

目录
- 查看唯一值
- 设定格式
- 创建空的DataFrame
- pandas切片指定的行和列
- pandas替代值
- 读取和存储数据时,设置索引和表头
- 转置
- 设置路径
- 重命名表头
- 合并表格
- 更改index
- 对df排序
- 查找关键词
- spyder打不开
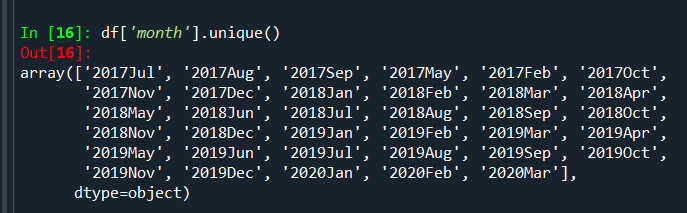
查看唯一值
df['month'].unique()

设定格式
用 Pandas 处理一个 csv 文件时,出现了一个警告:DtypeWarning: Columns (2,3) have mixed types. Specify dtype option on import or set low_memory=False.,下面记录下出现这个警告的原因和解决方法。
从警告的字面意思看是由于第 2,3 列存在多种数据类型导致的。
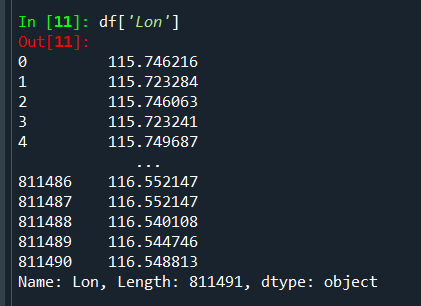
Pandas 在读取 csv 文件时时按块读取的,并不会一次性读取,并且对于数据的类型”都靠猜”,所以就可能出现了 Pandas 在不同块对同一列的数据”猜”出了不同的数据类型,也就造成了上述的警告。2 、3列为坐标,可能有些被认为是float 型,但是一些小数位过长的被认为是 str 型。
指定列的数据类型。 即可避免错误
df=pd.read_csv("data.csv",sep=',',dtype={"Lat": str, "Lon": str})
创建空的DataFrame
创建以个空表格,并且指定了表头
df=pd.DataFrame(columns=['userid','Lat','Lon','time','month','num'])
也可以创建只设置index的空DataFrame
allwords=pd.DataFrame(index=a)
pandas切片指定的行和列
如下用iloc对表格切片,提取的是0-99列,0-541行的数据
df1=df.iloc[0:542,0:100]
pandas替代值
如下,用replace将表格中所有的” “替换为0
df=df.replace(' ',0)
读取和存储数据时,设置索引和表头
读取时,设置数据有无表头,否则默认第一列为表头,并且读取的时候应设置好编码,一般为’ansi’或’utf8′
存储为csv文件的时候也可以指定是否存储索引和表头
df =pd.read_csv("data.csv",encoding='ansi',header=None)
df.to_csv("data.csv",index=False,header=None)
转置
df=df.T
设置路径
代码过长时,应该在开头设置好path,方便后面再做第二次实验修改代码
path1 = "F:\城市事件探测\数据"
df =pd.read_csv(path1+"\\data.csv",encoding='ansi',header=None)
重命名表头
[]内按顺序设置新表头
df1.columns = ['正面']
.str.replace替代部分表头
df= df.rename(columns={'old': 'new'})
合并表格
axis设置按列还是按行合并
df=pd.concat([df1,df2],axis=1)
更改index
创建一个时间list,利用index方法修改df的索引
d=pd.date_range('20190101', '20200331',freq='D')
df.index=d
对df排序
针对df中columns为27的列,进行降序排序。
ascending控制降序还是升序
df=df.sort_values(by=27,ascending=False)
查找关键词
查找并返回在”text”列中,含有word关键词的行数据
df=df[df['text'].str.contains(word)]
spyder打不开
pip install -U spyder
Original: https://blog.csdn.net/xza13155/article/details/115055245
Author: 燕南路GISer
Title: Python处理csv数据的技巧(pandas为主)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/739267/
转载文章受原作者版权保护。转载请注明原作者出处!