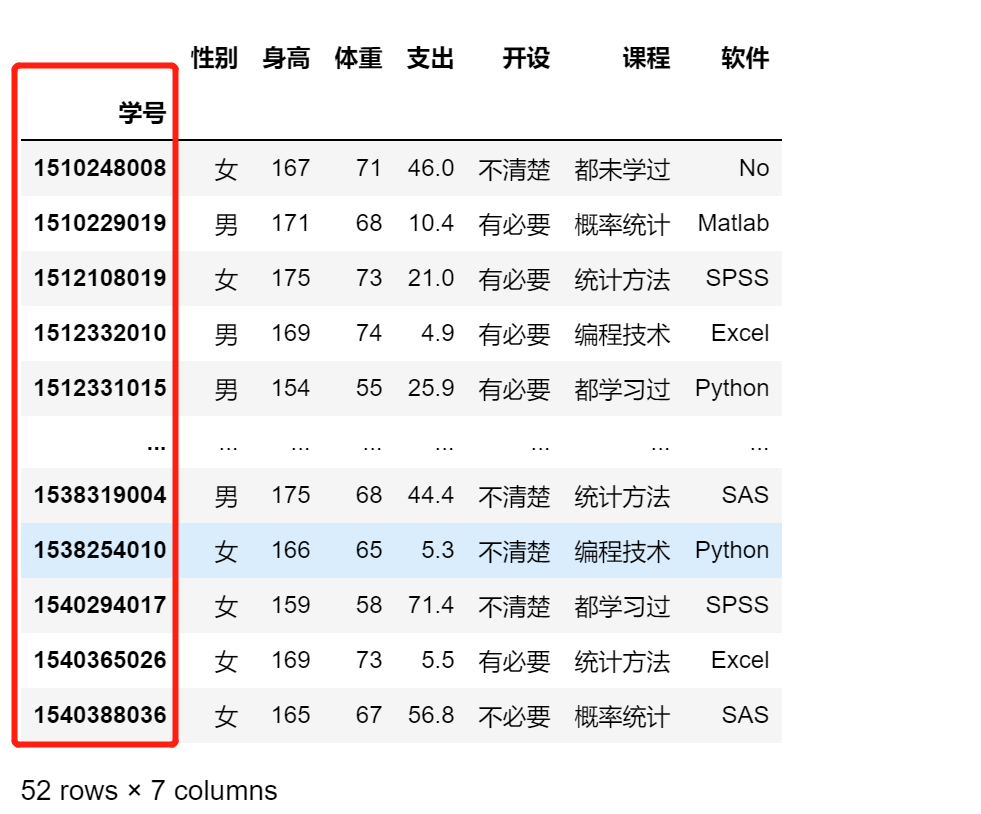
df.set_index(keys='学号',append = True)
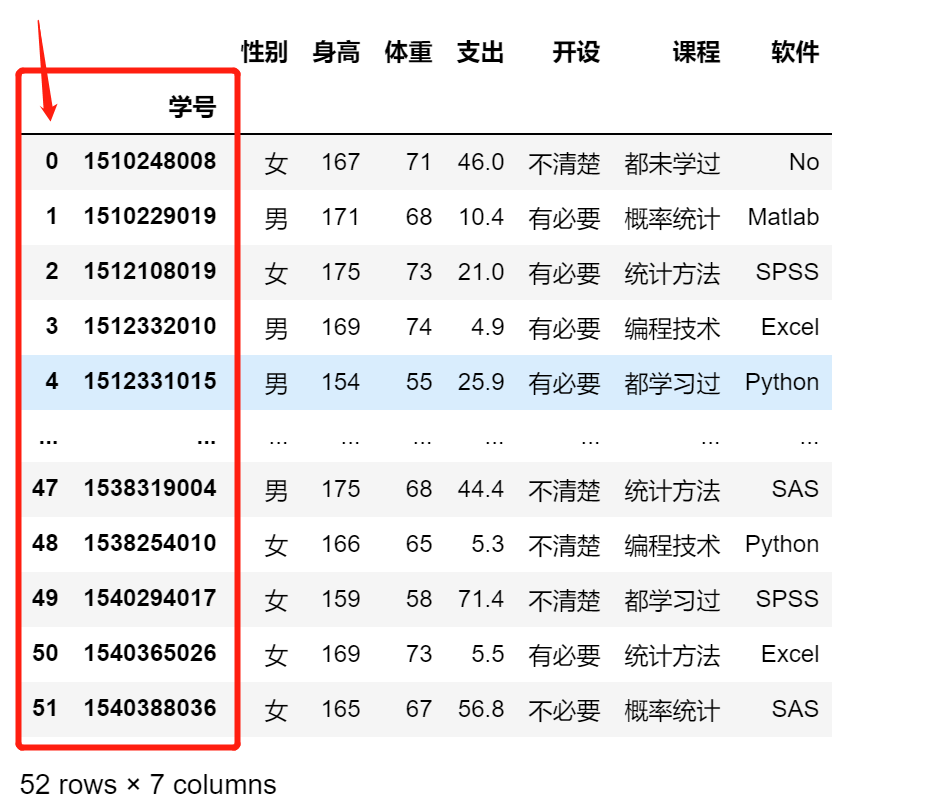
df.set_index(keys='学号',drop=False)
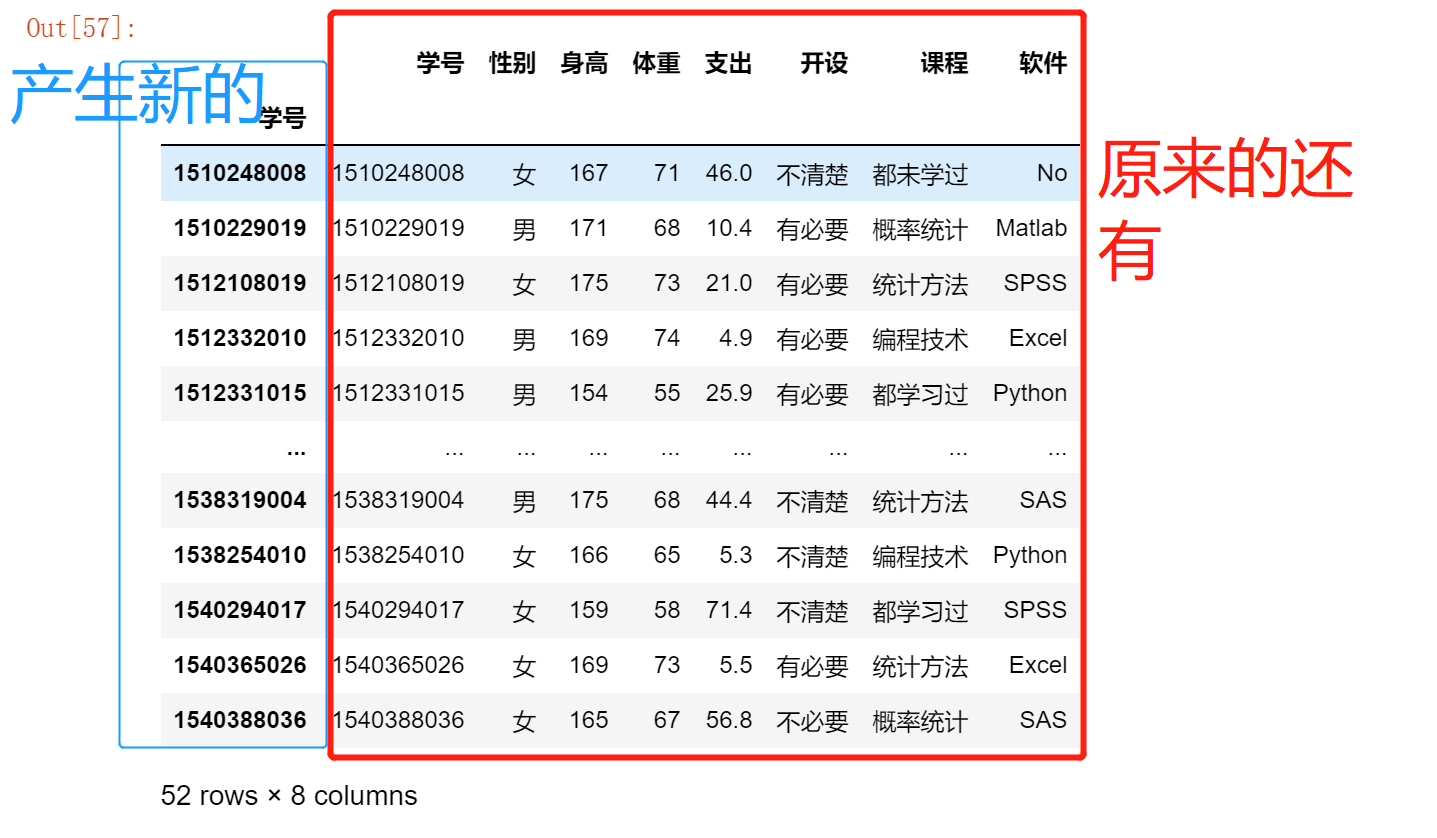
df.set_index(keys=['学号','性别'])
4.2 将索引还原变量列
df.reset_index(
drop = False :是否将原索引直接删除,而不是还原为变量列
inplace = False :是否直接修改原数据框
)
用法:
df.reset_index()
df.reset_index( drop = True)
4.3 引用和修改索引
4.3.1 引用索引
注意:索引仍然是有存储格式的,注意区分数值型和字符型的引用方式
df.index
4.3.2 修改索引
1.修改索引名
本质上和变量列名的修改方式相同
2.修改索引值
这里的修改本质上是全部替换
df4 = pd.read_excel('stu_data.xlsx')
df5 = df.set_index(keys = ['学号','性别'])
df5.index

df4 = pd.read_excel('stu_data.xlsx')
df5 = df.set_index(keys = ['学号','性别'])
df5.index.names = ['no','sex']
df5
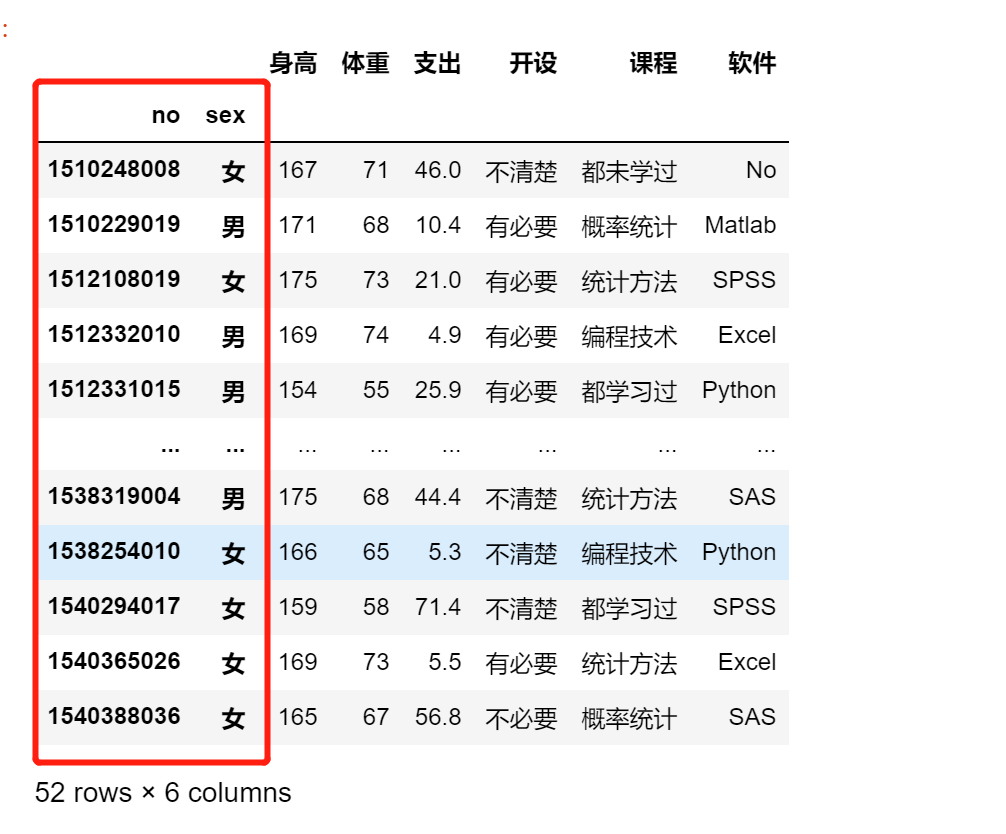
df4 = pd.read_excel('stu_data.xlsx')
df5 = df.set_index(keys = ['学号','性别'])
df5.index.names = [None,None]
df5
4.3.3 更新索引
reindex 则可以使用数据框中不存在的数值建立索引,并据此扩充新索引值对应的索引行/列,同时进行缺失值填充操作
df.reindex(
labels :类数组结构的数值,将按此数值重建索引,非必需
copy = True :建立新对象而不是直接更改原 df/series
缺失数据的处理方式
method :针对已经排序过的索引,确定数据单元格无数据时的填充方法,非必需
pad / ffill:用前面的有效数值填充
backfill / bfill:用后面的有效数值填充
nearest:使用最接近的数值逬行填充
fill_value = np.NaN :将缺失值用什么数值替代
limit = None :向前/向后填充时的最大步长
)
用法:
import pandas as pd
df = pd.DataFrame({
'name':['zs','ls','ww'],
'level':['vip1','vip2','pm']
})
df.reindex([0,1,3])

df.reindex([0,1,2,3],method='ffill')
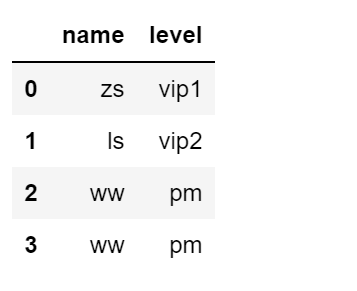
df.reindex([0,1,2,3],fill_value="test")

5 案例的基本操作
5.1 案例排序
5.1.1 用索引排序
df.sort_index(
level :(多重索引时)指定用于排序的级别顺序号/名称
ascending = True :是否为升序排列,多列时以表形式提供
inplace = False :
na_position = 'last' :缺失值的排列顺序,f irst/last
)
5.1.2 使用变量值排序
df.sort_values(
by :指定用于排序的变量名,多列时以列表形式提供
ascending = True :是否为升序排列
inplace = False :
na_position = 'last' :缺失值的排列顺序,f irst/last
)
用法:
import pandas as pd
df = pd.read_excel('stu_data.xlsx',index_col=[3,4])
df
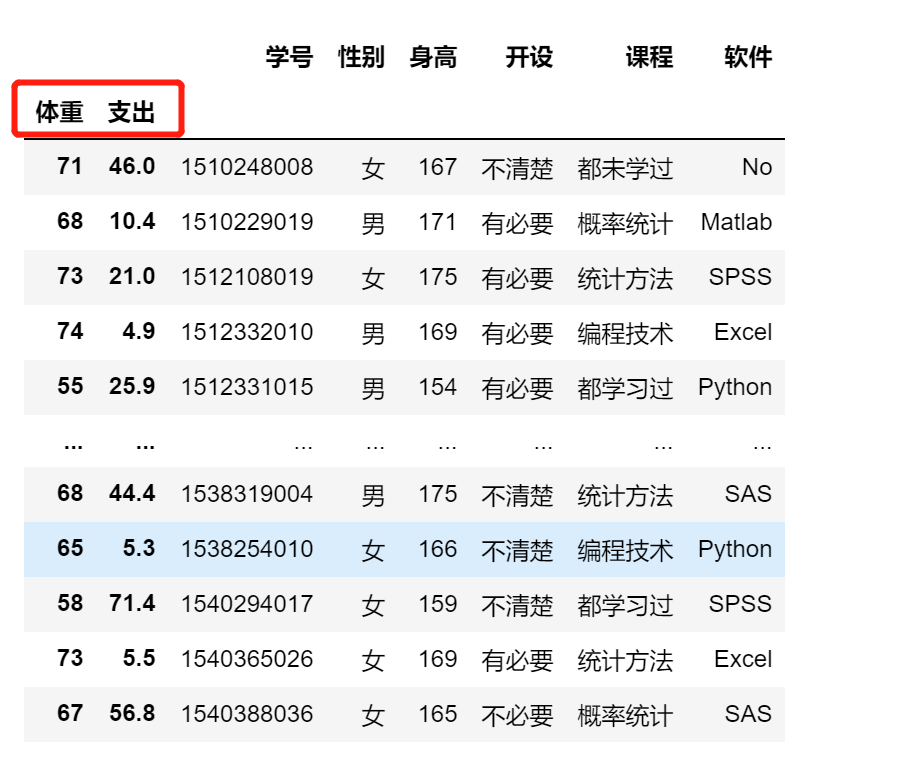
df.sort_index(ascending=False)
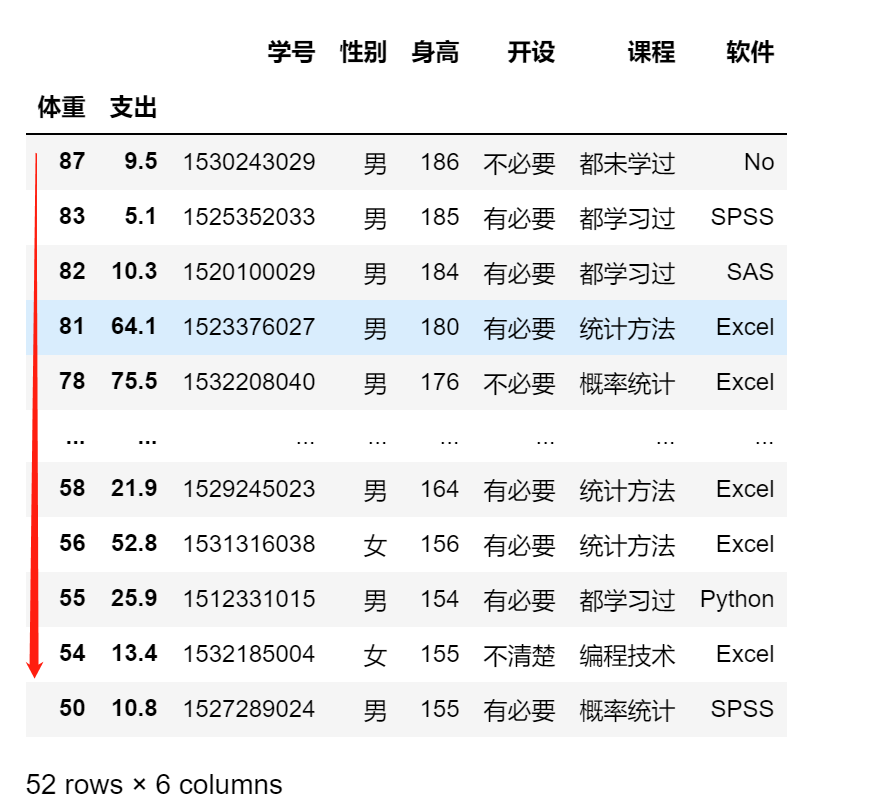
df.sort_values(by='身高')
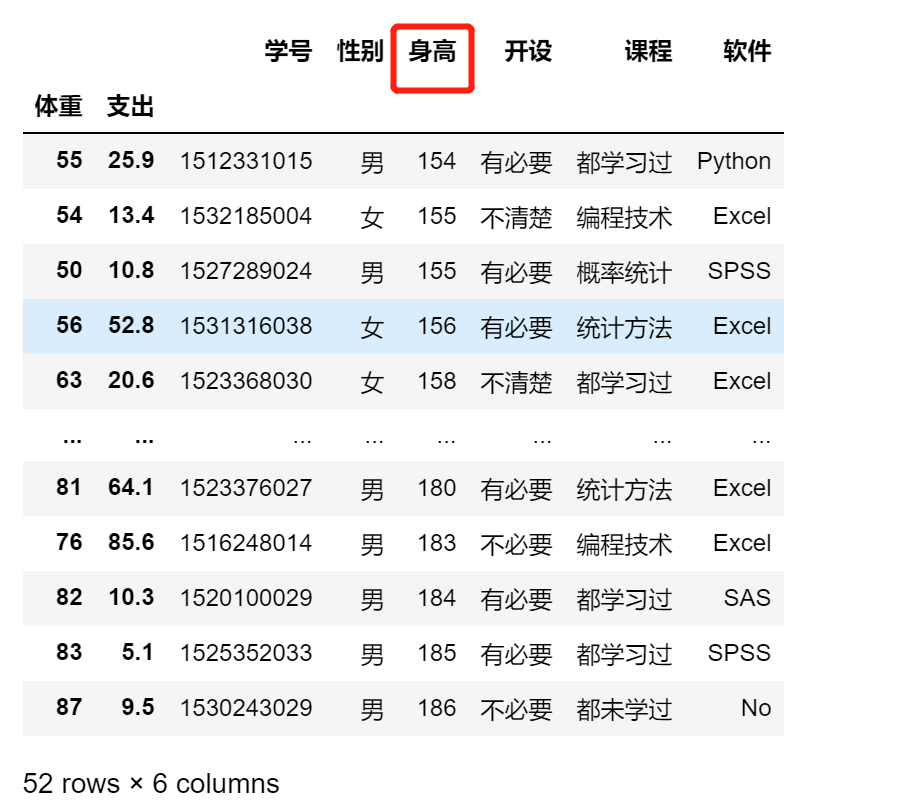
5.2 数据选择
5.2.1 列选择
选择列
当想要获取 df 中某列数据时,只需要在 df 后面的方括号中指明要选择的列即可。如果是一列,则只需要传入一个列名;如果是同时选择多列,则传入多个列名即可(注意:多个列名
用一个 list 存放)
df[col]
df[[col1 , col2]]
Python 中我们把通过传入列名选择数的方式称为普通索引
除了传入具体的列名,我们可以传入具体列的位置,即第几行,对数据进行选取,通过传入位置来获取数据时需要用到== iloc 方法==
df.iloc[,[0,2]]
df.iloc 意为 integer-location,即按照行列序号逬行检索,iloc 后面的方括号中逗号之前的部分表示要获取的行的位置,只输入一个冒号,不输入任何数值表示获取所有的行,逗号之后方括号表示要获取的列的位置,列的位置同样也是从 0 开始计数
选择连续列
当需要获取连续列时,可以通过 iloc 方法实现
df[ : ,0:3]
用法:
df['学号']
df[['学号','开设']]
df.iloc[:,[0,2]]
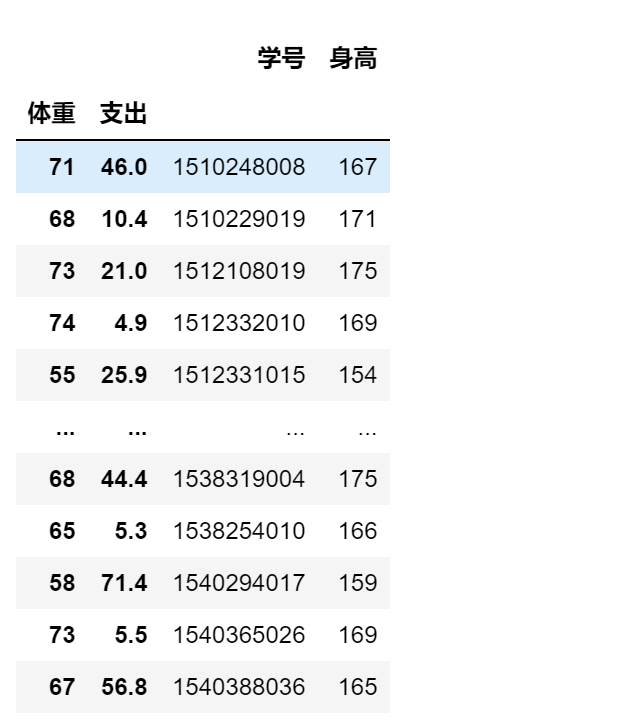
df.iloc[:,1:4]
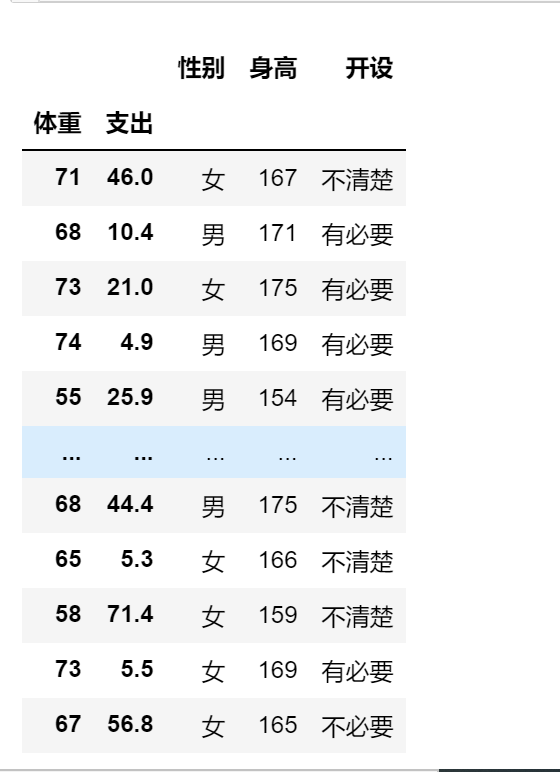
5.2.2 案例(行)的选择
获取行的方式主要有 2 种:
一种是普通索引,即传入具体索引的名称== loc 方法;==
另一种是位置索引,即传入具体的行数,需要用== iloc 方法==
- 普通索引方式loc
获取某行
df.loc[index_name]
df.loc[5]

#获取某几行
df.loc[[index_name1,index_name2]]
df.loc[[0,1]]

2.通过位置索引iloc [行,列]
df.iloc[0]

df.iloc[[3,1]]
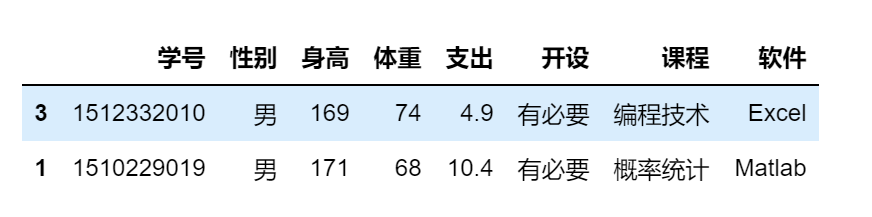
df.iloc[0:5]
条件筛选
df[df['支出']>20]
df['性别'] == '男'
df[ (df['支出']>20)& (df['性别'] == '男')]
5.2.3 混合选择
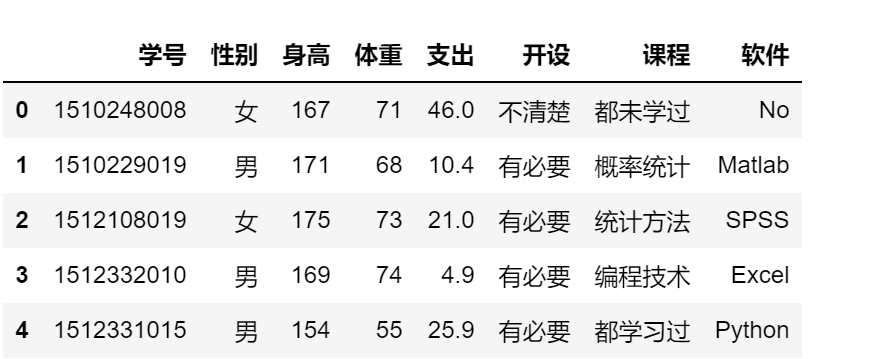
df.loc[[0,1],['学号','性别']]

df.iloc[[0,1],[0,2]]
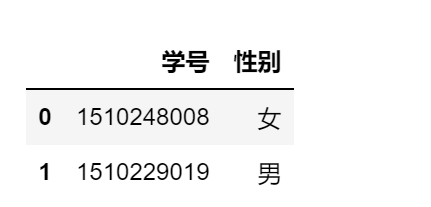
df[df['身高']>170][['学号','性别']]
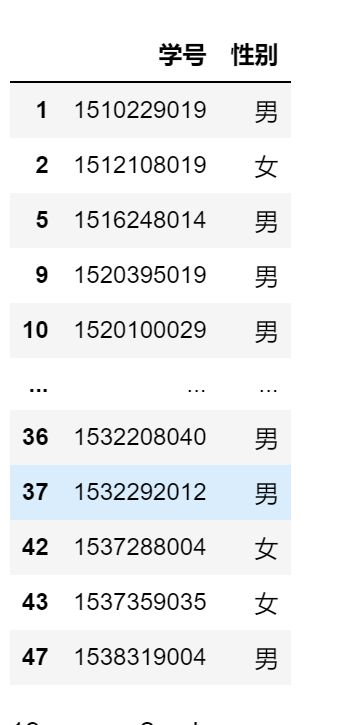
df.iloc[0:2,0:2]

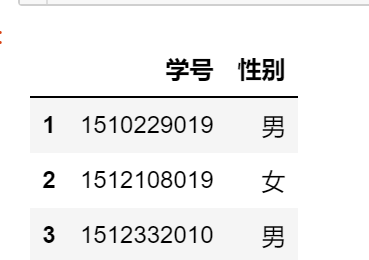
df.loc[1:3,['学号','性别']]
5.2.4 isin的筛选使用
df.isin(values) 返回结果为相应的位置是否匹配给出的 values
values 为序列:对应每个具体值
values 为字典:对应各个变量名称
values 为数据框:同时对应数值和变量名称
用法:
df.isin([167,68])
df[df.isin([167,68])]
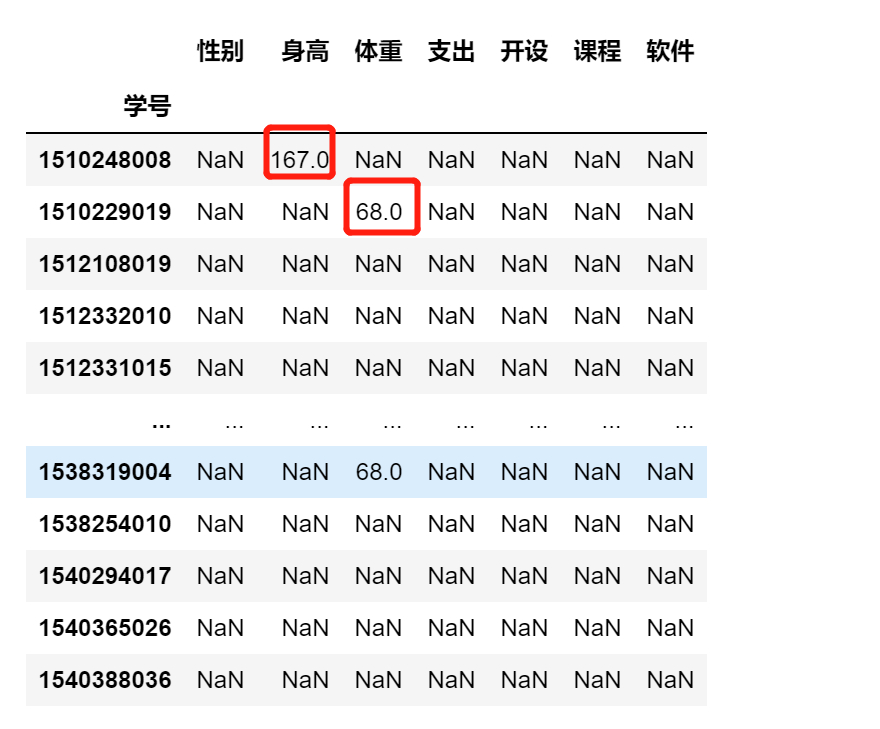
df.身高.isin([167,170])
df[df.身高.isin([167,170])]
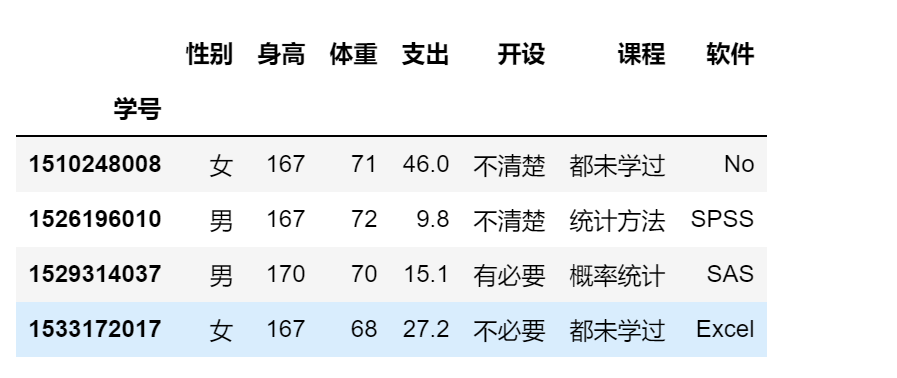
df.isin({
'身高':[167,171],
'性别':['男']
})
df2 = pd.DataFrame({
'身高':[167,171],
'性别':'男'
})
df2
5.2.5 query的使用
df.query('1540388036')
df.query('身高 > 170 and 性别 == "女" ')
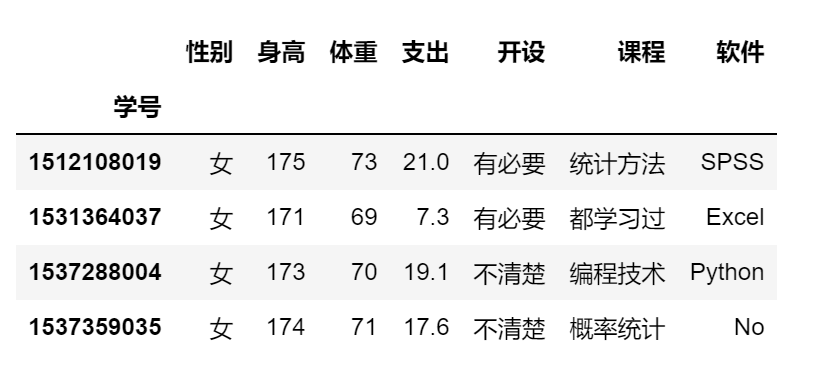
df.query('身高 > 支出')
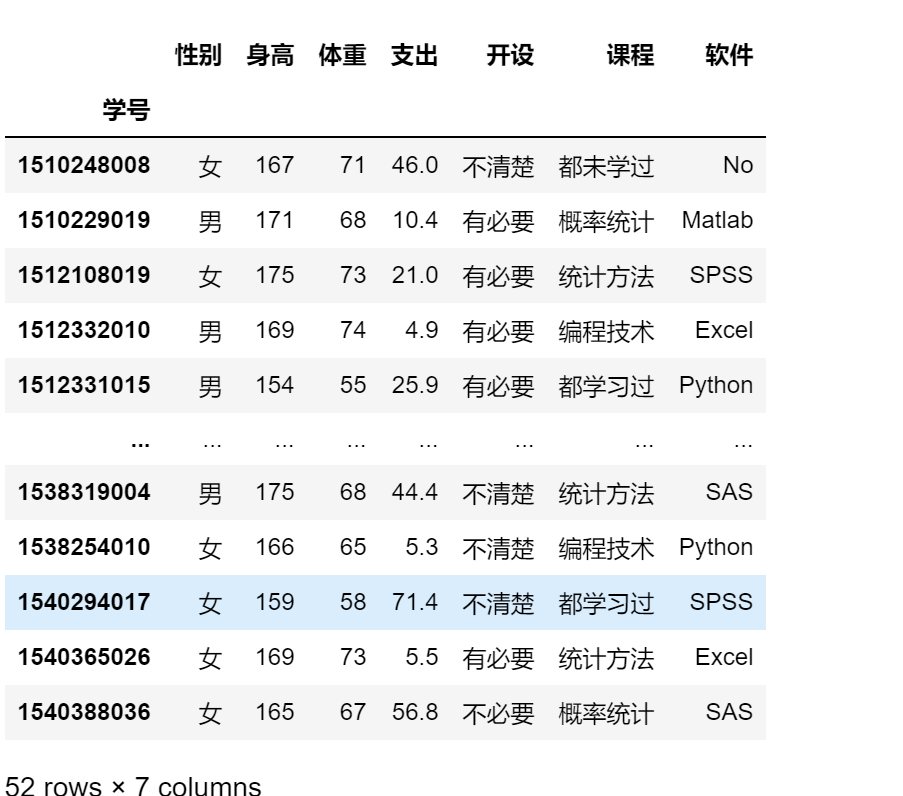
height = 180
df.query('身高 > @height ')
6 变量变换
6.1 计算新变量
6.1.1 新变量为常数
1.增加新变量
df['n1'] = 100
df
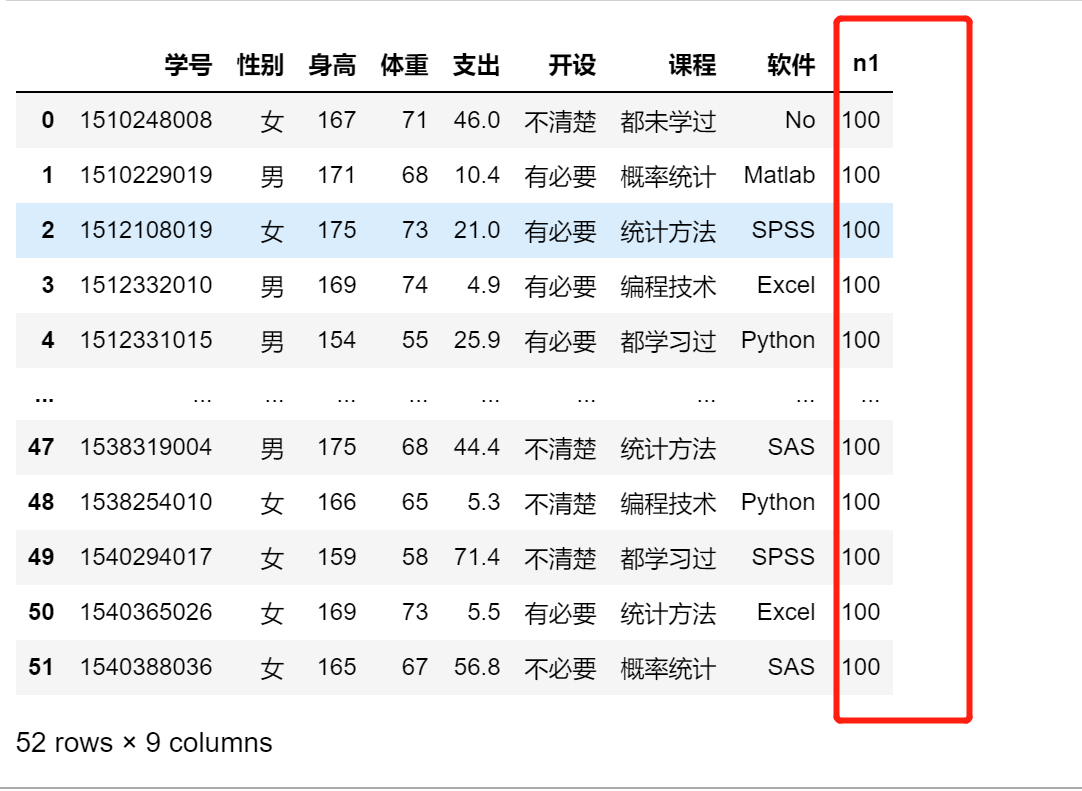
df['n2'] = df.身高 - df.体重
df

2.
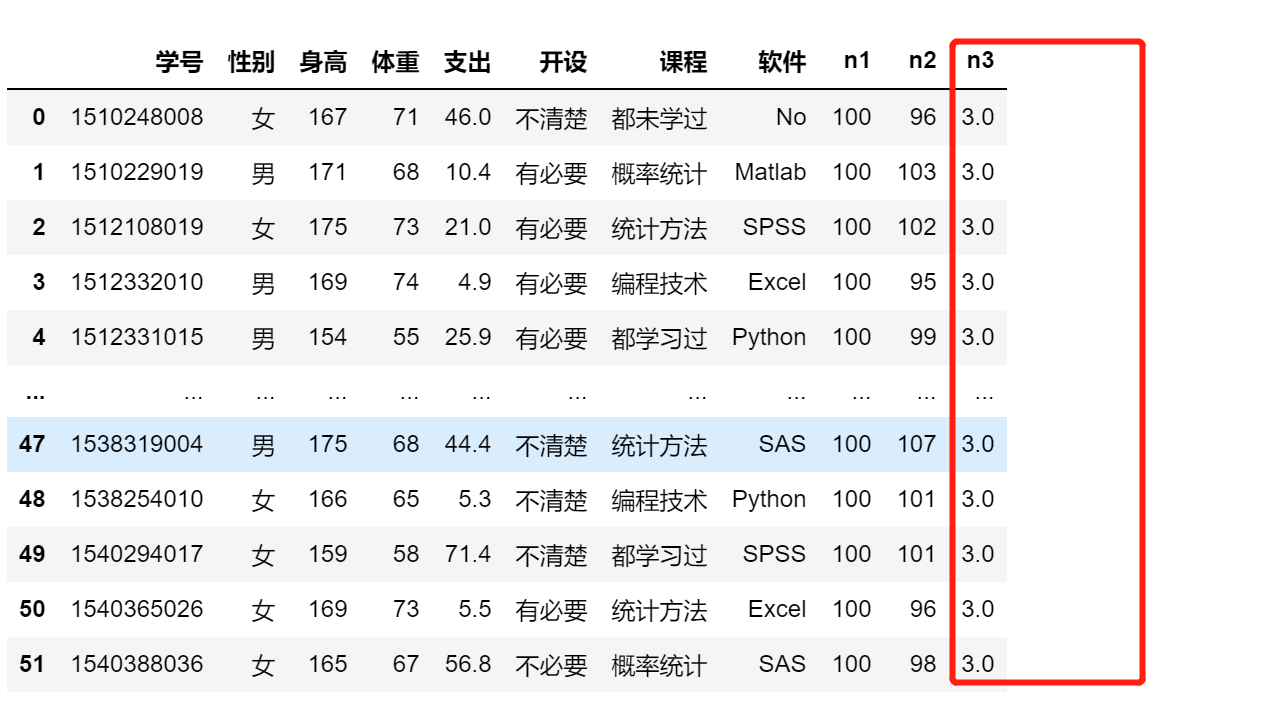
6.1.2 基于原变量做简单四则运算
使用内部函数计算
import math
df['n3'] = math.sqrt(9)
df
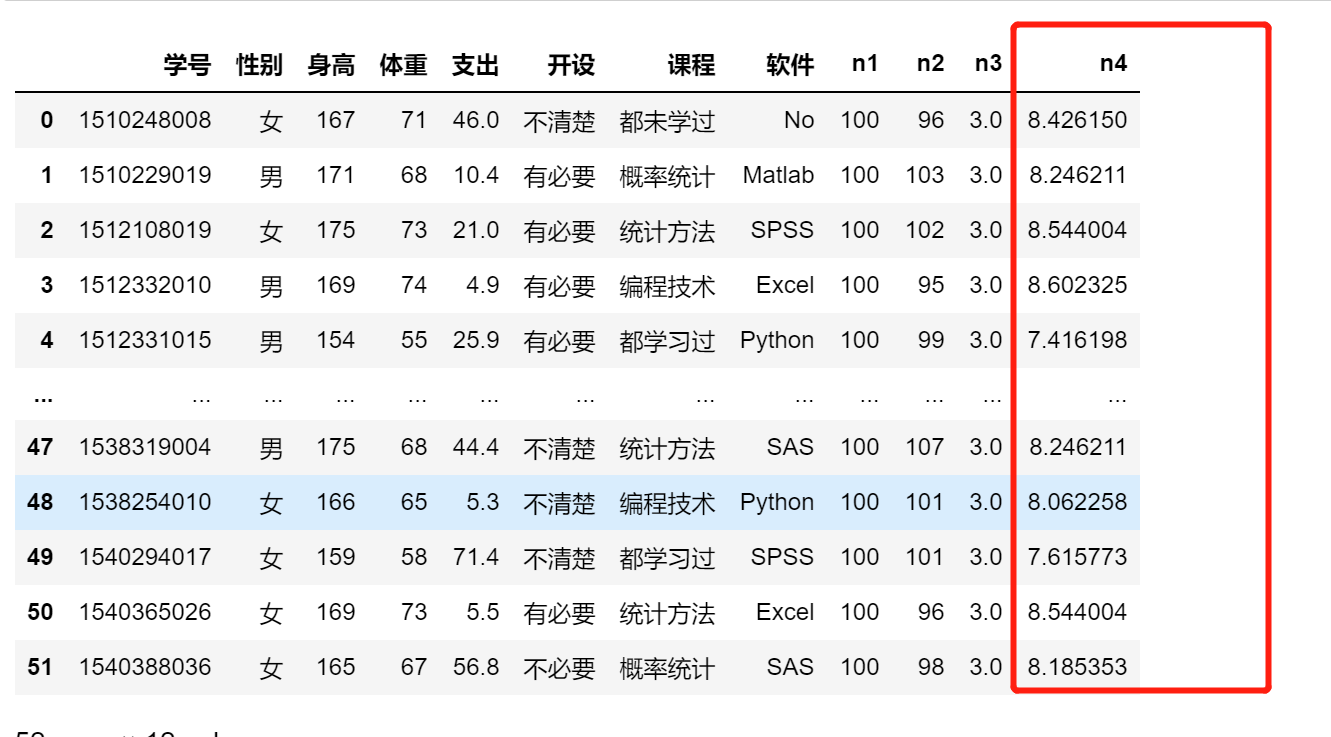
import numpy
df['n4'] = numpy.sqrt(df.体重)
df
6.1.3 基于一个原变量做函数运算
df.apply(
func : 希望对行/列执行的函数表达式
axis = 0 :针对行还是列逬行计算
0:' index':针对每列进行计算
1: ' columns ':针对每行逬行计算
)
简化的用法
df [' varname ' ] = df. oldvar. apply (函数表达式)
import math
使用自定义函数
- 特殊运算的实现方式
例:取变量的第一个字符
def m_head(temp_str):
return tmpstr[:1]
用法:
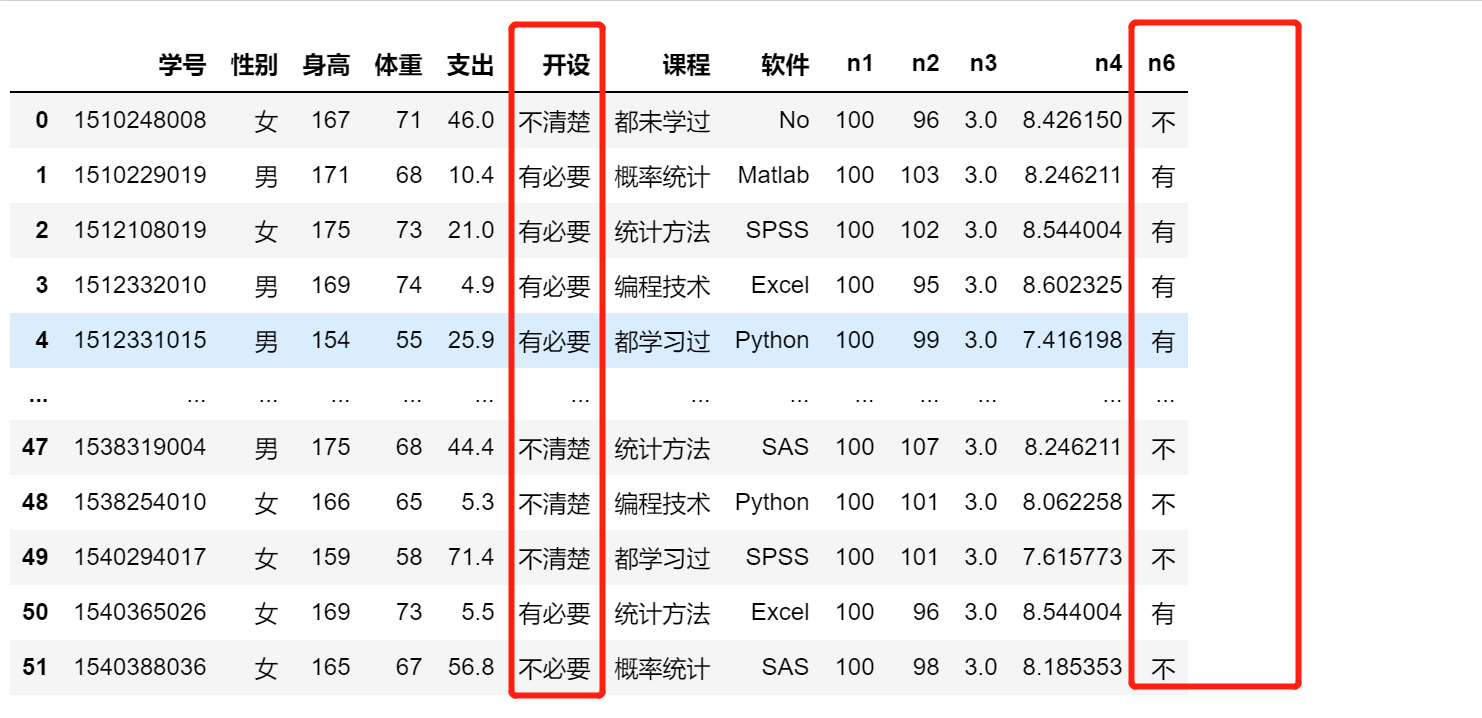
def get_first(tmp):
return tmp[:1]
df['n6'] = df.开设.apply(get_first)
df
- 对所有单元格进行相同的函数运算
df_new = df .applymap (函数表达式)
df [['col1','col2']].applymap (math.sqrt)
- 不修改原 df,而是生成新的 df
df.assign(varname = expression)
df_new = df .assign (new = df .总分.apply (math, sqrt))
df2 = df.assign(n8 = df.课程.apply(get_first))
df2
6.2 在指定位置插入新变量列
df.insert(
loc :插入位置的索引值,0 loc len (columns)
column :插入的新列名称
value : Series 或者类数组结构的变量值
allow_duplicates = False :是否允许新列重名
)
df.insert(1, ‘new_var’, ‘cons’)
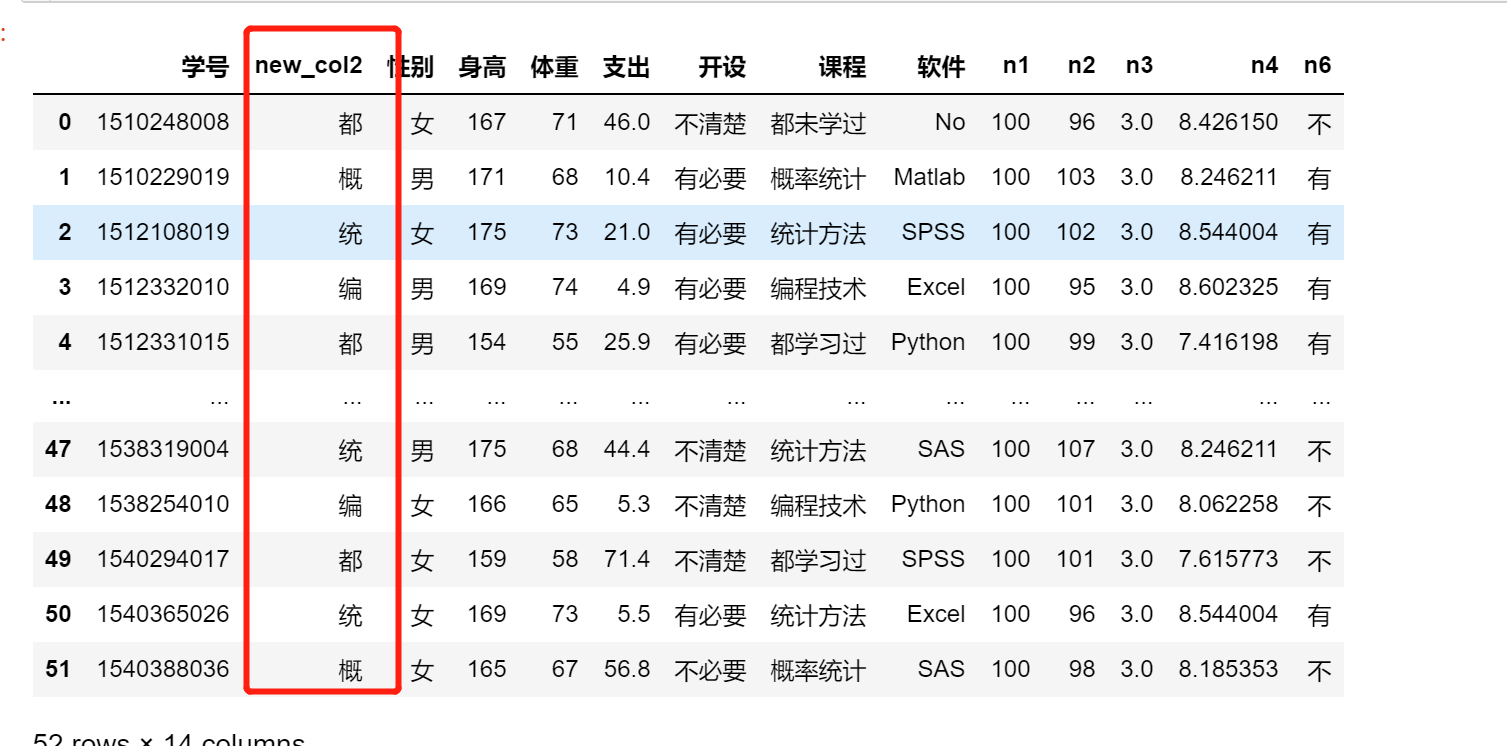
df.insert(1,'new_col2',df.课程.apply(get_first))
df
6.3 修改/替换变量值
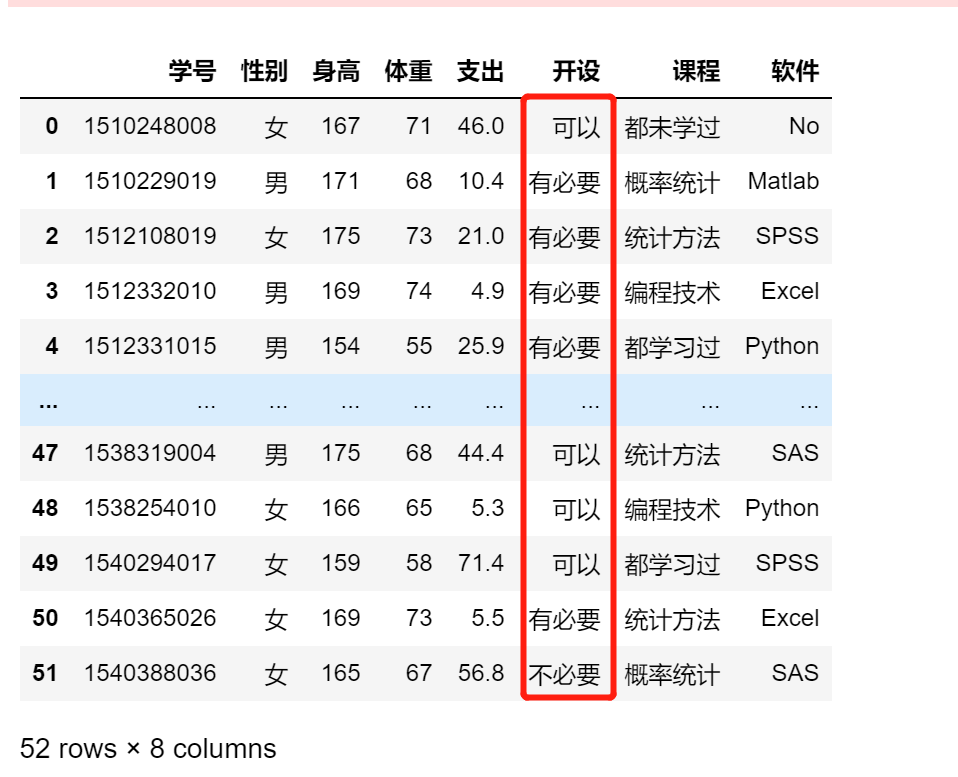
本质上是如何直接指定单元格的问题,只要能准确定位单元地址,就能够做到准确替换
df.开设[df.开设.isin(['不清楚'])] = '可以'
替换单个数据
df.体重[1] = 78
把'体重'的第一个数据改为68
df['体重'][1] = 68
6.3.1 对应数值的替换
df.replace(
to_replace = None :将被替换的原数值,所有严格匹配的数值将被用 value 替换,可以
str/regex/list/dict/Series/numeric/None
value = None :希望填充的新数值
inplace = False
)
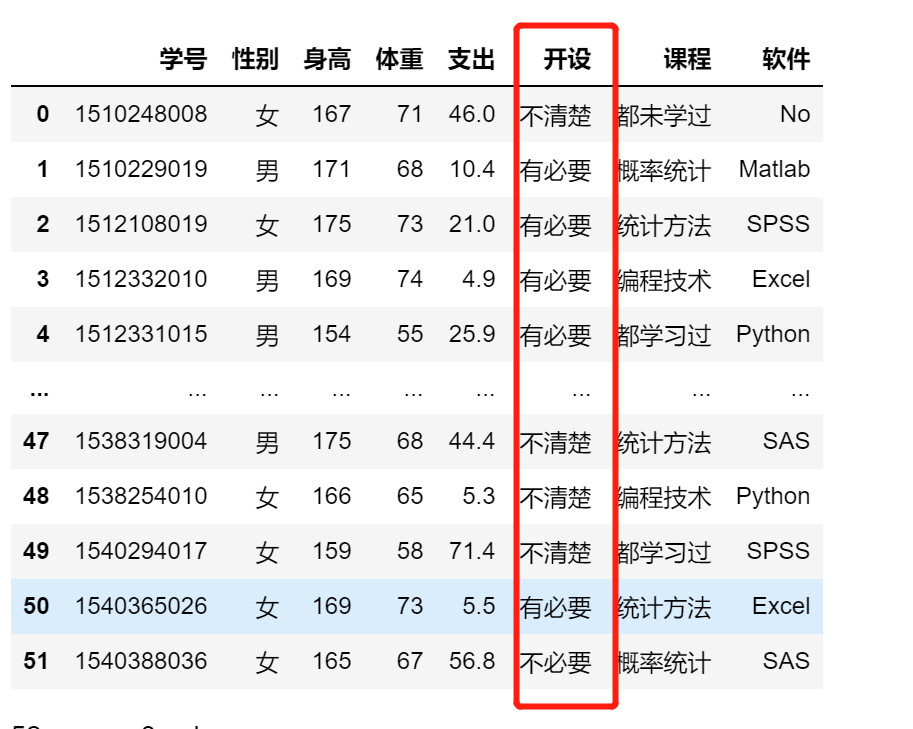
df.开设.replace('可以','不清楚',inplace = True)
列表值批量替换
df.性别.replace(['女','男'],[0,1],inplace = True)
字典批量映射替换
df.性别.replace({0:'女',1:'男'},inplace = True)
6.3.2 指定数值范围的替換
方法一:使用正则表达式完成替换
df.replace(regex=正则, newvalue=修改的目标数据)
用法:
df.开设.replace(regex = '不.+',value = '可以',inplace = True)
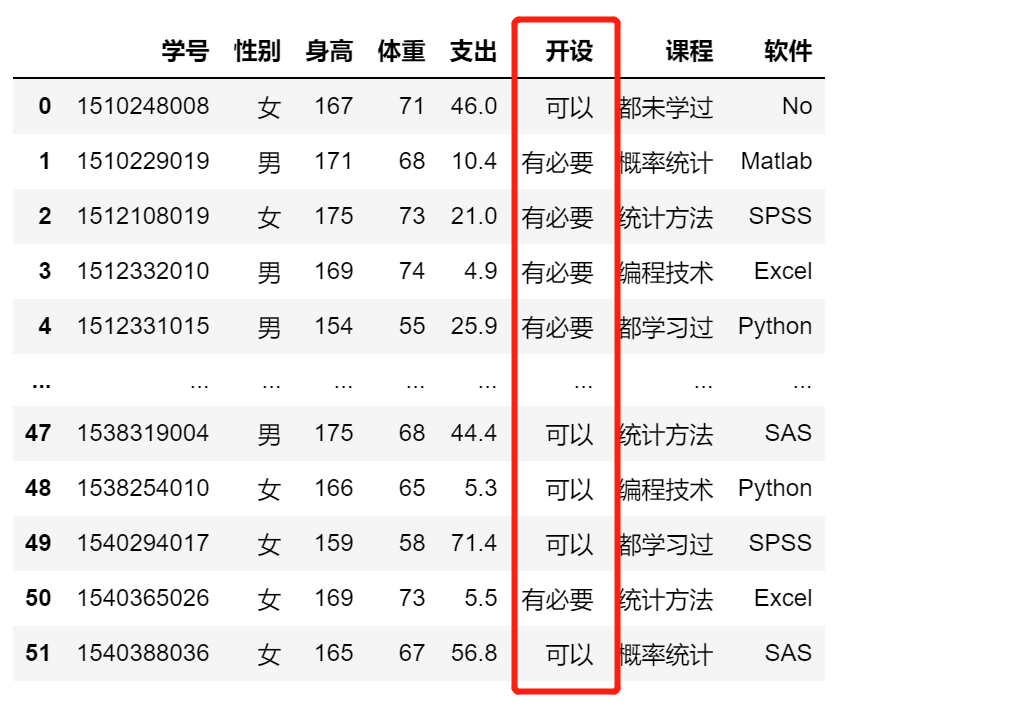
方法二:使用行筛选方式完成替换
用行筛选方式得到行索引,然后用 loc 命令定位替换
目前也支持直接筛选出单元格进行数值替换
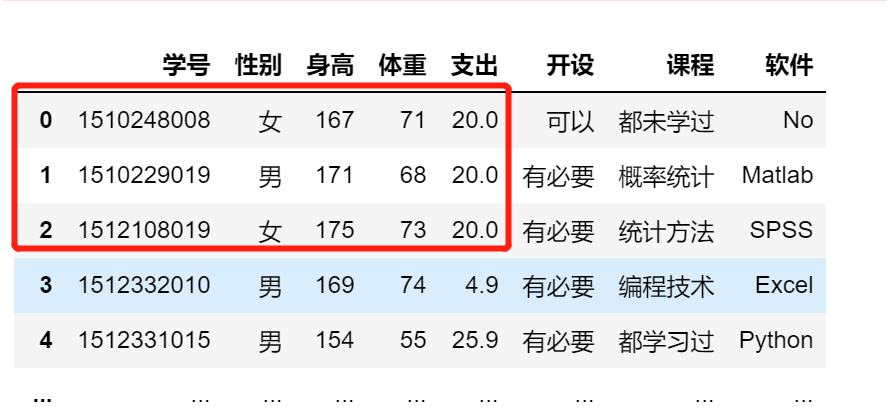
df.支出.iloc[0:3] = 20
df.支出.loc[0:2] =20
df
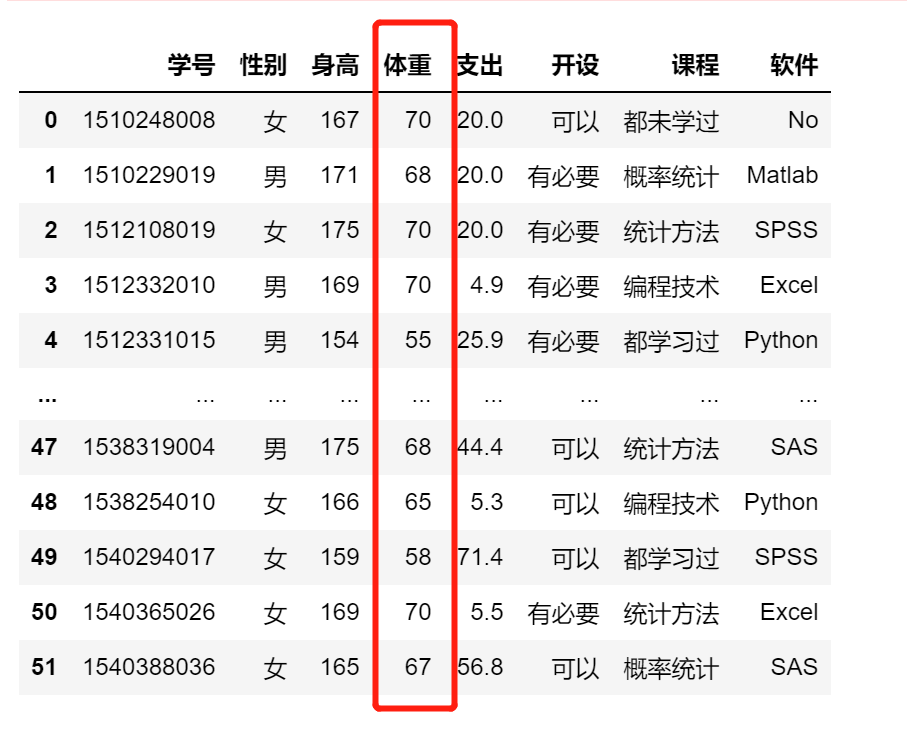
df.体重[df.体重>70] =70
注意:query 命令的类 SQL 语句可以逬行检索,但不直接支持数值替换
df.loc[df.query('性别 == "女" and 体重 > 60 ').体重.index,'体重'] = 50
df
6.4 虚拟变量变换
pd.get_dummies(
data :希望转换的数据框/变量列
prefix = None :哑变量名称前缀
prefix_sep = 11 :前缀和序号之间的连接字符,设定有prefix 或列名时生效
dummy_na = False :是否为 NaNs 专门设定一个哑变量列
columns = None :希望转换的原始列名,如果不设定,则转换所有符合条件的列
drop_first = False :是否返回 k-l 个哑变量,而不是 k 个哑变量
)
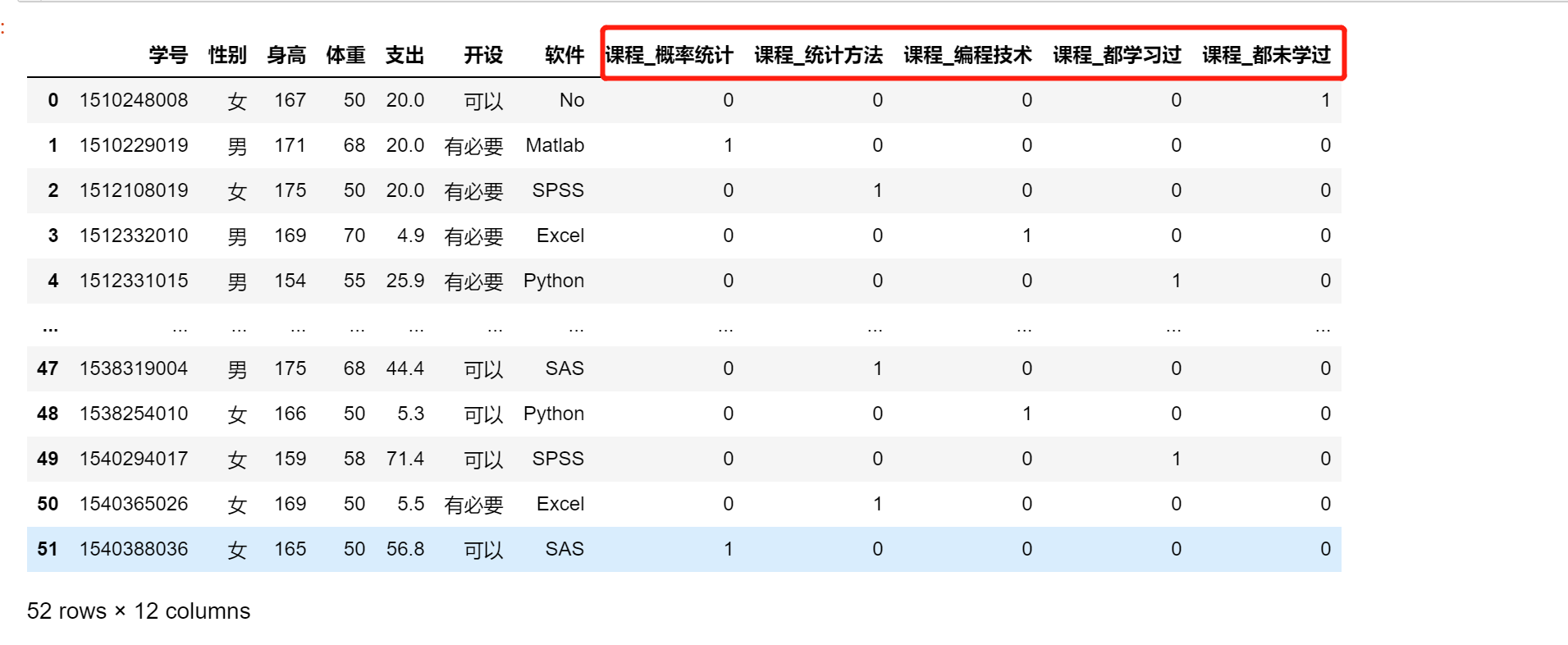
用法:
pd.get_dummies(df,columns=['课程'])
pd.get_dummies(df.课程,'pre')
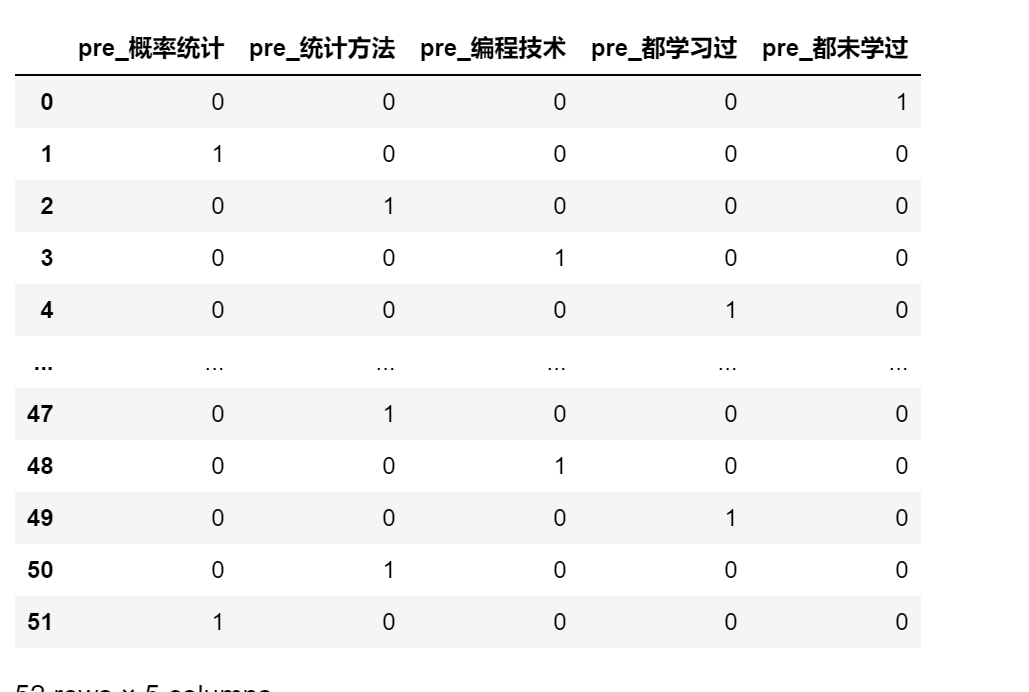
6.5 数值变量分段
pd.cut()
pd.cut(
X :希望逬行分段的变量列名称
bins :具体的分段设定
int :被等距等分的段数
sequence of scalars :具体的每一个分段起点,必须包括最值,可不等距
right = True :每段是否包括右侧界值
labels = None :为每个分段提供自定义标签
include_lowest = False :第一段是否包括最左侧界值,需要和 right 参数配合
)
pd.qcut
pd.qcut
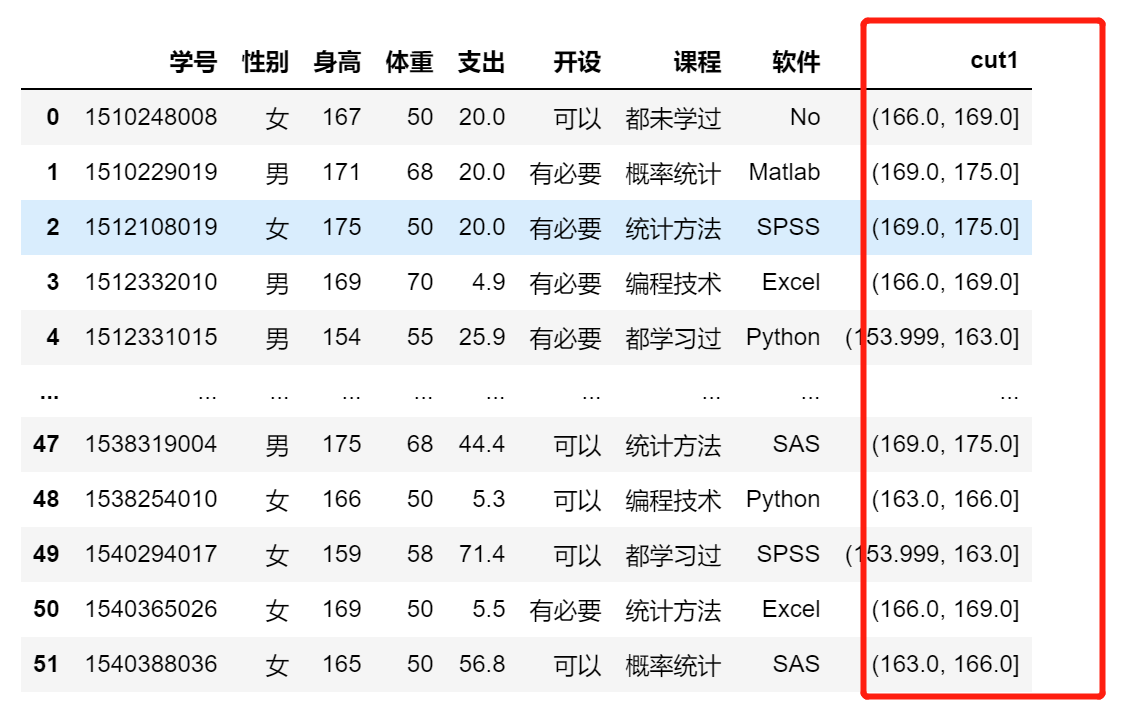
均分
df['cut1'] = pd.qcut(df.身高,q=5)
df
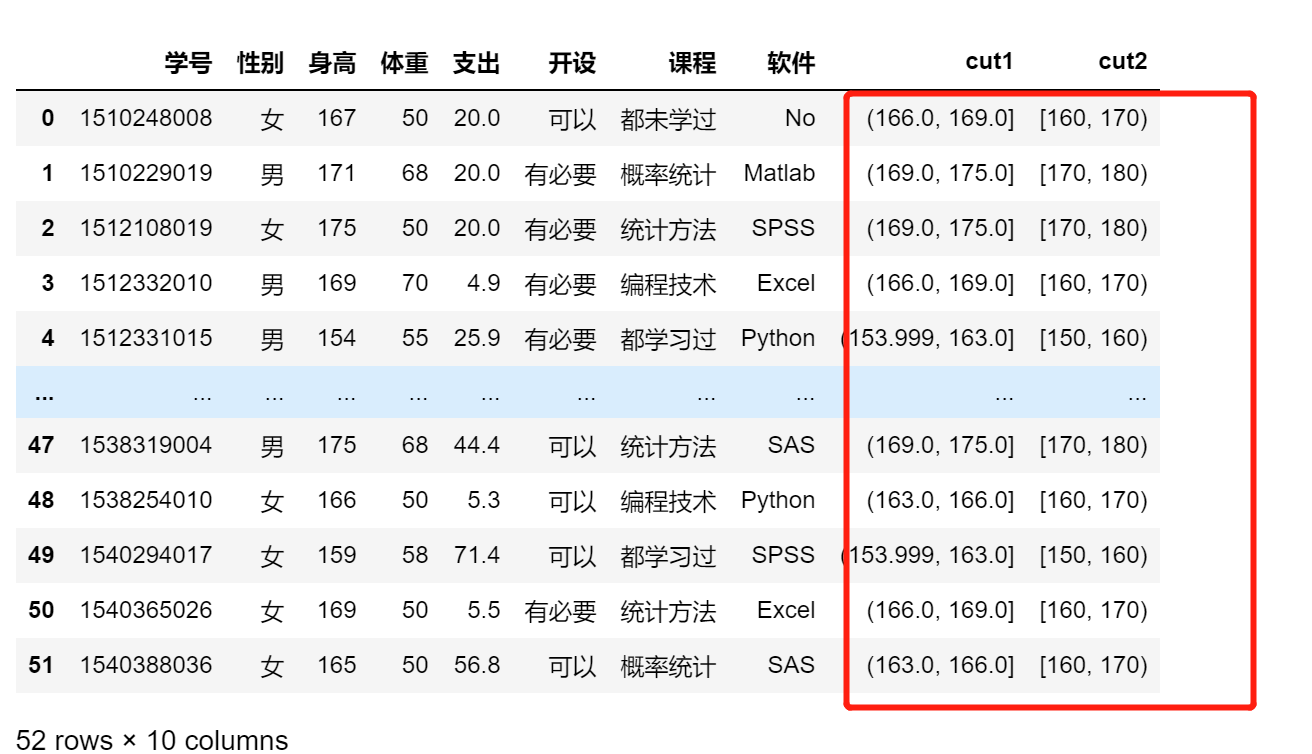
自定义
df['cut2'] = pd.cut(df.身高,bins=[150,160,170,180,190],right=False)
df
Original: https://blog.csdn.net/weixin_52720197/article/details/115418850
Author: 不太累的码农
Title: Pandas 最全的使用方式(上)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/739511/
转载文章受原作者版权保护。转载请注明原作者出处!