

配套免费资源地址:https://download.csdn.net/download/qq_52053775/86757972
给个好评吧!
1.常用操作
(1).创建dataframe
data = pd.DataFrame({'group':['a','a','a','b','b','b','c','c','c'],
                    'data':[4,3,2,1,12,3,4,5,7]}) 
axis:{0 or ‘index’, 1 or ‘columns’}, default 0,默认按照索引排序,即纵向排序,如果为1,则是横向排序
by:str or list of str;如果axis=0,那么by=”列名”;如果axis=1,那么by=”行名”;
ascending:布尔型,True则升序,可以是[True,False],即第一字段升序,第二个降序
inplace:布尔型,是否用排序后的数据框替换现有的数据框
kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心
na_position : {‘first’, ‘last’}, default ‘last’,默认缺失值排在最后面
(2).删除重复项
DataFrame.drop_duplicates(subset=None, keep=’first’, inplace=False, ignore_index=False)
subset – 指定特定的列 默认所有列
keep:{‘first’, ‘last’, False} – 删除重复项并保留第一次出现的项 默认第一个
keep=False – 表示删除所有重复项 不保留
inplace – 是否直接修改原对象
gnore_index=True – 重置索引 (version 1.0.0 才有这个参数)
(3).映射
food2Upper = {
'A1':'A',
'A2':'A',
'B1':'B',
'B2':'B',
'B3':'B',
'C1':'C',
'C2':'C'
}
data['upper'] = data['food'].map(food2Upper)
data


(4) 添加一列并迭代赋值
datafame.assign()
df2 = df.assign(ration = df['data1']/df['data2'])

(5) 删除一列
df.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
- labels:指示标签,表示行标或列标;
- axis = 0:默认取 0,表示删除集合的行;
- axis = 1:删除集合中的列;
- index:删除行;
- columns:删除列;
- level:针对有两级行标或列标的集合;如下图,集合有两级行标;
- level = 1:表示按第2级行删除整行;(即speed、weight、length)
- level = 0:默认取 0,表示按第1级行标删除整行;(即speed、cow、falcon,此处一次删除 3 行数据)

(6) pd.Series( data=None , index=None , dtype=None , name=None , copy=False , fastpath=False )
Pandas 主要的数据结构是 Series(一维)与 DataFrame(二维)
Series是带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据,
轴标签统称为索引.。
Pandas会默然用0到n-1来作为series的index,但也可以自己指定index(可以把index理解为dict里面的key)。
调用 pd.Series 函数即可创建 Series:
name, 给Series命名, 默认name=None
dtype, 给Series里的成员指定数据类型, 默认dtype=None
(7)替换元素
data.replace(9,np.nan,inplace=True)

(8) 数据分组
pd.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates='raise')
参数解释:
x:被分割的数组数据,可以是df[col],np.array,还可以是pd.seres,list 但是数据必须是一维的
bins:被分割后的区间,有三种形式,int值(如bins=5,就是将x平均分为5位),list或者np.array(如bins=[1,2,3],则将x按照(1,2],(2,3]分割),pandas.IntervalIndex 定义要使用的精确区间
right:bool型参数,默认为True,表示是否包含区间右部
labels:给分割后的区间打标签,但是labels的长度必须和分割后的区间的长度相等
retbins:bool型的参数,表示是否将分割后的bins返回
precision:保留区间小数点的位数,默认为3
include_lowest:bool型的参数,表示区间的左边是开还是闭的,默认为false,也就是不包含区间左部(闭)
duplicates:是否允许重复区间
返回值:
分割后每个值落在的区间
group_names = ['Yonth','Mille','Old']
#pd.cut(ages,[10,20,50,80],labels=group_names)
pd.value_counts(pd.cut(ages,[10,20,50,80],labels=group_names))

(9) 空值
判断空值:df.isnull()
每列是否有空值:df.isnull().any()
每行是否有空值:df.isnull().any(axis = 1)
2.pandas 读取数据
- df.head(6) 读取前几条数据
- df.info() 返回当前的信息
- df.index 返回索引值
- df.columns 返回列名
- df.dtypes 返回列数据类型
- df.values 返回每列的值
- age = df[‘Age’] 取特定列(series结构)
- df.set_index(‘Name’) 设置索引
- .mean()/.max()/.min() 数值操作
- df.describe() 得到数据的基本统计特性
3.pandas索引
df[[‘Age’,’Fare’]][:5]
- loc 用label来去定位
- iloc 用position来去定位


bool类型的索引
pd.isin()

pd.MultiIndex.from_product()

pd.select()

pd.where()
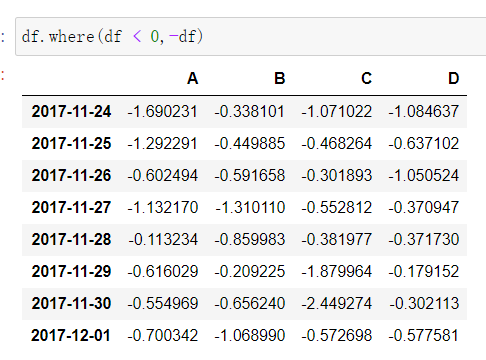
pd.query()

4.groupby操作
DataFrame.groupby (by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True,=False, **kwargs)
by :分组字段,接收list、str、mapping或generator,用于确定进行分组的键值。如果传入的是一个函数则对索引进行计算并分组;如果传入的是一个字典或者series则用字典或者series的值作为分组依据;如果传入一个numpy数组则用数据的元素作为分组依据;如果传入的是字符串或者字符串列表则用这些字符串所代表的字段作为分段依据
axis :指定切分方向,默认为0,表示沿着行切分,对列进行操作
level :表示标签所在级别,默认为None
as_index:表示聚合后的聚合标签是否以DataFrame索引形式输出,默认为True;当设置为False时相当于加了reset_index功能
sort :通过sort参数指定是否对输出结果按索引排序,默认为True
group_keys :表示是否显示分组标签的名称,默认为True
squeeze :表示是否在允许的情况下对返回数据进行降维,默认为True
数据分组就是根据一个或多个键(可以是函数、数组或df列名)将数据分成若干组,然后对分组后的数据分别进行汇总计算,并将汇总计算后的结果进行合并,被用作汇总计算的函数称为聚合函数。数据分组的具体分组流程如下图所示

import pandas as pd
df = pd.DataFrame({'key':['A','B','C','A','B','C','A','B','C'],
'data':[0,5,10,5,10,15,10,15,20]})
df

for key in ['A','B','C']:
print (key,df[df['key'] == key].sum())

df.groupby('key').sum() 


设置标签所在级别,重复值的个数

得到对应的组别:

分组计算:

5.分组运算方法
pandas提供了多种分组运算方法,包括aggregate、apply和transform,它们的用法各有不同,适用于不同的场景。
aggregate方法
前面用到的聚合函数都是直接在DataFrameGroupBy上调用的,这样分组以后所有列做的都是同一种汇总运算,且一次只能使用一种汇总方式。
aggregate的神奇之处在于,一次可以使用多种汇总方式,比如下面的例子先对分组后的所有列做计数汇总运算,然后对所有列做求和汇总运算。
aggregate方法是一个既能作用于Series、DataFrame,也能作用于GroupBy的聚合方法。aggregate方法接收函数并应用于每个分组,返回标量值,其基本语法格式如下
Groupby.aggregate(func,axis=0,args,*kwargs)
func : 指定用于集合运算的函数,具体类型包含自定义函数名、字符串函数名、列表函数名,字典函数名。该参数支持的统计函数是pandas、numpy、scipy、python提供的所有统计函数,也可以是自定义函数
axis :值为0则在列向做聚合运算,值为1则在行向做聚合运算

6.pandas数值操作
- df.sum()
- df.mean()
- df.min()
df.max() - df.median()
- df.cov() 协方差
- df.corr() 相关系数
value_counts(values,sort=True, ascending=False, normalize=False,bins=None,dropna=True)
在pandas中,value_counts常用于数据表的 计数及排序,它可以用来查看数据表中,指定列里有多少个不同的数据值,并计算每个不同值有在该列中的个数,同时还能根据需要进行排序。
sort=True: 是否要进行排序;默认进行排序
ascending=False: 默认降序排列;
normalize=False: 是否要对计算结果进行标准化并显示标准化后的结果,默认是False。
bins=None: 可以自定义分组区间,默认是否;
dropna=True:是否删除缺失值nan,默认删除
7.pandas 对象操作
series:
改值:

s1.replace(to_replace = 100,value = 101,inplace = True)


增:
df.append(other, ignore_index=False, verify_integrity=False, sort=None)
other:要追加的数据,可以是dataframe,series,字典,列表
ignore_index:两个表的index是否有实际含义,默认为False,若ignore_index=True,表根据列名对齐合并,生成新的index
verify_integrity:默认为False,若为True,创建具有重复项的索引时引发ValueError
sort:默认为False,若为True如果’ self ‘和’ other ‘的列没有对齐,则对列进行排序。

删除:
DataFrame.drop(labels = None,axis = 0,index = None,columns = None,level = None,inplace = False,errors =’raise’)
参数:
labels:引用行或列名称的字符串或字符串列表。
axis: int或string value,行为0’index’,列为1’列’。
index:单个标签或列表。索引或列是轴的替代,不能一起使用。
level:用于在数据帧具有多级索引的情况下指定级别。
inplace:如果为True,则对原始数据框进行更改。
errors:如果列表中的任何值不存在,则忽略错误,并在errors =’ignore’时删除其余值

DataFrame:
增:

pandas.concat( objs,
axis=0,
join=’outer’,
join_axes=None,
ignore_index=False,
keys=None,
levels=None,
names=None,
verify_integrity=False,
copy=True)
objs 需要连接的对象。eg: [df1, df2]
axis:默认为0。axis = 0, 表示在水平方向(row)进行连接 axis = 1, 表示在垂直方向(column)进行连接
join:默认为”outer”,outer为并集/inner为交集。
ignore_index:ignore_index 忽略需要连接的frame本身的index。当原本的index没有特别意义的时候可以使用。
join_axes:Index对象列表。用于其他n-1轴的特定索引,而不是执行内部/外部设置逻辑。
keys:可以给每个需要连接的df一个label。
levels:序列列表,默认值无。用于构建MultiIndex的特定级别(唯一值)。否则,它们将从键推断。
names:list,default无。结果层次索引中的级别的名称。
verify_integrity:boolean,default False。检查新连接的轴是否包含重复项。这相对于实际的数据串联可能是非常昂贵的。
copy:boolean,default True。如果为False,请勿不必要地复制数据。

删:

8.pd.merge()
pd.merge( left, right, how=’inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(‘_x’, ‘_y’), copy=True, indicator=False, validate=None,)
参数left和right
和pd.concat()不同,pd.merge()只能用于两个表的拼接,而且通过参数名称也能看出连接方向是左右拼接,一个左表一个右表,而且参数中没有指定拼接轴的参数,所以pd.merge()不能用于表的上下拼接。
如果需要拼接的两个表中,有相同的列信息,那么进行拼接的时候即使不指定以哪个字段作为主键函数也会默认用信息相同的列做主键对两个表进行拼接
参数on
这个参数确定哪个字段作为主键,上边提到如果有相同的列信息不指定主键也可以
参数leftindex和rightindex
除了指定字段作为主键以外,还可以考虑用索引作为拼接的主键,leftindex和rightindex默认为False,就是不以索引作为主键
参数how
how参数控制拼接方式,默认内连接(inner)
左连接是保留所有左表的信息,把右表中主键与左表一致的信息拼接进来,标签不能对齐的部分,用NAN进行填充
右连接是保留所有右表的信息,把左表中主键与左表一致的信息拼接进来,标签不能对齐的部分,用NAN进行填充
参数lefton和righton
有的时候还会有这种情况,两个表里没有完全一致的列名,但是有信息一致的列这个时候需要指定每个表中用来做主键的字段是哪一个,就用到了lefton和righton这两个参数
参数suffixes
有时候两个表中有好几个相同的列名,除了作为主键的列之外,其他名字相同的列被拼接到表中的时候会有一个后缀表示这个列来自于哪个表格,用于区分名字相同的列,这个后缀默认是(x和y)
参数indicator
在pd.concat()中可以通过参数设定显示拼接后的表中哪些信息来自于哪一个表格,在pd.merge()中也可以进行这样的操作,就是通过indicator参数设置,默认是False不显示数据来源,把参数设置为True就可以了。
9.显示设置
pandas.get_option(‘display.max_columns’)
display.[max_categories, max_columns, max_colwidth, max_dir_items, max_info_columns, max_info_rows, max_rows, max_seq_items, memory_usage, min_rows, multi_sparse, notebook_repr_html, pprint_nest_depth, precision, show_dimensions]
pd.set_option(‘display.max_columns’,30)
display.[max_categories, max_columns, max_colwidth, max_dir_items, max_info_columns, max_info_rows, max_rows, max_seq_items, memory_usage, min_rows, multi_sparse, notebook_repr_html, pprint_nest_depth, precision, show_dimensions]

10.数据透视表
pandas.pivot(data, index=None, columns=None, values=None)
indexstr 或 object 或 str 列表,可选
用于制作新框架索引的列。如果没有,则使用现有索引。
columns:str or object or a list of str
用于制作新框架的列的列。
valuesstr, object 或前一个列表,可选
用于填充新框架值的列。如果未指定,将使用所有剩余的列,并且结果将具有分层索引的列。


DataFrame.pivot_table(values=None, index=None, columns=None, aggfunc=’mean’, fill_value=None, margins=False, dropna=True, margins_name=’All’, observed=False, sort=True) [source]
参数
values :要聚合的值列,可选
_index:_列、Grouper、数组或前一个列表
如果传递一个数组,它必须与数据的长度相同。该列表可以包含任何其他类型(列表除外)。在数据透视表索引上分组的键。如果传递了一个数组,则它的使用方式与列值相同。
columns:列、Grouper、数组或前一个列表
如果传递一个数组,它必须与数据的长度相同。该列表可以包含任何其他类型(列表除外)。在数据透视表列上分组的键。如果传递了一个数组,则它的使用方式与列值相同。
aggfunc函数,函数列表,dict,默认 numpy.mean
如果传递函数列表,则生成的数据透视表将具有分层列,其顶层是函数名称(从函数对象本身推断)如果传递 dict,则键是要聚合的列,值是函数或函数列表。
fill_value标量,默认无
用于替换缺失值的值(在结果数据透视表中,聚合后)。
_margins:_布尔值,默认为 False
添加所有行/列(例如小计/总计)。
dropna:布尔值,默认为 True
不要包括其条目全部为 NaN 的列。
margins_namestr,默认”全部”
当边距为 True 时将包含总计的行/列的名称。
_observed:_布尔值,默认为 False
这仅适用于任何 groupers 是分类的。如果为真:仅显示分类分组的观察值。如果为 False:显示分类分组的所有值。

pandas.crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name=’All’, dropna=True, normalize=False)
参数
_index:_类数组、系列或数组/系列列表
行中分组依据的值。
_columns:_类数组、系列或数组/系列列表
列中分组依据的值。
values:类似数组,可选
根据因子聚合的值数组。需要指定aggfunc。
_rownames:_序列,默认无
如果通过,则必须匹配通过的行数组数。
colnames序列,默认无
如果通过,则必须匹配通过的列数组的数量。
aggfunc函数,可选
如果指定,则还需要指定值。
_margins:_布尔值,默认为 False
添加行/列边距(小计)。
margins_namestr,默认”全部”
当边距为 True 时将包含总计的行/列的名称。
dropna布尔值,默认为 True
不要包括其条目全部为 NaN 的列。
normalizebool, {‘all’, ‘index’, ‘columns’} 或 {0,1},默认 False
通过将所有值除以值的总和进行归一化。
- 如果通过 ‘all’ 或True,将对所有值进行标准化。
- 如果通过”index”将在每一行上标准化。
- 如果通过”columns”将在每一列上进行规范化。
- 如果 margins 是True,也将规范化边距值。

11.时间序列
datetime.datetime()

pd.Timestamp(‘2017-11-24’)

pd.to_datetime(‘2017-11-24’)


pd.date_range(start=’2017-11-24′,periods = 10,freq = ’12H’)

12.时间序列操作




data.between_time(’08:00′,’12:00′)

重采样:




13.pandas字符串操作
所有字符串函数都能使用

s.str.contains(‘Ag’)


14.pandas绘图
折线图:
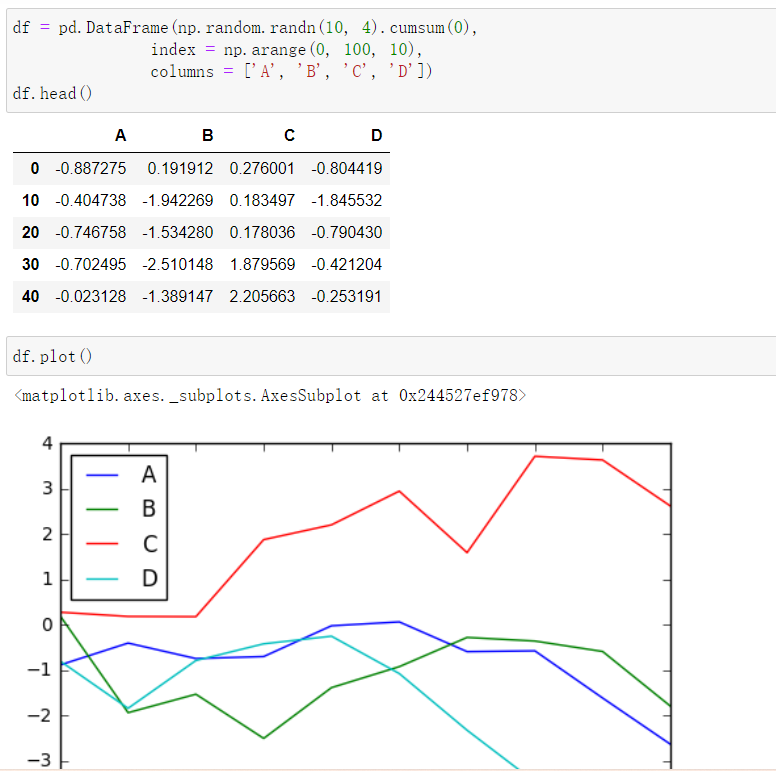
条形图:

直方图:

散点图:

散点图矩阵:

Original: https://blog.csdn.net/qq_52053775/article/details/125626554
Author: 樱花的浪漫
Title: Pandas库的使用
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/739441/
转载文章受原作者版权保护。转载请注明原作者出处!