

文章目录
- 一、mysql基础
* - 1,MySQL安装及配置
– - 2,数据库管理及相关命令
- 3,数据表管理及相关命令
- 4,数据内容的增删改查
- 5,使用python连接mysql
- 6,mysql创建用户和授权
- 7,mysql数据库权限表
- 二、表关系及条件查询
* - 1,常用sql查询语句
– - 2,表关系
- 三、mysql高级
* - 1,函数
- 2,索引(重点)
- 3,存储过程
- 4,视图
- 5,触发器
- 6,事务(重要)
- 7,锁
– - 8,数据库连接池
- 四、sql工具包(python版本)
*
–
一、mysql基础
1,MySQL安装及配置
windows环境安装
第一步:下载mysql
官方地址:https://downloads.mysql.com/archives/community/


选择对应的系统进行下载(推荐5.7.31)新版本有一些新功能但是有些地方还不是很稳定
第二步:解压
windows系统是免安装的,直接将mysql解压到任意文件夹即可(为了后期方便使用推荐解压路径C:\Program Files\mysql-5.7.31-winx64)
第三步:
在MySQL的安装目录下创建 my.ini 的文件,作为MySQL的配置文件。
[mysqld]
#端口号
port = 3306
#安装路径
basedir = C:\\Program Files\\mysql-5.7.31-winx64
#数据库存放路径
datadir = C:\\Program Files\\mysql-5.7.31-winx64\\data
注意:如果C盘下只能创建文件夹不能创建文件(权限问题)最简单的办法就是在桌面创建好在移入即可
第四步:初始化
切记使用管理员省份打开cmd,不然会报错Can’t create directory ‘C:\Program Files\mysql-5.7.31-win64\data’
“C:\Program Files\mysql-5.7.31-winx64\bin\mysqld.exe” –initialize-insecure
- 自动创建data目录,以后我们的数据都会存放在这个目录。
- 同时创建建必备一些的数据,例如默认账户 root (无密码)。
第五步:启动mysql
“C:\Program Files\mysql-5.7.31-winx64\bin\mysqld.exe” –install mysql
net start mysql 启动服务
net stop mysql 关闭服务
也可以在任务管理器中直接用鼠标关闭
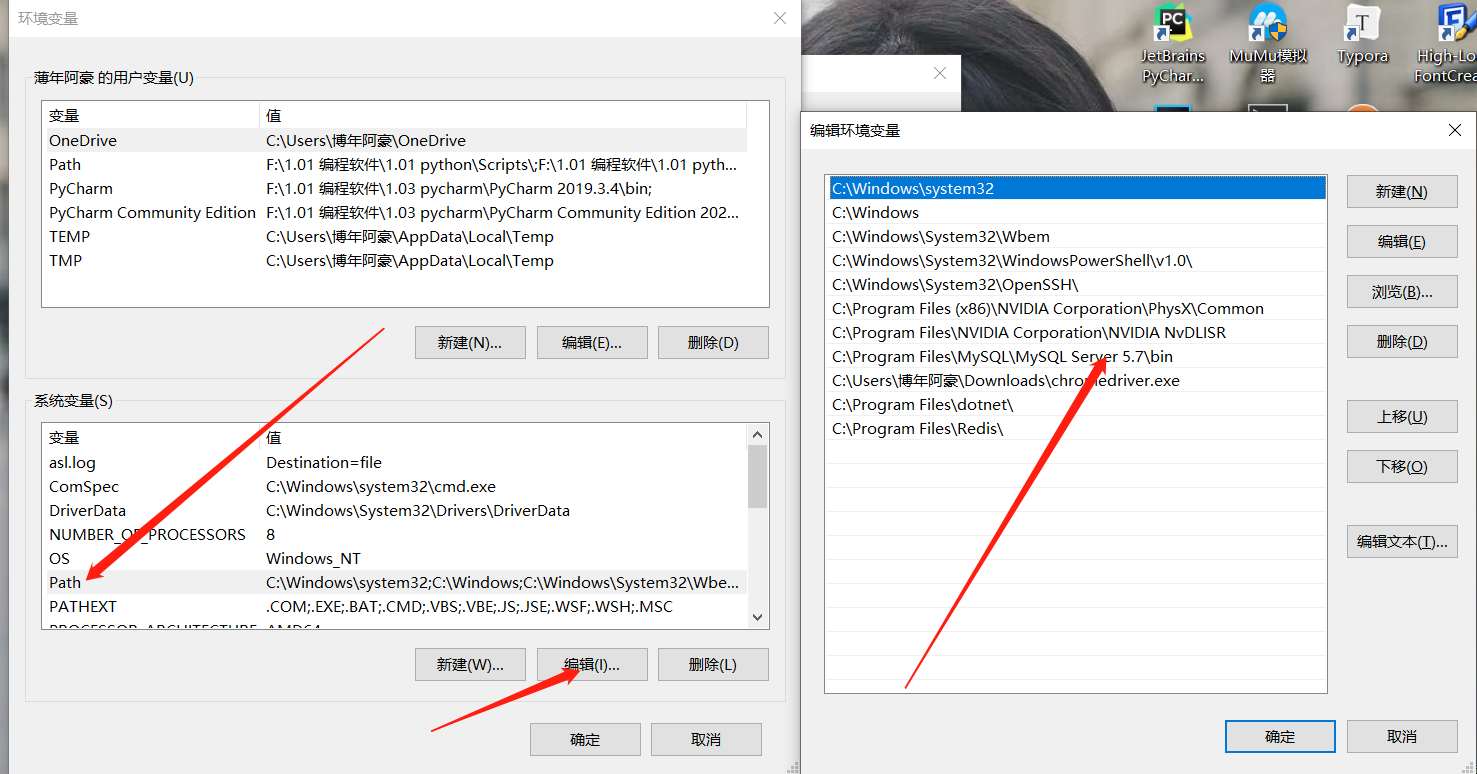
第六步:添加环境变量
打开高级系统设置,找到环境变量,添加mysql下的bin路径到path中
第七步:测试连接
在cmd输入
mysql -u root -p
回车
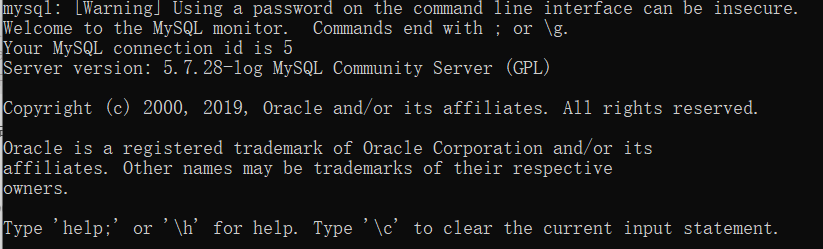
返回如图即安装成功
第八步:设置密码
打开cmd命令输入
mysqladmin -uroot -p
出现 Enter password (旧密码)直接回车,然后输入两次新密码即可

注意:如果忘记密码修改方式
在mysql配置文件加入代码
[mysqld]
…
skip-grant-tables=1
…
重启mysql(任务管理器找到mysql),然后打开cmd重新设置密码就好了
最后不要忘记把 skip-grant-tables=1删除
2,数据库管理及相关命令
- 查看当前所有的数据库:
show databases;
- 创建数据库: charset 设置编码 collate 排序规则
create database 数据库名 default charset utf8 collate utf8_general_ci;
- 删除数据库:
drop database 数据库名;
- 进入数据库:
use 数据库名字;
- 查看数据库所有表:
show tables;
3,数据表管理及相关命令
- 创建数据表
格式
create table 表名(
列名 类型,
列名 类型,
列名 类型
)default charset=utf8;create table tb5(
id int not null auto_increment primary key, –不允许为空 & 主键 & 自增
name varchar(16) not null, –不允许为空
email varchar(32) null, –允许为空(默认)
age int default 3 –插入数据时,默认值:3
)default charset=utf8;
注意:一个表只能由一个自增长列,且一般为主键
- 删除表
删除表(这个表直接被删除)
drop table 表名;
清空表(清空所有数据,表还在)
delete from 表名;
清空表(速度快、无法回滚撤销等)
truncate table 表名;
- 修改表
1, 添加列
alter table 表名 add 列名 类型;
alter table 表名 add 列名 类型 DEFAULT 默认值;
alter table 表名 add 列名 类型 not null default 默认值;
alter table 表名 add 列名 类型 not null primary key auto_increment;
2,删除列
alter table 表名 drop column 列名;
3,修改列类型
alter table 表名 modify column 列名 类型;
4,修改列类型和名称
alter table 表名 change 原列名 新列名 新类型;
4,修改列 默认值
alter table 表名 alter 列名 set default 100;
4,删除列 默认值
alter table 表名 alter 列名 drop default 100;
4,添加主键
alter table 表名 add primary key(列名);
4,删除主键
alter table 表名 drop primary key;
- 数据类型
数字类型
int[(m)][unsigned][zerofill]
int 表示有符号,取值范围:-2147483648 ~ 2147483647
int unsigned 表示无符号,取值范围:0 ~ 4294967295
int(5)zerofill 仅用于显示,如果位数不够会在数字前加0补全 比如00004
tinyint[(m)] [unsigned] [zerofill]
tinyint 有符号,取值范围:-128 ~ 127.
tinyint unsigned 无符号,取值范围:0 ~ 255
bigint[(m)][unsigned][zerofill]
bigint 有符号,取值范围:-9223372036854775808 ~ 9223372036854775807
bigint unsigned 无符号,取值范围:0 ~ 18446744073709551615
decimal[(m,d)] [unsigned] [zerofill]
m为数字总个数(负号不算),d为小数点后的数字个数
m最大65,d最大30
例如:
create table L2(
id int not null primary key auto_increment,
number decimal(5,2)
)default charset=utf8;
如果位数多出小数点后会四舍五入
字符串类型
char(m)
定长字符串,m代表字符串的长度,最多可容纳255个字符。
varchar(m)
变长字符串,m代表字符串的长度,最多可容纳65535个字节。
text
text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。
mediumtext
text数据类型用于保存变长的大字符串,可以组多到65535 (2**24 − 1)个字符。
longtext
text数据类型用于保存变长的大字符串,可以组多到65535 (2**32 − 1)个字符。
时间类型
datetime
时间格式 YYYY-MM-DD HH:MM:SS 时间范围(1000-01-01 00:00:00/9999-12-31 23:59:59)
timestamp
时间格式 YYYY-MM-DD HH:MM:SS 时间范围(1970-01-01 00:00:00/2037年)
该时间会将插入时间转换成utc(国标时间)存储,查询时又转换成本地时间
date
时间格式 YYYY-MM-DD 时间范围(1000-01-01/9999-12-31)
time
时间格式 HH:MM:SS 时间范围('-838:59:59'/'838:59:59')
更多类型请移步官方文档:https://dev.mysql.com/doc/refman/5.7/en/data-types.html
4,数据内容的增删改查
- 增加数据
insert into 表名 (列名,列名,列名) values(对应列的值,对应列的值,对应列的值);
value(1,2,3),value(4,5,6)代表一次插入多条数据
- 删除数据
delete from 表名 where 条件;
- 修改数据
update 表名 set 列名=值 where 条件; 不加条件修改整列
- 查找数据
select * from 表名;
select 列名,列名,列名 from 表名;
select 列名,列名 as 别名,列名 from 表名;
select * from 表名 where 条件;
5,使用python连接mysql
import pymysql
连接MySQL,db 默认使用数据库 ; -- 进入数据库
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='mysql', charset="utf8", db='mysql')
cursor = conn.cursor()
cursor.execute("mysql命令")
conn.commit() #commit表示提交 查询操作不需要提交
如果要获取返回结果(查询操作不需要commit()提交)
cursor.execute("mysql命令")
data = cursor.fetchone() # cursor.fetchall()
print(data)
#关闭连接
cursor.close()
conn.close()
注意:在python中最好避免使用字符串格式化 ,不然容易被sql注入攻击
例如:
sql = “select * from mysql where name='zhangsan' and age=14
cursor.execute(sql)
正确用法
name = zhangsan
age = 18
cursor.execute(”select * from mysql where name={} and age={}“.format(name,age))
6,mysql创建用户和授权
1,用户信息表user (记录所有mysql用户的账号权限等信息)
2,创建用户
create user ‘用户名’@’IP地址’ identified by ‘密码’;
3,删除用户
drop user ‘用户名’@’用户的IP地址’;
4,修改用户
rename user ‘用户名’@’IP地址’ to ‘新用户名’@’IP地址’;
5,修改密码
set password for ‘用户名’@’IP地址’ = Password(‘新密码’)
6,用户授权
grant 权限 on 数据库.表 to ‘用户’@’IP地址’ ;
grant 权限 on 数据库.存储过程名 to ‘用户’@’IP地址’ ;
grant all privileges on *.* TO 'zhangsan'@'localhost'; -- 张三拥有所有数据库的所有权限
grant all privileges on sdu.* TO 'zhangsan'@'localhost'; -- 张三拥有数据库sdu的所有权限
grant all privileges on sdu.info TO 'zhangsan'@'localhost'; -- 张三拥有数据库sdu中info表的所有权限
grant select on sdu.info TO 'zhangsan'@'localhost'; -- 张三拥有数据库sdu中info表的查询权限
grant select,insert on sdu.* TO 'zhangsan'@'localhost'; -- 张三拥有数据库sdu所有表的查询和插入权限
grant all privileges on sdu.* to 'zhangsan'@'%'; --张三可以在任何IP地址登录数据库且拥有所有权限
flush privileges; -- 权限生效
7,查看权限
show grants for ‘用户’@’IP地址’
8,取消权限
revoke 权限 on 数据库.表 from ‘用户’@’IP地址’
7,mysql数据库权限表
all privileges 除grant外的所有权限
select 仅查权限
select,insert 查和插入权限
...
usage 无访问权限
alter 使用alter table
alter routine 使用alter procedure和drop procedure
create 使用create table
create routine 使用create procedure
create temporary tables 使用create temporary tables
create user 使用create user、drop user、rename user和revoke all privileges
create view 使用create view
delete 使用delete
drop 使用drop table
execute 使用call和存储过程
file 使用select into outfile 和 load data infile
grant option 使用grant 和 revoke
index 使用index
insert 使用insert
lock tables 使用lock table
process 使用show full processlist
select 使用select
show databases 使用show databases
show view 使用show view
update 使用update
reload 使用flush
shutdown 使用mysqladmin shutdown(关闭MySQL)
super 使用change master、kill、logs、purge、master和set global。还允许mysqladmin􏵗􏵘􏲊􏲋调试登陆
replication client 服务器位置的访问
replication slave 由复制从属使用
二、表关系及条件查询
1,常用sql查询语句
第一张表名 class 第二张表名 sdu
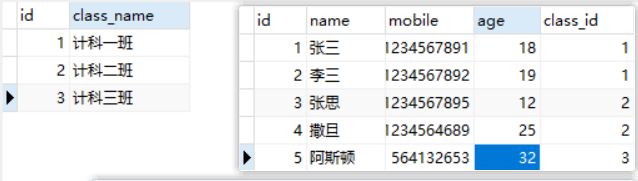
; where查询
select 列名,列名 from 表名 where 条件
eg:
select * from class where id > =1 ;
select name,age from sdu where id>1 and age>20 ;
select name from sdu where id between 2 and 4 ;
select * from sdu where id in(2,3,4)
select * from sdu where sdu.id not in(2,3,4)
select * from sdu where id not in(select id from class) ;
select * from sdu where (name = ‘张三’ or age = 32) and mobile = 1234567891 ;
like通配符模糊查询
(%代表任何,_代表一个字符)
select * from sdu where name like “%斯%” ;
select * from sdu where name like “_三” ;
映射查询
- 第一张表名 class 第二张表名 sdu
select id, name as NM, 123 from info;
eg:
select
id,
name,
666 as num,
( select max(id) from class ) as mid, – max/min/sum
( select min(id) from class) as nid, – max/min/sum
age
from sdu;

select
id,
name,
case class_id when 1 then “优秀班级成员” else “普通班级成员” end classinfo
from sdu;

select
id,
name,
case when age
; 排序查询
*
– 第一张表名 class 第二张表名 sdu
select * from sdu order by age desc; – 倒序
select * from sdu order by age asc; – 顺序
select * from sdu order by age asc,id desc; – 优先按照age从小到大;如果age相同则按照id从大到小。
eg:
select * from sdu where mobile like “%9_” order by age asc,id desc;
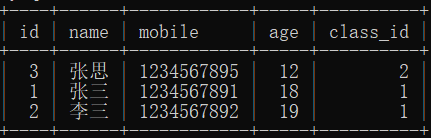
取部分数据
select * from sdu limit 3 offset 2; – 从位置2开始,向后获取前3数据
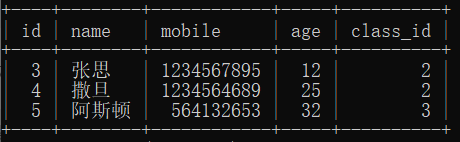
; 数据分组
select age,max(id),count(id),sum(id),avg(id) from sdu group by age;
解释:12岁的最大id为3,有一个12岁的人,这些人id和为3,id平均数为3
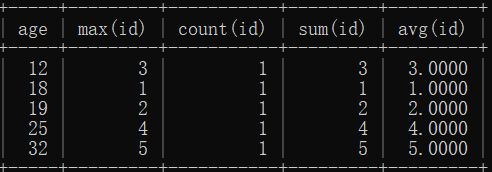
select class_id,count(id) from sdu group by class_id having count(id) > 1;
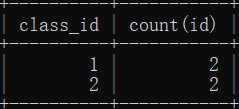
左右连表

主表 left outer join 从表 on 主表.列明 = 从表.id
eg:
select * from sdu left outer join class on sdu.class_id = class.id;
- 右连表(一般掌握左连即可,需要时变换主从位置即可)
从表 right outer join 主表 on 主表.列明 = 从表.id
eg:
select * from sdu right outer join class on sdu.class_id = class.id;
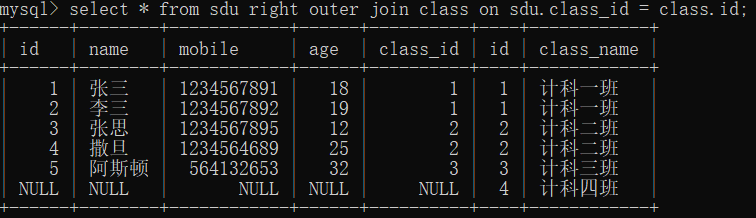
注意:·查看数据以主表为主从表为辅,主表不会显示从表没有关联的数据。从表会显示没有关联的数据关联的位置为null(不重要,推荐掌握一个左连就够用)
; 联合
select id from class
union
select id from sdu;
– 列数需相同 自动去重select id from class
union all
select id from sdu;
– 列数需相同 保留所有
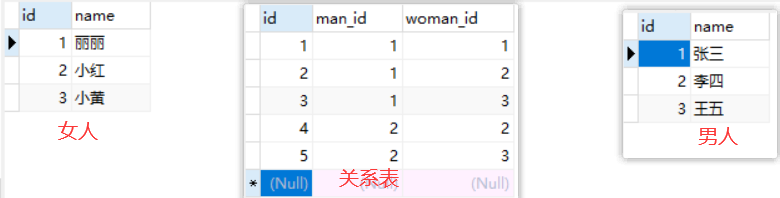
2,表关系
- 一对一
单独一张表,没有什么好说的
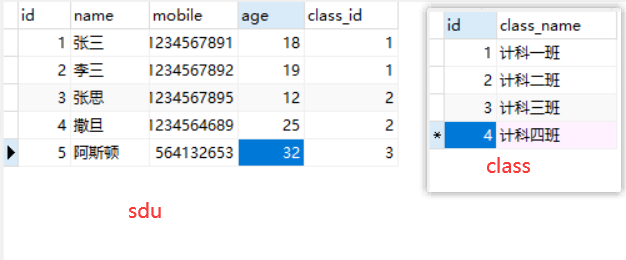
- 一对多 or 多对一
- 多对多
; 三、mysql高级
1,函数
count() 计数函数
max() 求最大值
min() 最小值
avg() 平均值
reverse() 字符颠倒
concat() 字符串拼接
concat_ws() 字符串拼接(不忽略空字符,会忽略Null)
Now() 现在时间
DATE_FORMAT( NOW(),'%Y-%m-%d %H:%i:%s')
sleep() 睡眠
lower(str) 全部小写
upper(str) 全部大写
conv(N,from_base,to_base) 进制转换
left(str,len) 从第len开始开始一直到结束的子字符串
ltrim(str) 返回字符串 str ,其引导空格字符被删除。
rtrim(str) 返回字符串 str ,结尾空格字符被删去。
.....
官方文档:
2,索引(重点)
索引的作用: 快速查找 约束
缺点:插入、删除、更新速度比较慢,因为每次操作都需要调整整个B+Tree的数据结构关系
- 索引原理
底层是基于B+Tree的数据结构存储

数据库的索引是基于上述B+Tree的数据结构实现,但在创建数据库表时,如果指定不同的引擎,底层使用的B+Tree结构的原理有些不同。
myisam引擎,非聚簇索引(数据 和 索引结构 分开存储)
innodb引擎,聚簇索引(数据 和 主键索引结构存储在一起)
区别:myisam在树的最下部存放的是数据地址而innodb存放的是数据。而且innodb还支持事务,行级锁外键等特点
create table 表名(
id int not null auto_increment primary key,
name varchar(32) not null,
age int
)engine=myisam/innodb default charset=utf8;
常见索引
- 主键索引:加速查找、不能为空、不能重复。 + 联合主键索引
create table 表名(
id int not null auto_increment,
name varchar(32) not null,
primary key(id,列2) -- 如果有多列,称为联合主键(不常用且myisam引擎支持),且自增列必须是主键索引否则报错
);
- 唯一索引:加速查找、不能重复。 + 联合唯一索引
create table 表名(
id int not null auto_increment,
name varchar(32) not null,
unique (列1,列2) -- 如果有多列,称为联合唯一索引。
);
- 普通索引:加速查找。 + 联合索引
create table 表名(
id int not null auto_increment,
name varchar(32) not null,
index ix_email (name,email) -- 如果有多列,称为联合索引。
);
注意:在使用索引时一定要命中索引,如果没有命中索引就默认会顺序查找耗费时间
未命中情况
- 类型不一致
select * from big where name = 123; – 未命中
特殊的主键:
select * from big where id = “123”; – 命中
- 使用不等于
select * from big where name != “张三”; – 未命中
特殊的主键:
select * from big where id != 123; – 命中
- or (存在未建立索引列)
select * from big where 列1=”xx” or 列二=”xx”; – 如果列一和列二有一个没有索引则未命中
联合索引(列一,列二)查询列一,或者同时查询列一和列二才会加速,单独查询列二不会加速。
(列一,列二)括号第一个相当于有自己的索引,第二个相当于依赖第一的加速效果
在or或者and中只要有一列没有自己的索引就会默认顺序查询
- 排序,当根据索引排序时候,选择的映射如果不是索引,则不走索引。
select * from big order by name asc; – 未命中
select * from big order by name desc; – 未命中
特别的主键:
select * from big order by id desc; – 命中
- like 模糊查询
select * from big where name like “12-%-10”; – 当通配符在中间或者前边时未命中
特别的:
select * from big where name like “wu-1111-%”; – 当通配符在末尾时命中
- 使用函数
select * from big where reverse(name) = “张三”; – 未命中
特别的:
select * from big where name = reverse(“张三”); – 命中
执行计划
explain + SQL语句;
其中比较重要的是 type,他他SQL性能比较重要的标志,性能从低到高依次:
all < index < range < index_merge < ref_or_null < ref < eq_ref < system/const
这里通过判断type类型来看sql语句的查找速度
3,存储过程
存储过程,是一个存储在MySQL中的SQL语句集合,当主动去调用存储过程时,其中内部的SQL语句会按照逻辑执行。(用的较少,详细可上官方文档查看)
- 创建存储过程
delimiter $$
create procedure 存储过程名()
BEGIN
select * from sdu;
sql语句
END $$
delimiter ;
执行
call 存储过程名();
删除存储过程
drop procedure 存储过程名;
- 参数类型
存储过程的参数可以有如下三种:
in,仅用于传入参数用
out,仅用于返回值用
inout,既可以传入又可以当作返回值
delimiter $$
create procedure p2(
in i1 int,
in i2 int,
inout i3 int,
out r1 int
)
BEGIN
DECLARE temp1 int;
DECLARE temp2 int default 0;
set temp1 = 1;
set r1 = i1 + i2 + temp1 + temp2;
set i3 = i3 + 100;
end $$
delimiter ;
set @t1 =4;
set @t2 = 0;
CALL p2 (1, 2 ,@t1, @t2);
SELECT @t1,@t2;
4,视图
等于给一个指定的集合命名(Name),在该集合查询只需要Name.列名 条件即可
select * from
(select id,name from sdu where id > 2) as A
where
A.name > ‘xxx’;
创建视图
create view 视图名 as select id,name from sdu 条件;
as后边可以是任何表
使用视图
select * from 视图名;
删除视图
drop view 视图名;
修改视图
alter view 视图名 as 任何表
5,触发器
对某个表进行【增/删/改】操作的前后如果希望触发某个特定的行为时,可以使用触发器。
插入前
create trigger 触发器名 before insert on 表名 for each row
BEGIN
sql语句;
sql语句;
END
插入前后 befor/after insert
删除前后 befor/after delete
更新前后 befor/after update
删除触发器
drop trigger 触发器名;
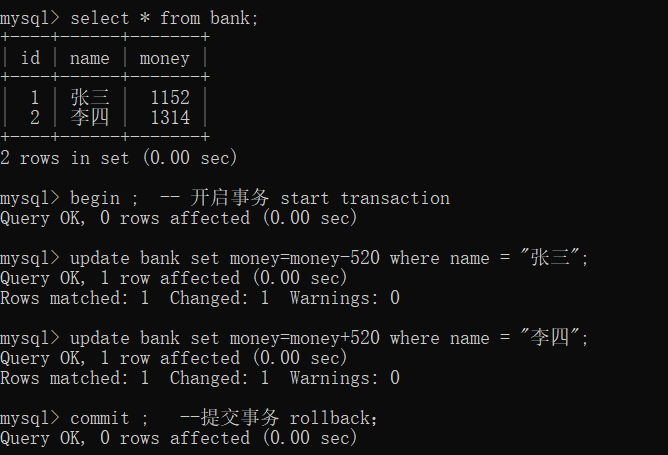
6,事务(重要)
例如:张三 给 李四 转账 520,那就会涉及2个步骤。
- 张三账户 减520
- 李四账户 加 520
这两个步骤必须同时完成才算完成,并且如果第一个完成、第二步失败,还是回滚到初始状态。
重点:事务的四大特性(ACID)
- 原子性(Atomicity)
原子性是指事务包含的所有操作不可分割,要么全部成功,要么全部失败回滚。
- 一致性(Consistency)
执行的前后数据的完整性保持一致。
- 隔离性(Isolation)
一个事务执行的过程中,不应该受到其他事务的干扰。
- 持久性(Durability)
事务一旦结束,数据就持久到数据库
提交后
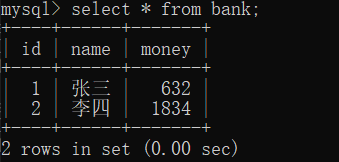
- python代码
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='mysql', charset="utf8", db='bank')
cursor = conn.cursor()
开启事务
conn.begin()
try:
cursor.execute("update bank set money=money-520 where name='张三'")
cursor.execute("update bank set money=money+520 where name='李四'")
except Exception as e:
# 回滚
print("回滚")
conn.rollback()
else:
# 提交
print("提交")
conn.commit()
cursor.close()
conn.close()
7,锁
在用MySQL时,同时有很多做更新、插入、删除动作,MySQL为了保证数据不出错,提供了锁的功能。
- 表级锁,即A操作表时,其他人对整个表都不能操作,等待A操作完之后,才能继续。
- 行级锁,即A操作表时,其他人对指定的行数据不能操作,其他行可以操作,等待A操作完之后,才能继续。
【注意:MYISAM支持表锁,不支持行锁;InnoDB引擎支持行锁和表锁。】
在innodb引擎中,update、insert、delete的行为内部都会先申请锁(排它锁),申请到之后才执行相关操作,最后再释放锁。所以,当多个人同时像数据库执行:insert、update、delete等操作时,内部加锁后会排队逐一执行。而select * from 默认不会【加锁 for update(排它锁)lock in share mode(共享锁)】
排它锁(重要)
排它锁( for update),加锁之后,其他事务不可以读写。
应用场景:商品库存剩下最后一件防止多人同时购买使库存变成负数 。
begin; -- start transaction;
select count from goods where id=3 for update;
-- 获取个数进行判断
if count>0:
update goods set count=count-1 where id=3;
else:
-- 已售罄
commit;
共享锁
共享锁( lock in share mode),可以读,但不允许写。
加锁之后,后续其他事物可以可以进行读,但不允许写(update、delete、insert),因为写的默认也会加锁。
应用场景:当用户一插入与其他数据相关联的数据防止别人插入数据破坏原有结构导致报错
begin; -- start transaction;
select count from goods where id=3 lock in share mode;
sq语句;
commit;
8,数据库连接池
在多个客户端需要连接数据库时为了避免客户端与数据库连接过多导致数据库高负荷时数据库池就可以很好的限制客户端与数据库的连接数
pip install pymysql #连接数据库模块
pip install dbutils #数据池模块,需要依赖于pymysql
import threading
import pymysql
from dbutils.pooled_db import PooledDB
MYSQL_DB_POOL = PooledDB(
creator=pymysql, # 使用链接数据库的模块
maxconnections=5, # 连接池允许的最大连接数,0和None表示不限制连接数
mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached=3, # 链接池中最多闲置的链接,0和None不限制
blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错
setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping=0,
# ping MySQL服务端,检查是否服务可用。
# 如:0 = None = never, 1 = default = whenever it is requested,
# 2 = when a cursor is created, 4 = when a query is executed, 7 = always
host='127.0.0.1',
port=3306,
user='root',
password='root123',
database='userdb',
charset='utf8'
)
def task():
# 去连接池获取一个连接
conn = MYSQL_DB_POOL.connection()
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute('select sleep(2)')
result = cursor.fetchall()
print(result)
cursor.close()
# 将连接交换给连接池
conn.close()
def run():
for i in range(10):
t = threading.Thread(target=task)
t.start()
if __name__ == '__main__':
run()
四、sql工具包(python版本)
1,单例方法
import pymysql
from dbutils.pooled_db import PooledDB
class SQLdb(object):
def __init__(self):
# TODO 此处配置,可以去配置文件中读取。
self.pool = PooledDB(
creator=pymysql, # 使用链接数据库的模块
maxconnections=5, # 连接池允许的最大连接数,0和None表示不限制连接数
mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached=3, # 链接池中最多闲置的链接,0和None不限制
blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错
setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping=0,
host='127.0.0.1',
port=3306,
user='root',
password='root123',
database='userdb',
charset='utf8'
)
def get_conn_cursor(self):
conn = self.pool.connection()
cursor = conn.cursor(pymysql.cursors.DictCursor)
return conn, cursor
def close_conn_cursor(self, *args):
for item in args:
item.close()
def exec(self, sql, **kwargs):
conn, cursor = self.get_conn_cursor()
cursor.execute(sql, kwargs)
conn.commit()
self.close_conn_cursor(conn, cursor)
def fetch_one(self, sql, **kwargs):
conn, cursor = self.get_conn_cursor()
cursor.execute(sql, kwargs)
result = cursor.fetchone()
self.close_conn_cursor(conn, cursor)
return result
def fetch_all(self, sql, **kwargs):
conn, cursor = self.get_conn_cursor()
cursor.execute(sql, kwargs)
result = cursor.fetchall()
self.close_conn_cursor(conn, cursor)
return result
db = SQLdb()
from import db
db.exec("insert into bank(name) values(%(name)s)", name="张三")
data = db.fetch_one("select * from bank")
print(data)
data = db.fetch_all("select * from bank")
print(data)
2,with 上下文管理
import threading
import pymysql
from dbutils.pooled_db import PooledDB
POOL = PooledDB(
creator=pymysql, # 使用链接数据库的模块
maxconnections=5, # 连接池允许的最大连接数,0和None表示不限制连接数
mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached=3, # 链接池中最多闲置的链接,0和None不限制
blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错
setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping=0,
host='127.0.0.1',
port=3306,
user='root',
password='root123',
database='userdb',
charset='utf8'
)
class SQLdb(object):
def __init__(self):
self.conn = conn = POOL.connection()
self.cursor = conn.cursor(pymysql.cursors.DictCursor)
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.cursor.close()
self.conn.close()
def exec(self, sql, **kwargs):
self.cursor.execute(sql, kwargs)
self.conn.commit()
def fetch_one(self, sql, **kwargs):
self.cursor.execute(sql, kwargs)
result = self.cursor.fetchone()
return result
def fetch_all(self, sql, **kwargs):
self.cursor.execute(sql, kwargs)
result = self.cursor.fetchall()
return result
from import SQLdb
with SQLdb() as q:
data = q.fetch_one("select * from bank")
print(data)
data = q.fetch_all("select * from bank where id >= %(id)s", id=1)
print(data)
链接:https://pan.baidu.com/s/1P1eVtUsalvp6v2vEVoiqjg
提取码:ahzb
–来自百度网盘超级会员V4的分享
Original: https://blog.csdn.net/weixin_53950583/article/details/124183420
Author: 薄年阿豪
Title: 【mysql】mysql全面总结
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/737354/
转载文章受原作者版权保护。转载请注明原作者出处!