

这里,才 python 前沿。可惜是英文原版。所以,我要练习英文阅读。🧐🧐
自学并不是什么神秘的东西,一个人一辈子自学的时间总是比在学校学习的时间长,没有老师的时候总是比有老师的时候多。
—— 华罗庚
本篇学习笔记,需要有 list、dict 数据类型基础打底,如您还没了解请先行学习。如继续下看,可能有些 “吃力”。另:这是 DataFrame 的第二个数据类型,要有 DataFrame 的第一个数据类型 Series 的知识打底,请点击蓝色超链接文字跳转查看。
笔记:pandas 数据类型之 DataFrame
pandas 作为 python的数据处理模块,她是支持 python 的全部数据类型的,也同样可以定义自己的类。但 pandas 还有两个自己的数据类型 Series 、 DataFrame ,让数据在 pandas 中处理变得更得心应手。想要用 python 来处理数据,一定要”吃透” 这两个数据类型。
目录
一、 DataFrame 实例创建
二、 用 dict、Series 创建 DataFrame 实例
* list.append() 花絮
三、 插入行列
四、 赋值
四、 df.loc 方法条件筛选
五、 本笔记完整代码
例子原始数据:六名学生每天跳绳练习个数记录(4月9日至4月13,5天)。
Tom = 453, 307, 618, 742, 267
Rose = 303, 421, 512, 289, 306
John = 367, 431, 519, 279, 336
Anna = 273, 391, 512, 289, 306
Duo = 283, 371, 507, 243, 323
Liuyi = 347, 291, 472, 329, 345
数据初处理:
- 数据整合成一个列表,姓名字符列表准备好用来重置索引。
- globals() 从全局变量名字典中列表解析 names 中的变量名字符串 ( locals() 当前变量函数和 dir() 也可以从当前作用域中获取变量名字符串,前者是跟 globals() 一样是字典,后者是列表)。
- 直接对字典用一个变量遍历,就是对 key 操作(同时两个变量遍历字典,变量接收的依次是 key、value,类 doct.iters() 字典视图。),key 即是 globles() 获取的变量名字符串。
names = [Tom, Rose, John, Anna, Duo, Liuyi]
gb = globals()
names_str = [i for i in gb if gb[i] in names]
一、DataFrame 实例创建
- 默认创建
df = pd.DataFrame(names)
print(f"\n\n{' 1、数据直接生成 DatsFrame ':-^34}\n\n{df}")
运行效果
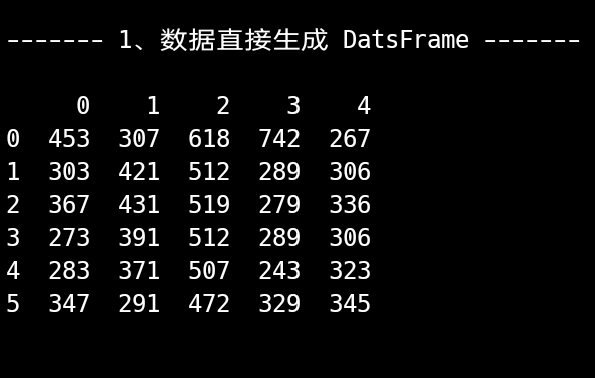

默认定义没有设置特定索引,按照惯例( Series 中已经形成的惯例)索引就是从 0 开始的整数。从上面的结果中很明显表示出来,这就是一个二维的数据结构(类似 excel 或者 mysql 中的查看效果)。
回首页
- 用姓名字符串重置索引。
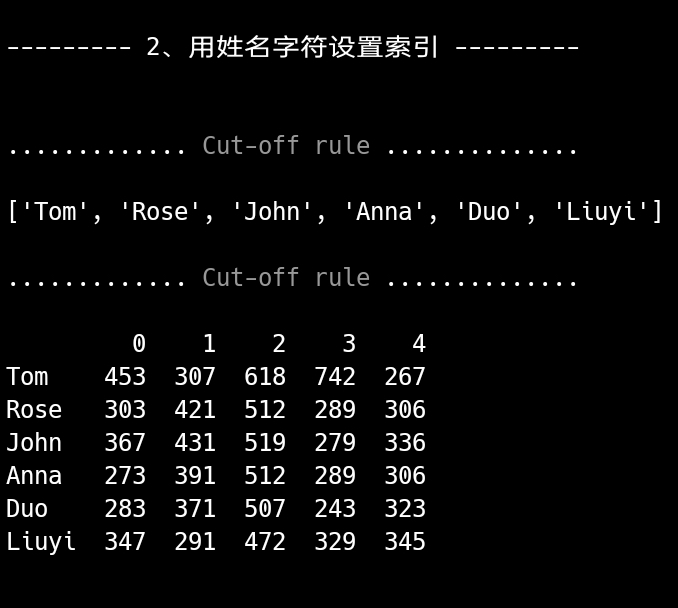
注意:”用 df.index = “重置索引,index 序列元素一定要与 DataFrame 的行数匹配,否则报错。但,创建时设置,可以”短长”少的行被舍去,多的无值为空(NaN)。
df.index = names_str
print(f"\n\n{' 2、用姓名字符设置索引 ':-^31}\
\n{cut_line()}{names_str}{cut_line()}{df}")
运行效果
回首页
用 date 重置 columns
代码
date = [f'{i}日' for i in range(9, 14)]
df.columns = date
print(f"\n\n{' 3、用 date 设置 columns ':-^37}\
\n{cut_line()}{date}{cut_line()}{df}")
运行效果
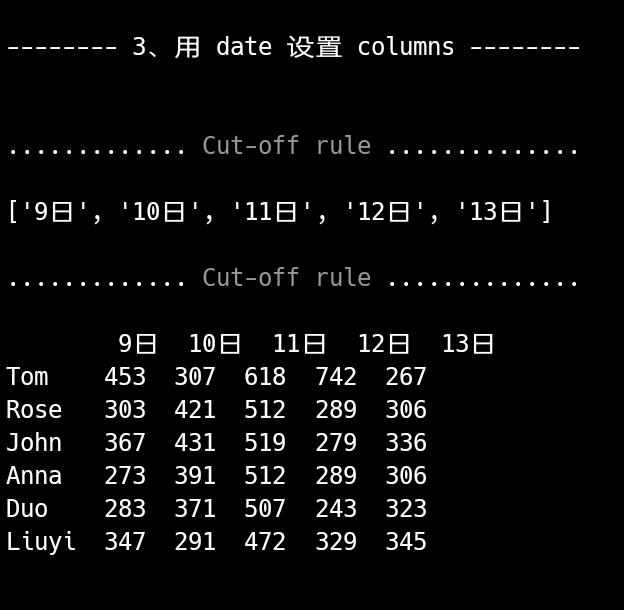
至此,终于有了数据的样子。😝
每一行为一个学生的跳绳练习数据,每一列为每日跳绳练习各个学生跳绳练习数据,这才是一个有实际意义的二维数据表格的样子。
回首页
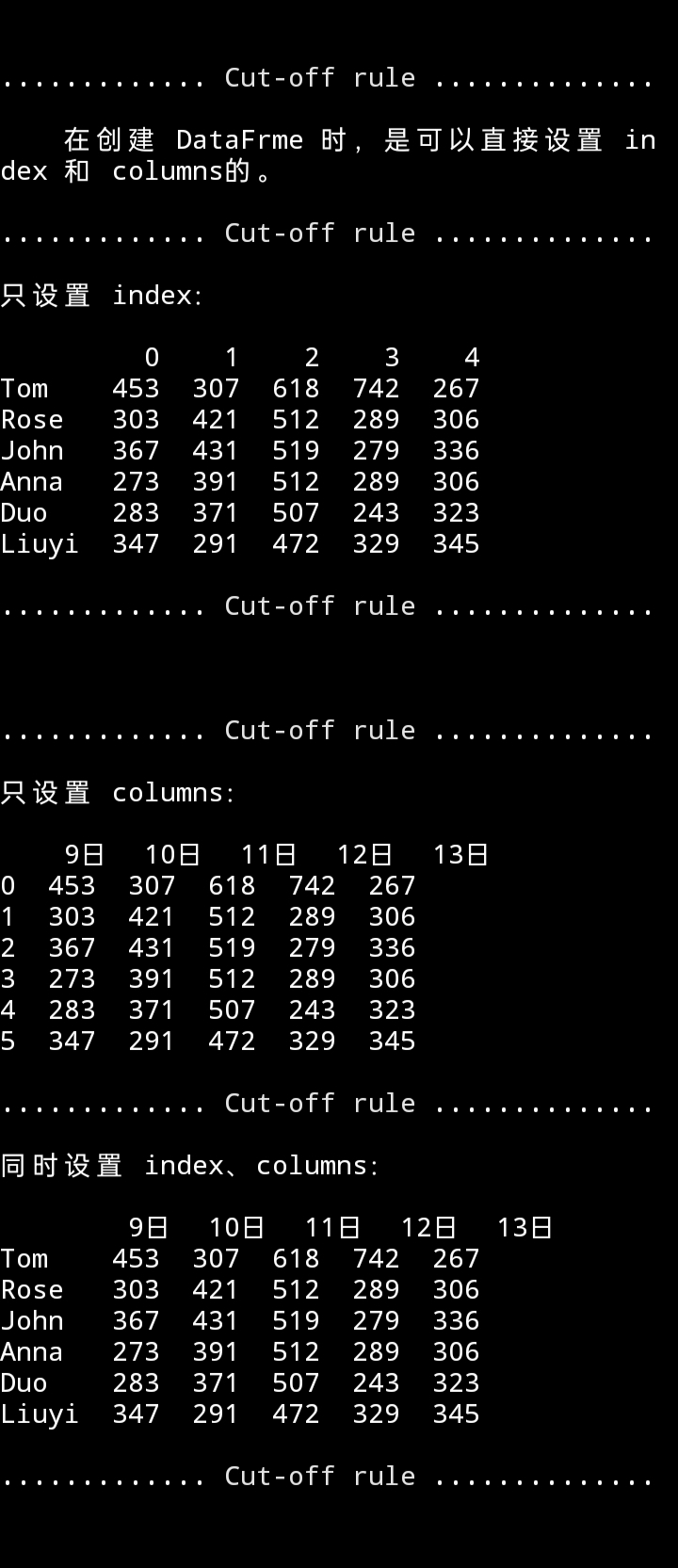
- 在创建 DataFrme 时,是可以直接设置 index 和 columns 的咯。
代码
df01 = pd.DataFrame(names, index=names_str)
df02 = pd.DataFrame(names, columns=date)
df03 = pd.DataFrame(names, columns=date, index=names_str)
print(f"\n\n{cut_line()}{'':>4}在创建 DataFrme 时,是可以直接设置 index 和 columns的。\
{cut_line()}只设置 index:\n\n{df01}{cut_line()}\
{cut_line()}只设置 columns:\n\n{df02}{cut_line()}\
同时设置 index、columns:\n\n{df03}{cut_line()}")
运行效果
回首页
二、用 dict、Series 创建 DataFrame 实例
1. Dict 创建
使用 dict 定义。这是定义一个 DataFrame 对象的常用方法。字典的”键”( names、date )就是 DataFrame 的 index、columns 的值(名称),字典中每个”键”的”值”是一个列表,它们就是那一竖列中的具体填充数据。
代码
data_dict_d = {x: y for x, y in zip(date, data_date)}
df_dict_d = pd.DataFrame(data_dict_d, index=names_str)
data_dict_n = {x: y for x, y in zip(names_str, names)}
df_dict_n = pd.DataFrame(data_dict_n, index=date)
运行效果
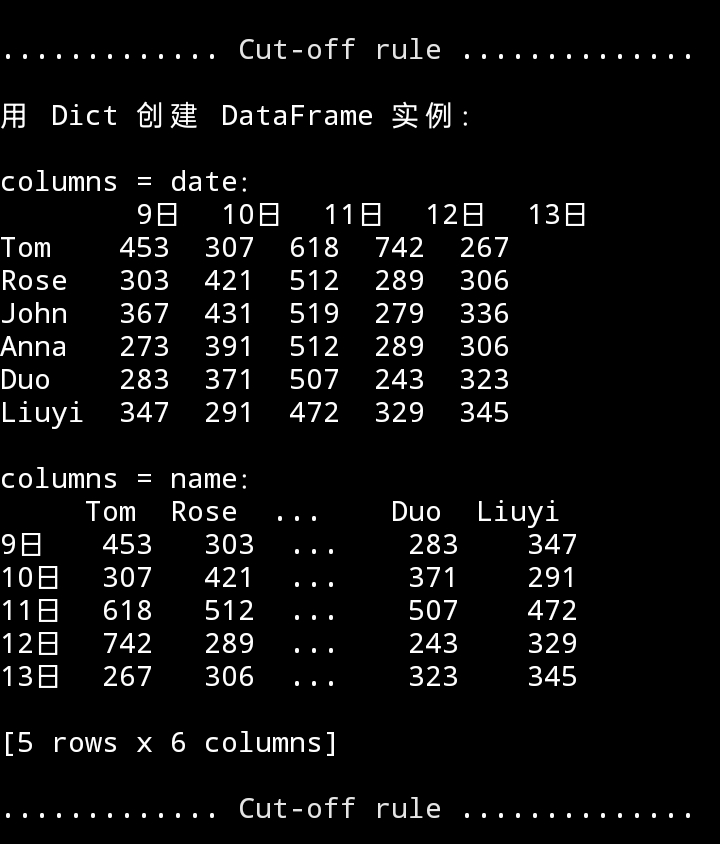
回首页
2. Series 创建
代码
data_S_name = [pd.Series(i, index=date) for i in names]
df_S_n = pd.DataFrame(data_S_name, index=names_str)
data_S_date = [pd.Series(i, index=names_str) for i in data_date]
df_S_d = pd.DataFrame(data_S_date, index=date)
运行效果
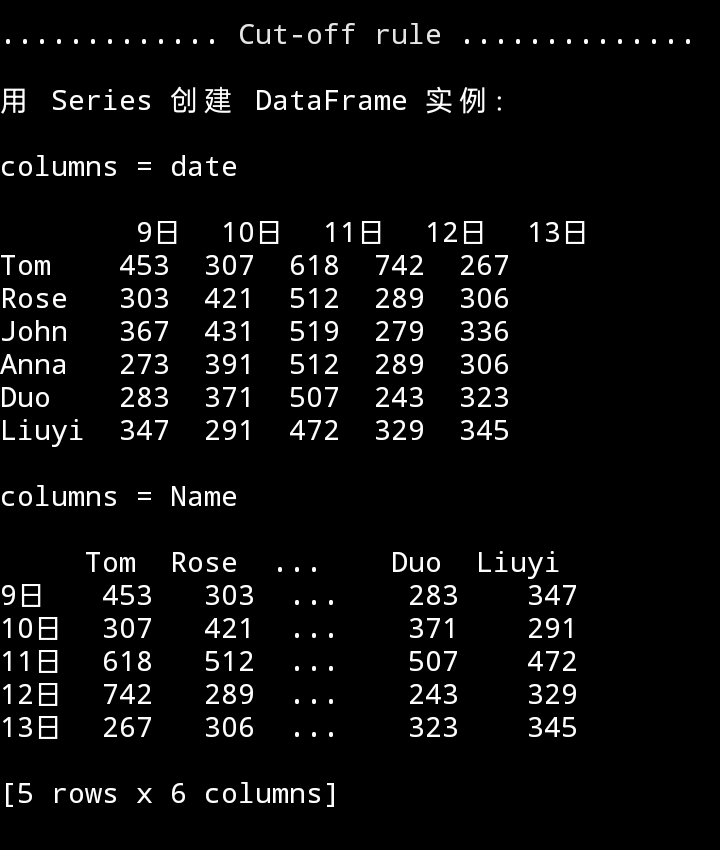
如上试验,可以看出,dict、Series 创建 DataFrame 实例,效果完全一样。用行或者列表示一个人的数据,都是可以的。
3. Series 创建
代码
定义 DataFrame 的方法,除了 dict、Series,还可以用字典套字典创建 DataFrame 。
在字典中就规定好行列名称(第一层键)和每横行索引(第二层字典键)以及对应的数据(第二层字典值),也就是在字典中规定好了每个数据格子中的数据。
嵌套字典生成代码
d = data_dict_d
dd = {}
for x, y in zip(date, d):
tem = {}
for m,n in zip(names_str, d.get(y)):
tem[m] = n
dd[x] = tem
代码
df = pd.DataFrame(dd)
print(f"\n\n{' 3、dict 套 dict 创建 Dataframe ':-^37}\
{cut_line()}嵌套字典:\n\n{dd}\
{cut_line()}创建的 Dataframe:\n\n{df}{cut_line()}")
运行效果
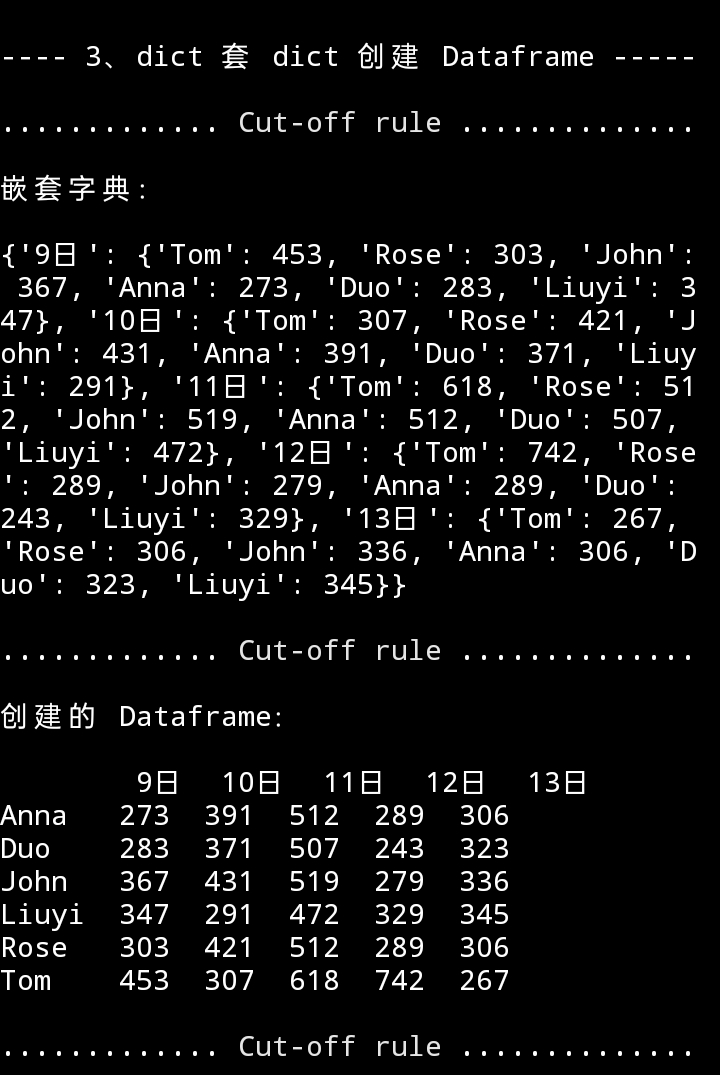
回首页
3. 索引 index
a. 创建同时设置 index
b. 重置 index
代码
print(f"{cut_line()}当前 DataFrame:\n\n{df}")
tem = df.copy()
tem.index = list('ABCDEF')
print(f"\n\n用{list('ABCDEF')}设置 index:\n\n{tem}")
tem.index = list('abcde') + ['Tom']
print(f"\n\n重置 index 不可以"自动对齐":\n\n{tem}{cut_line()}")
运行效果
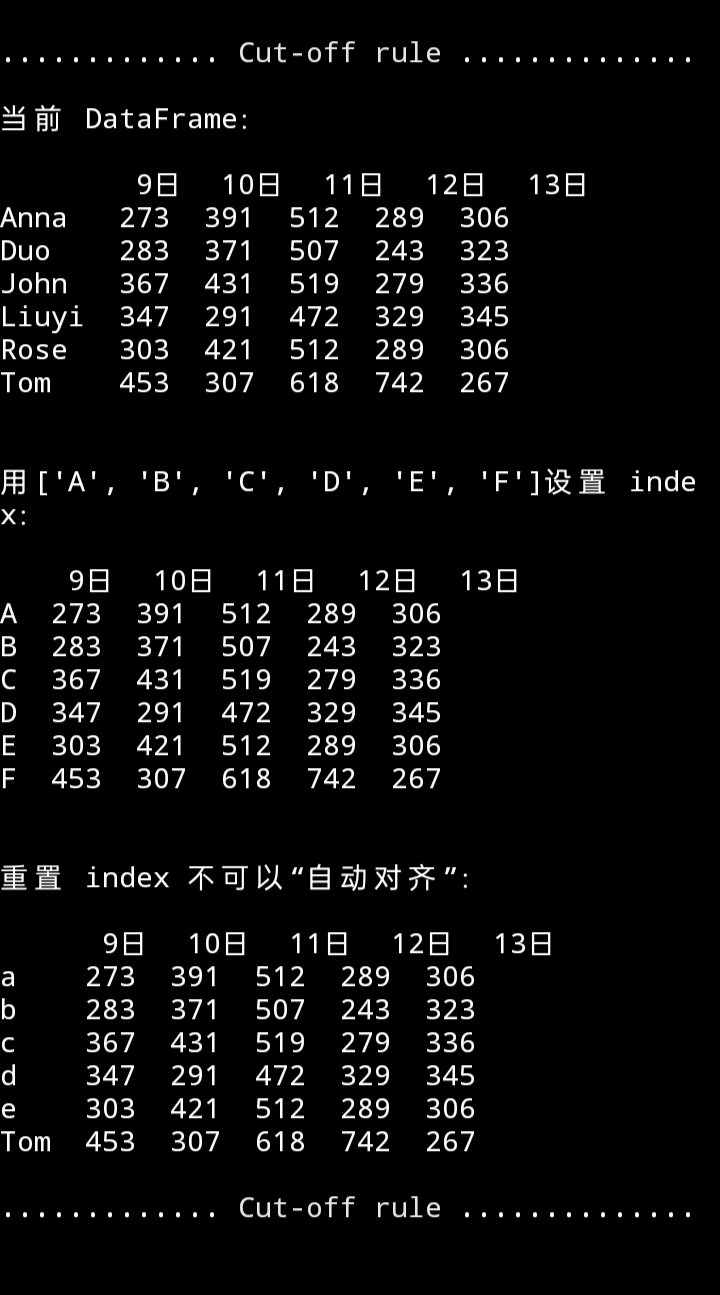
重置 index 不可以”自动对齐”,是按照 df.index = 后面的序列排序。注意:跟定义 DataFrame 一样,
index 序列的元素个数必须匹配行数,否则报错。
回首页
4. 列序 columns
列序 columns 的重置和定义时设置:日期、姓名设置,与 index 类似,这里就不再赘述( 点击蓝色超链接文字可以查看)。
回首页
list.append() 花絮
在 DataFrame 的参数中 index=list.append() ,可以得到想要的结果。
在这里,好像打破了 list.append() 没能返回值的”神话🧐🧐”。
打断点查看,list 也是成功追加新元素的,DataFrome 也是得到了新增元素的 list 赋值 index 的。
回首页
; 三、 插入行、列
14日新数据
new_data = {'Anna': 337, 'Tom': 403, 'Rose': 567, 'Liuquan': 453}
1. 同时插入行列
代码
old_names_str = names_str[:]
dd['14日']=new_data
df_new_dict = pd.DataFrame(dd, index=names_str.append('Liuquan'),
columns=list(df.columns).append('14日'))
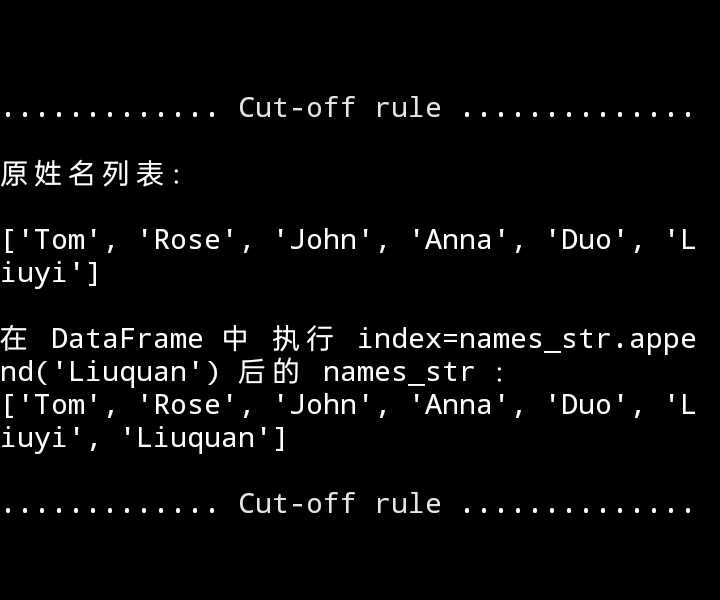
print(f"{cut_line()}原姓名列表:\n\n{old_names_str}\
\n\n在 DataFrame 中 执行 index=names_str.append('Liuquan') 后的 names_str :\n{names_str}{cut_line()}")
print(f"{cut_line()}4月14日数据:\n{new_data}\
\n\n追加后姓名列表:\n{names_str}\
\n\n{' 追加新数据的嵌套字典新建 DataFrame ':-^29}\n\n{df_new_dict}\
\n\n{' 没有数据填充的单元都是空(NaN)':-^29}{cut_line()}")
运行效果
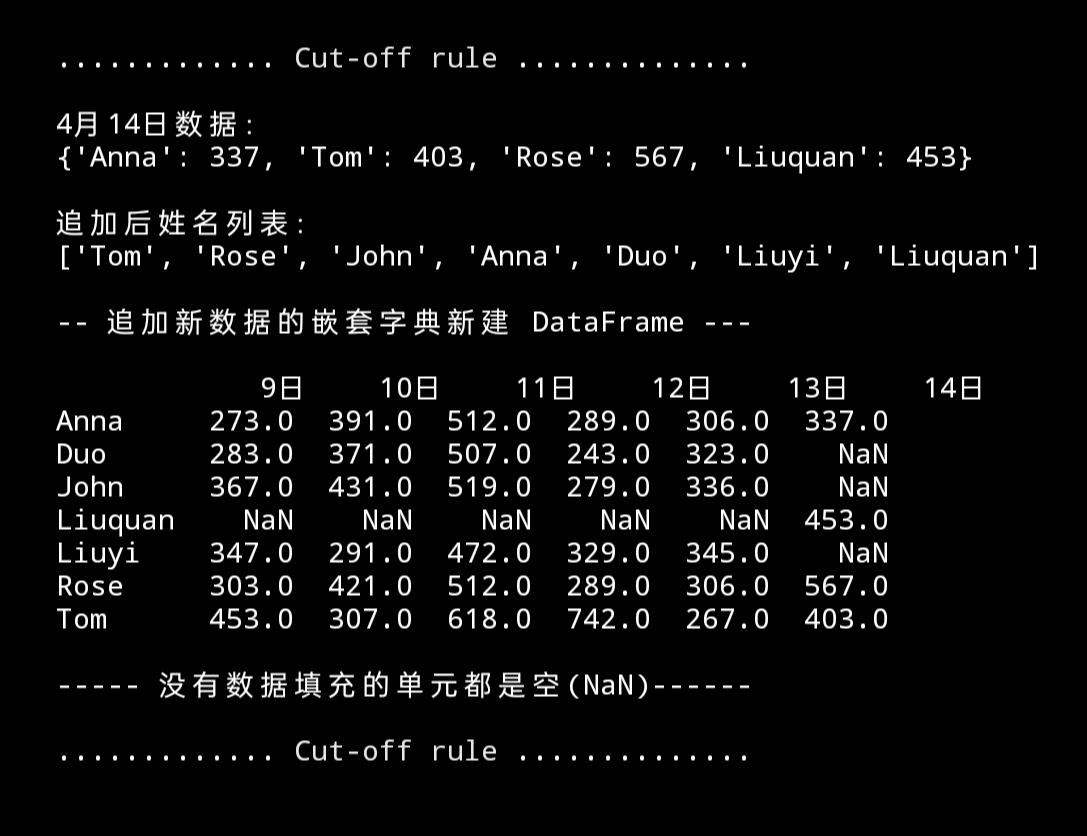
用追加新数据的嵌套字典重建 DataFrame , 新的行、列都可以得到保存。
回首页
2. 插入列
代码
new_Series = pd.Series(new_data)
df_new_S = df.copy()
df_new_S['14日'] = new_Series
print(f"{cut_line()}4月14日数据:\n{new_data}\
\n\n追加后姓名列表:\n{names_str}\
\n\n{' 数据创建 Seroies,字典式赋值追加 ':-^29}\n\n{df_new_S}\
\n\n{' 没有数据填充的单元都是空(NaN)':-^29}{cut_line()}")
运行效果

如您所见, Series 追加数据虽然方便快捷,但不可以新增行索引,不匹配 index 的数据将被舍弃。DataFrame 新建实例确是可以定义多于原数据的索引的。这,就 需要根据追加的数据选择了。当然, 我更喜欢 Series 。
回首页
3. 追加空列并整列赋值
代码
df = df_new_dict.copy()
print(f"{cut_line()}当前 DataFrame:\n\n{df}")
df['15日'] = pd.Series()
print(f"\n\n{'添加空列':-^37}\n\n{df}")
data_new1 = (389, 452, 422, 309, 433, 398, 409)
df['15日'] = data_new1
print(f"\n\n{'对空列依次赋值':-^34}\n\n数据 = {data_new1}\n\n{df}")
data_new2 = {'Anna': 347, 'Any': 564, 'Liuyi': 389, 'Tom': 422, 'Duo': 402, 'John': 338, 'Rose': 409, 'Liuquan': 309}
df['16日'] = pd.Series(data_new2)
print(f"\n\n{'用 Series 添加元素多于行数的数据':-^29}\
\n\n数据 = {data_new2}\n\n{df}")
运行效果
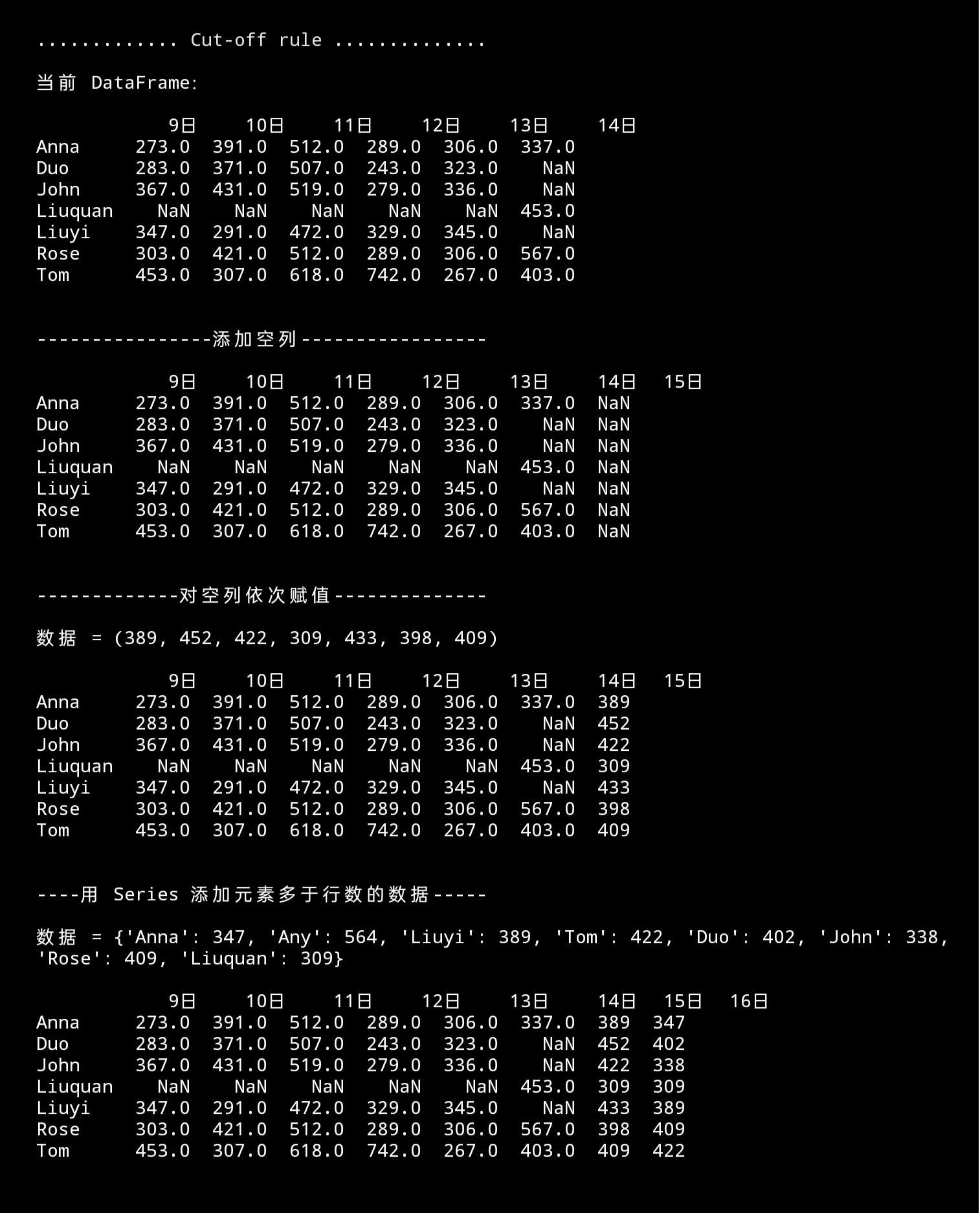
添加不等行数元素,可以用 dict、Series ,不多于 DataFrame 行数的数据,二者皆可;多于行数就只可以 Series 数据类型添加。DataFrame 会自动对齐索引,不在意数据字典顺序。索引中没有的数据,将被”丢弃”。
回首页
四、 赋值
1. 整列赋值
a. 等长依次赋值
b. 整列赋同一值
代码
df.insert(0, '班级', [f'4.{i}班' for i in range(1, 8)])
index_num = list(df.columns).index('16日') + 1
df.insert(index_num, '职务', '学生')
print(f"\n\n{' 插入列(colmuns) ':-^34}\n\n{df}")
运行效果
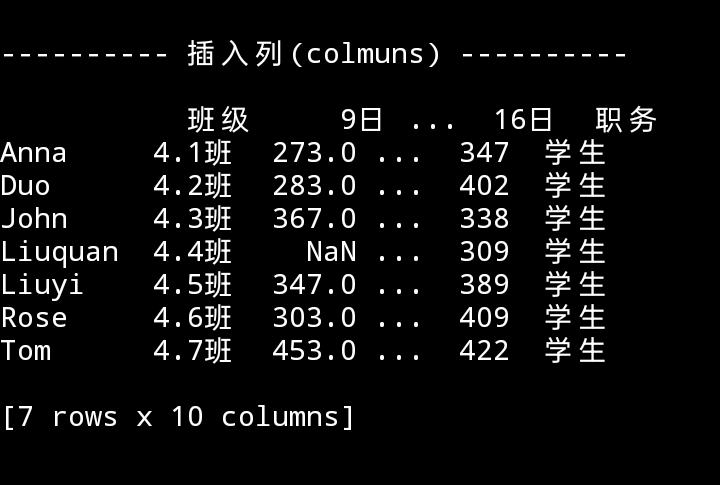
插入列,赋同一值也可赋不同值(不同值数量一定得与行数匹配)。DataFrame ,添加本来没有的列, 这操作同字典(字典可以添加本来没有的键)。
按日期倒序重置列序
代码
columns_lis = ['班级'] + [f'{i}日' for i in range(16, 8, -1)]+['职务']
print(f"\n\n{'重置列序':-^37}\n\n列序:\n{columns_lis}\
\n\n{df.loc[:, columns_lis]}{cut_line()}")
代码运行效果
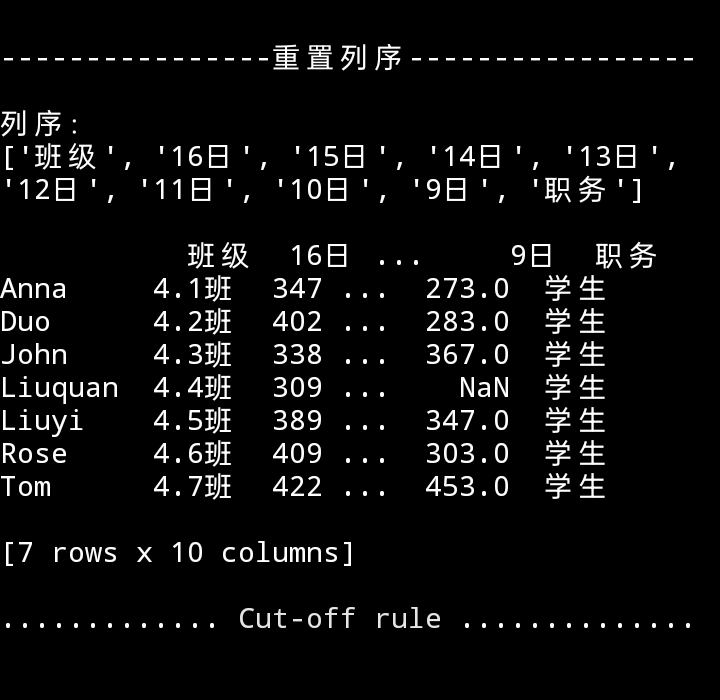
回首页
2. 单个精准赋值
a. 字典列表式赋值
代码
print(f"{cut_line()} Liuquan 4月9日、11日原有数据:\n{df['9日']['Liuquan']},{df['11日']['Liuquan']}\n\n")
df['9日']['Liuquan'] = 453
df['11日']['Liuquan'] = 386
print(f"\n\n补录(修改)后 Liuquan 4月9日、11日数据:\n{df['9日']['Liuquan']},{df['11日']['Liuquan']}{cut_line()}")
运行效果
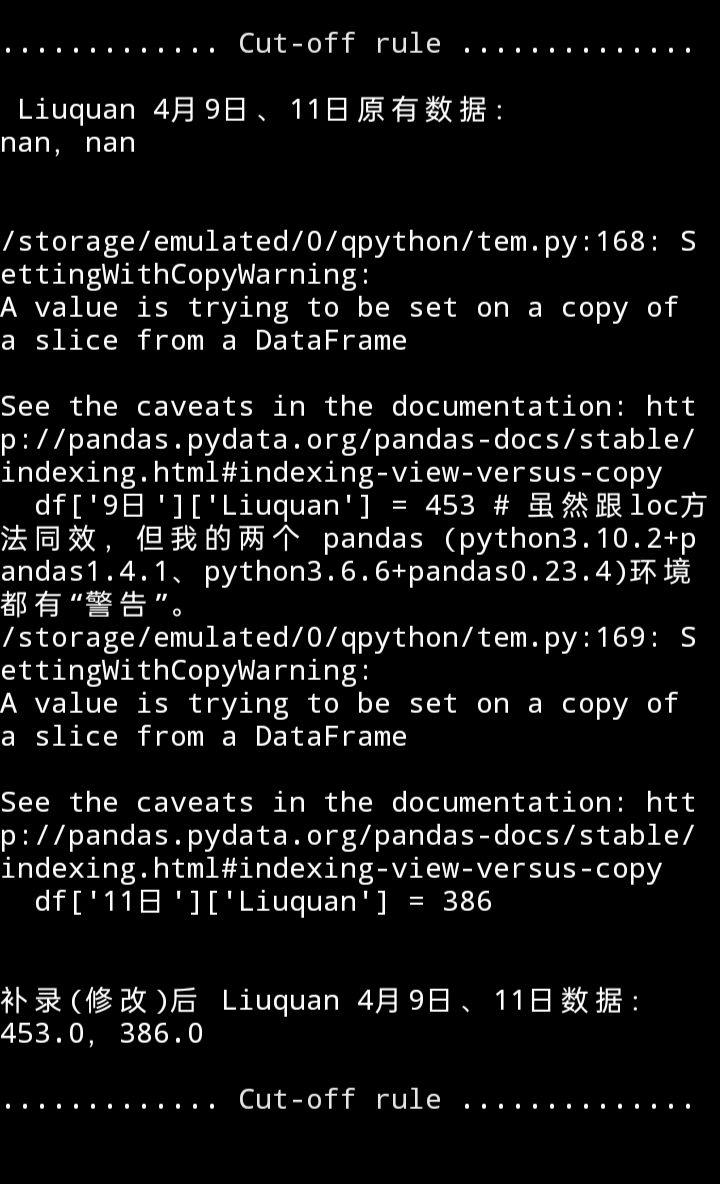
字典列表式赋值( df[rows][columns] = value )虽然跟loc方法同效,但我的两个 pandas ( python3.10.2+pandas1.4.1、python3.6.6+pandas0.23.4 )环境都有”警告”信息抛出,虽然也可以实现赋值。我不明白:是不是因为手机环境?
回首页
b. loc 方法选择赋值
代码
print(f"{cut_line()}原有数据:liuquan ,10日:{df['10日']['Liuquan']},12日:{df['12日']['Liuquan']}\n\n{'-'*41}")
df.loc['Liuquan', ['10日']] = 436
df.loc['Liuquan', ['12日']] = 398
print(f"\n\nLiuquan 4月10日、12日(436, 398)数据补录:\n\n{df}\
\n\n{df[df.index == 'Liuquan']}\
补全(修改)后数据:liuquan ,10日:{df['10日']['Liuquan']},12日:{df['12日']['Liuquan']}{cut_line()}")
运行效果
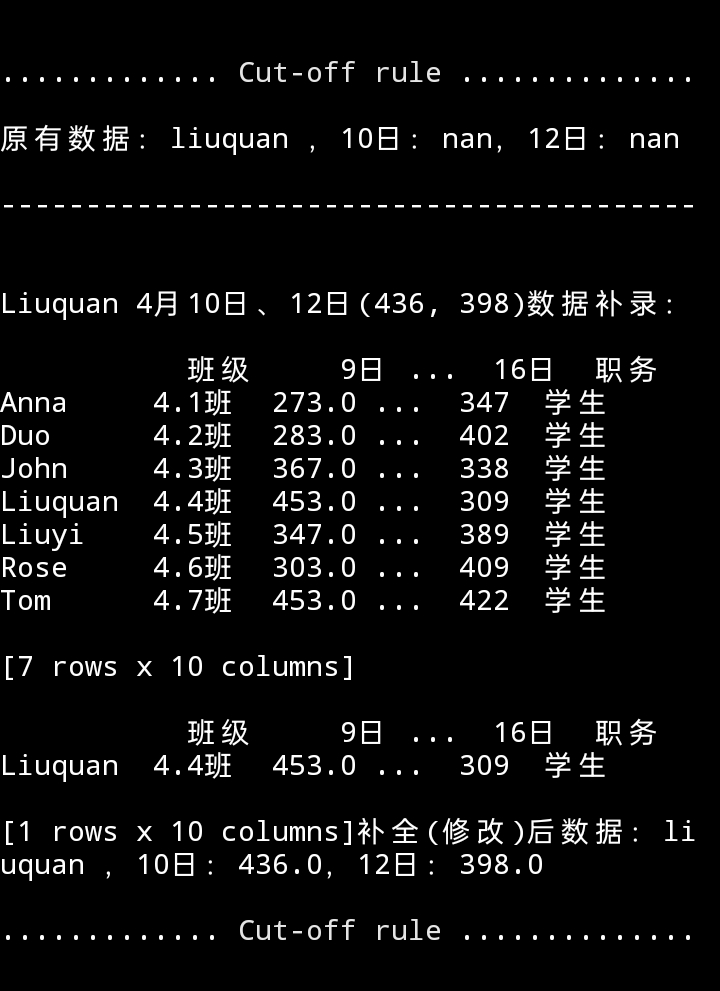
用 loc 方法修改更明了,且静默。
回首页
四、df.loc 方法条件筛选
- 空值判定
代码
df.insert(len(df.columns), 'Rank', 'OK')
df_bool = df.isna()
for date in [f"{i}日" for i in range(9,17)]:
for name in df.index:
if df_bool[date][name]:
df.loc[name,['Rank']] = 'NG'
elif not df_bool[date][name] and df['Rank'][name]=='OK':
df.loc[name,['Rank']] = 'OK'
print(f"{cut_line()}计算全勤后的列表:\n\n{df}\n\n{'-'*41}\
\n\n4月9日至16日每天坚持跳绳练习的有:\
\n{df.loc[df['Rank']=='OK']}\n{cut_line()}")
运行效果
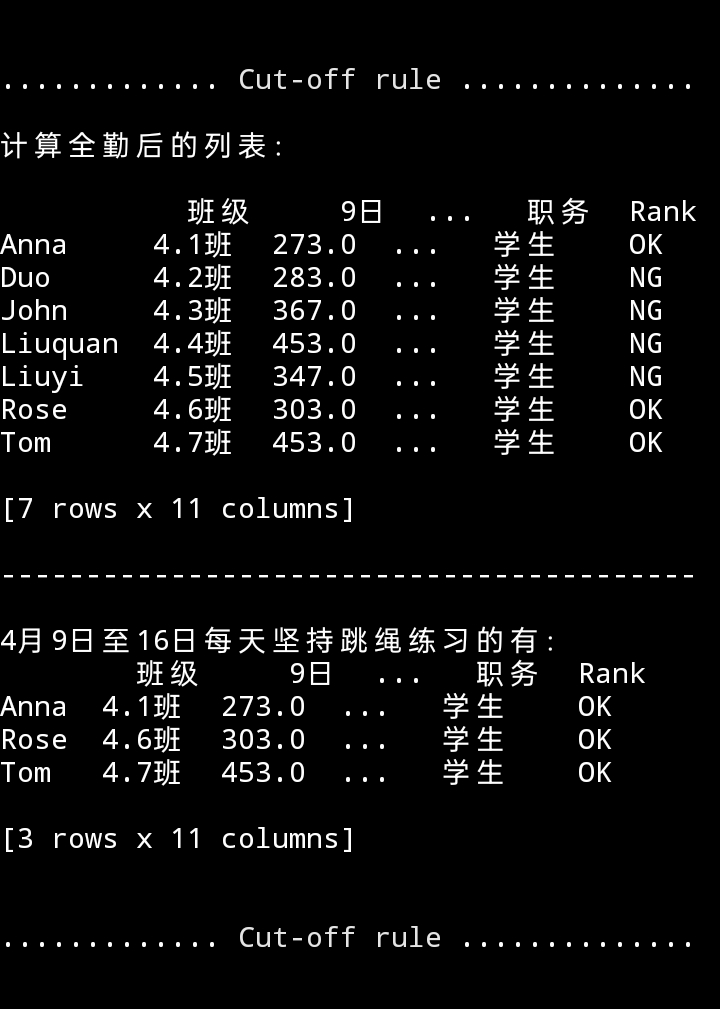
回首页
- 条件筛选
换组数据试试,换一组实验数据来看看 df.loc() 方法的条件筛选。
代码
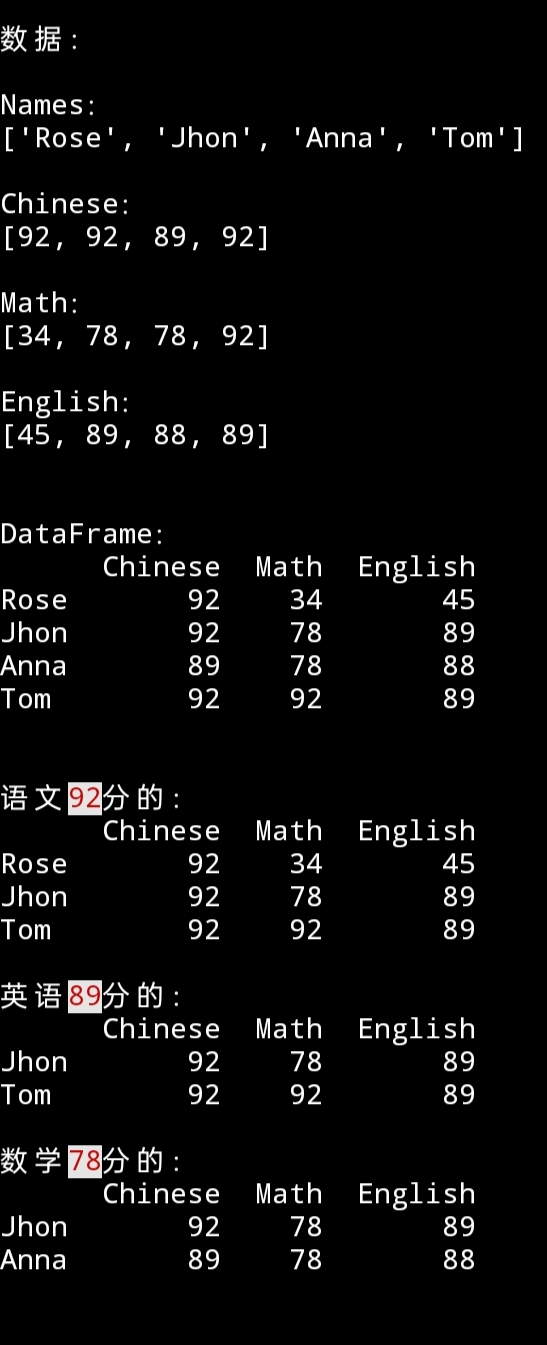
english = [45, 89, 88, 89]
chinese = [92, 92, 89, 92]
math = [34, 78, 78, 92]
names = ['Rose', 'Jhon', 'Anna', 'Tom']
df = pd.DataFrame({'Chinese': chinese,
'English': english,
'Math': math},
index=names, columns=('Chinese', 'Math', 'English'))
print('数据:')
for i in ('Names', 'Chinese', 'Math', 'English'):
print(f"\n{i}:\n{eval(i.lower())}")
print(f"\n\nDataFrame:\n{df}")
print(f"\n\n语文{color(92, 'b_gray', 'f_red')}分的:\n{df.loc[df['Chinese']==92]}\
\n\n英语{color(89, 'f_red', 'b_gray')}分的:\n{df.loc[df['English']==89]}\
\n\n数学{color(78, 'f_red', 'b_gray')}分的:\n{df.loc[df['Math']==78]}")
运行效果
回首页
完整 Python 代码
我的解题思路,已融入代码注释,博文中就不再赘述。
(如果从语句注释不能清楚作用,请评论区留言指教和探讨。🤝)
'''
filename: /sdcard/qpython/tem.py
梦幻精灵_cq的炼码场
'''
from mypythontools import color, wait, cut_line
print(f"\n\n{'正在加载 Pandad ...':^38}")
import pandas as pd
Tom = 453, 307, 618, 742, 267
Rose = 303, 421, 512, 289, 306
John = 367, 431, 519, 279, 336
Anna = 273, 391, 512, 289, 306
Duo = 283, 371, 507, 243, 323
Liuyi = 347, 291, 472, 329, 345
names = [Tom, Rose, John, Anna, Duo, Liuyi]
gb = globals()
names_str = [i for i in gb if gb[i] in names]
df = pd.DataFrame(names)
print(f"\n\n{' 1、数据直接生成 DatsFrame ':-^34}\n\n{df}")
df.index = names_str
print(f"\n\n{' 2、用姓名字符设置索引 ':-^31}\
\n{cut_line()}{names_str}{cut_line()}{df}")
date = [f'{i}日' for i in range(9, 14)]
df.columns = date
print(f"\n\n{' 3、用 date 设置 columns ':-^37}\
\n{cut_line()}{date}{cut_line()}{df}")
df01 = pd.DataFrame(names, index=names_str)
df02 = pd.DataFrame(names, columns=date)
df03 = pd.DataFrame(names, columns=date, index=names_str)
print(f"\n\n{cut_line()}{'':>4}在创建 DataFrme 时,是可以直接设置 index 和 columns的。\
{cut_line()}只设置 index:\n\n{df01}{cut_line()}\
{cut_line()}只设置 columns:\n\n{df02}{cut_line()}\
同时设置 index、columns:\n\n{df03}{cut_line()}")
data_date = []
for k in range(5):
tem = []
for i in names:
tem.append(i[k])
data_date.append(tem)
data_dict_d = {x: y for x, y in zip(date, data_date)}
df_dict_d = pd.DataFrame(data_dict_d, index=names_str)
data_dict_n = {x: y for x, y in zip(names_str, names)}
df_dict_n = pd.DataFrame(data_dict_n, index=date)
data_S_date = [pd.Series(i, index=names_str) for i in data_date]
df_S_d = pd.DataFrame(data_S_date, index=date)
data_S_name = [pd.Series(i, index=date) for i in names]
df_S_n = pd.DataFrame(data_S_name, index=names_str)
print(f"\n\n{' 二、用 dict、Series 创建 DataFrame 实例。':-^33}\
\n\n{cut_line()}用 Dict 创建 DataFrame 实例:\
\n\ncolumns = date:\n{df_dict_d}\
\n\ncolumns = name:\n{df_dict_n}\
\
{cut_line()}用 Series 创建 DataFrame 实例:\
\n\ncolumns = date\n\n{df_S_n}\
\n\ncolumns = Name\n\n{df_S_d}")
d = data_dict_d
dd = {}
for x, y in zip(date, d):
tem = {}
for m,n in zip(names_str, d.get(y)):
tem[m] = n
dd[x] = tem
df = pd.DataFrame(dd)
print(f"\n\n{' 3、dict 套 dict 创建 Dataframe ':-^37}\
{cut_line()}嵌套字典:\n\n{dd}\
{cut_line()}创建的 Dataframe:\n\n{df}{cut_line()}")
print(f"{cut_line()}当前 DataFrame:\n\n{df}")
tem = df.copy()
tem.index = list('ABCDEF')
print(f"\n\n用{list('ABCDEF')}设置 index:\n\n{tem}")
tem.index = list('abcde') + ['Tom']
print(f"\n\n重置 index 不可以"自动对齐":\n\n{tem}{cut_line()}")
new_data = {'Anna': 337, 'Tom': 403, 'Rose': 567, 'Liuquan': 453}
old_names_str = names_str[:]
dd['14日']=new_data
df_new_dict = pd.DataFrame(dd, index=names_str.append('Liuquan'),
columns=list(df.columns).append('14日'))
print(f"{cut_line()}原姓名列表:\n\n{old_names_str}\
\n\n在 DataFrame 中 执行 index=names_str.append('Liuquan') 后的 names_str :\n{names_str}{cut_line()}")
print(f"{cut_line()}4月14日数据:\n{new_data}\
\n\n追加后姓名列表:\n{names_str}\
\n\n{' 追加新数据的嵌套字典新建 DataFrame ':-^29}\n\n{df_new_dict}\
\n\n{' 没有数据填充的单元都是空(NaN)':-^29}{cut_line()}")
new_Series = pd.Series(new_data)
df_new_S = df.copy()
df_new_S['14日'] = new_Series
print(f"{cut_line()}4月14日数据:\n{new_data}\
\n\n追加后姓名列表:\n{names_str}\
\n\n{' 数据创建 Seroies,字典式赋值追加 ':-^29}\n\n{df_new_S}\
\n\n{' 没有数据填充的单元都是空(NaN)':-^29}{cut_line()}")
df = df_new_dict.copy()
print(f"{cut_line()}当前 DataFrame:\n\n{df}")
df['15日'] = pd.Series()
print(f"\n\n{'添加空列':-^37}\n\n{df}")
data_new1 = (389, 452, 422, 309, 433, 398, 409)
df['15日'] = data_new1
print(f"\n\n{'对空列依次赋值':-^34}\n\n数据 = {data_new1}\n\n{df}")
data_new2 = {'Anna': 347, 'Any': 564, 'Liuyi': 389, 'Tom': 422, 'Duo': 402, 'John': 338, 'Rose': 409, 'Liuquan': 309}
df['16日'] = pd.Series(data_new2)
print(f"\n\n{'用 Series 添加元素多于行数的数据':-^29}\
\n\n数据 = {data_new2}\n\n{df}")
df.insert(0, '班级', [f'4.{i}班' for i in range(1, 8)])
index_num = list(df.columns).index('16日') + 1
df.insert(index_num, '职务', '学生')
print(f"\n\n{' 插入列(colmuns) ':-^34}\n\n{df}")
columns_lis = ['班级'] + [f'{i}日' for i in range(16, 8, -1)]+['职务']
print(f"\n\n{'重置列序':-^37}\n\n列序:\n{columns_lis}\
\n\n{df.loc[:, columns_lis]}{cut_line()}")
print(f"{cut_line()} Liuquan 4月9日、11日原有数据:\n{df['9日']['Liuquan']},{df['11日']['Liuquan']}\n\n")
df['9日']['Liuquan'] = 453
df['11日']['Liuquan'] = 386
print(f"\n\n补录(修改)后 Liuquan 4月9日、11日数据:\n{df['9日']['Liuquan']},{df['11日']['Liuquan']}{cut_line()}")
print(f"{cut_line()}原有数据:liuquan ,10日:{df['10日']['Liuquan']},12日:{df['12日']['Liuquan']}\n\n{'-'*41}")
df.loc['Liuquan', ['10日']] = 436
df.loc['Liuquan', ['12日']] = 398
print(f"\n\nLiuquan 4月10日、12日(436, 398)数据补录:\n\n{df}\
\n\n{df[df.index == 'Liuquan']}\
补全(修改)后数据:liuquan ,10日:{df['10日']['Liuquan']},12日:{df['12日']['Liuquan']}{cut_line()}")
df.insert(len(df.columns), 'Rank', 'OK')
df_bool = df.isna()
for date in [f"{i}日" for i in range(9,17)]:
for name in df.index:
if df_bool[date][name]:
df.loc[name,['Rank']] = 'NG'
elif not df_bool[date][name] and df['Rank'][name]=='OK':
df.loc[name,['Rank']] = 'OK'
print(f"{cut_line()}计算全勤后的列表:\n\n{df}\n\n{'-'*41}\
\n\n4月9日至16日每天坚持跳绳练习的有:\
\n{df.loc[df['Rank']=='OK']}\n{cut_line()}")
english = [45, 89, 88, 89]
chinese = [92, 92, 89, 92]
math = [34, 78, 78, 92]
names = ['Rose', 'Jhon', 'Anna', 'Tom']
df = pd.DataFrame({'Chinese': chinese,
'English': english,
'Math': math},
index=names, columns=('Chinese', 'Math', 'English'))
print('数据:')
for i in ('Names', 'Chinese', 'Math', 'English'):
print(f"\n{i}:\n{eval(i.lower())}")
print(f"\n\nDataFrame:\n{df}")
print(f"\n\n语文{color(92, 'b_gray', 'f_red')}分的:\n{df.loc[df['Chinese']==92]}\
\n\n英语{color(89, 'f_red', 'b_gray')}分的:\n{df.loc[df['English']==89]}\
\n\n数学{color(78, 'f_red', 'b_gray')}分的:\n{df.loc[df['Math']==78]}")
我的 相关博文 :
- pandas 数据类型之 Series(675阅读)
- pandas 数据类型之 DataFrame(610阅读)
参考文章 :
上一篇: 练习:身高出现的频次
下一篇: 聊天消息敏感词屏蔽系统(字符串替换 str.replace(str1, *) )
我的 HOT 博:
- New:Python字符串居中显示(1050阅读)
- New:练习:求偶数和、阈值分割和求差( list 对象的两个基础小题)(1314阅读)
- 用 pandas 解一道小题(1916阅读)
- 可迭代对象和四个函数(1042阅读)
- “快乐数”判断(1206阅读)
- 罗马数字转换器(构造元素取模)(1894阅读)
- 罗马数字(转换器|罗生成器)(2565阅读)
- Hot:让QQ群昵称色变的代码(17712阅读)
- Hot:斐波那契数列(递归| for )(3368阅读)
- 柱状图中最大矩形(1625阅读)
- 排序数组元素的重复起止(1215阅读)
- 电话拨号键盘字母组合(1284阅读)
- 密码强度检测器(1746阅读)
- 求列表平衡点(1787阅读)
- Hot:字符串统计(3611阅读)
- Hot:尼姆游戏(聪明版首发)(3348阅读) 尼姆游戏(优化版)(903阅读)
推荐条件 点阅破千

; 精品文章:
- 好文力荐: 《python 完全自学教程》齐伟书稿_免费_连载
- OPP三大特性:封装中的property
- 通过内置对象理解python’
- 正则表达式
- python中”*”的作用
- Python 完全自学手册
- 海象运算符
- Python中的
!=与is not不同 - 学习编程的正确方法
好文力荐:
CSDN实用技巧博文:
Original: https://blog.csdn.net/m0_57158496/article/details/124525814
Author: 梦幻精灵_cq
Title: pandas 数据类型之 DataFrame
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/738803/
转载文章受原作者版权保护。转载请注明原作者出处!