

Python & Django 问题记录
文章目录
- Python & Django 问题记录
* - Python MySQL gone away 问题排查
- Python 多线程和多进程
– - Django 如何不使用命令行创建 superuser
- Django OOMKilled 问题
- Max retries exceeded with URL xxx
- Django 405 Method Not Allowed
Python MySQL gone away 问题排查
背景:
Django 项目中涉及同步数据的操作,使用的是线程池和事件循环相结合的方式,服务经常在运行一天后出现 MySQL server has gone away
解决办法:
-
check max_allowed_packet
-
通常数据库设置 max_allowed_packet 为 16M(最大可设为 1G),标识 the maximum size of a MySQL network protocol packet that the server can create or read
show variables like 'max_allowed_packet';
通常当服务器收到的数据包过大超过 max_allowed_packet 时会关闭连接出现 MySQL server has gone away 的错误
一般若遇到这种情况也可以 double check 日志中是否抛出如下错误:
(1153, “Got a packet bigger than ‘max_allowed_packet’ bytes”)
解决方法如下:
- MySQL max_allowed_packet 设置为更高,比如 128M
set global max_allowed_packet=128*1024*1024
-
如果使用 Django bulk_create 请设置 batch_size,将大量的数据分多个 query 入库
-
check wait_timeout
使用第一种思路优化后未能解决问题,则需要考虑是否超过了 wait_timeout:
wait_timeout 默认值为 28800 seconds (8 hours),标识 The number of seconds the server waits for activity on a noninteractive connection before closing it.
而我们这里的主要问题是 ThreadPoolExecutor 创建的线程池中的每个线程创建之后会不断被复用同时每个线程创建的数据库连接是一个 threading.local 实例,一个线程中如果之前有数据库连接就会复用此时如果连接过期了就会 gone away,如果没有就会创建新的数据库连接由于最后不主动释放如果不限制线程数最终会数据库连接超限。
解决方法如下:
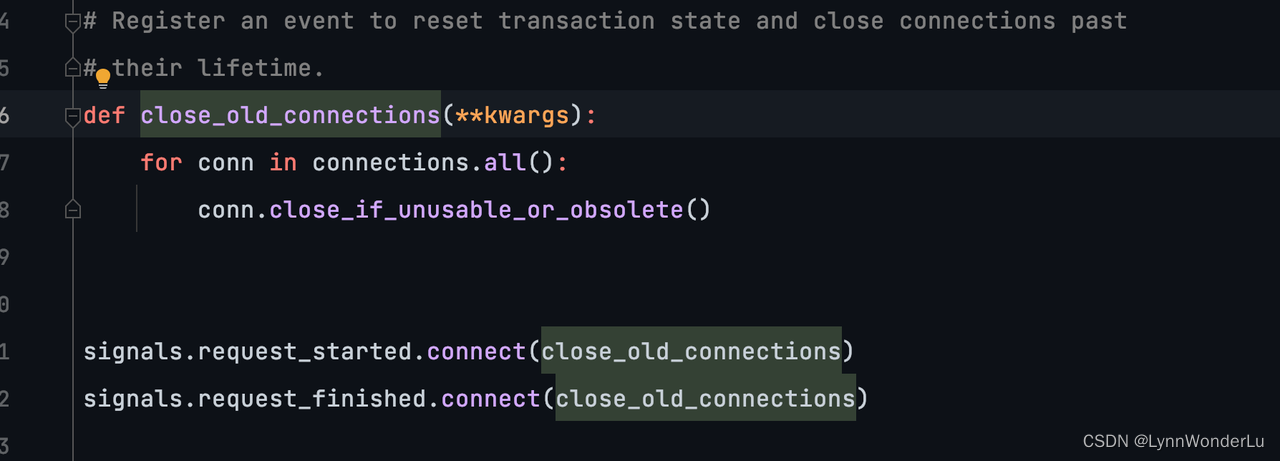
- 设置 CONN_MAX_AGE,注意这个参数仅涉及 http 请求开始和结束,因此对于我们异步任务的处理不会起到作用,仅在这里做标注。(请看如下源码)

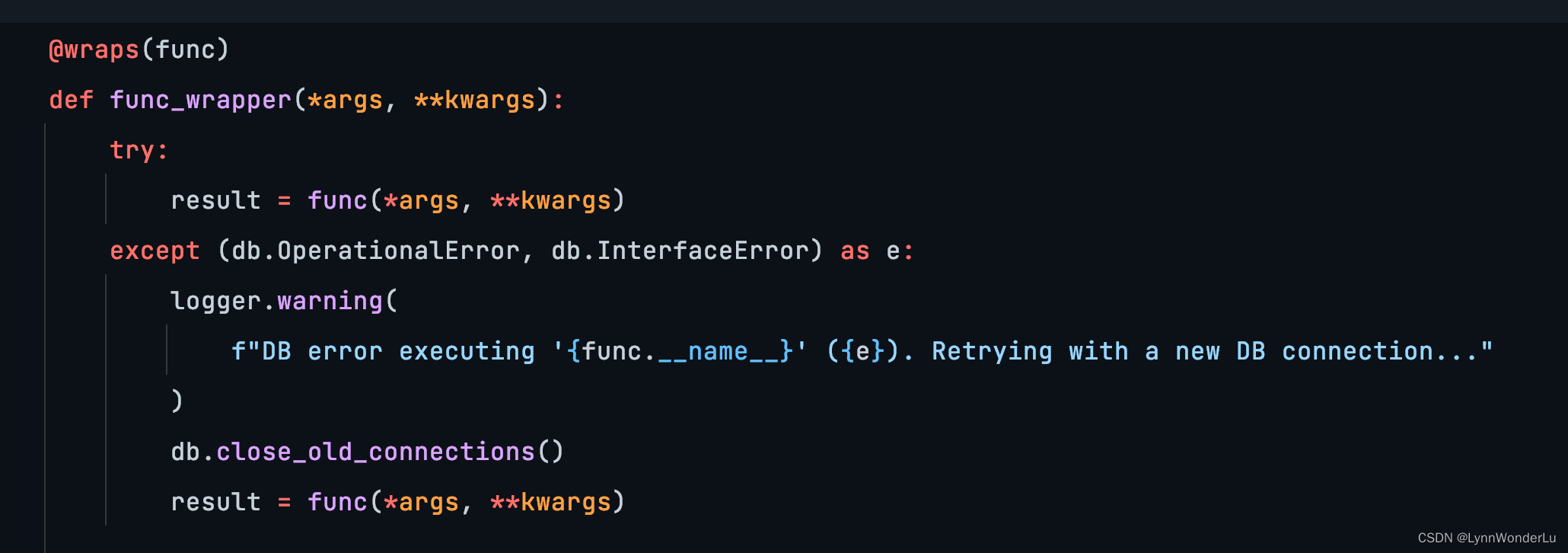
- 最终解决方式是在每个线程中执行数据库操作之前都直接调用 close_old_connections 清一遍过期的连接,这样既可以复用正常连接也不会导致超限。
主动关闭旧连接并不是新鲜事,在使用 Django-apscheduler 时也可以发现:
Python 多线程和多进程
一些概念
多任务: 简单地说,就是操作系统可以同时运行多个任务。打个比方,你一边在用浏览器上网,一边在听 MP3,一边在用 Word 赶作业,这就是多任务,至少同时有 3 个任务正在运行。还有很多任务悄悄地在后台同时运行着,只是桌面上没有显示而已。
多进程
解决多任务的一种处理方式是:启动多个进程,每个进程中有一个线程,从而实现多任务。当然也可以多进程+多线程相结合的方式实现。
Python 多进程目前没有进行应用,暂时不赘述
多线程
启动一个进程,其中有多个线程,从而实现多任务。一个进程默认会启动一个线程,称为主线程,主线程可以启动更多的线程。
多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改。
线程共享变量的解决方法:基于这个背景,我们在 Python 中通常用 threading.Lock() 来给线程中的任务中的某些内容按需加锁,这样某个线程获得了锁之后其他线程就只能等这个锁 release 了才能执行。因此包含锁的某段代码实际上只能以单线程模式执行。
threading.local 让每个线程可以拥有自己独立的数据,不必再理会加锁的麻烦。
应用: threading.local常用的地方就是为每个线程绑定一个数据库连接,HTTP请求,用户身份信息等,这样一个线程的所有调用到的处理函数都可以非常方便地访问这些资源。
Django 如何不使用命令行创建 superuser
当我们在不同的环境部署 Django 服务,尤其是多节点如果想使用 django-admin 每次使用
python manage.py createsuperuser明显不方便,如何在代码中直接创建一个默认的呢
reference:
原理:
- 登录后端的时候会顺序通过下文所述的两个 backend 的认证,第一个是默认的,如果 db 没有 admin 的信息,它会失败,继续走第二个的 authenticate 会自动入库。
- 下次再进来走第一个 backend 认证会通过
AUTHENTICATION_BACKENDS = [
'django.contrib.auth.backends.ModelBackend',
'apps.xx.backends.InitUserBackend',
]
INIT_USERNAME = os.getenv('INIT_USERNAME') or 'admin'
INIT_IDENTITY = os.getenv('INIT_IDENTITY') or \
'xxx'
import logging
from django.conf import settings
from django.contrib.auth.backends import BaseBackend
from django.contrib.auth.hashers import check_password
from .models import Account
logger = logging.getLogger(__name__)
class InitUserBackend(BaseBackend):
"""
初始用户Backend
"""
def authenticate(self, request, username=None, password=None, **kwargs):
if Account.objects.filter(username=username).exists():
return None
username_valid = (username == settings.INIT_USERNAME)
password_valid = check_password(password, settings.INIT_IDENTITY)
if username_valid and password_valid:
user = Account.objects.create(**{
'username': settings.INIT_USERNAME,
'password': settings.INIT_IDENTITY,
'is_staff': True,
'is_superuser': True,
})
logger.debug(f'初始用户 {user} 验证通过')
return user
return None
def get_user(self, user_id):
try:
return Account.objects.get(pk=user_id)
except Account.DoesNotExist:
return None
def has_perm(self, user_obj, perm, obj=None):
return user_obj.username == settings.INIT_USERNAME
Django OOMKilled 问题
项目是用 k8s 部署的,运行一段时间后总能发现某个 pod 重启次数蛮多的,查看原因发现都是 OOMKilled,起初以为是由于 bulk_create 前用一个数组暂存了 queryset 导致内存占用越来越多。(实际并非如此,按这种思路应该这个数组最终使用完成会释放掉内存而不是逐渐累加)最终我们经过测试和验证发现是 queryset 缓存的原因。
reference:
数据库访问优化
背景知识:
- queryset 是惰性的,queryset 被构造、过滤、切片或者复制赋值时不会访问数据库,Django 只会在 queryset 被计算时执行查询操作,比如迭代
- 一旦开始计算 queryset 的值即意味着执行数据查询,就会将结果缓存在内存中,这也是 oom 的原因,注意使用切片或者索引的这种限制查询结果集不会产生缓存。
解决方法:
- 在 queryset 上使用 iterator() 将直接读取结果,而不在 QuerySet 级别做任何缓存(在内部,默认的迭代器调用 iterator() 并缓存返回值)。对于一个只需要访问一次就能返回大量对象的 QuerySet 来说,这可以带来更好的性能,并显著减少内存。
items = []
for item in Test.objects.filter(account__id__exact=self.id).iterator():
items.append(item)
Test2.objects.bulk_create(items)
- 另外在返回数据库对象的时候尽量使用
queryset.values()取出真正需要的字段的值而非返回整个对象
Max retries exceeded with URL xxx
Fix “Max retries exceeded with URL” error in Python requests library
可能原因:
- url 错误
- 网络连接不稳定
- 服务器过载:server 收到了太多的请求,处理不过来导致我们的 request 没有得到响应
解决办法:
- 增加 request timeout
- 增加重试策略,可以参考详解指数退避算法
Django 405 Method Not Allowed
这个很大原因是 APPEND_SLASH 这个导致的,它在 CommonMiddleware 中,默认为 True,在路由上加上 / 即可访问到设定好的内容。
Original: https://blog.csdn.net/lynnwonder6/article/details/127499195
Author: LynnWonderLu
Title: Python & Django 问题记录
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/737221/
转载文章受原作者版权保护。转载请注明原作者出处!