

目录
在models.py 文件中定义模型类。
from django.db import models
Create your models here.
准备书籍列表信息的模型类
class BookInfo(models.Model):
# 创建字段,字段类型...
name = models.CharField(max_length=20, verbose_name='名称')
pub_date = models.DateField(verbose_name='发布日期',null=True)
readcount = models.IntegerField(default=0, verbose_name='阅读量')
commentcount = models.IntegerField(default=0, verbose_name='评论量')
is_delete = models.BooleanField(default=False, verbose_name='逻辑删除')
class Meta:
db_table = 'bookinfo' # 指明数据库表名
verbose_name = '图书' # 在admin站点中显示的名称
def __str__(self):
"""定义每个数据对象的显示信息"""
return self.name
准备人物列表信息的模型类
class PeopleInfo(models.Model):
GENDER_CHOICES = (
(0, 'male'),
(1, 'female')
)
name = models.CharField(max_length=20, verbose_name='名称')
gender = models.SmallIntegerField(choices=GENDER_CHOICES, default=0, verbose_name='性别')
description = models.CharField(max_length=200, null=True, verbose_name='描述信息')
book = models.ForeignKey(BookInfo, on_delete=models.CASCADE, verbose_name='图书') # 外键
is_delete = models.BooleanField(default=False, verbose_name='逻辑删除')
class Meta:
db_table = 'peopleinfo'
verbose_name = '人物信息'
def __str__(self):
return self.name
插入对应数据
insert into bookinfo(name, pub_date, readcount,commentcount, is_delete) values
('射雕英雄传', '1980-5-1', 12, 34, 0),
('天龙八部', '1986-7-24', 36, 40, 0),
('笑傲江湖', '1995-12-24', 20, 80, 0),
('雪山飞狐', '1987-11-11', 58, 24, 0);
insert into peopleinfo(name, gender, book_id, description, is_delete) values
('郭靖', 1, 1, '降龙十八掌', 0),
('黄蓉', 0, 1, '打狗棍法', 0),
('黄药师', 1, 1, '弹指神通', 0),
('欧阳锋', 1, 1, '蛤蟆功', 0),
('梅超风', 0, 1, '九阴白骨爪', 0),
('乔峰', 1, 2, '降龙十八掌', 0),
('段誉', 1, 2, '六脉神剑', 0),
('虚竹', 1, 2, '天山六阳掌', 0),
('王语嫣', 0, 2, '神仙姐姐', 0),
('令狐冲', 1, 3, '独孤九剑', 0),
('任盈盈', 0, 3, '弹琴', 0),
('岳不群', 1, 3, '华山剑法', 0),
('东方不败', 0, 3, '葵花宝典', 0),
('胡斐', 1, 4, '胡家刀法', 0),
('苗若兰', 0, 4, '黄衣', 0),
('程灵素', 0, 4, '医术', 0),
('袁紫衣', 0, 4, '六合拳', 0);
shell
方便开发过程中对数据库的操作测试等
python manage.py shell
from book.models import BookInfo,PeopleInfo
BookInfo.objects.all()
<queryset [<bookinfo: 射雕英雄传>, <bookinfo: 天龙八部>, <bookinfo: 笑傲江湖>, <bookinfo: 雪山飞狐>, <bookinfo: python入门>]></bookinfo:></bookinfo:></bookinfo:></bookinfo:></queryset>
查看MySQL数据库日志
查看mysql数据库日志可以查看对数据库的操作记录。 mysql日志文件默认没有产生,需要做如下配置:
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
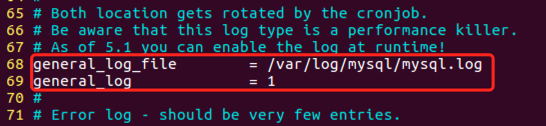

把68,69行前面的#去除,然后保存并使用如下命令重启mysql服务。
sudo service mysql restart
使用如下命令打开mysql日志文件。
tail -f /var/log/mysql/mysql.log # 可以实时查看数据库的日志内容
如提示需要sudo权限,执行
sudo tail -f /var/log/mysql/mysql.log
1 增加
增加数据有两种方法。
1)save
通过创建模型类对象,执行对象的save()方法保存到数据库中。
>>> from book.models import BookInfo,PeopleInfo
>>> book = BookInfo(
... name='python入门',
... pub_date='2010-1-1'
... )
>>> book.save()
>>> book
<bookinfo: python入门>
</bookinfo:>
2)create
通过模型类.objects.create()保存。
>>> PeopleInfo.objects.create(
... name='itheima',
... book=book
... )
<peopleinfo: itheima></peopleinfo:>
修改
修改更新有两种方法
1)save 先取获取指定的数据
修改模型类对象的属性,然后执行save()方法
>>> person = PeopleInfo.objects.get(name='itheima')
>>> person.name = 'itcast'
>>> person.save()
>>> person
<peopleinfo: itcast>
</peopleinfo:>
2)update
使用模型类.objects.filter().update(),会返回受影响的行数
>>> PeopleInfo.objects.filter(name='itcast').update(name='传智播客')
1
3 删除
删除有两种方法
1)模型类对象delete
>>> person = PeopleInfo.objects.get(name='传智播客')
>>> person.delete()
(1, {'book.PeopleInfo': 1})
2)模型类.objects.filter().delete()
>>> BookInfo.objects.filter(name='python入门').delete()
(1, {'book.BookInfo': 1, 'book.PeopleInfo': 0})
查询
get查询单一结果,如果不存在会抛出 模型类.DoesNotExist异常。
all查询多个结果。
count查询结果数量。
过滤查询
实现SQL中的where功能,包括
- filter过滤出多个结果 返回列表
- exclude排除掉符合条件剩下的结果 类似not
- get过滤单一结果
查询编号为1的图书。
BookInfo.objects.filter(id__exact=1)
可简写为:
BookInfo.objects.filter(id=1)
模糊查询
contains:是否包含。
说明:如果要包含%无需转义,直接写即可。
例:查询书名包含’传’的图书。
BookInfo.objects.filter(name__contains='传')
<queryset [<bookinfo: 射雕英雄传>]></queryset>
startswith、endswith:以指定值开头或结尾。
例:查询书名以’部’结尾的图书
>>> BookInfo.objects.filter(name__endswith='部')
<queryset [<bookinfo: 天龙八部>]>
</queryset>
以上运算符都区分大小写,在这些运算符前加上i表示不区分大小写,如iexact、icontains、istartswith、iendswith.
isnull:是否为null。
例:查询书名为空的图书。
>>> BookInfo.objects.filter(name__isnull=True)
<queryset []></queryset>
in:是否包含在范围内。
例:查询编号为1和3和5的图书 若不存在也不会报错
>>> BookInfo.objects.filter(id__in=[1,3,5])
<queryset [<bookinfo: 射雕英雄传>, <bookinfo: 笑傲江湖>]></bookinfo:></queryset>
比较查询
- gt大于 (greater then)
- gte大于等于 (greater then equal)
- lt小于 (less then)
- lte小于等于 (less then equal)
例:查询编号大于3的图书
BookInfo.objects.filter(id__gt=3)
不等于的运算符,使用exclude()过滤器。
BookInfo.objects.exclude(id=2)
, , ]>
year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算。
例:查询1980年发表的图书。
>>> BookInfo.objects.filter(pub_date__year=1980)
<queryset [<bookinfo: 射雕英雄传>]>
</queryset>
例:查询1990年1月1日后发表的图书。
>>> BookInfo.objects.filter(pub_date__gt='1990-1-1')
<queryset [<bookinfo: 笑傲江湖>]></queryset>
F对象
之前的查询都是对象的属性与常量值比较,两个属性怎么比较呢? 答:使用F对象,被定义在django.db.models中。
表中字段之间的比较 而不是字段与具体值的操作
查询阅读量大于等于评论量的图书。
>>> from django.db.models import F
>>> BookInfo.objects.filter(readcount__gt=F('commentcount'))
<queryset [<bookinfo: 雪山飞狐>]>
</queryset>
可以在F对象上使用算数运算。
例:查询阅读量大于2倍评论量的图书。
>>> BookInfo.objects.filter(readcount__gt=F('commentcount')*2)
<queryset [<bookinfo: 雪山飞狐>]></queryset>
查询阅读量大于20,并且编号小于3的图书。 同sql语句中where部分的and关键字
>>> BookInfo.objects.filter(readcount__gt=20,id__lt=3)
<queryset [<bookinfo: 天龙八部>]>
或者
>>> BookInfo.objects.filter(readcount__gt=20).filter(id__lt=3)
<queryset [<bookinfo: 天龙八部>]></queryset></queryset>
Q对象
同sql语句中where部分的or关键字 与 | & ~配合使用
查询阅读量大于20,或编号小于3的图书,只能使用Q对象实现
>>> BookInfo.objects.filter(Q(readcount__gt=20)|Q(id__lt=3))
<queryset [<bookinfo: 射雕英雄传>, <bookinfo: 天龙八部>, <bookinfo: 雪山飞狐>]>
</bookinfo:></bookinfo:></queryset>
Q对象前可以使用~操作符,表示非not。
例:查询编号不等于3的图书。
>>> BookInfo.objects.filter(~Q(id=3))
<queryset [<bookinfo: 射雕英雄传>, <bookinfo: 天龙八部>, <bookinfo: 雪山飞狐>]>
相当于
BookInfo.objects.exclude(id=3)</bookinfo:></bookinfo:></queryset>
聚合函数
配合Avg平均, Count数量, Max最大, Min最小, Sum求和使用
查询图书的总阅读量。
>>> from django.db.models import Sum
>>> BookInfo.objects.aggregate(Sum('readcount'))
{'readcount__sum': 126}
注意aggregate的返回值是一个字典类型,格式如下:
{'属性名__聚合类小写':值}
如:{'readcount__sum': 126}
排序
默认升序
>>> BookInfo.objects.all().order_by('readcount')
<queryset [<bookinfo: 射雕英雄传>, <bookinfo: 笑傲江湖>, <bookinfo: 天龙八部>, <bookinfo: 雪山飞狐>]>
降序
>>> BookInfo.objects.all().order_by('-readcount')
<queryset [<bookinfo: 雪山飞狐>, <bookinfo: 天龙八部>, <bookinfo: 笑傲江湖>, <bookinfo: 射雕英雄传>]></bookinfo:></bookinfo:></bookinfo:></queryset></bookinfo:></bookinfo:></bookinfo:></queryset>
关联查询
一对多,查询某个书中的人物
先查询书再从表_set的数据
BookInfo.objects.get(id=1).peopleinfo_set.all()
多对一 .book 这里是定义model时候写的外键变量
PeopleInfo.objects.get(id=1).book
访问一对应的模型类关联对象的id语法:
多对应的模型类对象.关联类属性_id
PeopleInfo.objects.get(id=10).book_id #3
关联过滤查询
查询书中有叫郭靖的书名称
BookInfo.objects.filter(peopleinfo__name='郭靖')注意方法内的属性都是小写
查询书中人物的描述带有八的书名称
BookInfo.objects.filter(peopleinfo__description__contains='八')
查询书的所有人物
PeopleInfo.objects.filter(book__name='天龙八部')
查询图书阅读量大于30的所有人物
PeopleInfo.objects.filter(book__readcount__gt=30)
查询集QuerySet
- all():返回所有数据。
- filter():返回满足条件的数据。
- exclude():返回满足条件之外的数据。
- order_by():对结果进行排序。
- 判断某一个查询集中是否有数据:
- exists():判断查询集中是否有数据,如果有则返回True,没有则返回False。
2大特性
惰性执行
创建查询集不会访问数据库,直到调用数据时,才会访问数据库
例如,当执行如下语句时,并未进行数据库查询,只是创建了一个查询集books
books = BookInfo.objects.all()
继续执行遍历迭代操作后,才真正的进行了数据库的查询
for book in books:
print(book.name)
缓存
就是吧用到的硬盘数据存到内存中,下次调用从内存中读取,速度快
查询集先把查询语句赋给变量 真正用到的时候通过变量去取,
此时多次执行取操作会发现只会去数据库执行一次查询
查看办法吧mysql日志文件打开查看
此操作不会走2大特性,因为是直接用的
from book.models import BookInfo
[book.id for book in BookInfo.objects.all()]
[book.id for book in BookInfo.objects.all()]
先赋予变量,通过该变量执行取语句2次,使用了2大特性
books=BookInfo.objects.all()
[book.id for book in books]
[book.id for book in books]
限制查询集
类似于limit和offset子句
books = BookInfo.objects.all()[0:2]
分页
#查询数据
books = BookInfo.objects.all()
#<queryset [<bookinfo: 射雕英雄传>, <bookinfo: 天龙八部>, <bookinfo: 笑傲江湖>, <bookinfo: 雪山飞狐>]>
#导入分页类
from django.core.paginator import Paginator
#创建分页实例 一页2条数据
paginator=Paginator(books,2)
#获取指定页码的数据 第几页的所有数据
page_skus = paginator.page(1)
#获取分页数据 告诉多少页
total_page=paginator.num_pages</bookinfo:></bookinfo:></bookinfo:></queryset>
Original: https://blog.csdn.net/crazynzg/article/details/122600023
Author: 皮阿玛
Title: django之模型数据操作
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/734265/
转载文章受原作者版权保护。转载请注明原作者出处!