

DataFrame、Series
*
–
+ 从字典dict构建Series
+ 用pandas和numpy分析药店的营业数据
+ 随机数组 — 正态分布数组
+ 租房数据预处理(1)
+ 租房数据预处理(2)
+ 租房数据预处理(3)
+ 租房数据预处理(4)
+ 创建具有两层索引结构的Series对象
+ 创建具有两层索引结构的DataFrame对象
To 大数据的友友 : 代码慢慢堆 ~ 终究会起飞 ~ Except Ctrl+V ~ Salute!
从字典dict构建Series
描述
从字典dict构建Series参考输出示例输出。输出如下
a 9
b 8
c 7
d 6
dtype: int64
代码及运行结果
import pandas as pd
d = {"a":9,"b":8,"c":7,"d":6}
a_Series = pd.Series(d)
print(a_Series)
print(type(a_Series))
a 9
b 8
c 7
d 6
dtype: int64
<class 'pandas.core.series.Series'>
进程已结束,退出代码为 0
用pandas和numpy分析药店的营业数据
以下是某连锁药店销售数据,请使用numpy、pandas相关做分析。要求如下:
序号药名销量价格分店1双黄连口服液8920四季青分店2莲花清瘟胶囊4521四季青分店3藿香正气水5510四季青分店4大山楂丸6615四季青分店5感冒清热颗粒1325四季青分店6六君子胶囊3940四季青分店7生脉饮1029四季青分店8红霉素软膏565四季青分店9西洋参含片19300四季青分店10清开灵口服液9932四季青分店11十全大补胶囊8955四季青分店12四物颗粒4545四季青分店13双黄连口服液3020金源分店14莲花清瘟胶囊2121金源分店15藿香正气水5510金源分店16大山楂丸6615金源分店17感冒清热颗粒1325金源分店18六君子胶囊3940金源分店19生脉饮1029金源分店20红霉素软膏565金源分店21西洋参含片19300金源分店22双黄连口服液2020花园桥分店23莲花清瘟胶囊4521花园桥分店24藿香正气水5810花园桥分店25大山楂丸2915花园桥分店26红霉素软膏65花园桥分店27西洋参含片65300花园桥分店28清开灵口服液3832花园桥分店29十全大补胶囊755花园桥分店30四物颗粒1045花园桥分店31双黄连口服液6820人大分店32莲花清瘟胶囊2521人大分店33藿香正气水3510人大分店34红霉素软膏355人大分店35西洋参含片65300人大分店36清开灵口服液4832人大分店37十全大补胶囊3555人大分店38四物颗粒3245人大分店
1.读取附件中excel文件drug_order_detail_1.xlsx中的数据。(提示:本平台读取excel文件时,函数的工作表参数为:sheet_name。)
2.计算所有分店的总销售额并打印输出。
3.增加”销售额”列,其中,销售额=价格*销量
4.按分店统计不同分店销售额的最小值,最大值,平均值。并打印输出。
5.输出效果如下所示,其中,*号代表具体统计的数据。
所有分店总销售额是:
amin amax mean
分店
人大分店 * *
四季青分店 * *
花园桥分店 * *
金源分店 * * *
代码及运行结果
import pandas as pd
import numpy as np
df = pd.read_excel('space/drug_order_detai_1.xlsx')
df['销售额'] = df['价格'] * df['销量']
result = df.groupby('分店')['销售额'].agg([np.min, np.max, np.mean])
print('所有分店总销售额是:', df['销量'].sum(), sep='')
print(result)
所有分店总销售额是:1555
amin amax mean
分店
人大分店 175 19500 3351.375000
四季青分店 280 5700 1875.666667
花园桥分店 30 19500 2660.111111
金源分店 280 5700 1192.888889
进程已结束,退出代码为 0
随机数组 — 正态分布数组
描述
1、使用numpy库random子库随机产生四门课的成绩,随机种子数取:0x1010
2、每门课程40个成绩,分布范围为50-100分之间,要符合正态分布规则,μ=75,σ=8,学生的成绩要为整数。
3、用此成绩创建一个DataFrame对象,学生的学号范围为1001-1040,四门课程的列标签分别为’A’,’B’,’C’,’D’.行索引为学生的学号
4、输出该班级前五名学生成绩,效果如下 。
A B C D
1001 83 73 93 60
1002 78 74 81 83
1003 64 73 64 82
1004 82 76 83 81
1005 73 83 74 73
代码及运行结果
import numpy as np
import pandas as pd
np.random.seed(int(input(), 16))
data = np.random.normal(loc=75, scale=8, size=(40, 4))
df = pd.DataFrame(data.astype(np.intc), index=[i + 1001 for i in range(40)],
columns=[chr(i) for i in range(ord('A'), ord('D') + 1)])
print(df.head(5))
0x1010
A B C D
1001 83 73 93 60
1002 78 74 81 83
1003 64 73 64 82
1004 82 76 83 81
1005 73 83 74 73
进程已结束,退出代码为 0
租房数据预处理(1)
描述
1.请读取租房数据原始文件zfsj.csv,前五行数据如下图所示。
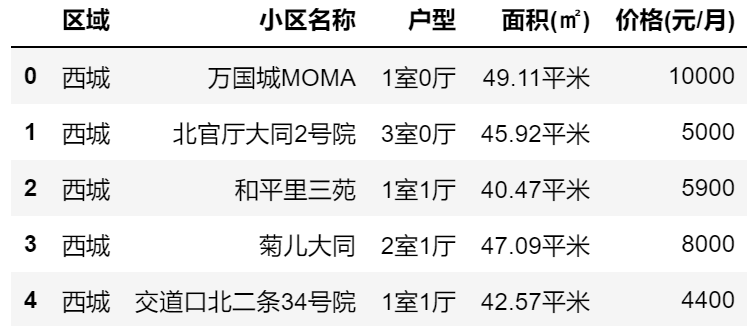

2.请对面积(㎡)列数据进行预处理,去掉”平米”单位,并设置该列数据为np.float64数据类型。
3.输出处理后的数据为zfsj2_after.csv文件,文件内前五行数据如下所示。
区域 小区名称 户型 面积(㎡) 价格(元/月)
0 西城 万国城MOMA 1室0厅 49.11 10000
1 西城 北官厅大同2号院 3室0厅 45.92 5000
2 西城 和平里三苑 1室1厅 40.47 5900
3 西城 菊儿大同 2室1厅 47.09 8000
4 西城 交道口北二条34号院 1室1厅 42.57 4400
代码
import numpy as np
import pandas as pd
file_path = open("zfsj.csv", encoding="utf-8")
file_data = pd.read_csv(file_path)
data_mj = file_data["面积(㎡)"].tolist()
data_mj = list(data_mj[i].strip('平米') for i in range(len(data_mj)))
data_mj = np.array(data_mj, dtype=np.float64)
file_data["面积(㎡)"] = data_mj
file_data.to_csv("zfsj2_after.csv", encoding="utf-8", header=True)
租房数据预处理(2)
描述
1.请读取租房数据原始文件zfsj.csv,某5行数据如下图所示。
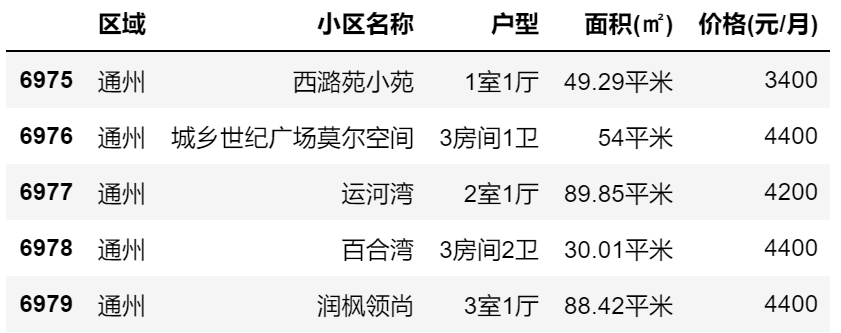
2.请对”户型”列数据进行预处理,将所有的”房间”字符修改为”室”字符。例如3房间1卫修改为3室1厅。
3.输出处理后的数据为zfsj1_after.csv文件
代码
import pandas as pd
file_path = open("zfsj.csv", encoding="utf-8")
file_data = pd.read_csv(file_path)
housetype_data = file_data["户型"].tolist()
housetype_data = list(housetype_data[i].replace('房间', '室') for i in range(len(housetype_data)))
file_data["户型"] = housetype_data
file_data.to_csv("zfsj1_after.csv", encoding="utf-8", header=True)
租房数据预处理(3)
描述
1.请读取租房数据原始文件zfsj_group.csv,某5行数据如下图所示。
2.请对”区域”列数据统计,统计结果如下。
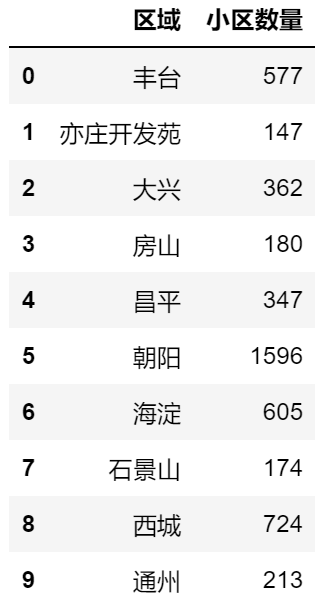
3.统计数据结果为zfsj3_after.csv文件
代码
import pandas as pd
file_path = open("zfsj_group.csv", encoding="utf-8")
file_data = pd.read_csv(file_path)
file_data.drop_duplicates(inplace=True)
df = pd.DataFrame(file_data.groupby('区域', as_index=False)['小区名称'].count())
df.rename(columns={'小区名称': '小区数量'}, inplace=True)
df.to_csv("zfsj3_after.csv", encoding="utf-8", header=True)
租房数据预处理(4)
描述
1.请读取租房数据原始文件zfsj_group.csv,某5行数据如下图所示。
2.请对”户型”列数据统计,筛选出数量大于50的户型,按数量降序,输出户型数量排名的结果如下。
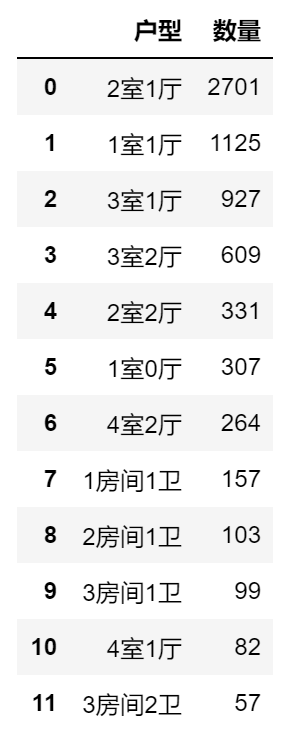
3.统计数据结果为zfsj4_after.csv文件
import numpy as np
import pandas as pd
file_path = open("zfsj_group.csv", encoding="utf-8")
file_data = pd.read_csv(file_path)
house_array = file_data["户型"]
df = pd.DataFrame(house_array)
df['num'] = 1
df = pd.DataFrame((df.groupby('户型')['num'].agg(np.sum)))
df.sort_values('num', ascending=False, inplace=True)
df.reset_index(inplace=True)
df.columns = ['户型', '数量']
df[df['数量'] > 50].to_csv("zfsj4_after.csv", encoding="utf-8", header=True)
创建具有两层索引结构的Series对象
描述
请参考编程模板完善代码,使用嵌套列表的方式创建具有两层索引结构的Series对象mulitindex_series。通过外层索引访问内层内容。
mulitindex_series如下:
运动 户外服装 1584
运动卫衣 1342
休闲鞋 1207
跑步鞋 7818
篮球鞋 7446
食品 名优白酒 6444
零食大礼包 15230
健康新零食 8269
dtype: int64
代码及运行结果
import pandas as pd
mulitindex_series = pd.Series([1584, 1342, 1207, 7818, 7446, 6444, 15230, 8269],
index=[['运动', '运动', '运动', '运动', '运动',
'食品', '食品', '食品'],
['户外服装', '运动卫衣', '休闲鞋', '跑步鞋', '篮球鞋',
'名优白酒', '零食大礼包', '健康新零食']])
x = input("")
print(mulitindex_series[x])
print(type(mulitindex_series[x]))
食品
名优白酒 6444
零食大礼包 15230
健康新零食 8269
dtype: int64
<class 'pandas.core.series.Series'>
运动
户外服装 1584
运动卫衣 1342
休闲鞋 1207
跑步鞋 7818
篮球鞋 7446
dtype: int64
<class 'pandas.core.series.Series'>
创建具有两层索引结构的DataFrame对象
描述
请参考编程模板完善代码,使用嵌套列表的方式创建创建具有两层索引结构的DataFrame对象mulitindex_df。通过外层索引访问内层内容。
mulitindex_df如下:
记录条数
运动 户外服装 1584
运动卫衣 1342
休闲鞋 1203
跑步鞋 7813
篮球鞋 7456
食品 名优白酒 6644
零食大礼包 1230
健康新零食 8269
代码及运行结果
import pandas as pd
mulitindex_df = pd.DataFrame({'记录条数': [1584, 1342, 1203, 7813,
7456, 6644, 1230, 8269]},
index=[['运动', '运动', '运动', '运动', '运动',
'食品', '食品', '食品'],
['户外服装', '运动卫衣', '休闲鞋', '跑步鞋', '篮球鞋',
'名优白酒', '零食大礼包', '健康新零食']])
x = input("")
print(mulitindex_df.loc[x, :])
print(type(mulitindex_df.loc[x, :]))
食品
记录条数
名优白酒 6644
零食大礼包 1230
健康新零食 8269
<class 'pandas.core.frame.DataFrame'>
运动
记录条数
户外服装 1584
运动卫衣 1342
休闲鞋 1203
跑步鞋 7813
篮球鞋 7456
<class 'pandas.core.frame.DataFrame'>
特此声明:【本文档内容源自互联网,仅用作学习交流,如有侵权,联系删除】
Original: https://blog.csdn.net/CSDNWV/article/details/121641665
Author: CSDNWV
Title: DataFrame、Series练习题——租房数据预处理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/739219/
转载文章受原作者版权保护。转载请注明原作者出处!