

系列文章目录
第1天:读入数据
第2天:read()、readline()与readlines()
第3天:进度条(tqdm模块)
第4天:命令行传参(argparse模块)
第5天:读、写json文件(load()、loads()、dump()、dumps())
第6天:os模块、glob模块
第7天:pandas.DataFrame
第8天:DataFrame的三种数据处理基本操作(df.drop(), df.fillna(), df.drop_duplicates())
第9天:DataFrame的属性编码、数据合并和连接(get_dummies,merge,join,concat)
第10天:DataFrame的排序、排名和索引重置(sort,rank,index)
python数据分析学习第11天记录
- 系列文章目录
- 前言
- 一、今天所学的内容
- 二、知识点详解
* - 2.1 pandas模块写入Excel的to_excel()操作
- 2.2 to_excel()常见参数解析
– - 2.3 to_json()
- 2.4 to_csv()
- 总结
前言
上一篇写了DataFrame的属性编码、数据合并和连接,是不是还是挺复杂的呢。今天继续学习pandas模块下对数据处理的另外两种操作:
- 追加写入Excel
- 转化格式(比如dict)进行保存
一、今天所学的内容
今天仍旧是陶醉在pandas的魅力中无法自拔的模样。前面介绍了那么多种处理方法了,今天先收一下尾,教大家如何将自己目前处理好的DataFrame,比如如何写入Excel,或者转化成其他格式(比如json格式、dict格式等等),然后保存在文件里。
二、知识点详解
2.1 pandas模块写入Excel的to_excel()操作
将DataFrame写入Excel的方式最直接的是使用pandas提供的函数:to_excel()。
该函数的主要形式是:
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='',
float_format=None, columns=None, header=True, index=True, index_label=None,
startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None,
inf_rep='inf', verbose=True, freeze_panes=None, storage_options=None)[source]
看着参数好多!如何使用该函数呢?
我们先开箱即用,举一个简单的例子吧:
import pandas as pd
data = {
'性别':['male','male','female','male'],
'姓名':['汤师爷','县长','县长夫人','黄老爷'],
'年龄':[40,35,25,44]}
df = pd.DataFrame(data,index=['one','two','three','four'],
columns=['姓名','性别','年龄','职业'])
print(df)
先直观地看一下生成的DataFrame的样子:


欢迎汤师爷、县长、县长夫人和黄老爷回归撒花🎉~
要保存在excel中,最简单的是要定义一下保存的excel的路径也就是要配置一下”excel_writer”这个参数。
下面就是重点了:
df.to_excel('excel_output.xls')
我美滋滋地等着出结果,然而报了错,真是人算不如天算呐!报的错提示我少了一个python包:xlwt。
于是pip install xlwt一行操作后,可以运行了,生成了一个excel文件。
然而,我打开却显示:

emm,我都保存成Excel文件了,为啥不用Microsoft Excel打开呢?
于是,以正确的方式打开之后是这样式的~:

汤师爷你吃着火锅唱着歌被我打印在excel文件里啦~
2.2 to_excel()常见参数解析
到这里,小伙伴们跟着我一起简单地使用了to_excel()操作,尤其是用Microsoft Excel打开的那一瞬间,看到汤师爷他们的名字被清楚地打印在屏幕上的时候,我还有点小激动呢。编程带来的快乐妙不可言~一行代码就可以做手动做需要复制很久的事情。
那么这个函数是不是就这么简单地使用了呢?其实不然,根据pandas官方文档来看,to_excel()有很多参数。所以第二小节咱们对其进行进阶学习,了解一下常见参数。
2.2.1 sheet_name :excel表名命名
2.2.2 na_rep : 缺失值填充 ,可以设置为字符串
如果na_rep设置为bool值,则写入excel时改为0和1;也可以写入字符串或数字。
我们先看看na_rep设置为True值的结果:

再看看na_rep设置为false的结果:

; columns :选择输出的的列存入
columns参数: 选择输出的列。直接在to_excel()函数的参数位置加上要输出的列名即可。
df.to_excel('excel_output.xls', columns=["姓名","年龄"])

2.3 to_json()
将pandas模块中的DataFrame转化为json格式的数据并保存在文件中。
代码示例:
df_json = df.to_json(orient="split")
print(df_json)
结果如下:

可以看出来,结果虽然是json格式,但是很不美观,而且也不是以字符串的格式来展示的。
所以对代码进行了改进:
parsed = json.loads(df_json)
string = json.dumps(parsed, indent=4)
print(string)
此时,代码运行的结果如下:
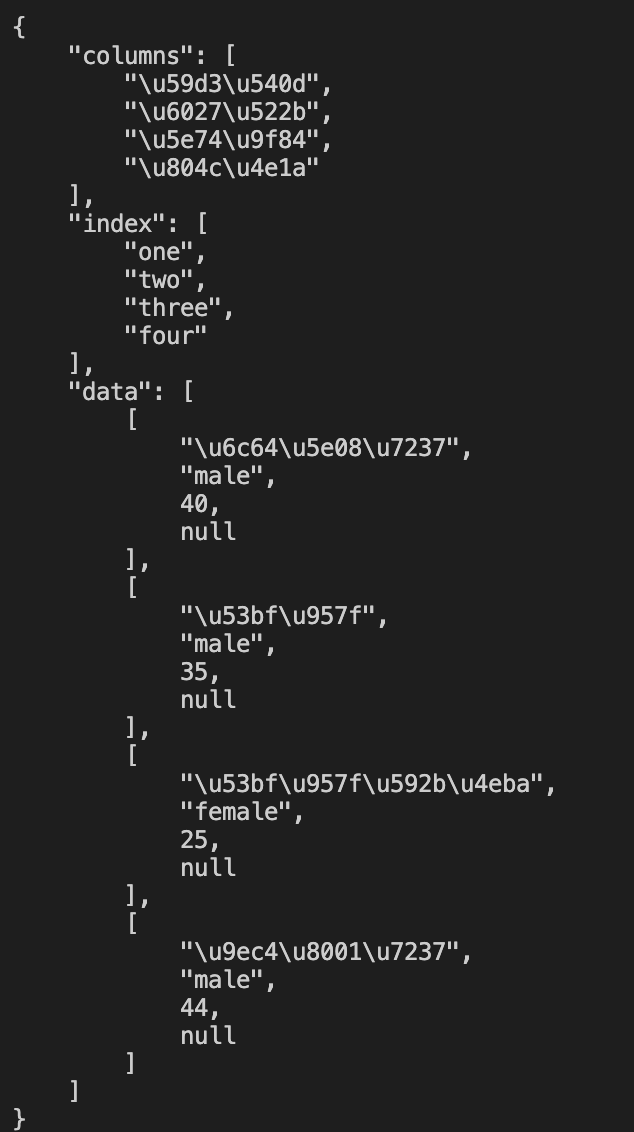
完美~
2.4 to_csv()
最后一部分啦!这一部分将dataframe的数据转化为csv文件中保存。
最简单的方式就是直接调用to_csv()函数,并且什么参数都不加:
df.to_csv('Result.csv')
结果会生成一个新的Result.csv文件(注意不要用excel软件打开):

当然,to_csv()函数本身也是有很多参数的,比如:
[1] 分隔符
dt.to_csv('Result.csv',sep='?')
[2] 替换空值
dt.to_csv('C:/Users/think/Desktop/Result1.csv',na_rep='NA')
[3] 还可以定义保存数据的格式
dt.to_csv('C:/Users/think/Desktop/Result1.csv',float_format='%.2f')
[4] 可以添加参数columns,定义是否保留某列数据
dt.to_csv('C:/Users/think/Desktop/Result.csv',columns=['name'])
[5] 可以定义是否保留列名
dt.to_csv('C:/Users/think/Desktop/Result.csv',header=0)
[6] 是否保留行索引
dt.to_csv('C:/Users/think/Desktop/Result1.csv',index=0)
[7] ……………………
总结
这篇文章可谓是干货满满哦!
查看了一下pandas的官方文档,关于DataFrame格式的转化以及保存,还有很多可以调用的函数。
我截了图分享给大家,你可以大致浏览一遍,心里有个数,如果后续用到的话直接查官方文档就好了。


博客更新停摆了一周。这一周有家人的陪伴,大半时间都在陪他们,内心感觉满足且充盈。今天他们回家了,独自在北京的我,觉得经过这些天的充电,可以更好地和大家一起学习和工作了。自己之后将以更加认真的态度学习python,并更新博客。
也祝大家变得更强,明天见!
今天的小tips:
- 越是重要的决定,越需要运用本质思考。”短视、从众、惯性”的直线式思考往往帮助我们躲避本质思考,并使我们给自己”我已经开始思考了”的心理假象、给自己”我已经付出很多了”的自我感动、给自己”我就是快速行动派”的自我安慰,并最终用自我感动替代高质量的决策。我们不断重复这样的思考方式,但希望获得不一样的结果。
- 所以我们要常常思考自己是如何思考的。因为真正的改变一定是发生在思考的质变中。
给自己一套系统化、坚实的、面向本质的思考方法,彻底带来自己用智方式的改变是非常重要的。共勉。
Original: https://blog.csdn.net/FANFANHEBAOER/article/details/117740724
Author: 王大梨
Title: Python数据分析【第11天】| DataFrame转化格式并保存(to_excel(),to_json(),to_csv())
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/738462/
转载文章受原作者版权保护。转载请注明原作者出处!